Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird die Zuordnung von Datenansichten erläutert, und es wird beschrieben, wie Datenrollen verwendet werden, um verschiedene Arten von Visuals zu erstellen. Es wird erläutert, wie bedingte Anforderungen für Datenrollen und die verschiedenen dataMappings-Typen angegeben werden.
Jede gültige Zuordnung erzeugt eine Datenansicht. Unter bestimmten Bedingungen können Sie mehrere Datenzuordnungen bereitstellen. Folgende Zuordnungsoptionen werden unterstützt:
"dataViewMappings": [
{
"conditions": [ ... ],
"categorical": { ... },
"single": { ... },
"table": { ... },
"matrix": { ... }
}
]
Power BI erstellt nur dann eine Zuordnung zu einer Datenansicht, wenn die gültige Zuordnung ebenfalls in dataViewMappings definiert ist.
Anders ausgedrückt: categorical kann in dataViewMappings definiert werden, andere Zuordnungen wie table oder single jedoch möglicherweise nicht. In diesem Fall erzeugt Power BI eine Datenansicht mit einer einzelnen categorical-Zuordnung, während table und andere Zuordnungen nicht definiert bleiben. Beispiel:
"dataViewMappings": [
{
"categorical": {
"categories": [ ... ],
"values": [ ... ]
},
"metadata": { ... }
}
]
Bedingungen
Im conditions-Abschnitt werden Regeln für eine bestimmte Datenzuordnung festgelegt. Wenn die Daten mit einer der beschriebenen Bedingungsgruppen übereinstimmen, werden die Daten vom Visual als gültig betrachtet.
Sie können für jedes Feld einen minimalen und einen maximalen Wert angeben. Diese Werte stellen die Anzahl von Feldern dar, die an die Datenrolle gebunden werden können.
Hinweis
Wenn eine Datenrolle in der Bedingung ausgelassen wird, kann sie über eine beliebige Anzahl von Feldern verfügen.
Im folgenden Beispiel ist category auf ein Datenfeld und measure auf zwei Datenfelder beschränkt.
"conditions": [
{ "category": { "max": 1 }, "measure": { "max": 2 } },
]
Sie können auch mehrere Bedingungen für eine Datenrolle festlegen. In diesem Fall sind die Daten gültig, wenn eine der Bedingungen erfüllt ist.
"conditions": [
{ "category": { "min": 1, "max": 1 }, "measure": { "min": 2, "max": 2 } },
{ "category": { "min": 2, "max": 2 }, "measure": { "min": 1, "max": 1 } }
]
Im vorherigen Beispiel ist eine der beiden folgenden Bedingungen erforderlich:
- Genau ein category-Datenfeld und zwei Measures
- Genau zwei Kategorien und genau ein Measure
Einzelne Datenzuordnung
Die einzelne Datenzuordnung ist die einfachste Form der Datenzuordnung. Sie akzeptiert ein einzelnes Measurefeld und gibt die Summe zurück. Wenn das Feld numerisch ist, wird die Summe zurückgegeben. Andernfalls wird die Anzahl der eindeutigen Werte ermittelt.
Wenn Sie eine einzelne Datenzuordnung verwenden möchten, definieren Sie den Namen der Datenrolle, die Sie zuordnen möchten. Diese Zuordnung funktioniert nur mit einem einzelnen Measurefeld. Wenn ein zweites Feld zugewiesen ist, wird keine Datenansicht generiert. Es wird daher empfohlen, eine Bedingung bereitzustellen, die die Daten auf ein einzelnes Feld beschränkt.
Hinweis
Diese Datenzuordnung kann nicht in Verbindung mit einer anderen Datenzuordnung verwendet werden. Sie soll Daten auf einen einzelnen numerischen Wert reduzieren.
Beispiel:
{
"dataRoles": [
{
"displayName": "Y",
"name": "Y",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"conditions": [
{
"Y": {
"max": 1
}
}
],
"single": {
"role": "Y"
}
}
]
}
Die resultierende Datenansicht kann immer noch die anderen Zuordnungstypen wie „table“ oder „categorical“ enthalten. Jede Zuordnung enthält jedoch nur den einzelnen Wert. Es empfiehlt sich, nur auf den Wert in der einzelnen Zuordnung zuzugreifen.
