Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die erweiterten Q&A Chatbots sind leistungsstarke Apps, die mit Hilfe von LLMs (Large Language Models) erstellt wurden. Die Chatbots beantworten Fragen, indem sie Informationen aus bestimmten Quellen mithilfe einer Methode namens Retrieval-Augmented Generation (RAG) abrufen. Die RAG-Architektur verfügt über zwei Standard Flows:
Datenerfassung: Eine Pipeline zum Erfassen und Indizieren von Daten aus einer Quelle. Dies geschieht normalerweise offline.
Abruf und Generierung: Die RAG-Kette, die die Benutzerabfrage zur Laufzeit übernimmt und die relevanten Daten aus dem Index abruft und diese dann an das Modell übergibt.
Microsoft Teams ermöglicht es Ihnen, einen Konversationsbot mit RAG zu erstellen, um eine verbesserte Erfahrung zu schaffen, um die Produktivität zu maximieren. Microsoft 365 Agents Toolkit (früher als Teams Toolkit bezeichnet) bietet eine Reihe von sofort einsatzbereiten App-Vorlagen in der Kategorie Chat with Your Data , die die Funktionen der Azure KI-Suche, Microsoft 365 SharePoint und benutzerdefinierte API als unterschiedliche Datenquelle und LLMs kombiniert, um eine Konversationssuche in Teams zu erstellen.
Voraussetzungen
| Installieren | Zum Benutzen... |
|---|---|
| Visual Studio Code | JavaScript-, TypeScript- oder Python-Buildumgebungen. Verwenden Sie die neueste Version. |
| Microsoft 365 Agents Toolkit | Microsoft Visual Studio Code-Erweiterung, die ein Projektgerüst für Ihre App erstellt. Verwenden Sie die neueste Version. |
| Node.js | Back-End-JavaScript-Laufzeitumgebung. Weitere Informationen finden Sie unter Node.js Versionskompatibilitätstabelle für den Projekttyp. |
| Microsoft Teams | Microsoft Teams für die Zusammenarbeit mit allen Personen, mit denen Sie über Apps für Chats, Besprechungen und Anrufe zusammenarbeiten, alles an einem Ort. |
| Azure OpenAI | Erstellen Sie zunächst Ihren OpenAI-API-Schlüssel, um den Generative Pretrained Transformer (GPT) von OpenAI zu verwenden. Wenn Sie Ihre App hosten oder auf Ressourcen in Azure zugreifen möchten, müssen Sie einen Azure OpenAI-Dienst erstellen. |
Erstellen eines neuen einfachen KI-Chatbotprojekts
Öffnen Sie Visual Studio Code.
Wählen Sie das Symbol Microsoft 365 Agents Toolkit
 in der Visual Studio Code-Aktivitätsleiste aus.
in der Visual Studio Code-Aktivitätsleiste aus.Wählen Sie Create a New Agent/App (Neuen Agent/neue App erstellen) aus.
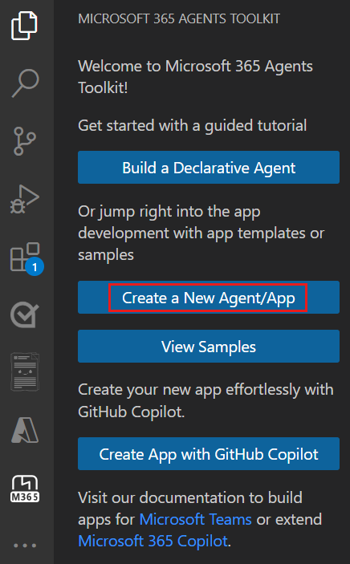
Wählen Sie Benutzerdefinierter Engine-Agent aus.
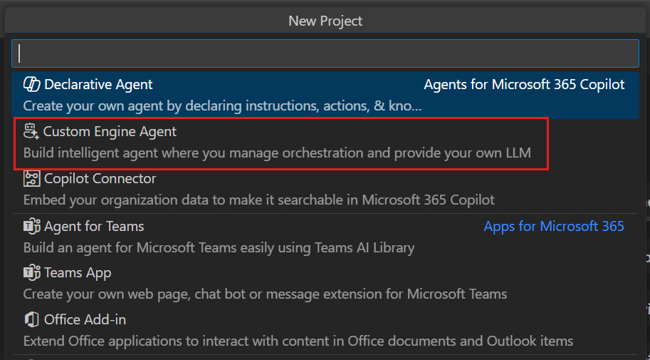
Wählen Sie Chat with Your Data (Mit Ihren Daten chatten) aus.
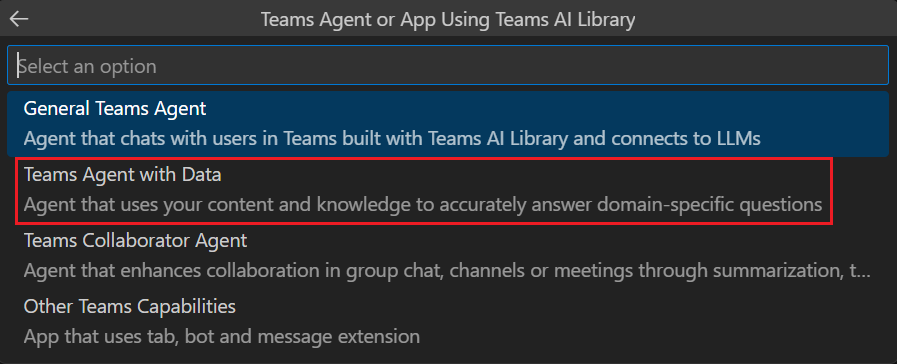
Wählen Sie Anpassen aus.
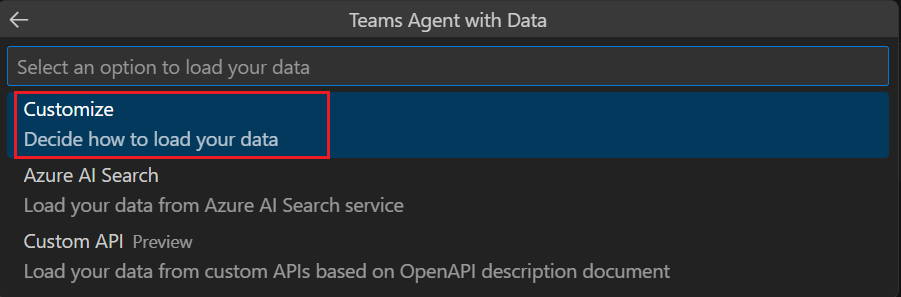
Wählen Sie JavaScript aus.
