Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die SpeechRecognition-API ist eine Standardmäßige Web-API, mit der Sprache aus einer Audioquelle wie einer Mediendatei oder einem Gerätemikrofon direkt aus dem JavaScript-Code einer Website oder Browsererweiterung in Text konvertiert werden kann. Dieser Artikel konzentriert sich auf die Verwendung der SpeechRecognition-API mit dem in Microsoft Edge integrierten Spracherkennungsmodell auf dem Gerät (oder lokal).
Weitere Informationen zur API finden Sie unter Web Speech-API unter MDN.
Ausführlicher Inhalt:
- Verfügbarkeit des lokalen Spracherkennungsmodells
- Vorteile des lokalen Spracherkennungsmodells
- Aktivieren der lokalen Spracherkennung in Microsoft Edge
- Sehen Sie sich ein funktionierendes Beispiel an
- Verwenden der SpeechRecognition-API mit lokaler Erkennung auf Ihrer Website
- Senden von Feedback
- Siehe auch
Verfügbarkeit des lokalen Spracherkennungsmodells
Das lokale Spracherkennungsmodell ist in Microsoft Edge Canary oder Dev (Version 150.0.4076 oder höher) verfügbar. Weitere Informationen finden Sie unter Werden Sie ein Microsoft Edge-Insider.
Vorteile des lokalen Spracherkennungsmodells
Wenn Sie die SpeechRecognition-API mit dem lokalen Modell in Microsoft Edge verwenden, erfolgt die Spracherkennung auf demselben Gerät, auf dem die Sprache erfasst wird. Dieser Ansatz bietet im Vergleich zu cloudbasierten Lösungen die folgenden Vorteile:
Reduzierte Kosten: Für die Verwendung eines Clouderkennungsdiensts fallen keine Kosten an.
Netzwerkunabhängigkeit: Abgesehen vom anfänglichen Modelldownload gibt es keine Netzwerklatenz, wenn diese API zum Konvertieren von Sprache verwendet wird, und die API kann auch verwendet werden, wenn das Gerät offline ist.
Verbesserter Datenschutz: Die Spracheingabe in das Modell verlässt nie das Gerät und wird nicht zum Trainieren von KI-Modellen gesammelt.
Modellverfügbarkeit
Ein erster Download des Modells ist erforderlich, wenn eine Website zum ersten Mal das lokale Spracherkennungsmodell mit der SpeechRecognition-API verwendet.
Sie können den Modelldownload mithilfe der Von der SpeechRecognition-API-Methode install() zurückgegebenen Zusage überwachen. Weitere Informationen finden Sie unter Überprüfen, ob das lokale Modell bereits installiert ist.
Aktivieren der lokalen Spracherkennung in Microsoft Edge
Um das lokale Spracherkennungsmodell mit der SpeechRecognition-API zu verwenden, müssen Sie das Feature in Microsoft Edge Canary oder Dev aktivieren. So aktivieren Sie die Spracherkennung mithilfe des Gerätemodells:
Stellen Sie sicher, dass Sie Microsoft Edge Canary oder Dev (Version 150.0.4076 oder höher) verwenden. Weitere Informationen finden Sie unter Werden Sie ein Microsoft Edge-Insider.
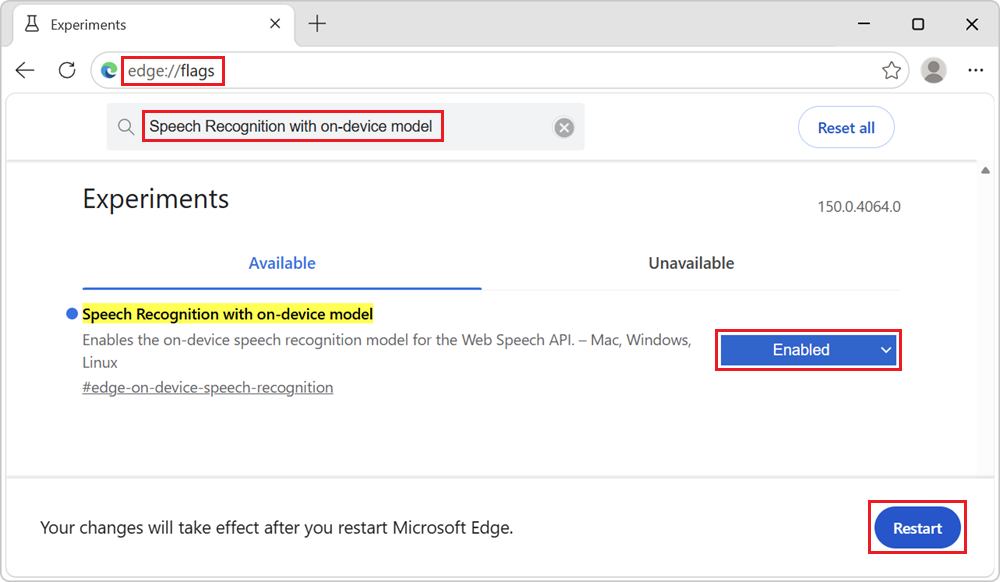
Öffnen Sie in Microsoft Edge Canary oder Dev eine neue Registerkarte oder ein neues Fenster, und wechseln Sie zu
edge://flags.Geben Sie im Suchfeld oben auf der Seite Die Spracherkennung mit dem Modell auf dem Gerät ein.
