Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Bevor Sie die Prozess-Mining-Funktion in Power Automate effektiv einsetzen können, müssen Sie verstehen:
- Datenanforderungen.
- Wo Sie Protokolldaten von Ihrer Anwendung erhalten.
- Wie Sie sich mit einer Datenquelle verbinden.
Hier ist ein kurzes Video zum Hochladen von Daten zur Verwendung mit der Prozess-Mining-Funktion:
Datenanforderungen
Ereignisprotokolle und Aktivitätsprotokolle sind Tabellen, die im Datensatzsystem gespeichert werden und den Zeitpunkt eines Ereignisses oder einer Aktivität erfassen. Beispielsweise werden Aktivitäten, die Sie in Ihrer Customer Relationship Management (CRM)-App ausführen, als Ereignisprotokoll in Ihrer CRM-App gespeichert. Damit Prozess-Mining das Ereignisprotokoll analysieren kann, sind folgende Felder notwendig:
Fall-ID
Die Fall-ID sollte eine Instanz Ihres Prozesses darstellen und ist oft das Objekt, auf das der Prozess reagiert. Dies kann eine „Patienten-ID“ für einen stationären Check-In-Prozess, eine „Auftrags-ID“ für einen Auftragseinreichungsprozess oder eine „Anfrage-ID“ für einen Genehmigungsprozess sein. Diese ID muss für alle Aktivitäten im Protokoll vorhanden sein.
Aktivitätsname
Aktivitäten sind die Schritte Ihres Prozesses, und Aktivitätsnamen beschreiben jeden Schritt. In einem typischen Genehmigungsprozess könnten die Aktivitätsnamen „Anfrage übermitteln“, „Anfrage genehmigt“, „Anfrage abgelehnt“ und „Anfrage überarbeiten“ sein.
Startzeitstempel und Endzeitstempel
Zeitstempel geben die genaue Uhrzeit an, zu der ein Ereignis oder eine Aktivität stattgefunden hat. Ereignisprotokolle haben nur einen Zeitstempel. Dieser gibt die Zeit an, zu der ein Ereignis oder eine Aktivität im System aufgetreten ist. Aktivitätsprotokolle haben zwei Zeitstempel: einen Startzeitstempel und einen Endzeitstempel. Diese zeigen den Beginn und das Ende des Ereignisses oder der Aktivität an.
Sie können Ihre Analyse auch durch die Aufnahme optionaler Attributtypen erweitern:
Ressource
Eine menschliche oder technische Ressource, die ein bestimmtes Ereignis ausführt.
Ereignisebenenattribut
Zusätzliches analytisches Attribut, das je nach Ereignis einen anderen Wert hat, z. B. die Abteilung, die die Aktivität ausführt.
Attribut auf Vorgangsebene (erstes Ereignis)
Das Attribut auf Vorgangsebene ist ein zusätzliches Attribut, das aus analytischer Sicht einen einzelnen Wert pro Vorgang hat (z. B. Rechnungsbetrag in USD). Das aufzunehmende Ereignisprotokoll muss jedoch nicht unbedingt die Konsistenz aufweisen, indem für alle Ereignisse im Ereignisprotokoll der gleiche Wert für das spezifische Attribut vorhanden ist. Dies kann möglicherweise nicht sichergestellt werden, beispielsweise bei Verwendung einer inkrementellen Datenaktualisierung. Power Automate Process Mining nimmt die Daten unverändert auf und speichert alle im Ereignisprotokoll bereitgestellten Werte, verwendet jedoch einen sogenannten Mechanismus zur Attributinterpretation auf Vorgangsebene, um mit den Attributen auf Vorgangsebene zu arbeiten.
Mit anderen Worten: Immer wenn das Attribut für eine bestimmte Funktion verwendet wird, die Werte auf Ereignisebene erfordert (z. B. Filtern auf Ereignisebene), verwendet das Produkt die Werte auf Ereignisebene. Wenn ein Wert auf Vorgangsebene benötigt wird (z. B. Filter auf Vorgangsebene, Ursachenanalyse), wird der interpretierte Wert verwendet, der dem chronologisch ersten Ereignis im Vorgang entnommen wird.