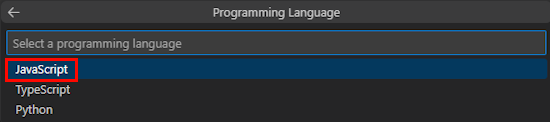
Wählen Sie Azure OpenAI oder OpenAI aus.
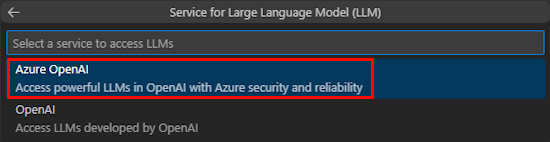
Geben Sie Ihre Azure OpenAI - oder OpenAI-Anmeldeinformationen basierend auf dem ausgewählten Dienst ein. Drücken Sie die EINGABETASTE.

Wählen Sie Standardordneraus.

Führen Sie die folgenden Schritte aus, um den Standardspeicherort zu ändern:
- Wählen Sie Durchsuchen aus.
- Wählen Sie den Speicherort für den Projektarbeitsbereich aus.
- Wählen Sie Ordner auswählen aus.
Geben Sie einen App-Namen für Ihre App ein, und drücken Sie dann die EINGABETASTE .

Sie haben ihren Projektarbeitsbereich Chat with Your Data erfolgreich erstellt.
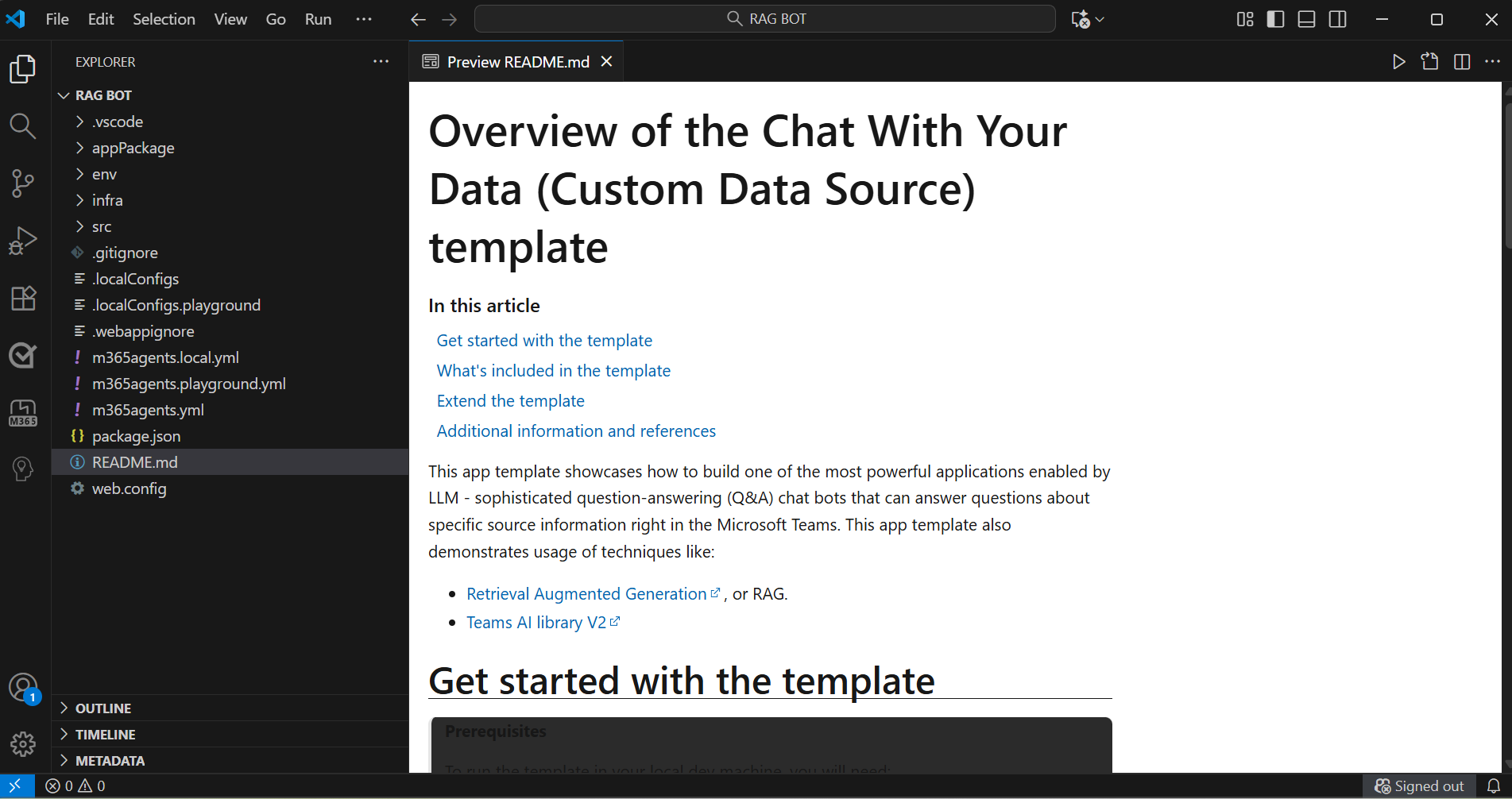
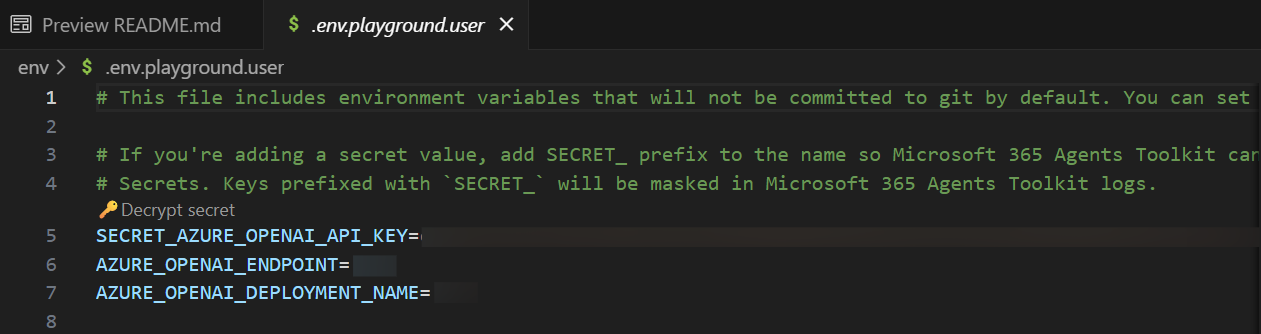
Wechseln Sie unter EXPLORER zur Datei env.env.playground.user>.