Wählen Sie in der Dropdownliste Spracherkennung mit Gerätemodelldie Option Aktiviert aus, und klicken Sie dann unten rechts auf die Schaltfläche Neu starten :
Sehen Sie sich ein funktionierendes Beispiel an
So sehen Sie die SpeechRecognition-API in Aktion und zeigen den Democode an:
Aktivieren Sie die lokale Spracherkennung in Microsoft Edge, wie oben beschrieben.
Öffnen Sie in Microsoft Edge Canary oder Dev eine Registerkarte oder ein Fenster, und wechseln Sie zum SpeechRecognition-API-Playground.
Überprüfen Sie oben im Informationsbanner die status: Zunächst wird die SpeechRecognition-API bereit gelesen. Klicken Sie auf Start, um zu beginnen.
Wählen Sie in der Dropdownliste Eingabesprache die Sprache aus, die Sie für die Spracherkennung verwenden möchten.
Wählen Sie in der Dropdownliste Audioquelle eine Audioquelle für die Spracherkennung aus:
- Wählen Sie Mikrofon aus, um ihr Gerätemikrofon als Audioquelle zu verwenden.
- Wählen Sie Datei aus, um eine Audio- oder Videodatei von Ihrem Gerät als Audioquelle zu verwenden.
Wenn Sie Datei als Audioquelle ausgewählt haben, wird ein Mediendateiabschnitt angezeigt. Klicken Sie auf die Schaltfläche Datei auswählen , und wählen Sie dann eine Audio- oder Videodatei von Ihrem Gerät aus.
Klicken Sie auf die Schaltfläche Start.
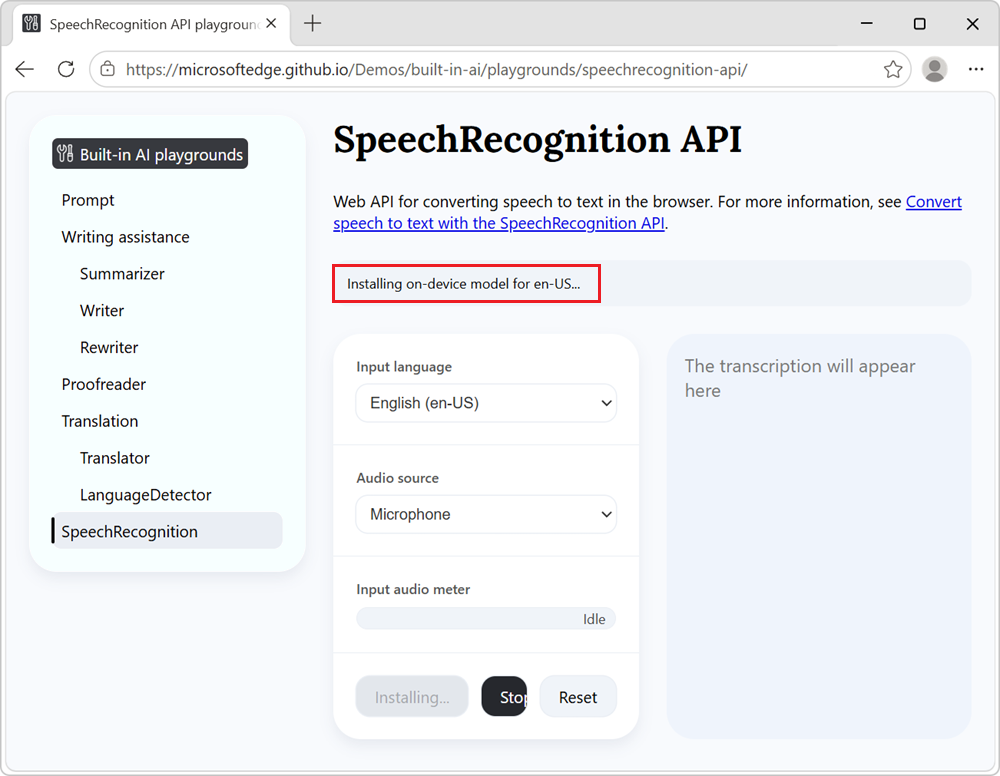
Wenn Sie das lokale Spracherkennungsmodell für die ausgewählte Sprache noch nicht heruntergeladen haben, wird der Download gestartet, und das Informationsbanner lautet Installing on-device model for en-US...:
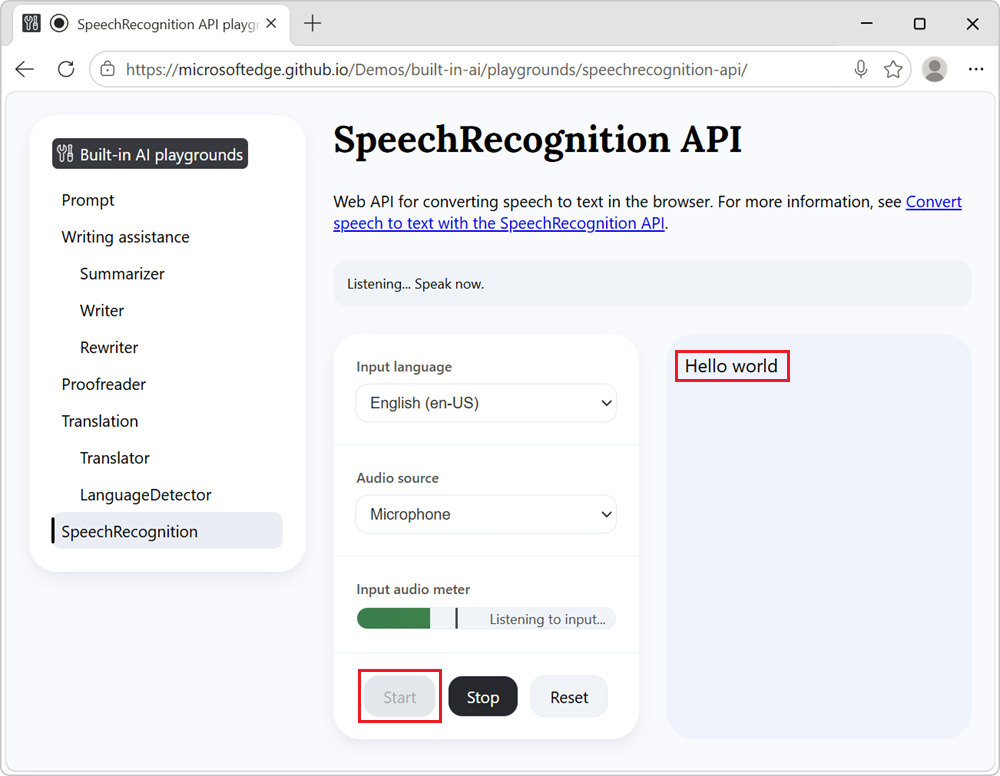
Nach der Installation des Modells wird die Texttranskription auf der Seite angezeigt:
Um die Konvertierung von Sprache in Text zu beenden, klicken Sie jederzeit auf die Schaltfläche Beenden .