{
"dataView": [
{
"metadata": null,
"categorical": null,
"matrix": null,
"table": null,
"tree": null,
"single": {
"value": 94163140.3560001
}
}
]
}
Im folgenden Code-Beispiel wird die einfache Datenzuordnung in der Ansicht verarbeitet:
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewSingle = powerbi.DataViewSingle;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private valueText: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.valueText = document.createElement("p");
this.target.appendChild(this.valueText);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const singleDataView: DataViewSingle = dataView.single;
if (!singleDataView ||
!singleDataView.value ) {
return
}
this.valueText.innerText = singleDataView.value.toString();
}
}
Das vorherige Code-Beispiel führt zur Anzeige eines einzelnen Werts aus Power BI:
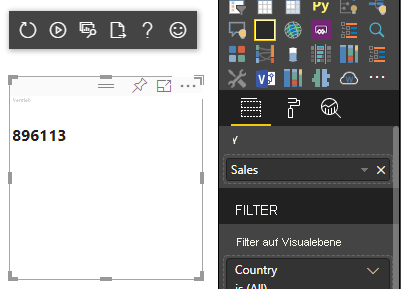
Kategorische Datenzuordnung
Die kategorische Datenzuordnung wird verwendet, um unabhängige Datengruppierungen oder Datenkategorien abzurufen. Die Kategorien können auch mithilfe von „group by“ in der Datenzuordnung gruppiert werden.
Grundlegende kategorische Datenzuordnung
Beachten Sie die folgenden Datenrollen und Zuordnungen:
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
}
],
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" }
},
"values": {
"select": [
{ "bind": { "to": "measure" } }
]
}
}
}
Das vorherige Beispiel kann wie folgt interpretiert werden: Die category-Datenrolle wird so zugeordnet, dass für jedes Feld, das in category gezogen wird, die Daten categorical.categories zugeordnet werden. Außerdem wird die measure-Datenrolle categorical.values zugeordnet.
- for...in: Schließt alle Elemente in dieser Datenrolle in die Datenabfrage ein.
- bind...to: Erzeugt dasselbe Ergebnis wie for...in, erwartet jedoch, dass die Datenrolle über eine Bedingung verfügt, die sie auf ein einzelnes Feld beschränkt.
Gruppieren von Kategoriedaten
Im nächsten Beispiel werden die gleichen beiden Datenrollen wie im vorherigen Beispiel verwendet, und es werden zwei weitere Datenrollen mit den Namen grouping und measure2 hinzugefügt.
"dataRoles":[
{
"displayName": "Category",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Y Axis",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Grouping with",
"name": "grouping",
"kind": "Grouping"
},
{
"displayName": "X Axis",
"name": "measure2",
"kind": "Grouping"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "grouping",
"select": [{
"bind": {
"to": "measure"
}
},
{
"bind": {
"to": "measure2"
}
}
]
}
}
}
}
]
Der Unterschied zwischen dieser Zuordnung und der grundlegenden Zuordnung besteht in der Zuordnung von categorical.values. Wenn Sie die Datenrollen measure und measure2 der Datenrolle grouping zuordnen, ist es möglich, die x-Achse und die y-Achse entsprechend zu skalieren.
Gruppieren von hierarchischen Daten
Im nächsten Beispiel werden die kategorischen Daten verwendet, um eine Hierarchie zu erstellen, die zur Unterstützung von Drill-down-Aktionen verwendet werden kann.
Das folgende Beispiel zeigt die Datenrollen und Zuordnungen an:
"dataRoles": [
{
"displayName": "Categories",
"name": "category",
"kind": "Grouping"
},
{
"displayName": "Measures",
"name": "measure",
"kind": "Measure"
},
{
"displayName": "Series",
"name": "series",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"categorical": {
"categories": {
"for": {
"in": "category"
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
]
}
}
}
}
]
Betrachten Sie folgenden kategorischen Daten:
| Land/Region | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|
| USA | x | x | 650 | 350 |
| Canada | x | 630 | 490 | x |
| Mexiko | 645 | x | x | x |
| UK | x | x | 831 | x |
Power BI erstellt eine kategorische Datenansicht mit den folgenden Kategorien.
{
"categorical": {
"categories": [
{
"source": {...},
"values": [
"Canada",
"USA",
"UK",
"Mexico"
],
"identity": [...],
"identityFields": [...],
}
]
}
}
Jede category-wird einer Gruppe von values zugeordnet. Jede dieser values ist nach dem Wert series gruppiert, der als Jahre ausgedrückt wird.