Aktualisieren Sie die folgenden Werte:
SECRET_AZURE_OPENAI_API_KEY=<your-key>AZURE_OPENAI_ENDPOINT=<your-endpoint>AZURE_OPENAI_DEPLOYMENT_NAME=<your-deployment>
Klicken Sie zum Debuggen Ihrer App auf F5 oder im linken Bereich auf Ausführen und Debuggen (STRG+UMSCHALT+D) und dann in der Dropdownliste auf Debuggen in Microsoft 365 Agents Playground (Vorschau) (zuvor als Teams App Test Tool bezeichnet).
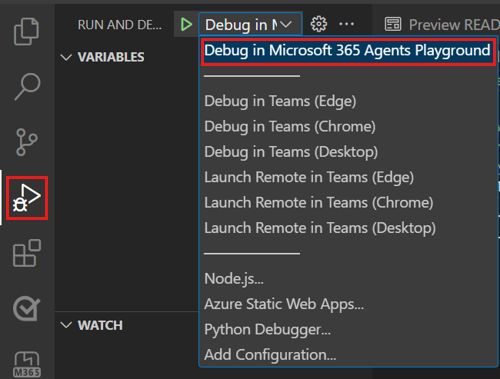
Agents Playground öffnet den Bot auf einer Webseite.

Machen Sie einen Überblick über den Quellcode der Bot-App
| Ordner | Inhalt |
|---|---|
.vscode |
Visual Studio Code-Dateien zum Debuggen. |
appPackage |
Vorlagen für das Teams-App-Manifest. |
env |
Umgebungsdateien. |
infra |
Vorlagen für die Bereitstellung von Azure-Ressourcen. |
src |
Der Quellcode für die App. |
src/index.js |
Richtet den Bot-App-Server ein. |
src/adapter.js |
Richtet den Botadapter ein. |
src/config.js |
Definiert die Umgebungsvariablen. |
src/prompts/chat/skprompt.txt |
Definiert die Eingabeaufforderung. |
src/prompts/chat/config.json |
Konfiguriert die Eingabeaufforderung. |
src/app/app.js |
Verarbeitet Geschäftslogiken für den RAG-Bot. |
src/app/myDataSource.js |
Definiert die Datenquelle. |
src/data/*.md |
Rohtextdatenquellen. |
m365agents.yml |
Dies ist die Standard Agents Toolkit-Projektdatei. Die Projektdatei definiert die Eigenschaften und Konfigurationsphasendefinitionen. |
m365agents.local.yml |
Dies wird mit Aktionen überschrieben m365agents.yml , die die lokale Ausführung und das Debuggen ermöglichen. |
m365agents.playground.yml |
Dies überschreibt m365agents.yml Aktionen, die die lokale Ausführung und das Debuggen im Agents Playground ermöglichen. |
RAG-Szenarien für Teams KI
Im KI-Kontext werden die Vektordatenbanken häufig als RAG-Speicher verwendet, die Einbettungsdaten speichern und die Suche nach Vektorähnlichkeiten ermöglichen. Die KI-Bibliothek von Teams bietet Hilfsprogramme zum Erstellen von Einbettungen für die angegebenen Eingaben.
Tipp
Die Ki-Bibliothek von Teams bietet keine Vektordatenbankimplementierung. Daher müssen Sie Ihre eigene Logik hinzufügen, um die erstellten Einbettungen zu verarbeiten.
// create OpenAIEmbeddings instance
const model = new OpenAIEmbeddings({ ... endpoint, apikey, model, ... });
// create embeddings for the given inputs
const embeddings = await model.createEmbeddings(model, inputs);
// your own logic to process embeddings
Das folgende Diagramm zeigt, wie die KI-Bibliothek von Teams Funktionen bereitstellt, um jeden Schritt des Abruf- und Generierungsprozesses zu vereinfachen:
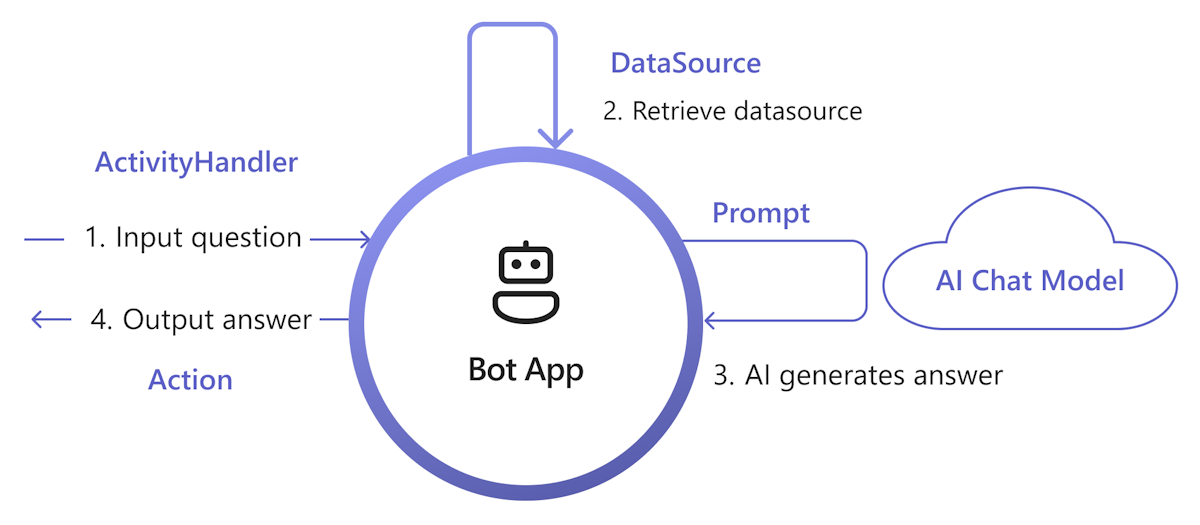
Eingabe verarbeiten: Die einfachste Methode besteht darin, die Eingabe des Benutzers ohne Änderung an den Abruf zu übergeben. Wenn Sie die Eingabe jedoch vor dem Abruf anpassen möchten, können Sie bestimmten eingehenden Aktivitäten einen Aktivitätshandler hinzufügen.
