Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie künstliche Intelligenz (KI) mit Dataflows verwendet werden kann. Dieser Artikel beschreibt Folgendes:
- Cognitive Services
- Automatisiertes maschinelles Lernen
- Azure Machine Learning-Integration
Wichtig
Die Erstellung von Power BI Automated Machine Learning (AutoML)-Modellen für Dataflows v1 wurde eingestellt und ist nicht mehr verfügbar. Kundinnen und Kunden sollten Ihre Lösung zum AutoML-Feature in Microsoft Fabric migrieren. Weitere Informationen finden Sie in der Einstellungsankündigung.
Cognitive Services in Power BI
Sie können mit Cognitive Services in Power BI verschiedene Algorithmen der Azure Cognitive Services anwenden, um Ihre Daten in der Self-Service-Datenaufbereitung für Dataflows zu ergänzen.
Die derzeit unterstützten Dienste sind Standpunktanalyse, Schlüsselbegriffserkennung, Sprachenerkennung und Bildmarkierung. Die Transformationen werden im Power BI-Dienst ausgeführt und erfordern kein Azure Cognitive Services-Abonnement. Dieses Feature erfordert Power BI Premium.
Aktivieren von KI-Features
Cognitive Services wird für die Premium-Kapazitätsknoten „EM2“, „A2“, „P1“ oder „F64“ und andere Knoten mit weiteren Ressourcen unterstützt. Cognitive Services sind auch mit einer Premium pro Benutzer-Lizenz (PPU) verfügbar. Eine separate KI-Workload auf der Kapazität wird zum Ausführen von Cognitive Services verwendet. Damit Cognitive Services in Power BI verwendet werden können, muss die KI-Workload in den Kapazitätseinstellungen des Verwaltungsportals aktiviert werden. Sie können die KI-Workload im Abschnitt „Workloads“ aktivieren.

Erste Schritte mit Cognitive Services in Power BI
Cognitive Services-Transformationen sind Teil der Self-Service-Datenvorbereitung für Datenflüsse. Um die Daten mit Cognitive Services zu erweitern, beginnen Sie mit dem Bearbeiten eines Datenflusses.

Klicken Sie auf die Schaltfläche KI Insights im oberen Menüband des Power Query-Editors.

Wählen Sie im Popupfenster die Funktion aus, die Sie verwenden möchten, und die Daten, die Sie transformieren möchten. In diesem Beispiel wird die Stimmung einer Spalte bewertet, die einen Rezensionstext enthält.

LanguageISOCode ist eine optionale Eingabe, um die Sprache des Texts anzugeben. In dieser Spalte wird ein ISO-Code erwartet. Sie können eine Spalte als Eingabe für LanguageISOCode oder eine statische Spalte verwenden. In diesem Beispiel wird die Sprache Englisch (En) für die gesamte Spalte angegeben. Wenn Sie diese Spalte leer lassen, erkennt Power BI die Sprache automatisch vor dem Anwenden der Funktion. Wählen Sie als Nächstes Aufrufen aus.

Nach dem Aufrufen der Funktion wird das Ergebnis der Tabelle als neue Spalte hinzugefügt. Die Transformation wird auch als angewendeter Schritt in der Abfrage hinzugefügt.

Wenn die Funktion mehrere Ausgabespalten zurückgibt, fügt der Aufruf der Funktion eine neue Spalte mit einer Zeile der mehreren Ausgabespalten hinzu.
Verwenden Sie die Erweiterungsoption, um einen oder beide Werte Ihren Daten als Spalten hinzuzufügen.