Beispielsweise stellt jedes values-Array ein Jahr dar.
Außerdem verfügt jedes values-Array über vier Werte: „Canada“, „USA“, „UK“ und „Mexico“.
{
"values": [
// Values for year 2013
{
"source": {...},
"values": [
null, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
645 // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2014
{
"source": {...},
"values": [
630, // Value for `Canada` category
null, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2015
{
"source": {...},
"values": [
490, // Value for `Canada` category
650, // Value for `USA` category
831, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
},
// Values for year 2016
{
"source": {...},
"values": [
null, // Value for `Canada` category
350, // Value for `USA` category
null, // Value for `UK` category
null // Value for `Mexico` category
],
"identity": [...],
}
]
}
Das folgende Code-Beispiel beschreibt die Verarbeitung einer kategorischen Datenansichtszuordnung. In diesem Beispiel wird die hierarchische Struktur Country/Region > Year > Value erstellt.
"use strict";
import powerbi from "powerbi-visuals-api";
import DataView = powerbi.DataView;
import DataViewCategorical = powerbi.DataViewCategorical;
import DataViewValueColumnGroup = powerbi.DataViewValueColumnGroup;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private categories: HTMLElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.categories = document.createElement("pre");
this.target.appendChild(this.categories);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const categoricalDataView: DataViewCategorical = dataView.categorical;
if (!categoricalDataView ||
!categoricalDataView.categories ||
!categoricalDataView.categories[0] ||
!categoricalDataView.values) {
return;
}
// Categories have only one column in data buckets
// To support several columns of categories data bucket, iterate categoricalDataView.categories array.
const categoryFieldIndex = 0;
// Measure has only one column in data buckets.
// To support several columns on data bucket, iterate years.values array in map function
const measureFieldIndex = 0;
let categories: PrimitiveValue[] = categoricalDataView.categories[categoryFieldIndex].values;
let values: DataViewValueColumnGroup[] = categoricalDataView.values.grouped();
let data = {};
// iterate categories/countries-regions
categories.map((category: PrimitiveValue, categoryIndex: number) => {
data[category.toString()] = {};
// iterate series/years
values.map((years: DataViewValueColumnGroup) => {
if (!data[category.toString()][years.name] && years.values[measureFieldIndex].values[categoryIndex]) {
data[category.toString()][years.name] = []
}
if (years.values[0].values[categoryIndex]) {
data[category.toString()][years.name].push(years.values[measureFieldIndex].values[categoryIndex]);
}
});
});
this.categories.innerText = JSON.stringify(data, null, 6);
console.log(data);
}
}
Das Ergebnis sieht wie die folgende Darstellung aus:
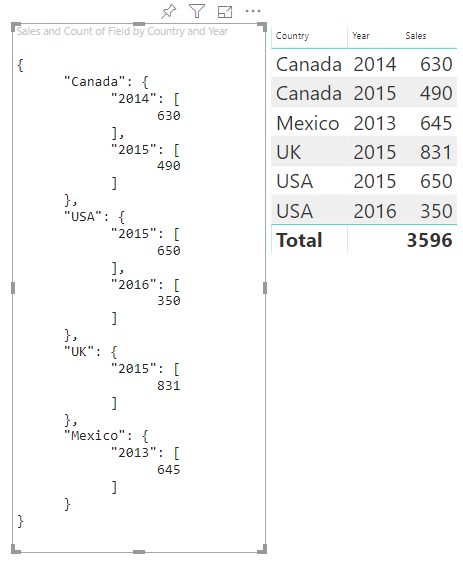
Zuordnungstabellen
Die Datenansicht table ist im Wesentlichen eine Liste von Datenpunkten, in denen numerische Datenpunkte aggregiert werden können.