Datenquelle abrufen: Die KI-Bibliothek von Teams bietet eine
DataSourceSchnittstelle, mit der Sie Ihre eigene Abruflogik hinzufügen können. Sie müssen Ihre eigeneDataSourceinstance erstellen, und die Teams KI-Bibliothek ruft sie bei Bedarf auf.class MyDataSource implements DataSource { /** * Name of the data source. */ public readonly name = "my-datasource"; /** * Renders the data source as a string of text. * @param context Turn context for the current turn of conversation with the user. * @param memory An interface for accessing state values. * @param tokenizer Tokenizer to use when rendering the data source. * @param maxTokens Maximum number of tokens allowed to be rendered. * @returns The text to inject into the prompt as a `RenderedPromptSection` object. */ renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { ... } }KI mit Eingabeaufforderung aufrufen: Im Teams KI-Eingabeaufforderungssystem können Sie einfach eine
DataSourceeinfügen, indem Sie denaugmentation.data_sourcesKonfigurationsabschnitt anpassen. Dadurch wird die Eingabeaufforderung mit demDataSourceund dem Bibliotheksorchestrator verbunden, um denDataSourceText in die letzte Eingabeaufforderung einzufügen. Weitere Informationen finden Sie unter authorprompt. Beispiel: In der Datei derconfig.jsonEingabeaufforderung:{ "schema": 1.1, ... "augmentation": { "data_sources": { "my-datasource": 1200 } } }Buildantwort: Standardmäßig antwortet die KI-Bibliothek von Teams auf die von der KI generierte Antwort als SMS an den Benutzer. Wenn Sie die Antwort anpassen möchten, können Sie die standardmäßigen SAY-Aktionen überschreiben oder explizit das KI-Modell aufrufen, um Ihre Antworten zu erstellen, z. B. mit adaptiven Karten.
Im Folgenden finden Sie einen minimalen Satz von Implementierungen zum Hinzufügen von RAG zu Ihrer App. Im Allgemeinen wird implementiert DataSource , um Ihre knowledge in die Eingabeaufforderung einzufügen, sodass KI eine Antwort basierend auf dem knowledgegenerieren kann.
Erstellen Sie
myDataSource.tseine Datei, um die Schnittstelle zu implementierenDataSource:export class MyDataSource implements DataSource { public readonly name = "my-datasource"; public async renderData( context: TurnContext, memory: Memory, tokenizer: Tokenizer, maxTokens: number ): Promise<RenderedPromptSection<string>> { const input = memory.getValue('temp.input') as string; let knowledge = "There's no knowledge found."; // hard-code knowledge if (input?.includes("shuttle bus")) { knowledge = "Company's shuttle bus may be 15 minutes late on rainy days."; } else if (input?.includes("cafe")) { knowledge = "The Cafe's available time is 9:00 to 17:00 on working days and 10:00 to 16:00 on weekends and holidays." } return { output: knowledge, length: knowledge.length, tooLong: false } } }Registrieren Sie in der
DataSourceapp.tsDatei:// Register your data source to prompt manager planner.prompts.addDataSource(new MyDataSource());
Erstellen Sie die
prompts/qa/skprompt.txtDatei, und fügen Sie den folgenden Text hinzu:The following is a conversation with an AI assistant. The assistant is helpful, creative, clever, and very friendly to answer user's question. Base your answer off the text below:Erstellen Sie die
prompts/qa/config.jsonDatei, und fügen Sie den folgenden Code hinzu, um eine Verbindung mit der Datenquelle herzustellen:{ "schema": 1.1, "description": "Chat with QA Assistant", "type": "completion", "completion": { "model": "gpt-35-turbo", "completion_type": "chat", "include_history": true, "include_input": true, "max_input_tokens": 2800, "max_tokens": 1000, "temperature": 0.9, "top_p": 0.0, "presence_penalty": 0.6, "frequency_penalty": 0.0, "stop_sequences": [] }, "augmentation": { "data_sources": { "my-datasource": 1200 } } }
Auswählen von Datenquellen
In den Szenarien Chat with Your Data oder RAG stellt Agents Toolkit die folgenden Arten von Datenquellen bereit:
Anpassen: Ermöglicht die vollständige Steuerung der Datenerfassung, um einen eigenen Vektorindex zu erstellen und als Datenquelle zu verwenden. Weitere Informationen finden Sie unter Erstellen einer eigenen Datenerfassung.
Sie können auch die Azure Cosmos DB Vector Database-Erweiterung oder die Azure PostgreSQL Server-Vektorerweiterung als Vektordatenbanken oder die Bing-Websuche-API verwenden, um aktuelle Webinhalte abzurufen, um beliebige Datenquellen instance zu implementieren, um eine Verbindung mit Ihrer eigenen Datenquelle herzustellen.
Azure KI Search: Stellt ein Beispiel zum Hinzufügen Ihrer Dokumente zum Azure AI Search Service bereit, und verwenden Sie dann den Suchindex als Datenquelle.
Benutzerdefinierte API: Ermöglicht Ihrem Chatbot das Aufrufen der im OpenAPI-Beschreibungsdokument definierten API zum Abrufen von Domänendaten aus dem API-Dienst.