Attribut auf Vorgangsebene (letztes Ereignis)
Dasselbe wie das Attribut auf Vorgangsebene (erstes Ereignis), aber bei der Interpretation auf Vorgangsebene wird der Wert dem chronologisch letzten Ereignis im Vorgang entnommen.
Finanziell pro Ereignis
Fixkosten/Umsatz/numerischer Wert, die bzw. der sich je nach ausgeführter Aktivität ändert, z. B. Kosten für Kurierdienste. Der finanzielle Wert wird als Summe (Mittelwert, Minimum, Maximum) der finanziellen Werte pro Ereignis berechnet.
Finanzen per Vorgang (erstes Ereignis)
Das Attribut „Finanzen per Vorgang“ ist ein zusätzliches numerisches Attribut, das aus analytischer Sicht einen einzelnen Wert pro Vorgang hat (z. B. Rechnungsbetrag in USD). Das aufzunehmende Ereignisprotokoll muss jedoch nicht unbedingt die Konsistenz aufweisen, indem für alle Ereignisse im Ereignisprotokoll der gleiche Wert für das spezifische Attribut vorhanden ist. Dies kann möglicherweise nicht sichergestellt werden, beispielsweise bei Verwendung einer inkrementellen Datenaktualisierung. Power Automate Process Mining nimmt die Daten unverändert auf und speichert alle bereitgestellten Werte im Ereignisprotokoll. Es verwendet jedoch einen sogenannten Mechanismus zur Attributinterpretation auf Vorgangsebene, um mit den Attributen auf Vorgangsebene zu arbeiten.
Mit anderen Worten: Immer wenn das Attribut für eine bestimmte Funktion verwendet wird, die Werte auf Ereignisebene erfordert (z. B. Filtern auf Ereignisebene), verwendet das Produkt die Werte auf Ereignisebene. Wenn ein Wert auf Vorgangsebene benötigt wird (z. B. Filter auf Vorgangsebene, Ursachenanalyse), wird der interpretierte Wert verwendet, der dem chronologisch ersten Ereignis im Vorgang entnommen wird.
Finanzen per Vorgang (letztes Ereignis)
Dasselbe wie „Finanzen per Vorgang (erstes Ereignis)“, aber bei der Interpretation auf Vorgangsebene wird der Wert dem chronologisch letzten Ereignis im Vorgang entnommen.
Wo Sie Protokolldaten von Ihrer Anwendung erhalten
Die Prozess-Mining-Funktion benötigt Ereignisprotokolldaten, um Prozess-Mining durchzuführen. Während viele Tabellen in der Datenbank Ihrer Anwendung den aktuellen Status der Daten enthalten, enthalten sie möglicherweise keine historische Aufzeichnung der aufgetretenen Ereignisse, was das erforderliche Ereignisprotokollformat ist. Glücklicherweise wird diese historische Aufzeichnung in vielen größeren Anwendungen oft in einer bestimmten Tabelle gespeichert. Beispielsweise behalten viele Dynamics-Anwendungen diesen Datensatz in der Tabelle „Aktivitäten“. Andere Anwendungen wie SAP oder Salesforce haben ähnliche Konzepte, aber der Name kann anders sein.
In diesen Tabellen, die historische Datensätze protokollieren, kann die Datenstruktur komplex sein. Möglicherweise müssen Sie die Protokolltabelle mit anderen Tabellen in der Anwendungsdatenbank verknüpfen, um bestimmte IDs oder Namen zu erhalten. Außerdem werden nicht alle Ereignisse, an denen Sie interessiert sind, protokolliert. Gegebenenfalls müssen Sie definieren, welche Ereignisse beibehalten oder herausgefiltert werden sollen. Wenn Sie Hilfe benötigen, wenden Sie sich an das IT-Team, das diese Anwendung verwaltet, um mehr zu erfahren.
Mit einer Datenquelle verbinden
Der Vorteil einer direkten Verbindung mit einer Datenbank besteht darin, den Prozessbericht mit den neuesten Daten aus Datenquelle auf dem neuesten Stand zu halten.