Verfügbare Funktionen
Dieser Abschnitt beschreibt die verfügbaren Funktionen in Cognitive Services in Power BI.
Erkennen von Sprache
Die Spracherkennungsfunktion wertet Texteingabe aus und gibt für jede Spalte den Sprachnamen und ISO-Bezeichner zurück. Diese Funktion ist nützlich für Datenspalten, die beliebigen Text sammeln, wobei die Sprache unbekannt ist. Die Funktion erwartet Daten im Textformat als Eingabe.
Die Textanalyse erkennt bis zu 120 Sprachen. Weitere Informationen finden Sie unter Was ist Azure Cognitive Service für Language?.
Extrahieren von Schlüsselbegriffen
Die Funktion Schlüsselbegriffserkennung wertet unstrukturierten Text aus und gibt für jede Textspalte eine Liste von Schlüsselbegriffen zurück. Die Funktion erfordert eine Textspalte als Eingabe und akzeptiert eine optionale Eingabe für LanguageISOCode. Weitere Informationen finden Sie unter Erste Schritte.
Im Gegensatz zur Stimmungsanalyse funktioniert die Schlüsselbegriffserkennung am besten, wenn Sie ihr größere Textblöcke zur Verarbeitung zuweisen. Die Stimmungsanalyse kann kleinere Textblöcke besser verarbeiten. Um die besten Ergebnisse beider Vorgänge zu erhalten, sollten Sie die Eingaben entsprechend umstrukturieren.
Bewerten der Stimmung
Die Score Sentiment-Funktion wertet die Texteingabe aus und gibt eine Stimmungspunktzahl im Bereich von 0 (negativ) bis 1 (positiv) für jedes Dokument zurück. Diese Funktion ist nützlich zum Erkennen von positiven und negativen Standpunkten in sozialen Medien, Kundenrezensionen und Diskussionsforen.
Die Textanalyse verwendet einen Machine Learning-Klassifizierungsalgorithmus, um eine Stimmungspunktzahl zwischen 0 und 1 zu generieren. Bewertungen, die näher bei 1 liegen, weisen auf eine positive Stimmung hin. Bewertungen, die näher bei 0 liegen, weisen auf eine negative Stimmung hin. Das Modell ist mit einem umfangreichen Textkörper mit Standpunktzuordnungen vortrainiert. Derzeit können Sie nicht Ihre eigenen Trainingsdaten verwenden. Das Modell verwendet zur Textanalyse eine Kombination aus Verfahren – einschließlich Textverarbeitung, Wortartanalyse, Wortplatzierung und Wortassoziationen. Weitere Informationen zum Algorithmus finden Sie im Artikel zu Machine Learning und Textanalyse.
Die Standpunktanalyse wird für die gesamte Eingabespalte durchgeführt, im Gegensatz zum Erkennen des Standpunkts für eine bestimmte Tabelle im Text. In der Praxis besteht die Tendenz, dass sich die Genauigkeit der Bewertung verbessert, wenn Dokumente einen oder zwei Sätze anstatt eines großen Textblocks enthalten. Während einer Objektivitätsbewertungsphase bestimmt das Modell, ob eine Eingabespalte als Ganzes objektiv ist oder einen Standpunkt enthält. Ein überwiegend objektive Eingabespalte wird nicht der Standpunkterkennung übergeben und erhält ohne weitere Verarbeitung eine Bewertung von 0,50. Für die folgenden Eingabespalten in der Pipeline generiert die nächste Phase je nach Grad der in der Eingabespalte erkannten Stimmung eine Bewertung von über oder unter 0,50.
Derzeit unterstützt die Standpunktanalyse Englisch, Deutsch, Spanisch und Französisch. Andere Sprachen befinden sich in der Vorschauphase. Weitere Informationen finden Sie unter Was ist Azure Cognitive Service für Language?.
Kennzeichnen von Images
Die Tag Images-Funktion gibt Tags basierend auf mehr als 2.000 erkennbaren Objekten, Lebewesen, Landschaften und Aktionen zurück. Wenn Tags nicht eindeutig oder nicht allgemein bekannt sind, bietet die Ausgabe „Hinweise“, um die Bedeutung des Tags im Kontext einer bekannten Einstellung zu verdeutlichen. Tags sind nicht taxonomisch angeordnet, und es gibt keine Vererbungshierarchien. Eine Auflistung von Inhaltstags bildet die Grundlage für eine „Bildbeschreibung“, die in einer für Menschen lesbaren Sprache in vollständigen Sätzen angezeigt wird.
Nach dem Hochladen eines Bilds oder der Angabe einer Bild-URL geben Algorithmen für maschinelles Sehen Tags basierend auf den im Bild identifizierten Objekten, Lebewesen und Aktionen aus. Die Markierung ist nicht auf den Hauptinhalt (etwa eine Person im Vordergrund) beschränkt, sondern bezieht auch die Umgebung (Innen- oder Außenbereich), Möbel, Werkzeuge, Pflanzen, Tiere, Zubehör, Geräte und Ähnliches mit ein.
Diese Funktion setzt eine Bild-URL oder eine Base-64-Spalte als Eingabe voraus. Zurzeit unterstützt die Bildmarkierung Englisch, Spanisch, Japanisch, Portugiesisch und Chinesisch (vereinfacht). Weitere Informationen finden Sie unter ComputerVision-Schnittstelle.
Automatisiertes Machine Learning in Power BI
Automatisiertes maschinelles Lernen (AutoML) für Dataflows ermöglicht Business Analysts, ML-Modelle (Machine Learning) direkt in Power BI zu trainieren, zu prüfen und aufzurufen. Dazu gehört eine einfache Umgebung zur Erstellung eines neuen ML-Modells, in dem Analysten ihre Dataflows verwenden können, um die Eingabedaten zum Trainieren des Modells festzulegen. Der Dienst extrahiert automatisch die wichtigsten Features, wählt einen geeigneten Algorithmus aus, optimiert das ML-Modell und prüft es. Nach dem Trainieren eines Modells erstellt Power BI automatisch einen Leistungsbericht, der die Ergebnisse der Prüfung enthält. Das Modell kann anschließend für alle neuen oder aktualisierten Daten im Dataflow aufgerufen werden.
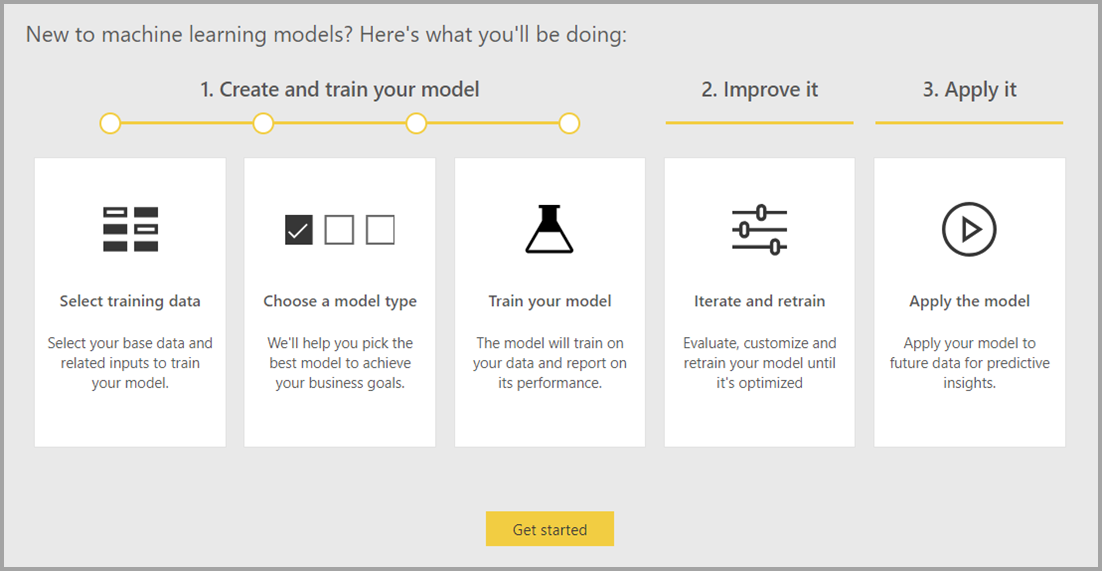
Automatisiertes maschinelles Lernen ist nur für Datenflows verfügbar, die in Power BI Premium und Embedded gehostet werden.
Arbeiten mit AutoML
In der Industrie und wissenschaftlichen Forschung erfreuen sich maschinelles Lernen (ML) und künstliche Intelligenz (KI) einer immer größeren Beliebtheit. Unternehmen suchen ebenfalls nach Möglichkeiten, diese neuen Technologien in ihren Betrieb zu integrieren.
Dataflows lassen eine Self-Service-Datenaufbereitung für Big-Data-Szenarios zu. AutoML ist in Dataflows integriert und ermöglicht Ihnen zum Erstellen von Machine Learning-Modellen die Aufbereitung Ihrer Daten direkt in Power BI.