Microsoft Graph und SharePoint: Stellt ein Beispiel zur Verwendung von Microsoft 365-Inhalten aus der Microsoft Graph-Such-API als Datenquelle bereit.
Erstellen einer eigenen Datenerfassung
Führen Sie die folgenden Schritte aus, um Ihre Datenerfassung zu erstellen:
Laden Der Quelldokumente: Stellen Sie sicher, dass Ihr Dokument aussagekräftigen Text enthält, da das Einbettungsmodell nur Text als Eingabe akzeptiert.
In Blöcke aufteilen: Stellen Sie sicher, dass Sie das Dokument aufteilen, um API-Aufruffehler zu vermeiden, da das Einbettungsmodell eine Einschränkung für Eingabetoken aufweist.
Aufruf des Einbettungsmodells: Rufen Sie die Einbettungsmodell-APIs auf, um Einbettungen für die angegebenen Eingaben zu erstellen.
Einbettungen speichern: Speichern Sie die erstellten Einbettungen in einer Vektordatenbank. Fügen Sie außerdem nützliche Metadaten und Rohinhalte hinzu, um weitere Verweise zu erstellen.
Beispielcode
loader.ts: Nur-Text als Quelleingabe.import * as fs from "node:fs"; export function loadTextFile(path: string): string { return fs.readFileSync(path, "utf-8"); }splitter.ts: Teilen Sie Text in Blöcke mit einer Überlappung auf.// split words by delimiters. const delimiters = [" ", "\t", "\r", "\n"]; export function split(content: string, length: number, overlap: number): Array<string> { const results = new Array<string>(); let cursor = 0, curChunk = 0; results.push(""); while(cursor < content.length) { const curChar = content[cursor]; if (delimiters.includes(curChar)) { // check chunk length while (curChunk < results.length && results[curChunk].length >= length) { curChunk ++; } for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } if (results[results.length - 1].length >= length - overlap) { results.push(""); } } else { // append for (let i = curChunk; i < results.length; i++) { results[i] += curChar; } } cursor ++; } while (curChunk < results.length - 1) { results.pop(); } return results; }embeddings.ts: Verwenden Sie die KI-BibliothekOpenAIEmbeddingsvon Teams, um Einbettungen zu erstellen.import { OpenAIEmbeddings } from "@microsoft/teams-ai"; const embeddingClient = new OpenAIEmbeddings({ azureApiKey: "<your-aoai-key>", azureEndpoint: "<your-aoai-endpoint>", azureDeployment: "<your-embedding-deployment, e.g., text-embedding-ada-002>" }); export async function createEmbeddings(content: string): Promise<number[]> { const response = await embeddingClient.createEmbeddings(content); return response.output[0]; }searchIndex.ts: Erstellen eines Azure AI Search-Indexes.import { SearchIndexClient, AzureKeyCredential, SearchIndex } from "@azure/search-documents"; const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const indexDef: SearchIndex = { name: indexName, fields: [ { type: "Edm.String", name: "id", key: true, }, { type: "Edm.String", name: "content", searchable: true, }, { type: "Edm.String", name: "filepath", searchable: true, filterable: true, }, { type: "Collection(Edm.Single)", name: "contentVector", searchable: true, vectorSearchDimensions: 1536, vectorSearchProfileName: "default" } ], vectorSearch: { algorithms: [{ name: "default", kind: "hnsw" }], profiles: [{ name: "default", algorithmConfigurationName: "default" }] }, semanticSearch: { defaultConfigurationName: "default", configurations: [{ name: "default", prioritizedFields: { contentFields: [{ name: "content" }] } }] } }; export async function createNewIndex(): Promise<void> { const client = new SearchIndexClient(endpoint, new AzureKeyCredential(apiKey)); await client.createIndex(indexDef); }searchIndexer.ts: Hochladen erstellter Einbettungen und anderer Felder in den Azure KI-Suchindex.import { AzureKeyCredential, SearchClient } from "@azure/search-documents"; export interface Doc { id: string, content: string, filepath: string, contentVector: number[] } const endpoint = "<your-search-endpoint>"; const apiKey = "<your-search-key>"; const indexName = "<your-index-name>"; const searchClient: SearchClient<Doc> = new SearchClient<Doc>(endpoint, indexName, new AzureKeyCredential(apiKey)); export async function indexDoc(doc: Doc): Promise<boolean> { const response = await searchClient.mergeOrUploadDocuments([doc]); return response.results.every((result) => result.succeeded); }index.ts: Orchestrieren Sie die oben genannten Komponenten.import { createEmbeddings } from "./embeddings"; import { loadTextFile } from "./loader"; import { createNewIndex } from "./searchIndex"; import { indexDoc } from "./searchIndexer"; import { split } from "./splitter"; async function main() { // Only need to call once await createNewIndex(); // local files as source input const files = [`${__dirname}/data/A.md`, `${__dirname}/data/A.md`]; for (const file of files) { // load file const fullContent = loadTextFile(file); // split into chunks const contents = split(fullContent, 1000, 100); let partIndex = 0; for (const content of contents) { partIndex ++; // create embeddings const embeddings = await createEmbeddings(content); // upload to index await indexDoc({ id: `${file.replace(/[^a-z0-9]/ig, "")}___${partIndex}`, content: content, filepath: file, contentVector: embeddings, }); } } } main().then().finally();
Azure AI Search als Datenquelle
In diesem Abschnitt erfahren Sie folgendes:
- Fügen Sie Ihr Dokument über den Azure OpenAI-Dienst zu Azure AI Search hinzu.
- Verwenden Sie den Azure AI Search-Index als Datenquelle in der RAG-App.
Hinzufügen eines Dokuments zu Azure AI Search
Hinweis
Dieser Ansatz erstellt eine End-to-End-Chat-API, die als KI-Modell bezeichnet wird. Sie können auch den zuvor erstellten Index als Datenquelle verwenden und die KI-Bibliothek von Teams verwenden, um den Abruf und die Eingabeaufforderung anzupassen.
Sie können Ihre Wissensdokumente in Azure AI Search Service erfassen und einen Vektorindex mit Azure OpenAI für Ihre Daten erstellen. Nach der Erfassung können Sie den Index als Datenquelle verwenden.