Die Transkription kann auch nach einer langen Stille in der Eingabeaudio automatisch beendet werden.
Siehe auch:
- /built-in-ai/playgrounds/speechrecognition-api/ – Quellcode für die Demo des SpeechRecognition-API-Playgrounds.
Verwenden der SpeechRecognition-API mit lokaler Erkennung auf Ihrer Website
In den folgenden Abschnitten wird beschrieben, wie Sie die SpeechRecognition-API mit lokaler Spracherkennung im Code Ihrer Website verwenden. Weitere Informationen zur API selbst finden Sie unter Web Speech-API unter MDN.
Überprüfen Sie, ob die API unterstützt wird, und instanziieren Sie ein SpeechRecognition-Objekt.
Um sicherzustellen, dass die SpeechRecognition-API im Browser unterstützt wird, testen Sie, ob das SpeechRecognition Objekt verfügbar ist:
if (!window.SpeechRecognition) {
console.log("The SpeechRecognition API is not available in this browser.");
} else {
console.log("The SpeechRecognition API is available.");
}
Wenn die API unterstützt wird, erstellen Sie eine neue SpeechRecognition instance, um mit der Verwendung der API zu beginnen:
const recognition = new SpeechRecognition();
Siehe auch:
- SpeechRecognition, bei MDN.
Auswählen einer Eingabesprache und Aktivieren der lokalen Erkennung
Um die Spracherkennung mithilfe eines lokalen Modells zu konfigurieren, geben Sie eine Eingabesprache an, und legen Sie die processLocally Option fest:
recognition.lang = "en-US";
recognition.processLocally = true;
Ab Microsoft Edge 150.0.4076 werden die folgenden Eingabesprachen für die lokale Spracherkennung unterstützt:
- Englisch (En-US)
- Deutsch (de-DE)
- Italienisch (it-IT)
- Portugiesisch (pt-PT)
- Spanisch (es-ES)
- Koreanisch (ko-KR)
Die Sprachunterstützung wird voraussichtlich in zukünftigen Versionen erweitert.