AutoML in Power BI ermöglicht Datenanalysten den Einsatz von Dataflows, um Machine Learning Modelle in vereinfachter Weise zu erstellen, wobei nur Power BI-Fertigkeiten genutzt werden. Power BI automatisiert den größten Teil der Data Science hinter der Erstellung der ML-Modelle. Dies geschieht mithilfe von Vorkehrungen, die sicherstellen, dass das produzierte Modell eine gute Qualität aufweist. Außerdem erhalten Sie Einblick in den Prozess, der zum Erstellen des ML-Modells verwendet wird.
AutoML unterstützt für Dataflows das Erstellen von Modellen der Typen Binäre Vorhersage, Klassifizierung und Regression. Diese Features sind beaufsichtigte Machine Learning-Techniken, was bedeutet, dass sie aus den bekannten Ergebnissen früherer Beobachtungen lernen, um die Ergebnisse anderer Beobachtungen vorherzusagen. Das Eingabesemantikmodell zum Trainieren eines AutoML-Modells besteht aus einer Reihe von Zeilen, die mit den bekannten Ergebnissen beschriftet sind.
AutoML in Power BI integriert automatisiertes Machine Learning aus Azure Machine Learning zur Erstellung Ihrer Machine Learning-Modelle. Sie benötigen jedoch kein Azure-Abonnement, um AutoML in Power BI zu nutzen. Training und Hosting der ML-Modelle wird vollständig vom Power BI-Dienst verwaltet.
Nachdem ein ML-Modell trainiert wurde, erstellt AutoML automatisch einen Power BI-Bericht, der die wahrscheinliche Leistung Ihres ML-Modells erklärt. AutoML legt den Schwerpunkt auf Erklärbarkeit, indem es die wichtigsten Einflussfaktoren unter Ihren Eingaben hervorhebt, die die von Ihrem Modell gelieferten Vorhersagen beeinflussen. Der Bericht enthält auch Schlüsselmetriken für das Modell.
Andere Seiten des generierten Berichts zeigen eine statistische Zusammenfassung zum Modell und die Trainingsdetails. Die statistische Zusammenfassung ist für Benutzer von Interesse, die die üblichen Data-Science-Measures der Modellleistung einsehen möchten. In den Trainingsdetails sind alle Iterationen mit den zugehörigen Modellierungsparametern zusammengefasst, die zur Erstellung Ihres Modells erfolgt sind. Außerdem wird beschrieben, wie die einzelnen Eingaben zur Erstellung des ML-Modells verwendet wurden.
Danach können Sie Ihr ML-Modell auf Ihre Daten anwenden, um es zu bewerten. Bei der Aktualisierung des Dataflows werden Ihre Daten mit Vorhersagen aus Ihrem ML-Datenmodell aktualisiert. Power BI bietet auch eine individualisierte Erklärung für die jeweilige Vorhersage, die das ML-Modell liefert.
Erstellen eines Machine Learning-Modells
In diesem Abschnitt wird das Erstellen eines AutoML-Modells beschrieben.
Datenaufbereitung zum Erstellen eines ML-Modells
Um ein Machine Learning-Modell in Power BI zu erstellen, müssen Sie zunächst einen Dataflow für die Daten mit den historischen Ergebnisinformationen erstellen, der zum Trainieren des ML-Modells verwendet wird. Sie sollten auch berechnete Spalten für Geschäftsmetriken hinzufügen, die starke Prädiktoren für das Ergebnis sein können, das Sie vorherzusagen versuchen. Details zum Konfigurieren Ihres Dataflows finden Sie unter Konfigurieren und Nutzen eines Dataflows.
In AutoML gelten für das Trainieren eines Machine Learning-Modells bestimmte Anforderungen. Diese Anforderungen werden in den folgenden Abschnitten basierend auf den jeweiligen Modelltypen beschrieben.
Konfigurieren der Eingaben für das ML-Modell
Um ein AutoML-Modell zu erstellen, klicken Sie in der Spalte Aktionen der Dataflowtabelle auf das ML-Symbol und wählen Machine Learning-Modell hinzufügen aus.
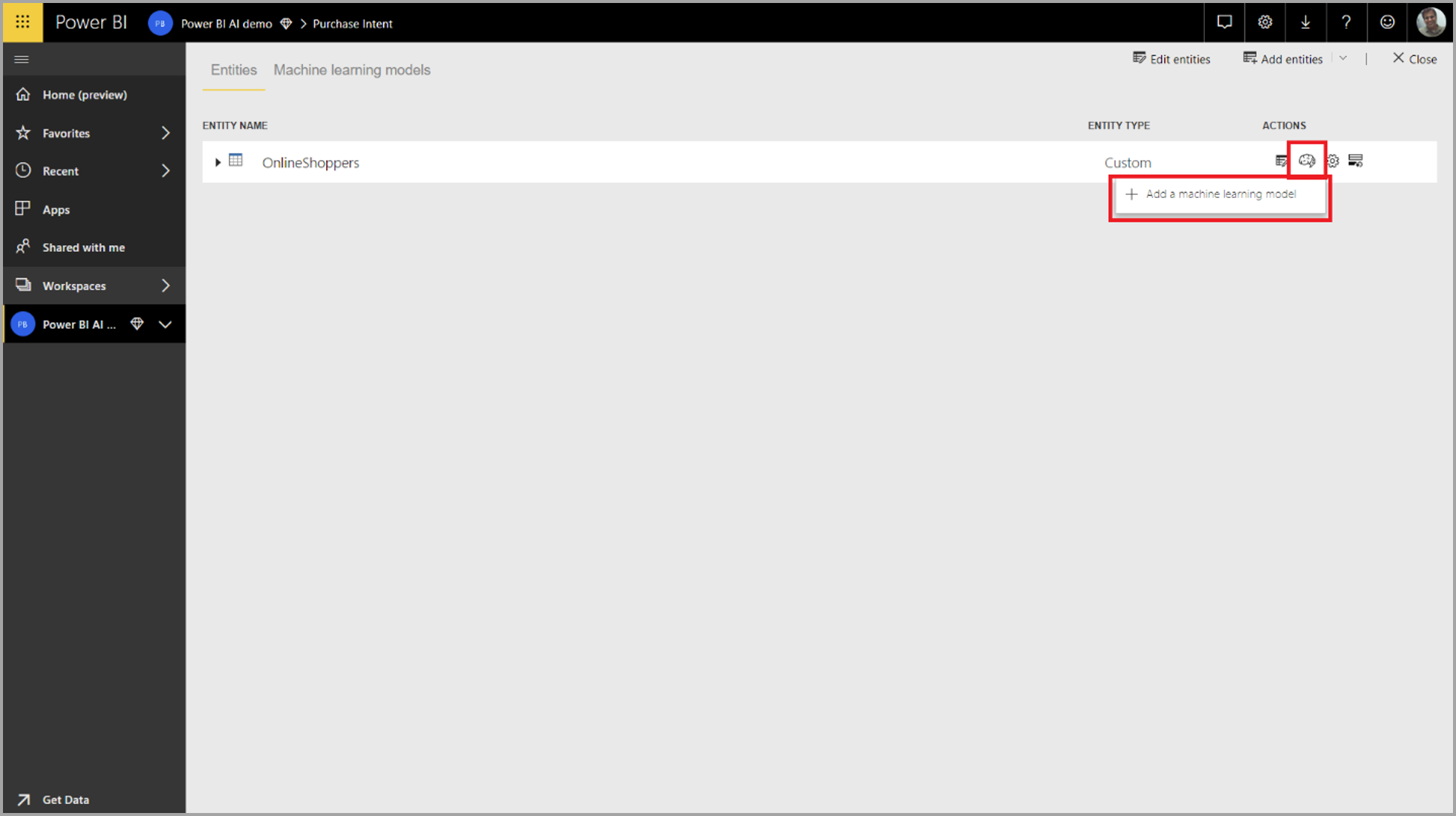
Es wird eine vereinfachte Benutzeroberfläche gestartet, die aus einem Assistenten besteht, der Sie durch die Erstellung des ML-Modells begleitet. Der Assistent umfasst die folgenden einfachen Schritte.
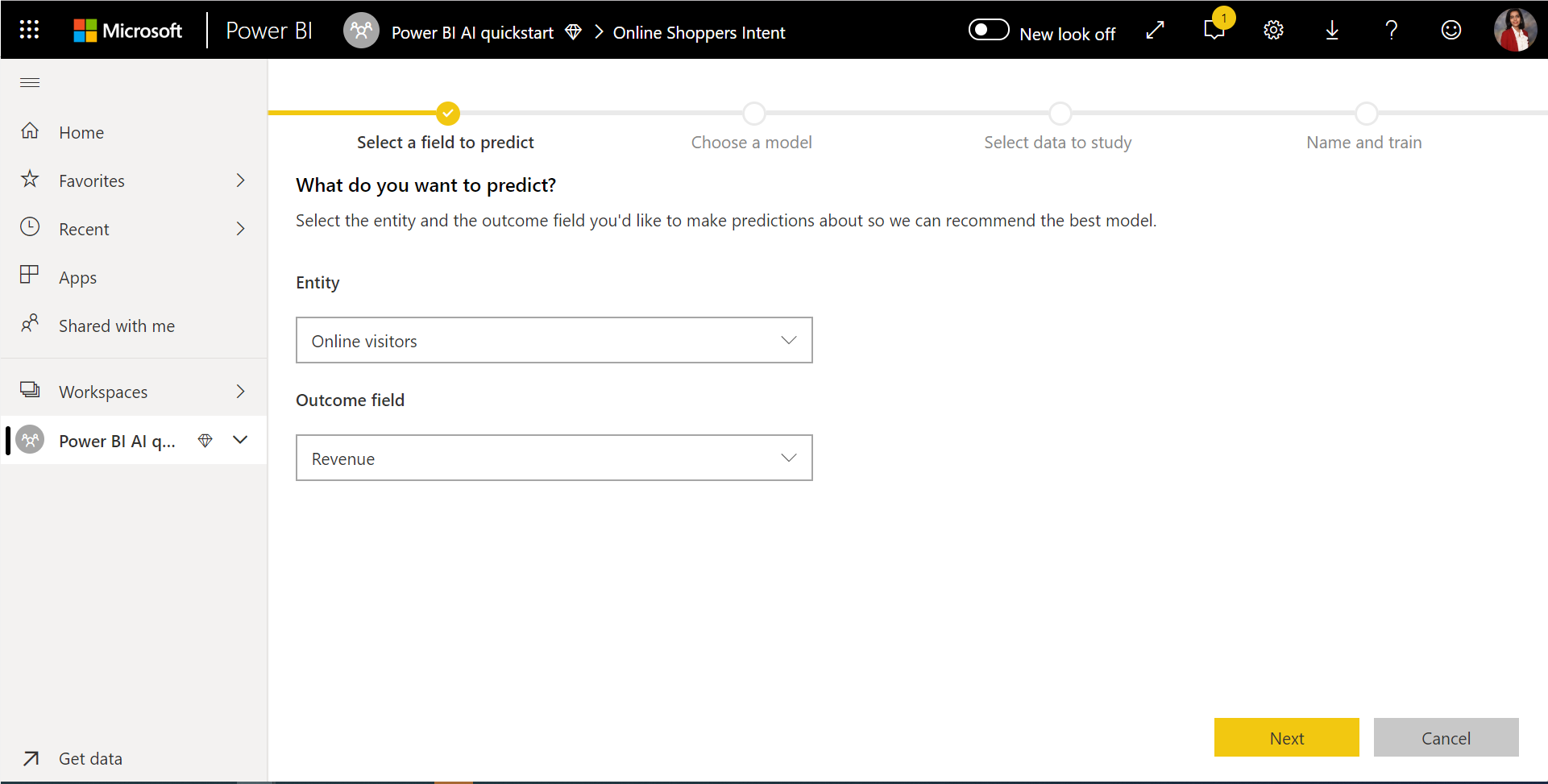
1. Wählen Sie die Tabelle mit den historischen Daten und die Ergebnisspalte aus, für die Sie eine Vorhersage wünschen.
In der Ergebnisspalte wird das Beschriftungsattribut für das Training des ML-Modells bestimmt. Die folgende Abbildung veranschaulicht das.
2. Wählen Sie einen Modelltyp aus.
Wenn Sie die Ergebnisspalte angeben, analysiert AutoML die Beschriftungsdaten, um den wahrscheinlichsten ML-Modelltyp vorzuschlagen, der trainiert werden kann. Sie können einen anderen Modelltyp als in der folgenden Abbildung auswählen, indem Sie auf Modell auswählen klicken.
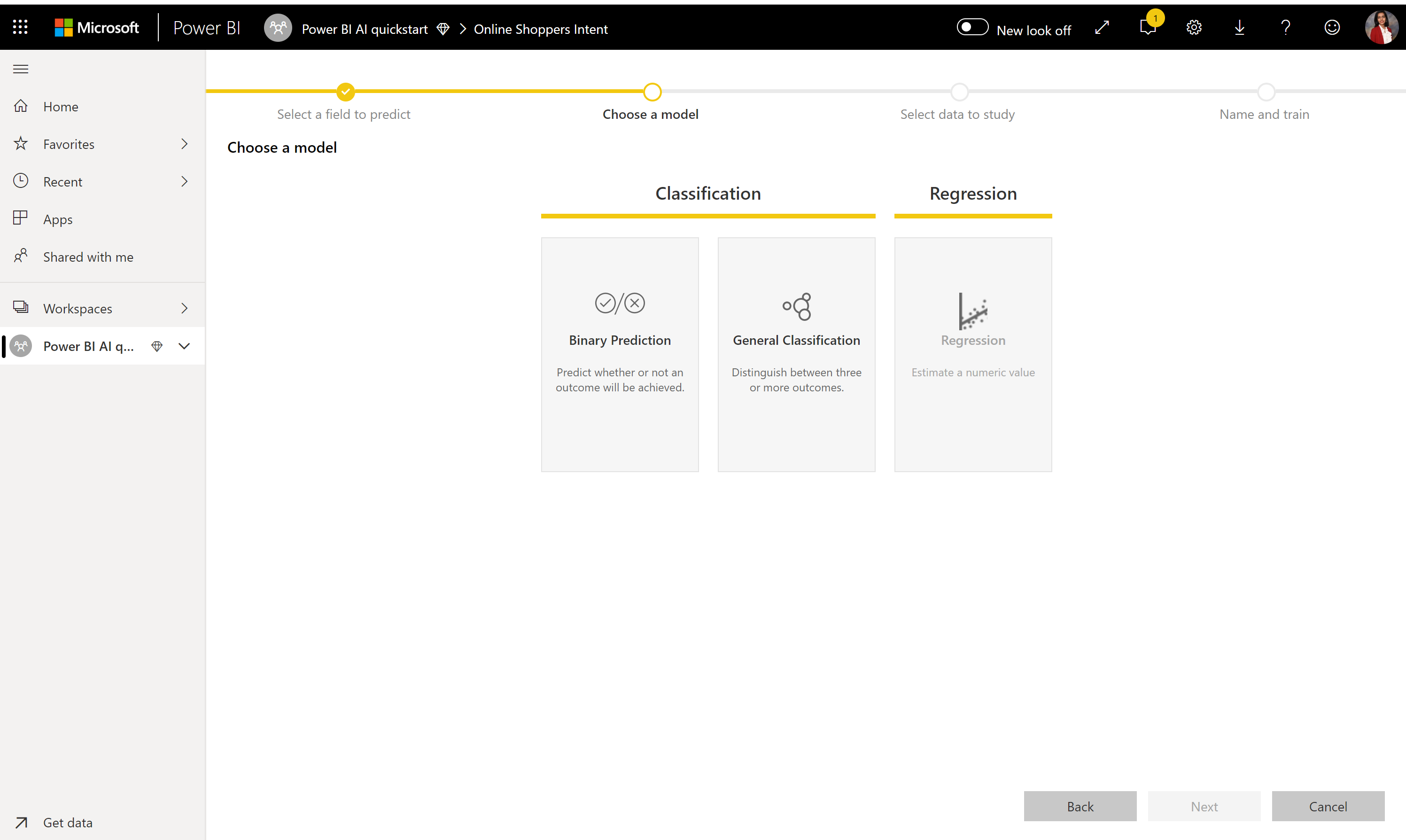
Hinweis
Einige Modelltypen werden möglicherweise nicht für die von Ihnen ausgewählten Daten unterstützt und sind daher deaktiviert. Im obigen Beispiel ist „Regression“ deaktiviert, da eine Textspalte als Ergebnisspalte ausgewählt ist.
3. Wählen Sie die Eingaben aus, die das Modell als Prognosesignale verwenden soll.
AutoML analysiert eine Stichprobe der ausgewählten Tabelle, um die Eingaben vorzuschlagen, die für das Training des ML-Modells verwendet werden können. Neben Spalten, die nicht ausgewählt sind, werden Erläuterungen angezeigt. Wenn eine bestimmte Spalte zu viele unterschiedliche Werte oder nur einen Wert oder eine geringfügige oder hohe Korrelation mit der Ergebnisspalte aufweist, wird sie nicht empfohlen.
Alle Eingaben, die von der Ergebnisspalte (oder Beschriftungsspalte) abhängig sind, dürfen nicht zum Trainieren des ML-Modells verwendet werden, da sie dessen Leistung beeinträchtigen. Spalten dieser Art werden als Spalten gekennzeichnet, die „eine verdächtig hohe Korrelation mit dem Ergebnisfeld“ aufweisen. Wenn diese Spalten in die Trainingsdaten einbezogen werden, kann dies zu einem Beschriftungsleck führen, bei dem das Modell bei Prüfungs- oder Testdaten gut abschneidet, diese Leistung bei Verwendung in der Produktion zur Bewertung jedoch nicht erreicht. Ein Beschriftungsleck kann bei AutoML-Modellen ein Problem darstellen, wenn die Leistung des Trainingsmodells überdurchschnittlich gut ist.