Verwenden Sie beispielsweise die gleichen Daten wie im vorherigen Abschnitt, aber mit den folgenden Funktionen:
"dataRoles": [
{
"displayName": "Column",
"name": "column",
"kind": "Grouping"
},
{
"displayName": "Value",
"name": "value",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"table": {
"rows": {
"select": [
{
"for": {
"in": "column"
}
},
{
"for": {
"in": "value"
}
}
]
}
}
}
]
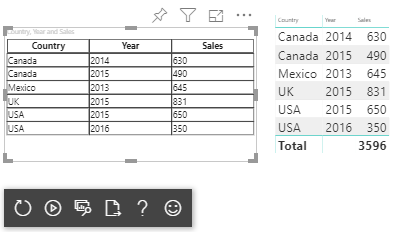
Visualisieren Sie die Datenansicht „table“ wie folgt:
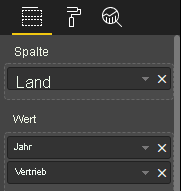
| Land/Region | Jahr | Sales |
|---|---|---|
| USA | 2016 | 100 |
| USA | 2015 | 50 |
| Canada | 2015 | 200 |
| Canada | 2015 | 50 |
| Mexiko | 2013 | 300 |
| UK | 2014 | 150 |
| USA | 2015 | 75 |
Datenbindung:
In Power BI werden die Daten als Tabellendatenansicht angezeigt. Gehen Sie nicht davon aus, dass die Daten sortiert wurden.
{
"table" : {
"columns": [...],
"rows": [
[
"Canada",
2014,
630
],
[
"Canada",
2015,
490
],
[
"Mexico",
2013,
645
],
[
"UK",
2014,
831
],
[
"USA",
2015,
650
],
[
"USA",
2016,
350
]
]
}
}
Wählen Sie das gewünschte Feld und anschließend Summe aus, um die Daten zu aggregieren.
Codebeispiel für die Verarbeitung der Tabellendatenansichtszuordnung
"use strict";
import "./../style/visual.less";
import powerbi from "powerbi-visuals-api";
// ...
import DataViewMetadataColumn = powerbi.DataViewMetadataColumn;
import DataViewTable = powerbi.DataViewTable;
import DataViewTableRow = powerbi.DataViewTableRow;
import PrimitiveValue = powerbi.PrimitiveValue;
// standard imports
// ...
export class Visual implements IVisual {
private target: HTMLElement;
private host: IVisualHost;
private table: HTMLParagraphElement;
constructor(options: VisualConstructorOptions) {
// constructor body
this.target = options.element;
this.host = options.host;
this.table = document.createElement("table");
this.target.appendChild(this.table);
// ...
}
public update(options: VisualUpdateOptions) {
const dataView: DataView = options.dataViews[0];
const tableDataView: DataViewTable = dataView.table;
if (!tableDataView) {
return
}
while(this.table.firstChild) {
this.table.removeChild(this.table.firstChild);
}
//draw header
const tableHeader = document.createElement("th");
tableDataView.columns.forEach((column: DataViewMetadataColumn) => {
const tableHeaderColumn = document.createElement("td");
tableHeaderColumn.innerText = column.displayName
tableHeader.appendChild(tableHeaderColumn);
});
this.table.appendChild(tableHeader);
//draw rows
tableDataView.rows.forEach((row: DataViewTableRow) => {
const tableRow = document.createElement("tr");
row.forEach((columnValue: PrimitiveValue) => {
const cell = document.createElement("td");
cell.innerText = columnValue.toString();
tableRow.appendChild(cell);
})
this.table.appendChild(tableRow);
});
}
}
Die Formatierungsvisualisierungdatei style/visual.less enthält das Layout für die Tabelle:
table {
display: flex;
flex-direction: column;
}
tr, th {
display: flex;
flex: 1;
}
td {
flex: 1;
border: 1px solid black;
}
Die resultierende Liste sieht wie folgt aus:
Matrixdatenzuordnung
Die Matrixdatenzuordnung ist mit der Tabellendatenzuordnung vergleichbar, allerdings werden Zeilen hierarchisch dargestellt. Alle Datenrollenwerte können als Werte für die Spaltenkopfzeile verwendet werden.
{
"dataRoles": [
{
"name": "Category",
"displayName": "Category",
"displayNameKey": "Visual_Category",
"kind": "Grouping"
},
{
"name": "Column",
"displayName": "Column",
"displayNameKey": "Visual_Column",
"kind": "Grouping"
},
{
"name": "Measure",
"displayName": "Measure",
"displayNameKey": "Visual_Values",
"kind": "Measure"
}
],
"dataViewMappings": [
{
"matrix": {
"rows": {
"for": {
"in": "Category"
}
},
"columns": {
"for": {
"in": "Column"
}
},
"values": {
"select": [
{
"for": {
"in": "Measure"
}
}
]
}
}
}
]
}
Hierarchische Struktur von Matrixdaten
Power BI erzeugt eine hierarchische Datenstruktur. Das Stammelement dieser Hierarchie enthält die Daten aus der Spalte Übergeordnete Elemente der Category-Datenrolle und die Daten aus der Spalte Untergeordnete Elemente aus der Datenrollentabelle.
Semantikmodell:
| Übergeordnete Elemente (Parents) | Children | Grandchildren (Enkelkinder) | Spalten | Werte |
|---|---|---|---|---|
| Parent1 | Child1 | Grand child1 | Col1 | 5 |
| Parent1 | Child1 | Grand child1 | Col2 | 6 |
| Parent1 | Child1 | Grand child2 | Col1 | 7 |
| Parent1 | Child1 | Grand child2 | Col2 | 8 |
| Parent1 | Child2 | Grand child3 | Col1 | 5 |
| Parent1 | Child2 | Grand child3 | Col2 | 3 |
| Parent1 | Child2 | Grand child4 | Col1 | 4 |
| Parent1 | Child2 | Grand child4 | Col2 | 9 |
| Parent1 | Child2 | Grand child5 | Col1 | 3 |
| Parent1 | Child2 | Grand child5 | Col2 | 5 |
| Parent2 | Child3 | Grand child6 | Col1 | 1 |
| Parent2 | Child3 | Grand child6 | Col2 | 2 |
| Parent2 | Child3 | Grand child7 | Col1 | 7 |
| Parent2 | Child3 | Grand child7 | Col2 | 1 |
| Parent2 | Child3 | Grand child8 | Col1 | 10 |
| Parent2 | Child3 | Grand child8 | Col2 | 13 |
Das Hauptmatrixvisual von Power BI rendert die Daten als Tabelle.
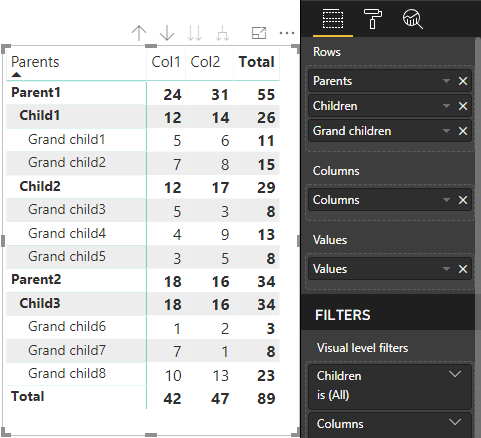
Die Datenstruktur für das Visual wird wie im folgenden Code definiert. Nur die ersten beiden Tabellenzeilen werden hier aufgeführt:
{
"metadata": {...},
"matrix": {
"rows": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Parent1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 1,
"levelValues": [...],
"value": "Child1",
"identity": {...},
"childIdentityFields": [...],
"children": [
{
"level": 2,
"levelValues": [...],
"value": "Grand child1",
"identity": {...},
"values": {
"0": {
"value": 5 // value for Col1
},
"1": {
"value": 6 // value for Col2
}
}
},
...
]
},
...
]
},
...
]
}
},
"columns": {
"levels": [...],
"root": {
"childIdentityFields": [...],
"children": [
{
"level": 0,
"levelValues": [...],
"value": "Col1",
"identity": {...}
},
{
"level": 0,
"levelValues": [...],
"value": "Col2",
"identity": {...}
},
...
]
}
},
"valueSources": [...]
}
}
Erweitern und Reduzieren von Zeilenüberschriften
Ab der API 4.1.0 wird das Erweitern und Reduzieren von Zeilenüberschriften von Matrix-Daten unterstützt. Ab API 4.2 können Sie die gesamte Ebene programmgesteuert erweitern/reduzieren. Das Feature zum Erweitern und Reduzieren optimiert das Abrufen von Daten in DataView, indem es dem Benutzer ermöglicht, eine Zeile zu erweitern oder zu reduzieren, ohne alle Daten für die nächste Ebene abrufen zu müssen. Es werden nur die Daten der ausgewählten Zeile abgerufen. Die Zeilenüberschrift bleibt für alle Lesezeichen und sogar für alle gespeicherten Berichte konsistent erweitert. Er ist nicht für jedes Visual spezifisch.
Befehle zum Erweitern und Reduzieren können dem Kontextmenü hinzugefügt werden, indem der Parameter dataRoles für die Methode showContextMenu angegeben wird.