Power Query unterstützt eine Vielzahl von Konnektoren, die der Prozess-Mining-Funktion die Möglichkeit bieten, Daten aus der entsprechenden Datenquelle zu verbinden und zu importieren. Zu den gängigen Konnektoren gehören Text/CSV, Microsoft Dataverse, und SQL Server-Datenbank. Wenn Sie eine Anwendung wie SAP oder Salesforce verwenden, können Sie möglicherweise direkt eine Verbindung zu diesen Datenquellen über deren Konnektoren herstellen. Informationen zu unterstützten Konnektoren und deren Verwendung finden Sie unter Konnektoren in Power Query.
Die Prozess-Mining-Funktion mit dem Text-/CSV-Connector testen
Eine einfache Möglichkeit, die Prozess-Mining-Funktion auszuprobieren, unabhängig davon, wo sich Ihr Datenquelle befindet, ist der Text/CSV-Connector. Möglicherweise müssen Sie mit Ihrem Datenbankadministrator zusammenarbeiten, um ein kleines Beispiel des Ereignisprotokolls als CSV-Datei zu exportieren. Sobald Sie über die CSV-Datei verfügen, können Sie die Prozess-Mining-Funktion mithilfe der folgenden Schritte im Auswahlbildschirm Datenquelle in den Prozessratgeber importieren.
Notiz
Sie müssen OneDrive für Business besitzen, um den Text/CSV-Connector zu verwenden. Wenn Sie OneDrive für Business nicht haben, erwägen Sie die Verwendung von Leere Tabelle statt Text/CSV, wie im folgenden Schritt 3. Mit Leere Tabelle können Sie nicht so viele Datensätze importieren.
Erstellen Sie auf der Prozess-Mining-Startseite einen Prozess, indem Sie Hier beginnen auswählen.
Geben Sie einen Prozessnamen ein und wählen Sie dann Verbindung erstellen.
Auf der Anzeige Wählen Sie Datenquelle wählen Sie Alle Kategorien>ext/CSV.
Wählen Sie OneDrive durchsuchen. Möglicherweise müssen Sie sich authentifizieren.
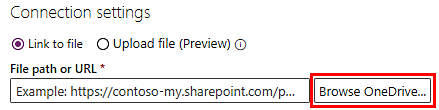
Laden Sie Ihr Ereignisprotokoll hoch, indem Sie das Symbol Hochladen oben rechts und dann Dateien auswählen.
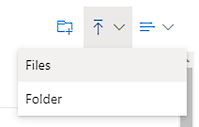
Laden Sie Ihr Ereignisprotokoll hoch, wählen Sie Ihre Datei aus der Liste aus und wählen Sie dann Öffnen, um diese Datei zu verwenden.
Verwenden des Dataflow-Connectors
Der Dataflow-Connector wird nicht unterstützt Microsoft Power Platform. Der vorhandene Datenfluss kann nicht als Datenquelle für Power Automate Prozess-Mining verwendet werden.
Den Dataverse-Konnektor verwenden
Der Dataverse-Connector wird in Microsoft Power Platform nicht unterstützt. Sie müssen sich über den OData-Connector damit verbinden, was einige weitere Schritte erfordert.
Stellen Sie sicher, dass Sie Zugriff auf die Dataverse-Umgebung haben.
Sie benötigen die Umgebungs-URL der Dataverse-Umgebung, mit der Sie eine Verbindung herstellen möchten. Normalerweise sieht es so aus:
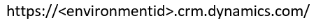
Um zu erfahren, wie Sie Ihre URL finden, gehen Sie zu Ihre Dataverse-Umgebungs-URL finden.
Wählen Sie im Bildschirm Power Query – Datenquellen auswählen die Option OData.
Geben Sie in das URL-Textfeld API/data/v9.2 am Ende der URL ein, so sieht es aus:
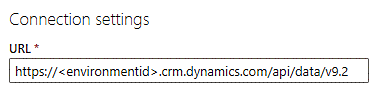
Wählen Sie unter Verbindungsanmeldinformationen die Option Organisationskonto im Feld Authentifizierungsart.
Wählen Sie Anmelden und geben Sie Ihre Anmeldeinformationen.
Wählen Sie Weiter.
Erweiteren Sie den Ordner OData. Sie sollten alle Dataverse-Tabellen in dieser Umgebung angezeigt bekommen. Als Beispiel heißt die Tabelle Aktivitäten Aktivitätszeiger.
Aktivieren Sie das Kontrollkästchen neben der Tabelle, die Sie importieren möchten, und wählen Sie dann Weiter.