Diese Featureempfehlung beruht auf einer Stichprobe von Daten. Daher sollten Sie die verwendeten Eingaben überprüfen. Sie können die Auswahl so ändern, dass nur die Spalten einbezogen werden, die mit dem Modell untersucht werden sollen. Sie können auch alle Spalten auswählen, indem Sie das Kontrollkästchen neben dem Tabellennamen aktivieren.
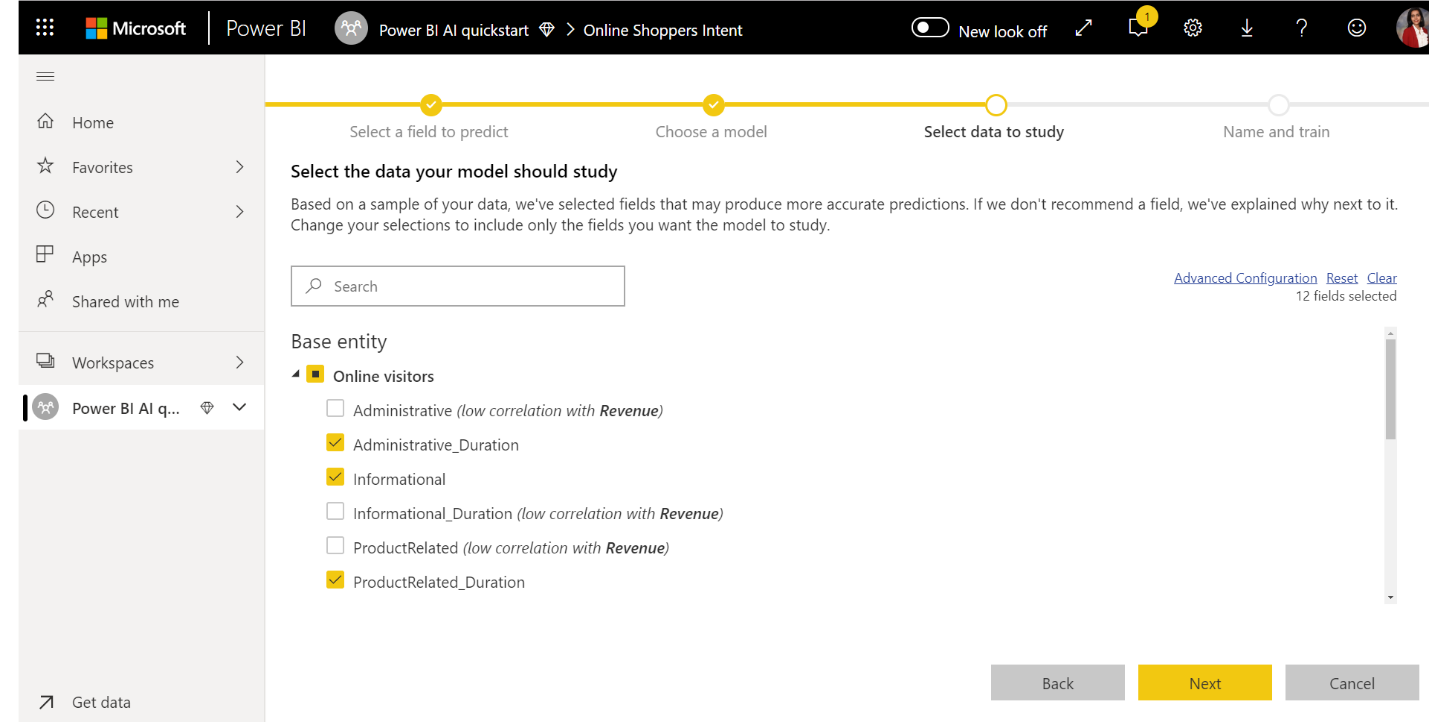
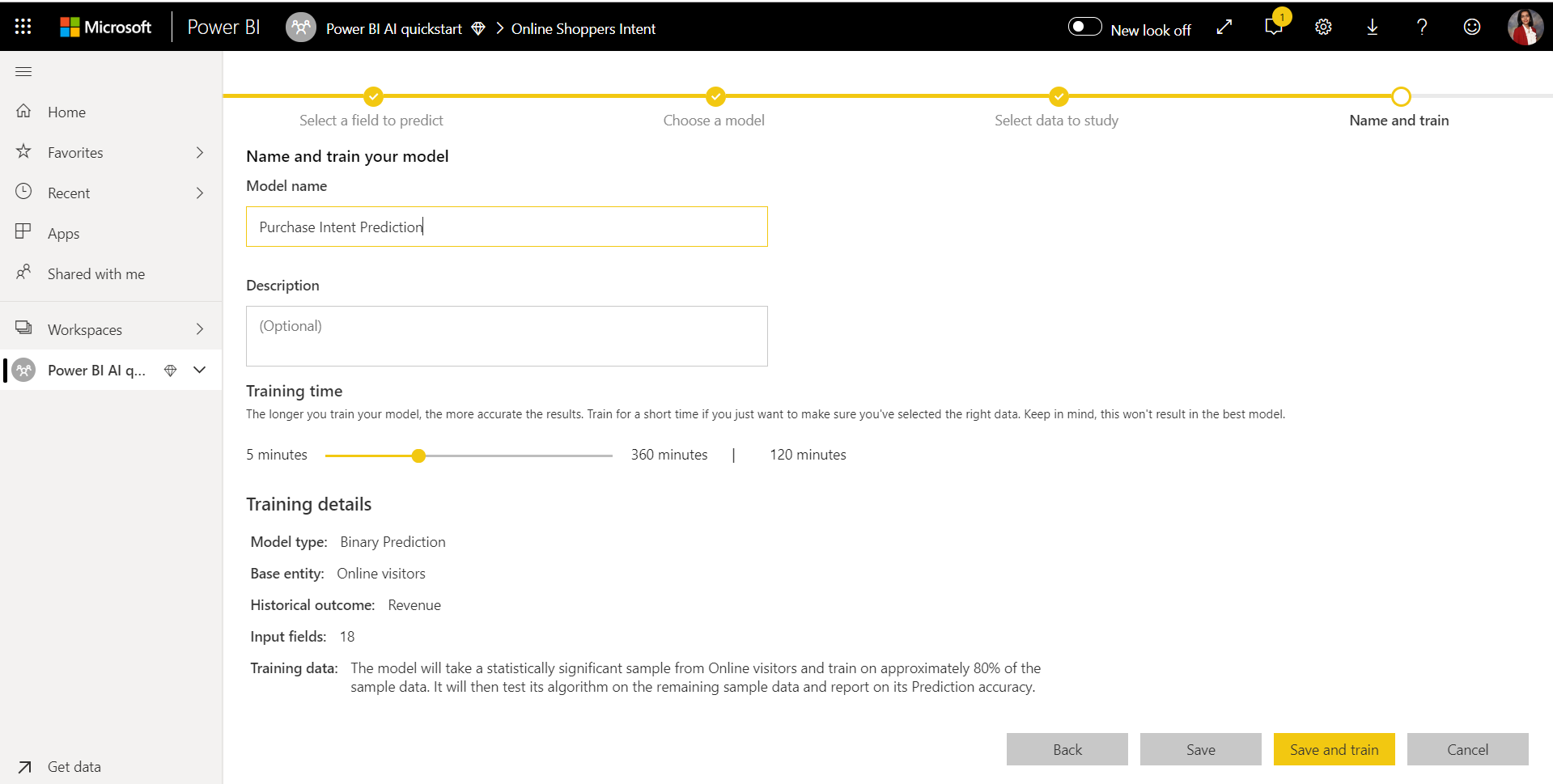
4. Geben Sie Ihrem Modell einen Namen, und speichern Sie die Konfiguration.
Im letzten Schritt können Sie dem Modell einen Namen geben, Speichern und trainieren auswählen, um das Training des ML-Modells zu beginnen. Sie können entscheiden, ob Sie die Trainingszeit verkürzen möchten, um schnelle Ergebnisse zu erzielen, oder ob Sie die Trainingszeit verlängern möchten, um das beste Modell zu erhalten.
ML-Modelltraining
Das Training von AutoML-Modellen ist Teil der Aktualisierung des Dataflows. AutoML bereitet zunächst Ihre Daten auf das Training auf. AutoML unterteilt die von Ihnen bereitgestellten historischen Daten in Trainings- und Testsemantikmodelle. Das Testsemantikmodell besteht aus zurückgehaltenen Daten, die zum Überprüfen der Modellleistung nach dem Training verwendet werden. Diese Datasets werden als Trainings- und Testtabellen im Dataflow realisiert. AutoML verwendet zur Modellprüfung die Kreuzvalidierung.
Anschließend wird jede Eingabespalte analysiert und die Anrechnung angewendet, bei der fehlende Werte durch Ersatzwerte ausgetauscht werden. AutoML arbeitet mit verschiedenen Anrechnungsstrategien. Bei Eingabeattributen, die als numerische Features behandelt werden, wird der Mittelwert der Spaltenwerte zur Anrechnung verwendet. Bei Eingabeattributen, die als kategorische Features behandelt werden, verwendet AutoML den Modus der Spaltenwerte zur Anrechnung. Der Mittelwert und der Modus von Werten, die zur Anrechnung verwendet werden, werden vom AutoML-Framework in dem Trainingssemantikmodell berechnet, das eine Teilstichprobe darstellt.
Anschließend werden bei Bedarf Stichprobenentnahmen und Normalisierungen auf Ihre Daten angewendet. Bei Klassifizierungsmodellen führt AutoML die Eingabedaten über geschichtete Zufallsstichprobenentnahmen aus und gleicht die Klassen aus, sodass alle dieselbe Anzahl von Zeilen enthalten.
AutoML wendet auf jede ausgewählte Eingabespalte je nach Datentyp und statistischen Eigenschaften mehrere Transformationen an. AutoML verwendet diese Transformationen zum Extrahieren von Features, die zum Trainieren Ihres ML-Modells verwendet werden.
Der Trainingsprozess für AutoML-Modelle besteht aus bis zu 50 Iterationen mit unterschiedlichen Modellierungsalgorithmen und Hyperparametereinstellungen, um das Modell mit der besten Leistung zu finden. Das Training kann schnell mit weniger Iterationen enden, wenn AutoML feststellt, dass keine Leistungsverbesserung beobachtet werden kann. AutoML bewertet die Leistung der einzelnen Modelle durch Überprüfung mit dem zurückgehaltenen Testsemantikmodell. Während dieses Trainingsschritts erstellt AutoML verschiedene Pipelines für Training und Prüfung dieser Iterationen. Die Leistungsbewertung von Modellen kann eine gewisse Zeit dauern, und zwar von einigen Minuten bis zu mehreren Stunden, je nach der im Assistenten konfigurierten Trainingszeit. Die benötigte Zeit hängt von der Größe Ihres Semantikmodells und den verfügbaren Kapazitätsressourcen ab.
In einigen Fällen verwendet das endgültige generierte Modell möglicherweise Ensemble-Lernmethoden, bei denen mehrere Modelle verwendet werden, um eine bessere Vorhersageleistung zu erzielen.
Erklärbarkeit des AutoML-Modells
Nachdem dem Trainieren des Modells analysiert AutoML die Beziehung zwischen Eingabefeatures und Modellausgabe. Bewertet wird für jedes Eingabefeature das Ausmaß der Änderung an der Modellausgabe für das zurückgehaltene Testsemantikmodell. Diese Beziehung wird als Featurepriorität bezeichnet. Diese Analyse erfolgt im Rahmen der Aktualisierung nach Abschluss des Trainings. Daher dauert die Aktualisierung möglicherweise länger als durch die im Assistenten konfigurierte Trainingszeit angegeben.
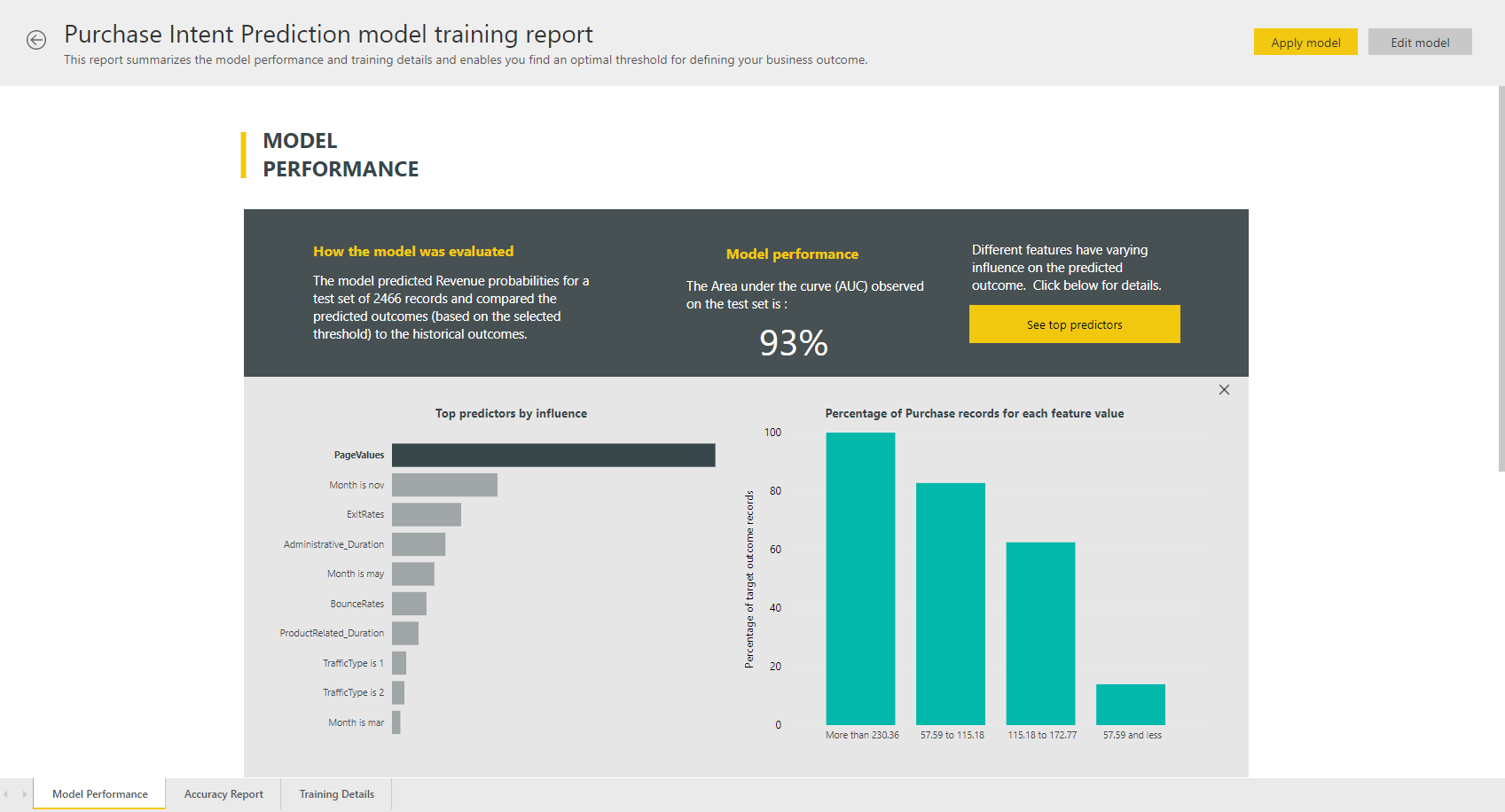
AutoML-Modellbericht
AutoML generiert einen Power BI-Bericht, der die Leistung des Modells während der Prüfung sowie die globale Featurepriorität aufzeigt. Auf diesen Bericht können Sie nach der Aktualisierung des Dataflows über die Registerkarte Machine Learning-Modell zugreifen. Der Bericht fasst die Ergebnisse der Anwendung des ML-Modells auf die zurückgehaltenen Testdaten zusammen und vergleicht die Vorhersagen mit den bekannten Ergebniswerten.
Sie können den Bericht zum Modell überprüfen, um seine Leistung zu verstehen. Sie können auch prüfen, ob die wichtigsten Einflussfaktoren des Modells mit den geschäftlichen Erkenntnissen zu den bekannten Ergebnissen übereinstimmen.
Die Diagramme und Measures, die zum Beschreiben der Modellleistung im Bericht verwendet werden, hängen vom Modelltyp ab. Diese Leistungsdiagramme und -measures werden in den folgenden Abschnitten beschrieben.
Auf weiteren Seiten des Berichts werden ggf. statistische Measures des Modells aus Data Science-Perspektive beschrieben. Der Bericht Binäre Vorhersage enthält beispielsweise ein Diagramm der Verstärkung und die Grenzwertoptimierungskurve für das Modell.
Die Berichte enthalten auch die Seite Trainingsdetails mit einer Beschreibung, wie das Modell trainiert wurde, und einem Diagramm, mit dem die Modellleistung bei den einzelnen Iterationsläufen beschrieben wird.
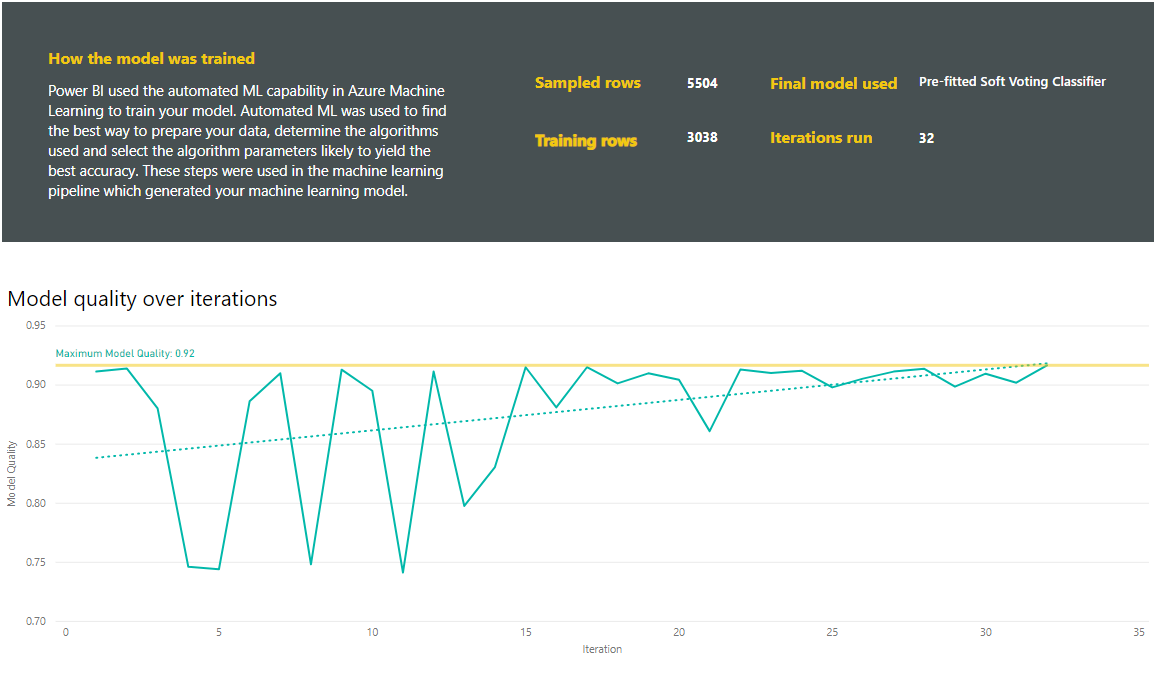
In einem weiteren Abschnitt auf dieser Seite wird neben dem erkannten Typ der Eingabespalte auch die Anrechnungsmethode beschrieben, die zum Auffüllen fehlender Werte verwendet wird. Der Abschnitt enthält auch die Parameter, die vom endgültigen Modell verwendet werden.
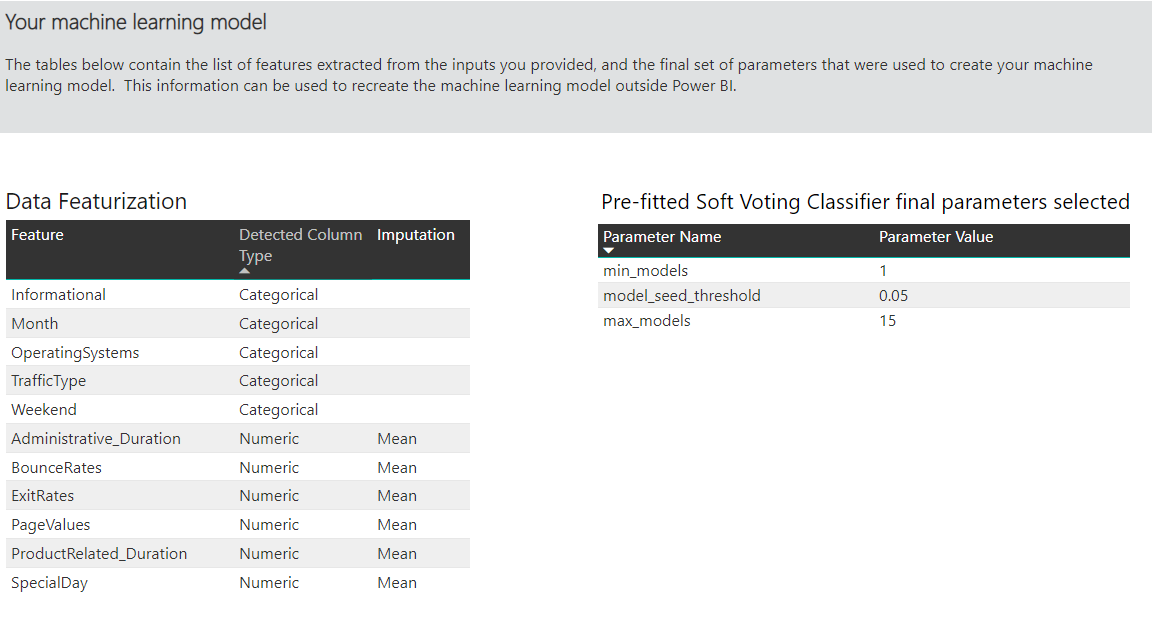
Wenn das produzierte Modell Ensemble-Lernmethoden verwendet, enthält die Seite Trainingsdetails auch ein Diagramm, mit dem die Gewichtung der einzelnen Teilmodelle im Ensemble und deren Parameter beschrieben werden.

Anwenden des AutoML-Modells
Falls Sie mit der Leistung des erstellten ML-Modells zufrieden sind, können Sie es auf neue oder aktualisierte Daten anwenden, wenn Ihr Dataflow aktualisiert wird. Wählen Sie Modellbericht rechts oben die Schaltfläche Anwenden oder auf der Registerkarte Machine Learning-Modelle unter „Aktionen“ die Schaltfläche ML-Modell anwenden aus.
Um das ML-Modell anzuwenden, müssen Sie den Namen der Tabelle, auf die es angewendet werden soll, und ein Präfix für die Spalten angeben, die dieser Tabelle bei der Modellausgabe hinzugefügt werden sollen. Das Standardpräfix für die Spaltennamen ist der Modellname. Die Funktion Anwenden kann weitere spezifische Parameter für den Modelltyp enthalten.
Beim Anwenden des ML-Modells werden zwei neue Dataflowtabellen erstellt, welche die Vorhersagen und individualisierte Erklärung für die einzelnen Zeilen enthalten, die in der Ausgabetabelle bewertet werden. Wenn Sie beispielsweise das Modell PurchaseIntent auf die Tabelle OnlineShoppers anwenden, werden bei der Ausgabe die Tabellen OnlineShoppers enriched PurchaseIntent (durch OnlineShoppers erweitertes PurchaseIntent) und OnlineShoppers enriched PurchaseIntent explanations (durch OnlineShoppers erweiterte PurchaseIntent-Erklärung) erzeugt. Für die einzelnen Zeilen in der erweiterten Tabelle werden Erläuterungen in mehrere Zeilen in der erweiterten Erklärungstabelle im Eingabefeature unterteilt. Mit ExplanationIndex können die Zeilen aus der erweiterten Erklärungstabelle der Zeile in der erweiterten Tabelle zugeordnet werden.
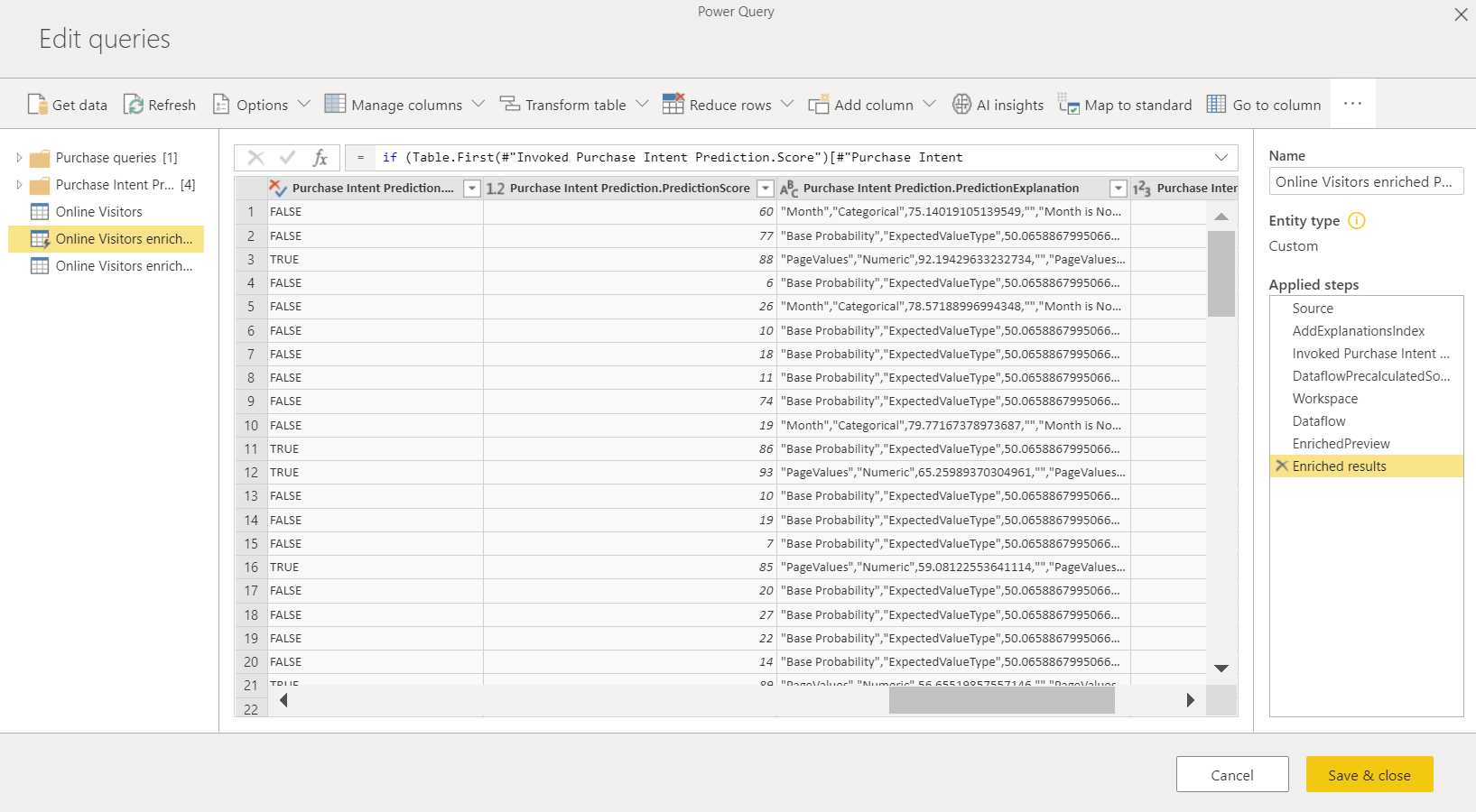
Sie können auch ein beliebiges Power BI-AutoML-Modell auf Tabellen in einem Dataflow im selben Arbeitsbereich anwenden, indem Sie KI Insights im PQO-Funktionsbrowser verwenden. Auf diese Weise können Sie von anderen Personen erstellte Modelle im selben Arbeitsbereich verwenden, ohne Besitzer des Dataflows sein zu müssen, zu dem das Modell gehört. Power Query entdeckt alle Power BI-ML-Modelle im Arbeitsbereich und macht sie als dynamische Power Query-Funktionen verfügbar. Sie können diese Funktionen aufrufen, indem Sie über das Menüband im Power Query-Editor darauf zugreifen oder indem Sie die M-Funktion direkt aufrufen. Diese Funktionalität wird derzeit nur für Power BI-Dataflows und im Power BI-Dienst für Power Query Online unterstützt. Dieses Verfahren unterscheidet sich vom Anwenden von ML-Modellen innerhalb eines Dataflows mit dem AutoML-Assistenten. Es gibt keine Erklärungstabelle, die bei Verwendung dieser Methode erstellt wird. Nur der Besitzer des Dataflows kann auf Modelltrainingsberichte zugreifen oder das Modell erneut trainieren. Wenn das Quellmodell bearbeitet wird (durch Hinzufügen oder Entfernen von Eingabespalten) oder das Modell oder der Quelldataflow gelöscht wird, funktioniert dieser abhängige Dataflow außerdem nicht mehr.

Nachdem Sie das Modell angewendet haben, werden Ihre Vorhersagen von AutoML mit jeder Aktualisierung des Dataflows ebenfalls aktualisiert.
Um die Erkenntnisse und Vorhersagen aus dem ML-Modell in einem Power BI-Bericht zu verwenden, können Sie sich in Power BI Desktop über den Connector Dataflows mit der Ausgabetabelle verbinden.
Binäre Vorhersagemodelle
Modelle zur binären Vorhersage, auch bekannt als Binärklassifizierungsmodelle, werden verwendet, um ein Semantikmodell in zwei Gruppen aufzuteilen. Sie werden für die Vorhersage von Ereignissen verwendet, die ein binäres Ergebnis aufweisen können, wie z. B. ob eine Verkaufschance in einen Abschluss konvertiert wird, ob ein Kunde abwandert, ob eine Rechnung pünktlich bezahlt wird, ob eine Transaktion betrügerisch ist usw.
Die Ausgabe eines Modells zur binären Vorhersage ist eine Wahrscheinlichkeitswert, der angibt, mit welcher Wahrscheinlichkeit das angestrebte Ergebnis erreicht wird.
Trainieren eines Modells zur binären Vorhersage
Voraussetzungen:
- Für jede Ergebnisklasse sind mindestens 20 Zeilen mit historischen Daten erforderlich.
Der Erstellungsprozess des Modells zur binären Vorhersage folgt den gleichen Schritten wie bei anderen AutoML-Modellen, die im vorherigen Abschnitt Konfigurieren der Eingaben in das ML-Modell beschrieben sind. Der Prozess unterscheidet sich lediglich im Hinblick auf den Schritt zum Auswählen eines Modells. Hier können Sie den Wert für das angestrebte Ergebnis auswählen, an dem Sie am meisten interessiert sind. Sie können auch benutzerfreundliche Beschriftungen für die Ergebnisse angeben, die im automatisch generierten Bericht verwendet werden, der die Ergebnisse der Modellüberprüfung zusammenfasst.
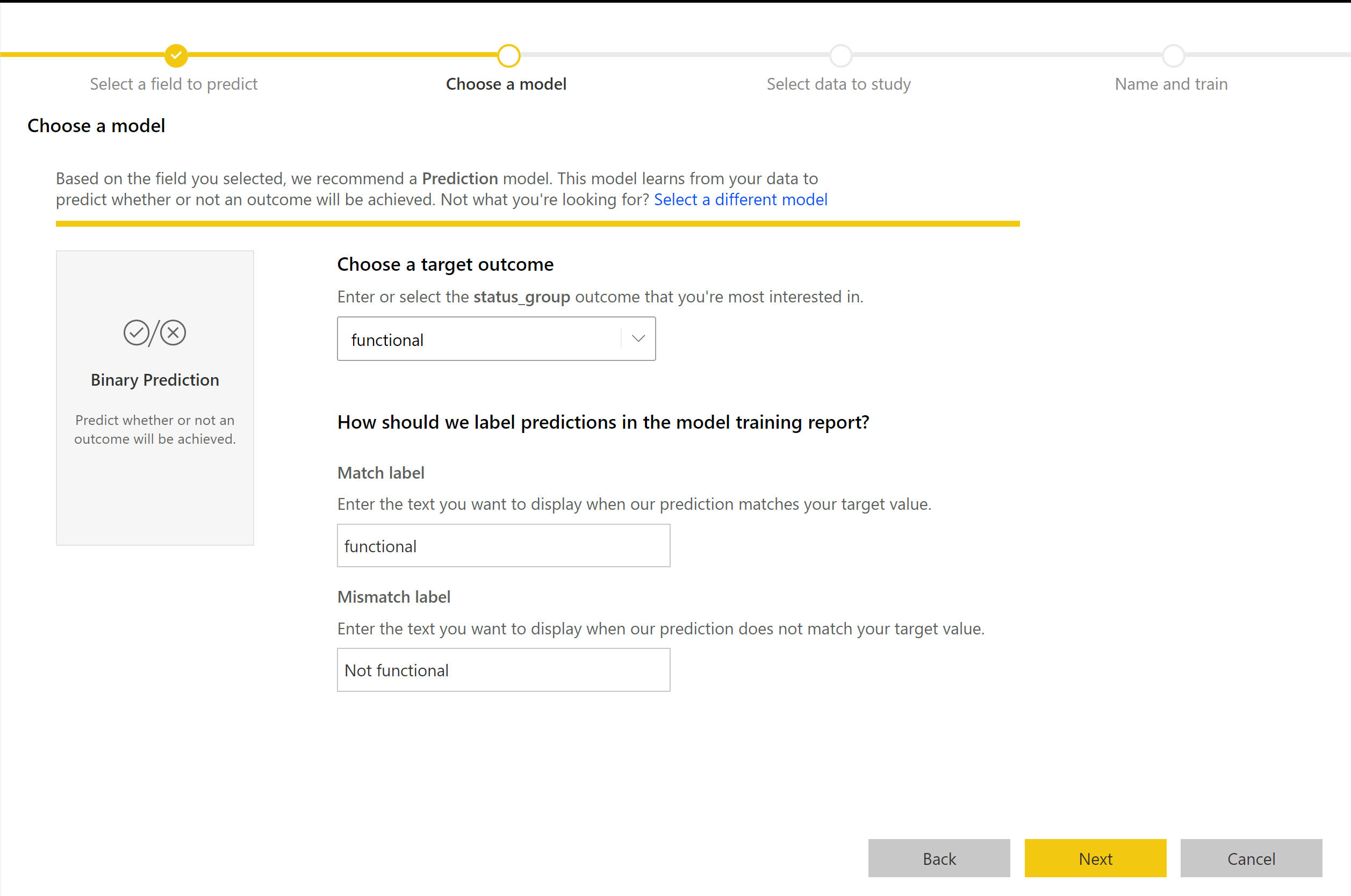
Bericht zum Modell zur binären Vorhersage
Mit dem Modell zur binären Vorhersage wird als Ausgabe ein Wert generiert, der angibt, mit welcher Wahrscheinlichkeit eine Zeile das angestrebte Ergebnis erreichen wird. Der Bericht enthält einen Schieberegler für den Wahrscheinlichkeitsschwellenwert, der beeinflusst, wie die Werte interpretiert werden, die größer und kleiner als der Wahrscheinlichkeitsschwellenwert sind.
Im Bericht wird die Leistung des Modells als True Positives, False Positives, True Negatives und False Negatives beschrieben. „Richtige Positive“ und „Richtige Negative“ sind für die beiden Klassen in den Ergebnisdaten richtig vorhergesagte Ergebnisse. False Positives sind Zeilen, für die vorhergesagt wurde, dass sie angestrebte Ergebnisse enthalten, bei denen dies jedoch nicht der Fall ist. Umgekehrt sind False Negatives Zeilen, die angestrebte Ergebnisse enthalten, für die jedoch vorhergesagt wurde, dass sie keine angestrebten Ergebnisse enthalten.
Measures, z. B. Genauigkeit und Abruf, beschreiben die Auswirkung des Wahrscheinlichkeitsschwellenwerts auf die vorhergesagten Ergebnisse. Sie können den Datenschnitt für den Wahrscheinlichkeitsschwellenwert verwenden, um einen Schwellenwert auszuwählen, der einen ausgewogenen Kompromiss zwischen Genauigkeit und Abruf erreicht.

Der Bericht enthält darüber hinaus ein Kosten-Nutzen-Analysetool zur Ermittlung der Teilmenge der Grundgesamtheit, die zur Realisierung einer optimalen Gewinnspanne gezielt angesprochen werden muss. Mit der Kosten-Nutzen-Analyse soll der Gewinn mithilfe von geschätzten Kosten pro Einheit für die Zielsetzung und einem Gewinn pro Einheit bei Erzielung eines angestrebten Ergebnisses maximiert werden. Mit diesem Tool können Sie Ihren Wahrscheinlichkeitsschwellenwert basierend auf dem maximalen Punkt im Graphen zur Maximierung des Gewinns auswählen. Sie können den Graphen auch verwenden, um den Gewinn oder die Kosten für Ihre Auswahl des Wahrscheinlichkeitsschwellenwerts zu berechnen.
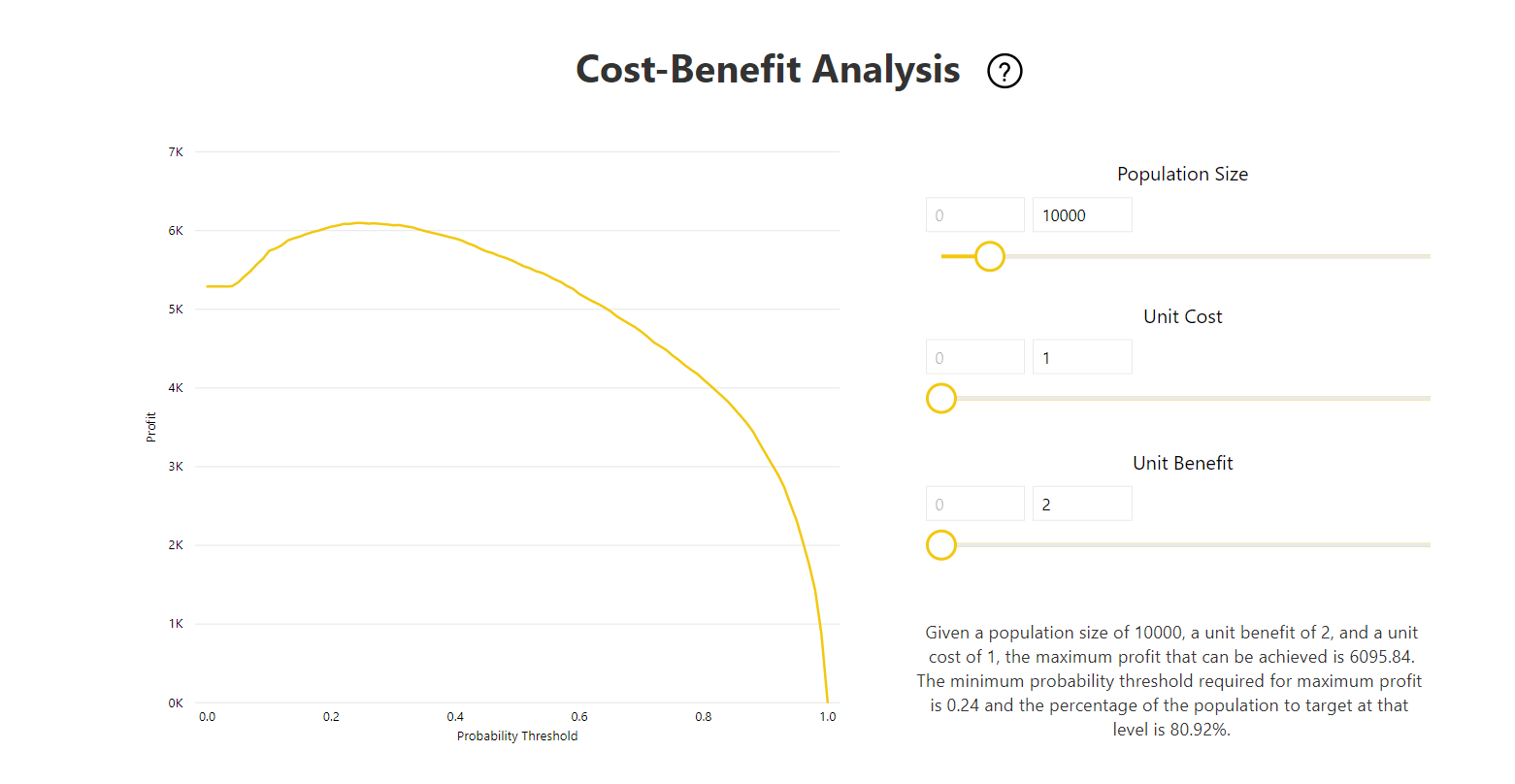
Die Seite Accuracy Report (Genauigkeitsbericht) des Modellberichts enthält das Diagramm für kumulative Verstärkungen und die Grenzwertoptimierungskurve für das Modell. Diese Daten liefern statistische Measures für die Modellleistung. Die Berichte enthalten Beschreibungen der gezeigten Diagramme.
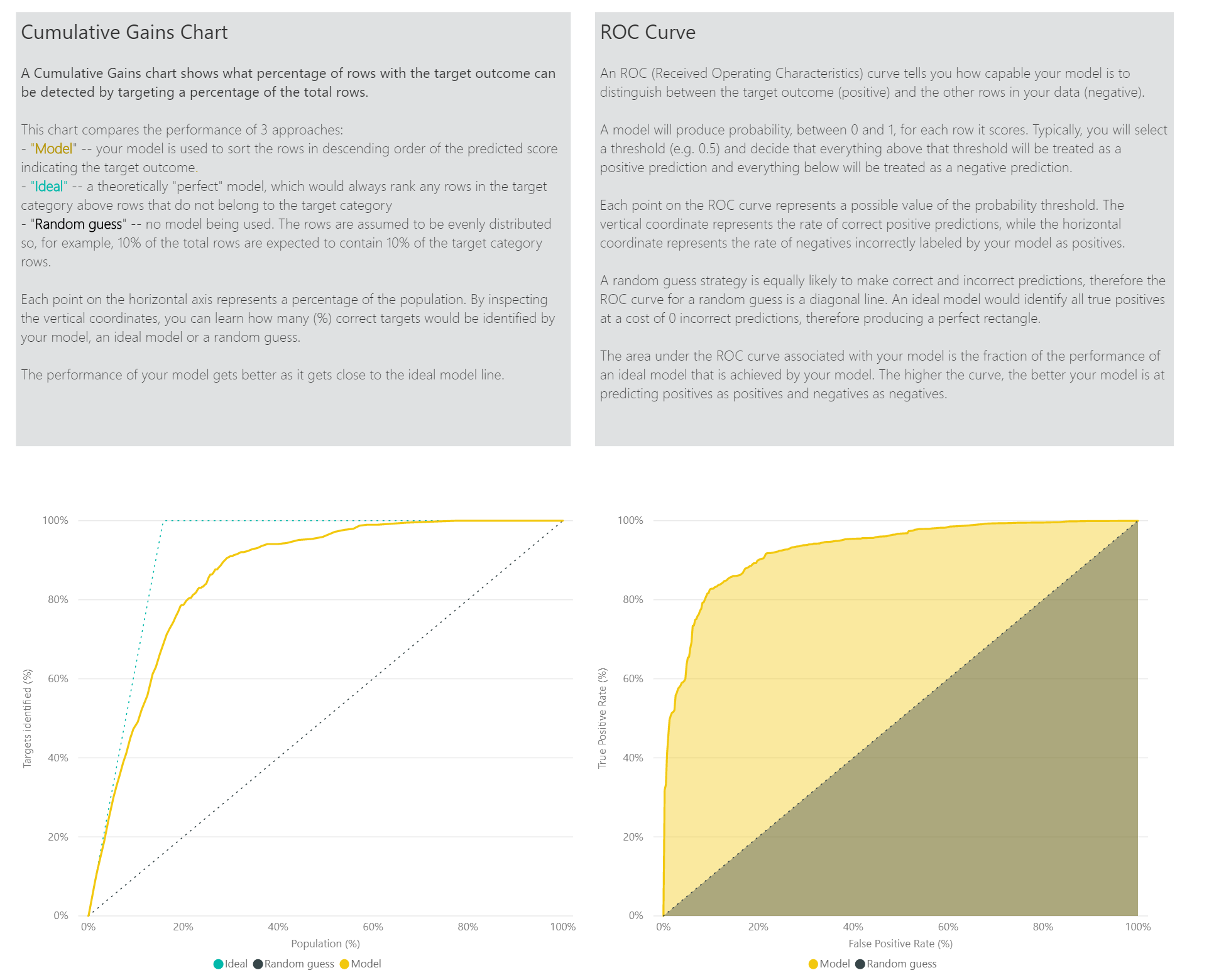
Anwenden eines Modells zur binären Vorhersage
Um ein Modell zur binären Vorhersage anwenden zu können, müssen Sie die Tabelle mit den Daten angeben, auf die Sie die Vorhersagen aus dem ML-Modell anwenden möchten. Weitere Parameter sind das Präfix für den Namen der Ausgabespalte und der Wahrscheinlichkeitsschwellenwert für die Klassifizierung des vorhergesagten Ergebnisses.
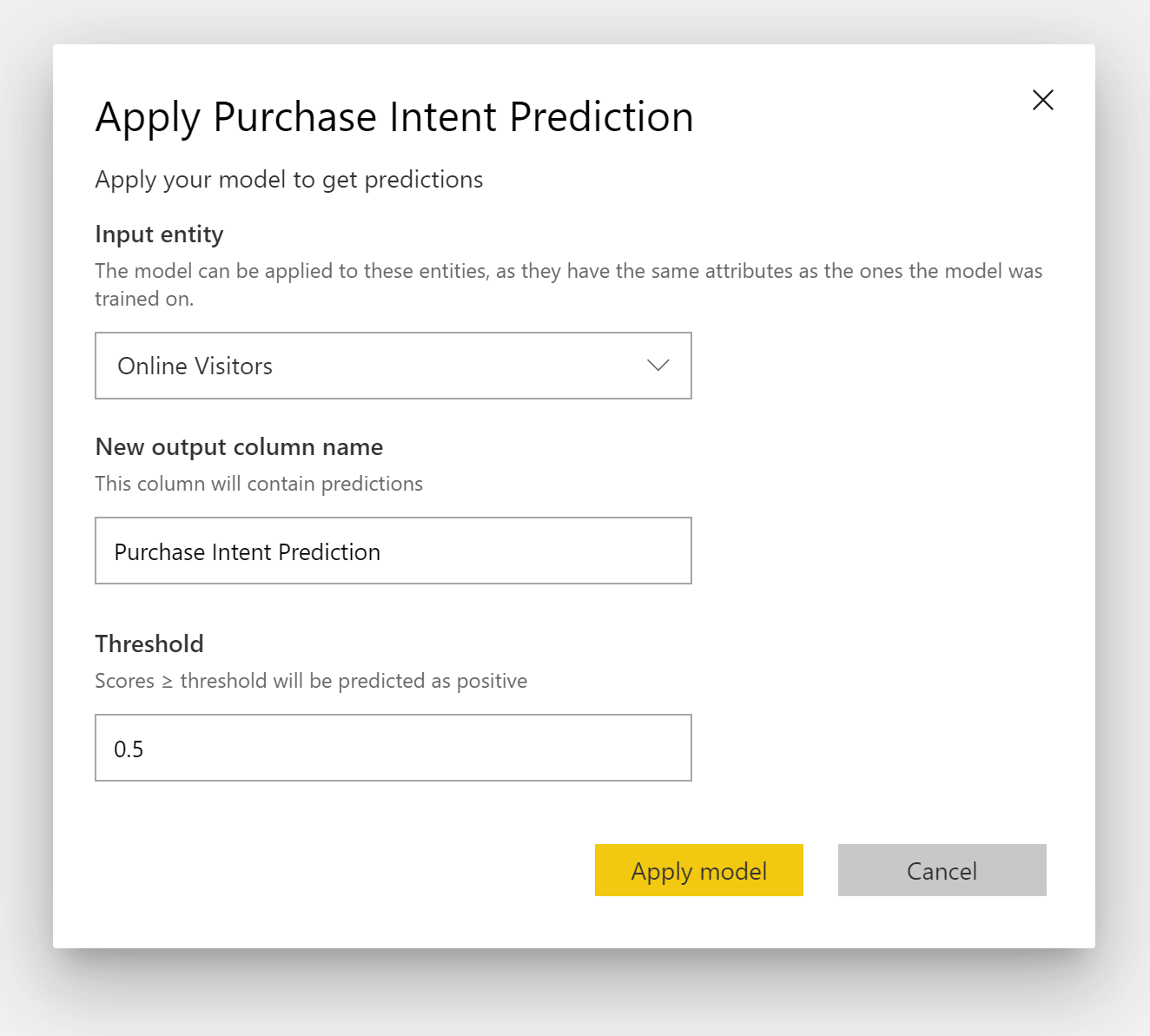
Wenn ein Modell zur binären Vorhersage angewendet wird, werden der erweiterten Ausgabetabelle vier Ausgabespalten hinzugefügt: Outcome, PredictionScore, PredictionExplanation und ExplanationIndex. Die Spaltennamen in der Tabelle haben das bei der Anwendung des Modells angegebene Präfix.
PredictionScore ist ein prozentualer Wert, der angibt, mit welcher Wahrscheinlichkeit das angestrebte Ergebnis erreicht wird.
Die Spalte Outcome enthält die vorhergesagte Ergebnisbeschriftung. Für Datensätze mit einem Wahrscheinlichkeitswert über dem Schwellenwert wird das Erreichen des angestrebten Ergebnisses als wahrscheinlich vorhergesagt. Sie sind mit „True“ gekennzeichnet. Für Datensätze unter dem Schwellenwert wird das Erreichen des Ergebnisses als unwahrscheinlich vorhergesagt. Sie sind mit „False“ gekennzeichnet.
Die Spalte PredictionExplanation enthält eine Erklärung des spezifischen Einflusses, den die Eingabefeatures auf PredictionScore hatten.
Klassifizierungsmodelle
Klassifizierungsmodelle werden verwendet, um ein Semantikmodell in mehrere Gruppen oder Klassen aufzuteilen. Diese Modelle werden verwendet, um Ereignisse vorherzusagen, die eines von mehreren möglichen Ergebnissen aufweisen können. Beispielsweise, ob ein Kunde wahrscheinlich einen hohen, mittleren oder geringen Lebensdauerwert hat. Sie können auch vorhersagen, ob das Ausfallrisiko hoch, moderat, gering usw. ist.
Die Ausgabe eines Klassifizierungsmodells ist eine Wahrscheinlichkeitsbewertung, die die Wahrscheinlichkeit angibt, dass eine Zeile die Kriterien einer bestimmten Klasse erfüllt.
Trainieren eines Klassifizierungsmodells
Die Eingabetabelle mit Ihren Trainingsdaten für ein Klassifizierungsmodell muss als Ergebnisspalte eine Zeichenfolgen- oder Ganzzahlspalte aufweisen, mit der die bisherigen bekannten Ergebnisse angegeben werden.
Voraussetzungen:
- Für jede Ergebnisklasse sind mindestens 20 Zeilen mit historischen Daten erforderlich.
Der Erstellungsprozess des Klassifizierungsmodells besteht aus den gleichen Schritten wie bei anderen AutoML-Modellen, die im vorherigen Abschnitt Konfigurieren der Eingaben in das ML-Modell beschrieben sind.
Bericht zum Klassifizierungsmodell
Power BI erstellt den Bericht zum Klassifizierungsmodell, indem das ML-Modell auf die zurückgehaltenen Testdaten angewendet wird. Anschließend wird die vorhergesagte Klasse für eine Zeile mit der tatsächlich bekannten Klasse verglichen.
Der Musterbericht enthält ein Diagramm, das die Aufschlüsselung der richtig und falsch klassifizierten Zeilen für jede bekannte Klasse enthält.
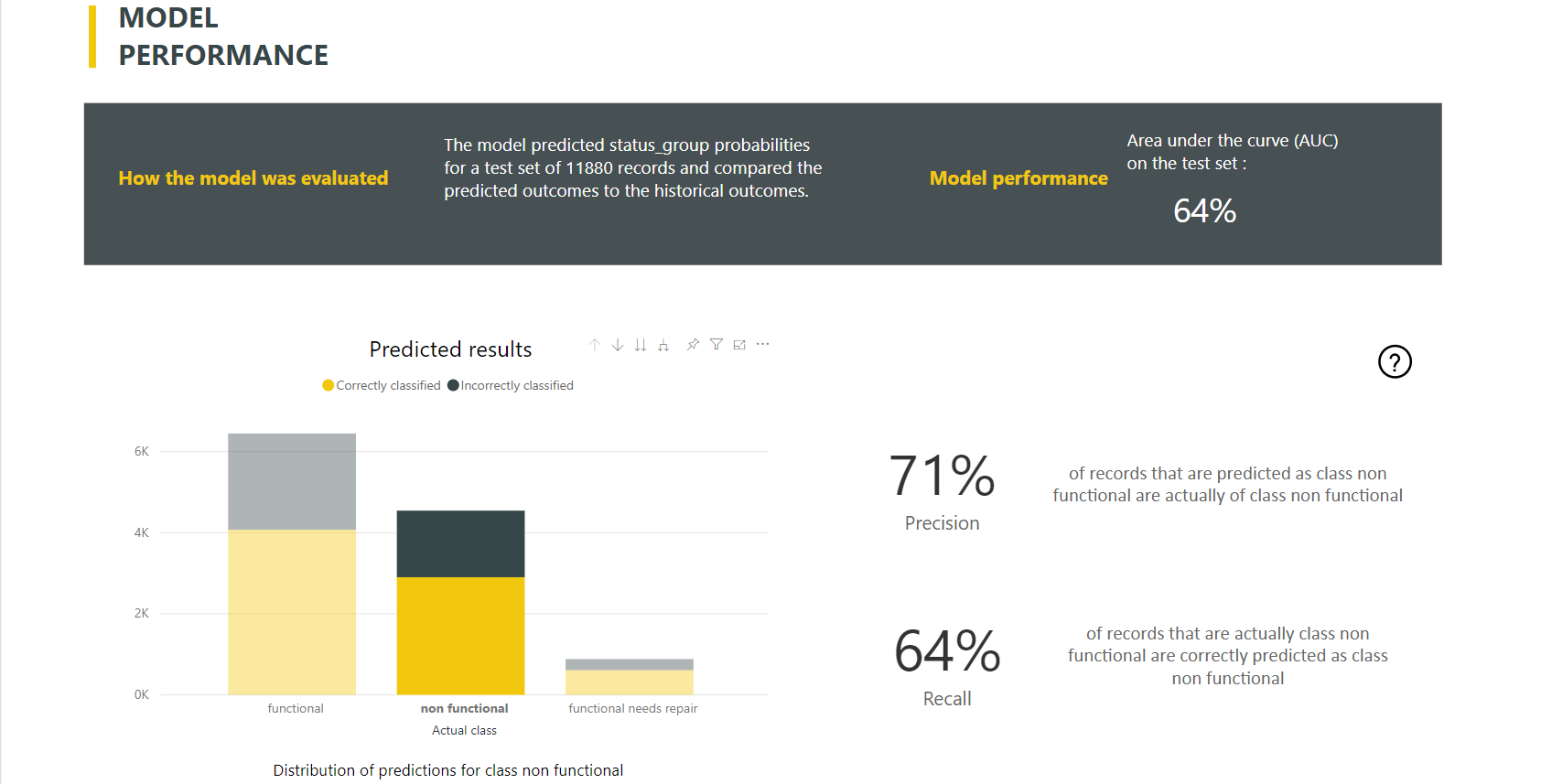
Ein weiterer klassenspezifischer Drilldownvorgang ermöglicht eine Analyse, wie die Vorhersagen für eine bekannte Klasse verteilt sind. Diese Analyse veranschaulicht auch die anderen Klassen, in denen Zeilen dieser bekannten Klasse wahrscheinlich falsch klassifiziert werden.
Die Modellerklärung im Bericht enthält auch die wichtigsten Prädiktoren für jede Klasse.
Der Bericht zum Klassifizierungsmodell enthält auch eine Seite mit Trainingsdetails ähnlich den Seiten bei anderen Modelltypen, wie zuvor im Abschnitt AutoML-Modellbericht beschrieben.
Anwenden eines Klassifizierungsmodells
Um ein ML-Modell zur Klassifizierung anzuwenden, müssen Sie die Tabelle mit den Eingangsdaten und das Präfix für den Namen der Ausgabespalte angeben.
Wenn ein Klassifizierungsmodell angewendet wird, werden der erweiterten Ausgabetabelle fünf Ausgabespalten hinzugefügt: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities und ExplanationIndex. Die Spaltennamen in der Tabelle haben das bei der Anwendung des Modells angegebene Präfix.
Die Spalte ClassProbabilities enthält die Liste der Wahrscheinlichkeitsbewertungen für die Zeile für jede mögliche Klasse.
ClassificationScore ist ein prozentualer Wert, der angibt, mit welcher Wahrscheinlichkeit eine Zeile die Kriterien einer bestimmten Klasse erfüllt.
Die Spalte ClassificationResult enthält die wahrscheinlichste vorhergesagte Klasse für die Zeile.
Die Spalte ClassificationExplanation enthält eine Erklärung des spezifischen Einflusses, den die Eingabefeatures auf ClassificationScore hatten.
Regressionsmodelle
Regressionsmodelle werden verwendet, um einen numerischen Wert vorherzusagen und können in Szenarien verwendet werden, um beispielsweise folgende Informationen zu bestimmen:
- Der Umsatz, der wahrscheinlich aus einem Verkaufsdeal erzielt wird.
- Der Lebensdauerwert eines Kontos.
- Der Betrag einer ausstehenden Rechnung, die wahrscheinlich bezahlt wird.
- Das Datum, an dem eine Rechnung bezahlt werden kann, usw.
Die Ausgabe eines Regressionsmodells ist der vorhergesagte Wert.
Trainieren eines Regressionsmodells
Die Eingabetabelle, die Ihre Trainingsdaten für ein Regressionsmodell enthält, muss als Ergebnisspalte eine numerische Spalte aufweisen, die die bekannten Ergebniswerte angibt.
Voraussetzungen:
- Für ein Regressionsmodell sind mindestens 100 Zeilen mit historischen Daten erforderlich.
Der Erstellungsprozess des Regressionsmodells besteht aus den gleichen Schritten wie bei anderen AutoML-Modellen, die im vorherigen Abschnitt Konfigurieren der Eingaben in das ML-Modell beschrieben sind.
Bericht zum Regressionsmodell
Wie bei den anderen AutoML-Modellberichten basiert der Bericht zur Regression auf den Ergebnissen der Anwendung des Modells auf die zurückgehaltenen Testdaten.
Der Modellbericht enthält ein Diagramm, das die vorhergesagten Werte mit den Istwerten vergleicht. In diesem Diagramm gibt die Entfernung von der Diagonalen den Fehler in der Vorhersage an.
Das Restfehlerdiagramm zeigt die Verteilung des Prozentsatzes des durchschnittlichen Fehlers für verschiedene Werte im zurückgehaltenen Testsemantikmodell. Die horizontale Achse stellt den Mittelwert des Istwerts für die Gruppe dar. Die Größe der Blasen veranschaulicht die Häufigkeit oder Anzahl von Werten im jeweiligen Bereich. Die vertikale Achse ist der durchschnittliche Restfehler.
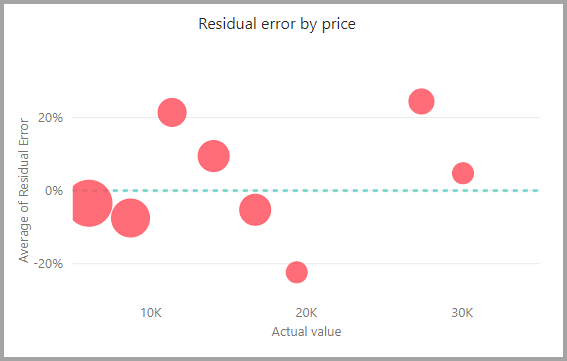
Der Bericht zum Regressionsmodell enthält auch eine Seite mit Trainingsdetails ähnlich wie in den Berichten zu anderen Modelltypen, wie im vorherigen Abschnitt AutoML-Modellbericht beschrieben.
Anwenden eines Regressionsmodells
Um ein ML-Modell zur Regression anzuwenden, müssen Sie die Tabelle mit den Eingabedaten und das Präfix für den Namen der Ausgabespalte angeben.
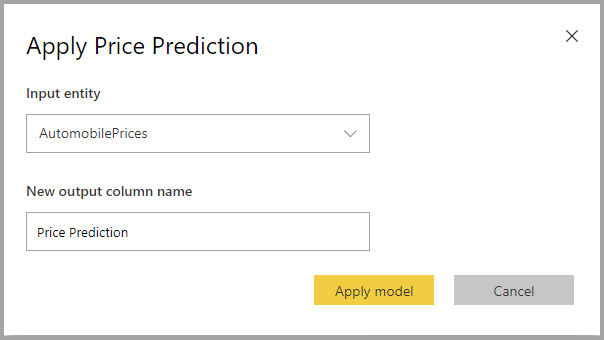
Wenn ein Regressionsmodell angewendet wird, werden der erweiterten Ausgabetabelle drei Ausgabespalten hinzugefügt: RegressionResult, RegressionExplanation und ExplanationIndex. Die Spaltennamen in der Tabelle haben das bei der Anwendung des Modells angegebene Präfix.
Die Spalte RegressionResult enthält den basierend auf den Eingabespalten vorhergesagten Wert für die Zeile. Die Spalte RegressionExplanation enthält eine Erklärung des spezifischen Einflusses, den die Eingabefelder auf RegressionResult hatten.
Azure Machine Learning-Integration in Power BI
Viele Organisationen verwenden Machine Learning-Modelle, um bessere Erkenntnisse über ihr Geschäft zu erhalten und Vorhersagen zu erstellen. Sie können maschinelles Lernen für Berichte, Dashboards und andere Analysen verwenden, um diese Erkenntnisse zu gewinnen. Die Möglichkeit, Erkenntnisse aus diesen Modellen aufzurufen und zu visualisieren, erleichtert die Weitergabe dieser Erkenntnisse an die Geschäftsbenutzer, die sie am dringendsten benötigen. Power BI vereinfacht jetzt die Integration der Erkenntnisse aus Modellen, die in Azure Machine Learning gehostet werden, über einfache Point-and-Click-Gesten.
Zur Verwendung dieser Funktion kann eine wissenschaftliche Fachkraft für Daten dem BI-Analysten einfach über das Azure-Portal Zugriff auf das Azure Machine Learning-Modell erteilen. Dann ermittelt Power Query am Anfang jeder Sitzung alle Azure Machine Learning-Modelle, auf die der Benutzer Zugriff hat, und macht sie als dynamische Power Query-Funktionen verfügbar. Der Benutzer kann dann über das Menüband im Power Query-Editor auf diese Funktionen zugreifen oder die M-Funktion direkt aufrufen. Power BI erstellt auch beim Aufrufen des Azure Machine Learning-Modells für eine Gruppe von Zeilen automatisch Batches der Zugriffsanforderungen, um eine bessere Leistung zu erzielen.
Diese Funktionalität wird derzeit nur für Power BI-Dataflows und im Power BI-Dienst für Power Query Online unterstützt.
Weitere Informationen zu Dataflows erhalten Sie unter Einführung in Dataflows und Self-Service-Datenaufbereitung.
Weitere Informationen zu Azure Machine Learning finden Sie unter:
- Übersicht: Was ist Azure Machine Learning?
- Schnellstarts und Tutorials für Azure Machine Learning: Azure Machine Learning-Dokumentation
Gewähren von Zugriff auf das Azure Machine Learning-Modell für Power BI-Benutzer
Um von Power BI aus auf ein Azure Machine Learning-Modell zugreifen zu können, benötigen Benutzer Lesezugriff auf das Azure-Abonnement und den Machine Learning-Arbeitsbereich.
Die Schritte in diesem Artikel beschreiben, wie Power BI-Benutzern Zugriff auf ein im Azure Machine Learning Service gehostetes Modell gewährt wird, damit sie als Power Query-Funktion auf dieses Modell zugreifen können. Weitere Informationen finden Sie unter Hinzufügen oder Entfernen von Azure-Rollenzuweisungen über das Azure-Portal.
Melden Sie sich beim Azure-Portal an.
Wechseln Sie zur Seite Abonnements. Sie finden die Seite Abonnements in der Liste Alle Dienste im Navigationsmenü des Azure-Portals.

Wählen Sie Ihr Abonnement aus.

Wählen Sie Zugriffssteuerung (IAM) und dann Hinzufügen aus.

Wählen Sie Leser als Rolle aus. Wählen Sie dann den Power BI-Benutzer aus, dem Sie Zugriff auf das Azure Machine Learning-Modell gewähren möchten.

Wählen Sie Speichern aus.
Wiederholen Sie die Schritte drei bis sechs, um dem Benutzer Lesezugriff auf den jeweiligen Machine Learning-Arbeitsbereich, in dem das Modell gehostet wird, zu gewähren.




Schemaermittlung für Machine Learning-Modelle
Data Scientists verwenden zum Entwickeln und sogar zum Bereitstellen ihrer Machine Learning-Modelle für Machine Learning in erster Linie Python. Der Data Scientist muss die Schemadatei explizit mit Python generieren.
Diese Schemadatei muss in den bereitgestellten Webdienst für Machine Learning-Modelle aufgenommen werden. Um das Schema für den Webdienst automatisch zu generieren, müssen Sie ein Beispiel der Eingabe/Ausgabe im Eingangsskript für das bereitgestellte Modell angeben. Weitere Informationen finden Sie unter Bereitstellen und Bewerten eines Machine Learning-Modells mithilfe eines Onlineendpunkts. Der Link beinhaltet das Beispieleingangsskript mit den Anweisungen für die Schemagenerierung.
Insbesondere verweisen die Funktionen @input_schema und @output_schema im Eingabeskript auf die Eingabe- und Ausgabebeispielformate in den Variablen input_sample und output_sample. Die Funktionen verwenden diese Beispiele, um während der Bereitstellung eine OpenAPI-Spezifikation (Swagger) für den Webdienst zu generieren.
Diese Anweisungen zur Schemagenerierung durch Aktualisieren des Eingangsskripts müssen auch auf Modelle angewendet werden, die automatisierte Experimente in Machine Learning unter Nutzung des Azure Machine Learning-SDKs verwenden.
Hinweis
Modelle, die über die grafische Benutzeroberfläche von Azure Machine Learning erstellt werden, unterstützen zurzeit keine Schemagenerierung. Diese Funktion wird jedoch in kommenden Releases implementiert.
Aufrufen des Azure Machine Learning-Modells in Power BI
Sie können ein Azure Machine Learning-Modell, auf das Ihnen Zugriff gewährt wurde, direkt über den Power Query-Editor in Ihrem Dataflow aufrufen. Wählen Sie für den Zugriff auf die Azure Machine Learning-Modelle die Schaltfläche Tabelle bearbeiten für die Tabelle aus, die Sie mit Erkenntnissen aus Ihrem Azure Machine Learning-Modell erweitern möchten, wie in der folgenden Abbildung dargestellt.

Durch Auswahl der Schaltfläche Tabelle bearbeiten wird der Power Query-Editor für die Tabellen in Ihrem Dataflow geöffnet.

Wählen Sie die Schaltfläche KI Insights im Menüband und dann im Navigationsmenü den Ordner Azure Machine Learning Models aus. Alle Azure Machine Learning-Modelle, auf die Sie Zugriff haben, werden hier als Power Query-Funktionen aufgelistet. Darüber hinaus werden die Eingabeparameter für das Azure Machine Learning-Modell automatisch als Parameter der entsprechenden Power Query-Funktion zugeordnet.
Um ein Azure Machine Learning-Modell aufzurufen, können Sie beliebige Spalten der ausgewählten Tabelle als Eingabe aus der Dropdownliste angeben. Sie können auch einen konstanten Wert angeben, der als Eingabe verwendet werden soll, indem Sie das Spaltensymbol auf der linken Seite des Eingabedialogfelds umschalten.

Wählen Sie Aufrufen aus, um die Vorschau der Ausgabe des Azure Machine Learning-Modells als neue Spalte in der Tabelle anzuzeigen. Der Modellaufruf wird als angewendeter Schritt für die Abfrage angezeigt.

Wenn das Modell mehrere Ausgabeparameter zurückgibt, werden sie als Zeile in der Ausgabespalte gruppiert. Sie können die Spalte erweitern, um einzelne Ausgabeparameter in separaten Spalten zu erzeugen.

Nach dem Speichern Ihres Dataflows wird das Modell automatisch aufgerufen, wenn der Dataflow aktualisiert wird, um etwaige neue oder aktualisierte Zeilen in der Tabelle zu berücksichtigen.
Überlegungen und Einschränkungen
- Dataflows Gen2 ist derzeit nicht in automatisiertes maschinelles Lernen integriert.
- KI Insights (Cognitive Services und Azure Machine Learning-Modelle) wird auf Computern mit eingerichteter Proxyauthentifizierung nicht unterstützt.
- Azure Machine Learning-Modelle werden für Gastbenutzer nicht unterstützt.
- Es gibt einige bekannte Probleme bei Verwendung eines Gateways mit AutoML und Cognitive Services. Wenn ein Gateway erforderlich ist, empfehlen wir, einen Dataflow zu erstellen, der die erforderlichen Daten zuerst über das Gateway importiert. Erstellen Sie dann einen anderen Dataflow, der auf den ersten Dataflow verweist, um diese Modelle und KI-Funktionen zu erstellen oder anzuwenden.
- Wenn Ihre KI mit Dataflows fehlschlägt, müssen Sie möglicherweise Fast Combine aktivieren, wenn Sie KI mit Dataflows verwenden. Nachdem Sie Ihre Tabelle importiert haben und bevor Sie mit dem Hinzufügen von KI-Features beginnen, wählen Sie im Menüband Start die Optionen aus, und aktivieren Sie im daraufhin angezeigten Fenster das Kontrollkästchen neben Kombination von Daten aus mehreren Quellen zulassen, um das Feature zu aktivieren, und wählen Sie dann OK aus, um Ihre Auswahl zu speichern. Anschließend können Sie Ihrem Dataflow KI-Features hinzufügen.
Zugehöriger Inhalt
Dieser Artikel enthält eine Übersicht über automatisiertes maschinelles Lernen für Dataflows im Power BI-Dienst. Die folgenden Artikel können ebenfalls hilfreich sein.
- Tutorial: Erstellen eines Machine Learning-Modells in Power BI
- Tutorial: Verwenden von Cognitive Services in Power BI
In den folgenden Artikeln finden Sie weitere Informationen zu Dataflows und Power BI:
- Einführung in Dataflows und Self-Service-Datenaufbereitung
- Erstellen eines Dataflows
- Konfigurieren und Verwenden eines Dataflows
- Konfigurieren der Verwendung von Azure Data Lake Gen 2 für Dataflowspeicher
- Premiumfunktionen von Dataflows
- Überlegungen und Einschränkungen zu Dataflows
- Bewährte Methoden für Dataflows