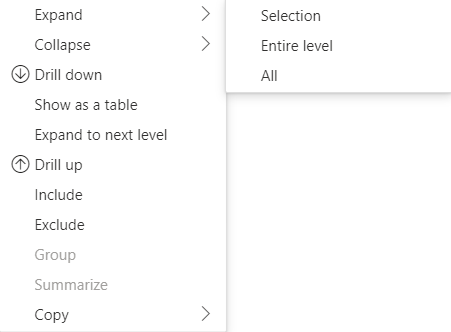
Um eine große Anzahl von Datenpunkten zu erweitern, verwenden Sie die API zum Abrufen zusätzlicher Daten mit der Erweiterungs-/Reduzierungs-API.
API-Features
Um das Erweitern und Reduzieren von Zeilenüberschriften zu ermöglichen, wurden der API-Version 4.1.0 die folgenden Elemente hinzugefügt:
Das Flag
isCollapsedin imDataViewTreeNode:interface DataViewTreeNode { //... /** * TRUE if the node is Collapsed * FALSE if it is Expanded * Undefined if it cannot be Expanded (e.g. subtotal) */ isCollapsed?: boolean; }Die Methode
toggleExpandCollapsein derISelectionManger-Schnittstelle:interface ISelectionManager { //... showContextMenu(selectionId: ISelectionId, position: IPoint, dataRoles?: string): IPromise<{}>; // dataRoles is the name of the role of the selected data point toggleExpandCollapse(selectionId: ISelectionId, entireLevel?: boolean): IPromise<{}>; // Expand/Collapse an entire level will be available from API 4.2.0 //... }Das Flag
canBeExpandedauf der Hierarchieebene der Datenansicht (DataViewHierarchyLevel):interface DataViewHierarchyLevel { //... /** If TRUE, this level can be expanded/collapsed */ canBeExpanded?: boolean; }
Visual-Anforderungen
So aktivieren Sie das Feature zum Erweitern und Reduzieren im Visual mithilfe der Matrix-Datenansicht:
Fügen Sie der Datei „capabilities.json“ den folgenden Code hinzu:
"expandCollapse": { "roles": ["Rows"], //”Rows” is the name of rows data role "addDataViewFlags": { "defaultValue": true //indicates if the DataViewTreeNode will get the isCollapsed flag by default } },Stellen Sie sicher, dass die Rollen drillfähig sind:
"drilldown": { "roles": ["Rows"] },Erstellen Sie für jeden Knoten eine Instanz des Auswahl-Generators, indem Sie die Methode
withMatrixNodeauf der ausgewählten Knotenhierarchieebene aufrufen und eineselectionIderstellen. Beispiel:let nodeSelectionBuilder: ISelectionIdBuilder = visualHost.createSelectionIdBuilder(); // parantNodes is a list of the parents of the selected node. // node is the current node which the selectionId is created for. parentNodes.push(node); for (let i = 0; i < parentNodes.length; i++) { nodeSelectionBuilder = nodeSelectionBuilder.withMatrixNode(parentNodes[i], levels); } const nodeSelectionId: ISelectionId = nodeSelectionBuilder.createSelectionId();Erstellen Sie eine Instanz des Auswahl-Managers, und verwenden Sie die Methode
selectionManager.toggleExpandCollapse()mit dem Parameter derselectionId, die Sie für den ausgewählten Knoten erstellt haben. Beispiel:// handle click events to apply expand\collapse action for the selected node button.addEventListener("click", () => { this.selectionManager.toggleExpandCollapse(nodeSelectionId); });
Hinweis
- Wenn der ausgewählte Knoten kein Zeilenknoten ist, ignoriert Power BI die Aufrufe zum Erweitern und Reduzieren, und die Befehle zum Erweitern und Reduzieren werden aus dem Kontextmenü entfernt.
- Der Parameter
dataRolesist für die MethodeshowContextMenunur erforderlich, wenn das Visualdrilldown- oderexpandCollapse-Features unterstützt. Wenn das Visual diese Features unterstützt, aber die „dataRoles“ nicht angegeben wurden, wird ein Fehler an die Konsole ausgegeben, wenn das Entwickler-Visual verwendet wird oder wenn ein öffentliches Visual mit aktiviertem Debug-Modus debuggt wird.
Überlegungen und Einschränkungen
- Nachdem Sie einen Knoten erweitern, werden neue Datengrenzwerte in DataView angewendet. Die neue DataView enthält möglicherweise einige der in der vorherigen DataView dargestellten Knoten nicht.