Legen Sie außerdem die continuous Optionen und interimResults auf fest true , um lange Audiositzungen zu transkribieren, ohne zu beenden und Zwischenergebnisse zu erhalten:
recognition.continuous = true;
recognition.interimResults = true;
Siehe auch:
- SpeechRecognition: lang-Eigenschaft, bei MDN.
- SpeechRecognition: processLocally-Eigenschaft bei MDN.
- SpeechRecognition: kontinuierliche Eigenschaft bei MDN.
- SpeechRecognition: interimResults-Eigenschaft bei MDN.
Überprüfen, ob das lokale Modell bereits installiert ist
Bevor Sie mit der Erkennung beginnen, überprüfen Sie mithilfe der -Methode, ob das lokale Modell für die SpeechRecognition.available() ausgewählte Sprache verfügbar ist.
Wenn das Modell noch nicht installiert ist, lösen Sie die Installation mithilfe der SpeechRecognition.install() -Methode aus, und warten Sie, bis das Modell abgeschlossen ist, bevor Sie mit der Erkennung beginnen:
async function ensureModelReady(lang) {
// Check if the model is already available.
const availability = await SpeechRecognition.available({
langs: [lang],
processLocally: true,
});
// If the model is already available, proceed to recognition.
if (availability === "available") {
return true;
}
// If the model is not available but can be downloaded,
// trigger the installation and wait for it to complete
// before proceeding to recognition.
if (availability === "downloadable" || availability === "downloading") {
const installed = await SpeechRecognition.install({
langs: [lang],
processLocally: true,
});
if (!installed) {
throw new Error(`Failed to install local model for ${lang}.`);
}
return true;
}
return false;
}
Die von SpeechRecognition.install() zurückgegebene Zusage wird aufgelöst, wenn die Installation erfolgreich war oder fehlschlägt.
Siehe auch:
- SpeechRecognition: statische Methode available() bei MDN.
- SpeechRecognition: statische Install()-Methode bei MDN.
Starten der Spracherkennung
Nachdem Sie sichergestellt haben, dass die API und das Modell bereit sind, verwenden Sie die -Methode, um die start() Erkennung zu starten.
Wenn sie ohne Parameter aufgerufen wird, erkennt die start() Methode Audiodaten vom Mikrofon des Benutzers:
recognition.start();
Um Audiodaten aus einer Mediendatei statt aus dem Mikrofon des Benutzers zu erkennen, übergeben Sie eine MediaStreamTrack instance als Argument an die start() -Methode. Sie können beispielsweise eine MediaStreamTrack instance erstellen, indem Sie mithilfe der WebAudio-API eine MediaStreamDestinationNode instance erstellen:
const audioContext = new AudioContext();
const mediaStreamDestination = audioContext.createMediaStreamDestination();
recognition.start(mediaStreamDestination.stream.getAudioTracks()[0]);
Siehe auch:
- SpeechRecognition: start()-Methode bei MDN.
- Webaudio-API bei MDN.
Erkennung explizit und auf Medienende beenden
Um die Erkennung zu beenden, verwenden Sie die - stop() Methode:
recognition.stop();
Sie können die Erkennung auch beenden, wenn die Medieneingabe endet, indem Sie den onended Ereignishandler des Medienelements verwenden, das Sie als Eingabe verwenden. Wenn Sie beispielsweise oder HTMLAudioElementHTMLVideoElement als Audioquelle verwenden, können Sie den Ereignishandler wie folgt einrichten:
mediaElement.onended = () => recognition.stop();
Siehe auch:
- SpeechRecognition: stop()-Methode bei MDN.
Feedback senden
Wir sind an Ihrem Feedback zu folgenden Fragen interessiert:
- Das lokale Spracherkennungsmodell.
- Die Leistung des lokalen Spracherkennungsmodells.
- Alle anderen Verbesserungen, die Sie für Ihre Anwendungsfälle wünschen.
Senden Sie Feedback, indem Sie einen Kommentar zum Feedbackproblem der SpeechRecognition-API hinzufügen.
Siehe auch
Microsoft:
MDN:
-
SpeechRecognition
- SpeechRecognition: statische Methode available()
- SpeechRecognition: fortlaufende Eigenschaft
- SpeechRecognition: statische Methode install()
- SpeechRecognition: interimResults-Eigenschaft
- SpeechRecognition: lang-Eigenschaft
- SpeechRecognition: processLocally-Eigenschaft
- SpeechRecognition: start()-Methode
- SpeechRecognition: stop()-Methode
- Webaudio-API
- Web Speech-API
Github: