Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Dies ist der dritte in einer Reihe von Themen zum skalierbaren Anpassungsdesign. Informationen zu Beginn finden Sie unter "Skalierbares Anpassungsdesign" in Microsoft Dataverse. Das vorherige Thema Der skalierbare Anpassungsentwurf: Datenbanktransaktionen beschrieb, wie Datenbanktransaktionen angewendet werden und welche Auswirkungen sie auf verschiedene Arten von Anpassungen haben.
Wenn Sie gleichzeitige Anforderungen haben, wird die Wahrscheinlichkeit von Kollisionen bei Sperren höher. Je länger die Transaktionen dauern, desto länger werden die Sperren gehalten. Die Wahrscheinlichkeit einer Kollision ist sogar noch höher, und die Gesamtauswirkung auf Endbenutzer wäre größer.
Sie müssen sich auch der vielfältigen Möglichkeiten bewusst sein, wie Aktivitäten auf die Anwendung angewendet werden können, von denen jede Sperren nimmt, die Konflikte mit anderen Aktionen innerhalb des Systems verursachen können. In diesen Fällen verhindert das Sperren Inkonsistenzen von Daten, wenn überlappende Aktionen auf denselben Daten stattfinden.
Einige Schlüsselbereiche, für die man das Design in Betracht ziehen und prüfen sollte, ob man Probleme sieht, sind:
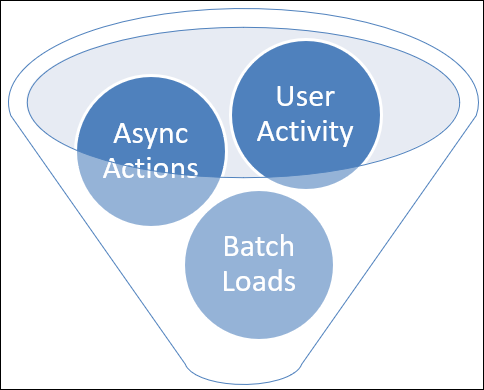
- Benutzergesteuerte Aktivität: Direkt über die Benutzeroberfläche.
- Asynchrone Aktionen: Aktivität, die später als Ergebnis anderer Aktionen auftritt. Wenn diese Aktivität verarbeitet wird, ist zu dem Zeitpunkt, zu dem die initiierende Aktion ausgelöst wird, nicht bekannt.
- Batchaktivitäten: Entweder von Dataverse gesteuert, z. B. Massenlöschaufträge oder serverseitige Synchronisierungsverarbeitung) oder von externen Quellen wie der Integration aus einem anderen System gesteuert.
Parallele asynchrone Operationen
Ein häufiges Missverständnis besteht darin, dass asynchrone Workflows oder Plug-Ins seriell aus einer Warteschlange verarbeitet werden und es keinen Konflikt zwischen ihnen gibt. Dies ist nicht korrekt, da Dataverse mehrere asynchrone Aktivitäten parallel sowohl innerhalb jeder asynchronen Dienstinstanz als auch über asynchrone Dienstinstanzen hinweg verarbeitet, um den Durchsatz zu erhöhen. Jeder asynchrone Dienst ruft tatsächlich Aufträge ab, die in Batches von ca. 20 pro Dienst basierend auf Konfiguration und Last ausgeführt werden sollen.
Wenn Sie mehrere asynchrone Aktivitäten aus demselben Ereignis für denselben Datensatz initiieren, werden sie wahrscheinlich parallel verarbeitet. Da sie den gleichen Datensatz nutzen, ist ein gemeinsames Muster die Aktualisierung auf den gleichen übergeordneten Datensatz; daher ist die Konfliktgelegenheit hoch.
Wenn ein auslösendes Ereignis auftritt, z. B. die Erstellung eines Kontos, kann eine asynchrone Logik in Dataverse Einträge in der AsyncOperation -Entität (Systemauftrag) für jeden Prozess oder jede auszuführende Aktion erstellen. Der Async-Dienst überwacht diese Tabelle, nimmt Wartezeitanforderungen in Batches auf und verarbeitet sie dann. Da die Workflows gleichzeitig ausgelöst werden, werden sie höchstwahrscheinlich im selben Batch aufgenommen und gleichzeitig verarbeitet.
Warum es wichtig ist, Transaktionen zu verstehen
Das Beispiel für die automatische Nummerierung stellt ein Szenario bereit, das veranschaulicht, wie Datenbanktransaktionen und Parallelitätsprobleme beim Entwerfen skalierbarer Anpassungen berücksichtigt werden müssen.
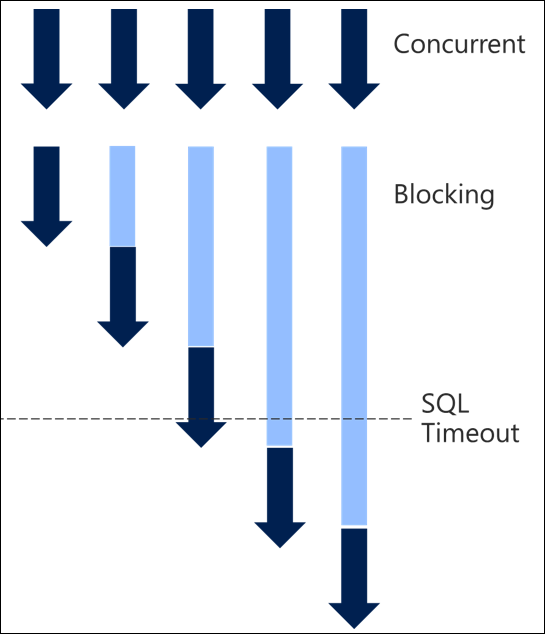
Serialisierung und Timeouts
Hoher Grad an Serialisierung führt in der Regel dazu, dass Blockierungen zu Timeouts und einem schlechten Durchsatz führen. Wenn Sie viele gleichzeitige Anforderungen haben, die serialisiert werden und lange Zeit zur Verarbeitung benötigen, dauert jede Anforderung wiederum immer länger, bis Sie schließlich auf Timeouts stoßen und infolgedessen Fehler auftreten.
Der Timeout des Plugins beginnt mit dem Zeitpunkt, zu dem es gestartet wird. Ein SQL-Timeout wird für die Datenbankanfrage berechnet, so dass eine Abfrage, die lange Zeit wartet, eine Zeitüberschreitung verursachen kann.
Aktionskette
Ebenso wie das Verständnis der spezifischen Abfragen in den direkt ausgelösten Aktivitäten ist es auch erforderlich, zu berücksichtigen, wo eine Kette verwandter Ereignisse auftreten kann.
Jede Nachrichtenanforderung, die in einem Plug-In oder als Schritt in einem synchronen Workflow getätigt wurde, löst nicht nur die direkte Aktion aus, sondern kann auch dazu führen, dass andere synchrone Plug-Ins und Workflows ausgelöst werden. Jede dieser synchronen Aktivitäten erfolgt in derselben Transaktion, wodurch die Lebensdauer dieser Transaktion und möglicher Sperren möglicherweise viel länger verlängert wird, als man realisieren könnte.