- Wenn Sie die Befehle zum Erweitern und Reduzieren verwenden, werden Gesamtsummen hinzugefügt, auch wenn das Visual sie nicht angefordert hat.
- Das Erweitern und Reduzieren von Spalten wird nicht unterstützt.
Beibehalten aller Metadatenspalten
Ab API 5.1.0 wird das Beibehalten aller Metadatenspalten unterstützt. Dieses Feature ermöglicht es dem visuellen Element, die Metadaten für alle Spalten unabhängig von seinen Projektionen zu empfangen.
Fügen Sie der Datei capabilities.json folgende Zeilen hinzu:
"keepAllMetadataColumns": {
"type": "boolean",
"description": "Indicates that visual is going to receive all metadata columns, no matter what the active projections are"
}
Wenn Sie diese Eigenschaft auf true festlegen, werden alle Metadaten empfangen, auch aus reduzierten Spalten. Wenn Sie sie auf false festlegen oder nicht definiert lassen, werden Metadaten nur für Spalten mit aktiven Projektionen empfangen (z. B. erweiterte Spalten).
Datenverringerungsalgorithmus
Der Datenverringerungsalgorithmus steuert, welche Daten und wie viele Daten in der Datenansicht empfangen werden.
Die Anzahl (count)wird auf die maximale Anzahl von Werten festgelegt, die die Datenansicht akzeptieren kann. Wenn mehr Werte als count-Werte vorhanden sind, bestimmt der Datenverringerungsalgorithmus, welche Werte empfangen werden sollen.
Typen von Datenverringerungsalgorithmen
Für den Datenverringerungsalgorithmus sind vier Einstellungstypen verfügbar:
top: Die ersten count Werte werden aus dem Semantikmodell abgerufen.bottom: Die letzten count Werte werden aus dem Semantikmodell abgerufen.sample: Das erste und das letzte Element werden einbezogen und eine durch count vorgegebenen Anzahl von Elementen bleibt zwischen dieselben Intervalle bestehen. Wenn beispielsweise das Semantikmodell [0, 1, 2, ..., 100] vorliegt und count 9 beträgt, ergeben sich daraus die Werte [0, 10, 20, ..., 100].window: Hiermit wird jeweils ein Segment (window) mit Datenpunkten mit der durch count angegebenen Anzahl von Elementen geladen.topundwindowsind derzeit gleichwertig. In Zukunft wird eine Windowing-Einstellung vollständig unterstützt.
Auf alle Power BI-Visuals wird standardmäßig der Datenverringerungsalgorithmus „top“ angewendet, wobei count auf 1000 Datenpunkte festgelegt ist. Diese Standardeinstellung entspricht der Einstellung der folgenden Eigenschaften in der Datei capabilities.json:
"dataReductionAlgorithm": {
"top": {
"count": 1000
}
}
Sie können für count einen anderen Integerwert bis 30.000 festlegen. R-basierte Power BI-Visuals können bis zu 150000 Zeilen unterstützen.
Verwenden des Datenverringerungsalgorithmus
Der Datenverringerungsalgorithmus kann für Datenansichtszuordnungen der Typen „categorical“, „table“ oder „matrix“ genutzt werden.
In der kategorischen Datenzuordnung können Sie den Algorithmus zum Abschnitt „categories“ und/oder „group“ von values für die kategorische Datenzuordnung hinzufügen.
"dataViewMappings": {
"categorical": {
"categories": {
"for": { "in": "category" },
"dataReductionAlgorithm": {
"window": {
"count": 300
}
}
},
"values": {
"group": {
"by": "series",
"select": [{
"for": {
"in": "measure"
}
}
],
"dataReductionAlgorithm": {
"top": {
"count": 100
}
}
}
}
}
}
Sie können in der Tabellendatenansichtszuordnung den Datenverringerungsalgorithmus auf den rows-Abschnitt der Zuordnungstabelle für Datenansichten anwenden.
"dataViewMappings": [
{
"table": {
"rows": {
"for": {
"in": "values"
},
"dataReductionAlgorithm": {
"top": {
"count": 2000
}
}
}
}
}
]
Sie können den Datenverringerungsalgorithmus auf die Abschnitte rows und columns der Zuordnungsmatrix für Datenansichten anwenden.