Bereiten Sie Ihre Daten in Azure Blob Storage vor.
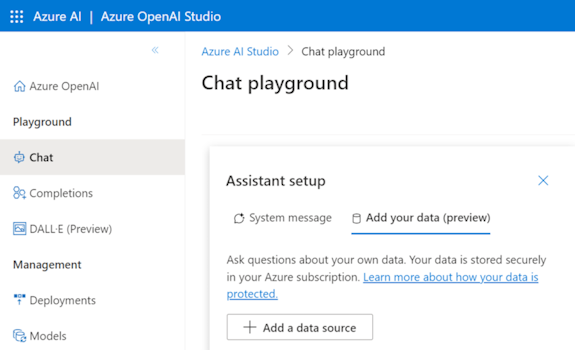
Wählen Sie in Azure OpenAI Studio die Option Datenquelle hinzufügen aus.
Aktualisieren Sie die erforderlichen Felder.
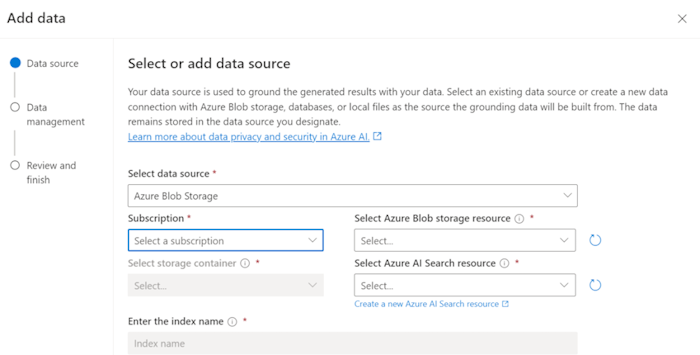
Wählen Sie Weiter aus.
Die Seite Datenverwaltung wird angezeigt.
Aktualisieren Sie die erforderlichen Felder.
Wählen Sie Weiter aus.
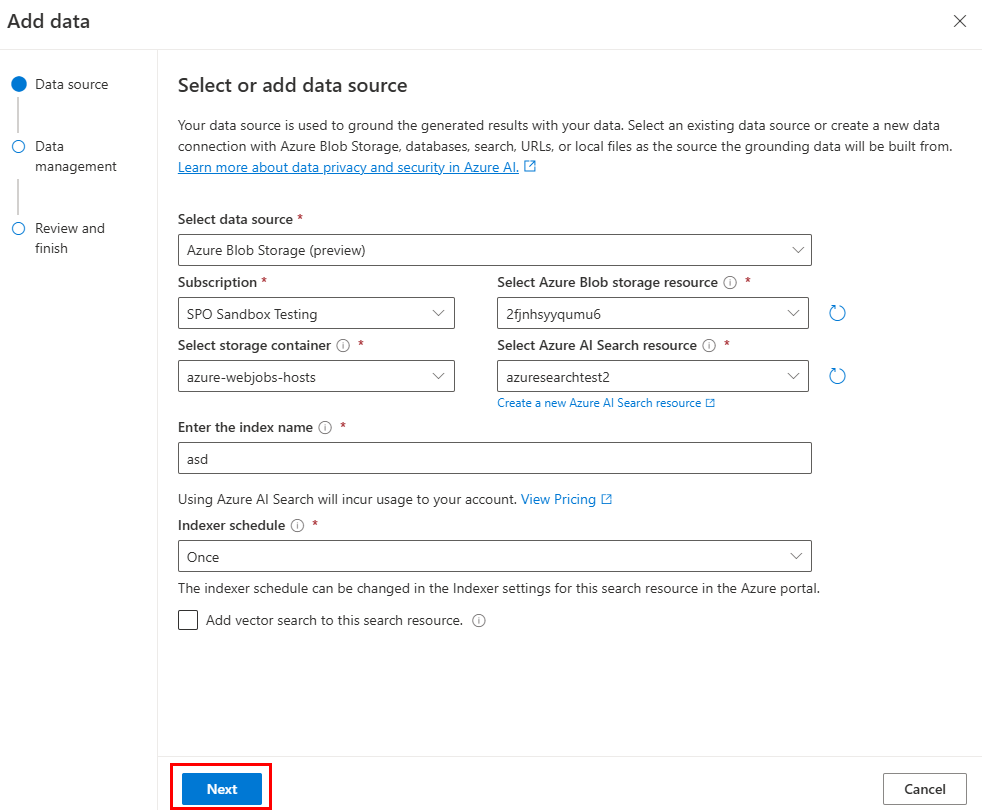
Aktualisieren Sie die erforderlichen Felder. Wählen Sie Weiter aus.
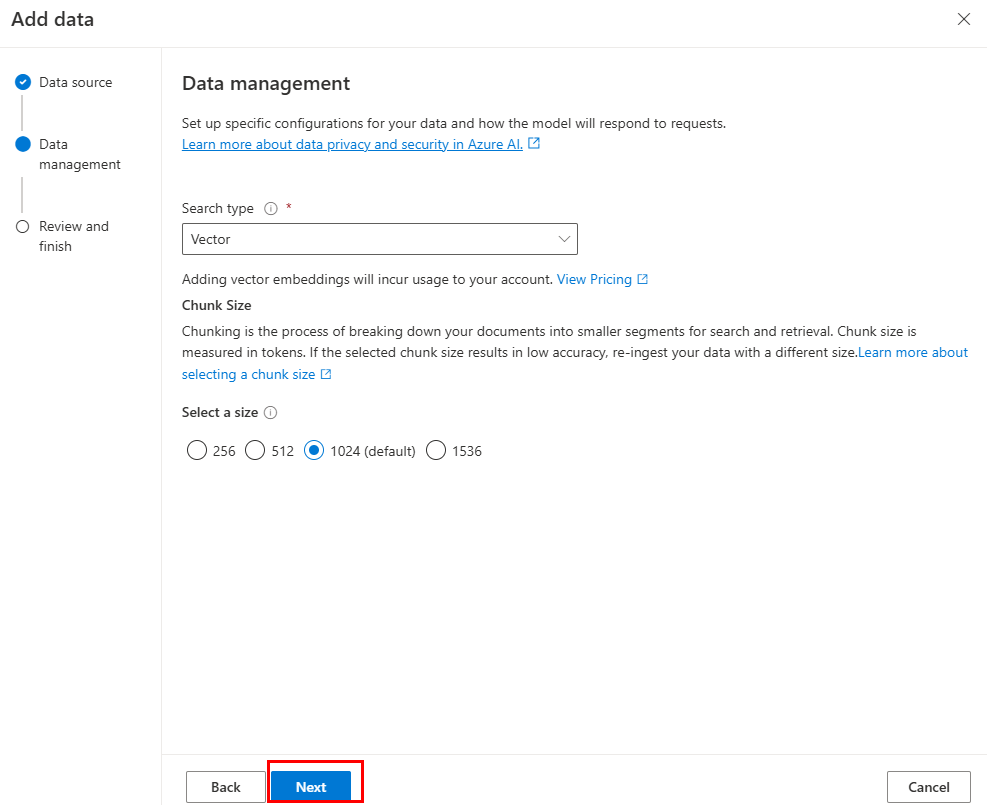
Wählen Sie Speichern und schließen aus.
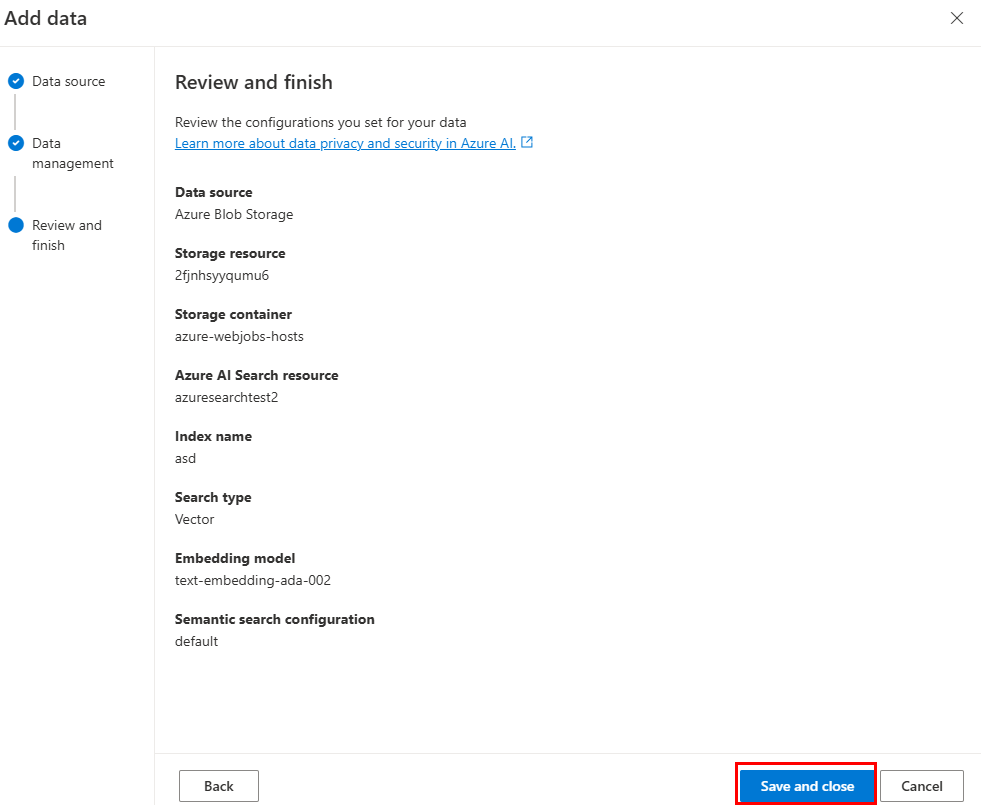
Verwenden der Azure AI Search-Indexdatenquelle
Nach dem Erfassen von Daten in Azure AI Search können Sie eigene DataSource Implementieren, um Daten aus dem Suchindex abzurufen.
const { AzureKeyCredential, SearchClient } = require("@azure/search-documents");
const { DataSource, Memory, OpenAIEmbeddings, Tokenizer } = require("@microsoft/teams-ai");
const { TurnContext } = require("botbuilder");
// Define the interface for document
class Doc {
constructor(id, content, filepath) {
this.id = id;
this.content = content; // searchable
this.filepath = filepath;
}
}
// Azure OpenAI configuration
const aoaiEndpoint = "<your-aoai-endpoint>";
const aoaiApiKey = "<your-aoai-key>";
const aoaiDeployment = "<your-embedding-deployment, e.g., text-embedding-ada-002>";
// Azure AI Search configuration
const searchEndpoint = "<your-search-endpoint>";
const searchApiKey = "<your-search-apikey>";
const searchIndexName = "<your-index-name>";
// Define MyDataSource class implementing DataSource interface
class MyDataSource extends DataSource {
constructor() {
super();
this.name = "my-datasource";
this.embeddingClient = new OpenAIEmbeddings({
azureEndpoint: aoaiEndpoint,
azureApiKey: aoaiApiKey,
azureDeployment: aoaiDeployment
});
this.searchClient = new SearchClient(searchEndpoint, searchIndexName, new AzureKeyCredential(searchApiKey));
}
async renderData(context, memory, tokenizer, maxTokens) {
// use user input as query
const input = memory.getValue("temp.input");
// generate embeddings
const embeddings = (await this.embeddingClient.createEmbeddings(input)).output[0];
// query Azure AI Search
const response = await this.searchClient.search(input, {
select: [ "id", "content", "filepath" ],
searchFields: ["rawContent"],
vectorSearchOptions: {
queries: [{
kind: "vector",
fields: [ "contentVector" ],
vector: embeddings,
kNearestNeighborsCount: 3
}]
},
queryType: "semantic",
top: 3,
semanticSearchOptions: {
// your semantic configuration name
configurationName: "default",
}
});
// Add documents until you run out of tokens
let length = 0, output = '';
for await (const result of response.results) {
// Start a new doc
let doc = `${result.document.content}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append doc to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
}
Hinzufügen weiterer APIs für die benutzerdefinierte API als Datenquelle
Führen Sie die folgenden Schritte aus, um den benutzerdefinierten Engine-Agent aus der Vorlage für benutzerdefinierte API mit weiteren APIs zu erweitern.
Aktualisieren Sie
./appPackage/apiSpecificationFile/openapi.*.Kopieren Sie den entsprechenden Teil der API, die Sie aus Ihrer Spezifikation hinzufügen möchten, und fügen Sie an an
./appPackage/apiSpecificationFile/openapi.*an.Aktualisieren Sie
./src/prompts/chat/actions.json.Aktualisieren Sie die erforderlichen Informationen und Eigenschaften für Pfad, Abfrage und Text für die API im folgenden Objekt:
{ "name": "${{YOUR-API-NAME}}", "description": "${{YOUR-API-DESCRIPTION}}", "parameters": { "type": "object", "properties": { "query": { "type": "object", "properties": { "${{YOUR-PROPERTY-NAME}}": { "type": "${{YOUR-PROPERTY-TYPE}}", "description": "${{YOUR-PROPERTY-DESCRIPTION}}", } // You can add more query properties here } }, "path": { // Same as query properties }, "body": { // Same as query properties } } } }Aktualisieren Sie
./src/adaptiveCards.Erstellen Sie eine neue Datei mit dem Namen
${{YOUR-API-NAME}}.json, und füllen Sie die adaptive Karte für die API-Antwort Ihrer API aus.Aktualisieren Sie die
./src/app/app.jsDatei.Fügen Sie den folgenden Code vor hinzu
module.exports = app;:app.ai.action(${{YOUR-API-NAME}}, async (context: TurnContext, state: ApplicationTurnState, parameter: any) => { const client = await api.getClient(); const path = client.paths[${{YOUR-API-PATH}}]; if (path && path.${{YOUR-API-METHOD}}) { const result = await path.${{YOUR-API-METHOD}}(parameter.path, parameter.body, { params: parameter.query, }); const card = generateAdaptiveCard("../adaptiveCards/${{YOUR-API-NAME}}.json", result); await context.sendActivity({ attachments: [card] }); } else { await context.sendActivity("no result"); } return "result"; });
Microsoft 365 als Datenquelle
Erfahren Sie, wie Sie die Microsoft Graph Search-API verwenden, um Microsoft 365-Inhalte als Datenquelle für die RAG-App abzufragen. Weitere Informationen zur Microsoft Graph-Such-API finden Sie unter Verwenden der Microsoft Search-API zum Durchsuchen von OneDrive- und SharePoint-Inhalten.
Voraussetzung: Sie müssen einen Graph-API-Client erstellen und ihm den Berechtigungsbereich für den Files.Read.All Zugriff auf SharePoint- und OneDrive-Dateien, -Ordner, -Seiten und -Nachrichten gewähren.
Datenerfassung
Die Microsoft Graph-Such-API, die SharePoint-Inhalte durchsuchen kann, ist verfügbar. Daher müssen Sie nur sicherstellen, dass Ihr Dokument auf SharePoint oder OneDrive hochgeladen wird, ohne dass eine zusätzliche Datenerfassung erforderlich ist.
Hinweis
SharePoint Server indiziert eine Datei nur, wenn ihre Dateierweiterung auf der Seite Dateitypen verwalten aufgeführt ist. Eine vollständige Liste der unterstützten Dateierweiterungen finden Sie unter standardindizierte Dateinamenerweiterungen und analysierte Dateitypen in SharePoint Server und SharePoint in Microsoft 365.
Datenquellenimplementierung
Ein Beispiel für die Suche nach den Textdateien in SharePoint und OneDrive ist wie folgt:
import {
DataSource,
Memory,
RenderedPromptSection,
Tokenizer,
} from "@microsoft/teams-ai";
import { TurnContext } from "botbuilder";
import { Client, ResponseType } from "@microsoft/microsoft-graph-client";
export class GraphApiSearchDataSource implements DataSource {
public readonly name = "my-datasource";
public readonly description =
"Searches the graph for documents related to the input";
public client: Client;
constructor(client: Client) {
this.client = client;
}
public async renderData(
context: TurnContext,
memory: Memory,
tokenizer: Tokenizer,
maxTokens: number
): Promise<RenderedPromptSection<string>> {
const input = memory.getValue("temp.input") as string;
const contentResults = [];
const response = await this.client.api("/search/query").post({
requests: [
{
entityTypes: ["driveItem"],
query: {
// Search for markdown files in the user's OneDrive and SharePoint
// The supported file types are listed here:
// https://learn.microsoft.com/sharepoint/technical-reference/default-crawled-file-name-extensions-and-parsed-file-types
queryString: `${input} filetype:txt`,
},
// This parameter is required only when searching with application permissions
// https://learn.microsoft.com/graph/search-concept-searchall
// region: "US",
},
],
});
for (const value of response?.value ?? []) {
for (const hitsContainer of value?.hitsContainers ?? []) {
contentResults.push(...(hitsContainer?.hits ?? []));
}
}
// Add documents until you run out of tokens
let length = 0,
output = "";
for (const result of contentResults) {
const rawContent = await this.downloadSharepointFile(
result.resource.webUrl
);
if (!rawContent) {
continue;
}
let doc = `${rawContent}\n\n`;
let docLength = tokenizer.encode(doc).length;
const remainingTokens = maxTokens - (length + docLength);
if (remainingTokens <= 0) {
break;
}
// Append do to output
output += doc;
length += docLength;
}
return { output, length, tooLong: length > maxTokens };
}
// Download the file from SharePoint
// https://docs.microsoft.com/en-us/graph/api/driveitem-get-content
private async downloadSharepointFile(
contentUrl: string
): Promise<string | undefined> {
const encodedUrl = this.encodeSharepointContentUrl(contentUrl);
const fileContentResponse = await this.client
.api(`/shares/${encodedUrl}/driveItem/content`)
.responseType(ResponseType.TEXT)
.get();
return fileContentResponse;
}
private encodeSharepointContentUrl(webUrl: string): string {
const byteData = Buffer.from(webUrl, "utf-8");
const base64String = byteData.toString("base64");
return (
"u!" + base64String.replace("=", "").replace("/", "_").replace("+", "_")
);
}
}
Siehe auch
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.