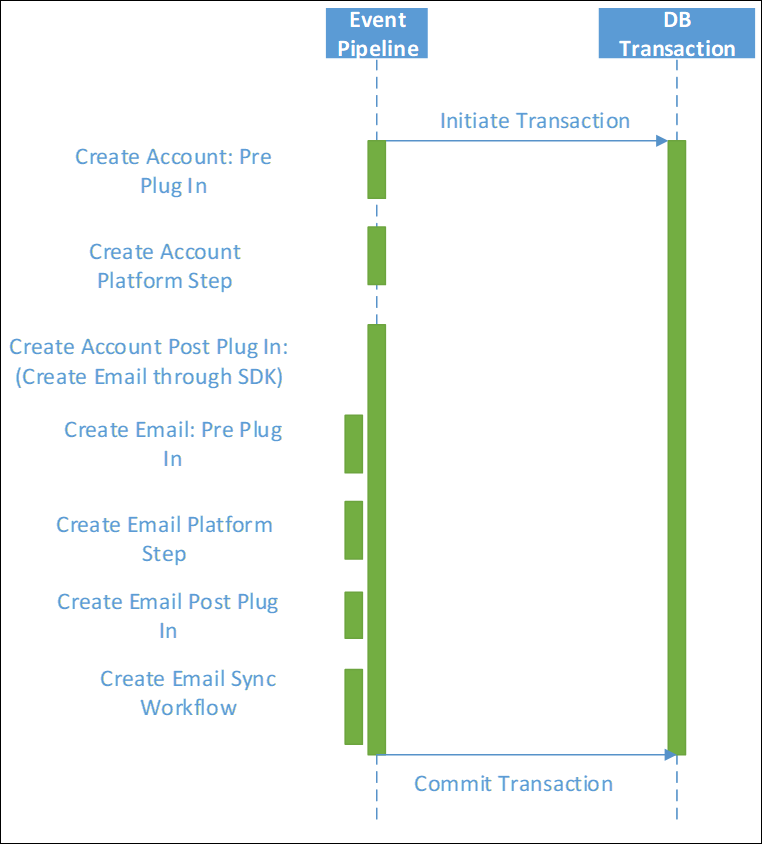
Der Gesamteffekt kann viel größer sein als anfänglich realisiert. Dies kann oft unbeabsichtigt geschehen, wenn mehrere Personen die Implementierung aufbauen oder sich im Laufe der Zeit weiterentwickelt.
Plattformbeschränkungen
Hier können sich die Plattformeinschränkungen einfinden. In Wirklichkeit ist dieses Verhalten genau der Grund, warum es Einschränkungen gibt, um das übergeordnete System zu schützen.
Wenn diese Verzögerung der Verarbeitung auftritt, hat sie unbeabsichtigte Folgen in anderen Bereichen des Systems und auf andere Benutzer. Daher ist es wichtig, diese Art von Aktivität daran zu hindern, die Systemleistung zu beeinträchtigen.
Obwohl die einfache Möglichkeit, die Fehler zu vermeiden, möglicherweise darin besteht, die Plattformeinschränkungen zu entspannen, geht es nicht um die grundlegenderen Auswirkungen auf die Gesamtskalierbarkeit und Leistung des Systems. Dieses Problem muss behoben werden, indem das Verhalten, das die Einschränkungen auslöst, korrigiert und verhindert wird.
Auswirkungen auf die Nutzung
Was sich häufig auch auf die Nutzung auswirkt, ist eine kaskadierende Folge von Auswirkungen dieses Verhaltens.
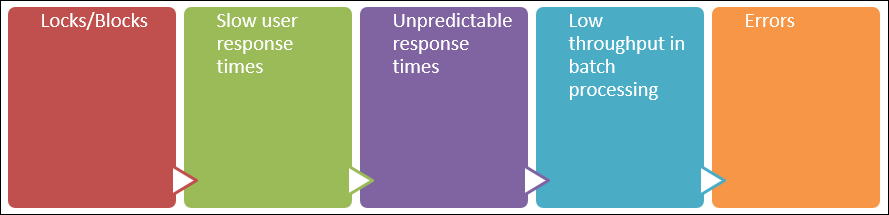
Das anfängliche Problem besteht in Sperren, die daher zu einer Blockierung im System führen. Dies führt zu langsamen Benutzerantwortzeiten, die dann als unvorhersehbare und unzuverlässige Benutzerantwortzeiten verstärkt werden, häufig in einem bestimmten Bereich des Systems.
Im Extremfall oder unter höherer als normaler Belastung kann dies dann in jeder Batch-Verarbeitung im Hintergrund mit schlechtem Durchsatz zum Tragen kommen. Schließlich kann alles in Fehler eskalieren, die im System auftreten.
Benutzer melden oft schlechte und unvorhersehbare Antwortzeiten, wenn sie SQL-Timeoutfehler untersuchen, und haben dabei die Verbindung zwischen diesen als verwandte Probleme nicht erkannt.
Nächste Schritte
Verstehen Sie Entwurfsmuster, die Sie anwenden können (oder vermeiden), um Leistungsprobleme zu minimieren. Weitere Informationen: Skalierbares Anpassungsdesign: Transaktionsentwurfsmuster