Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wenn der datenfluss, den Sie entwickeln, größer und komplexer wird, finden Sie hier einige Dinge, die Sie tun können, um Ihr ursprüngliches Design zu verbessern.
Aufteilen in mehrere Datenflüsse
Führen Sie nicht alles in einem Datenfluss aus. Nicht nur ein einzelner, komplexer Datenfluss macht den Datentransformationsprozess länger, es macht es auch schwieriger, den Datenfluss zu verstehen und wiederzuverwenden. Das Aufteilen des Datenflusses in mehrere Datenflüsse kann durch Trennen von Tabellen in verschiedenen Datenflüssen oder sogar einer Tabelle in mehrere Datenflüsse erfolgen. Sie können das Konzept einer berechneten Tabelle oder einer verknüpften Tabelle verwenden, um einen Teil der Transformation in einem Datenfluss zu erstellen und in anderen Datenflüssen wiederzuverwenden.
Datenflüsse für Datentransformationen von denen für Staging/Extraktion trennen
Einige Datenflüsse nur zum Extrahieren von Daten (d. h. Staging von Datenflüssen) und andere nur zum Transformieren von Daten sind nicht nur für die Erstellung einer mehrschichtigen Architektur hilfreich, es ist auch hilfreich, die Komplexität von Datenflüssen zu verringern. Einige Schritte extrahieren nur Daten aus der Datenquelle, z. B. Abrufen von Daten, Navigation und Datentypänderungen. Indem Sie die Stagingdatenflüsse und Transformationsdatenflüsse trennen, können Sie Ihre Datenflüsse einfacher entwickeln.
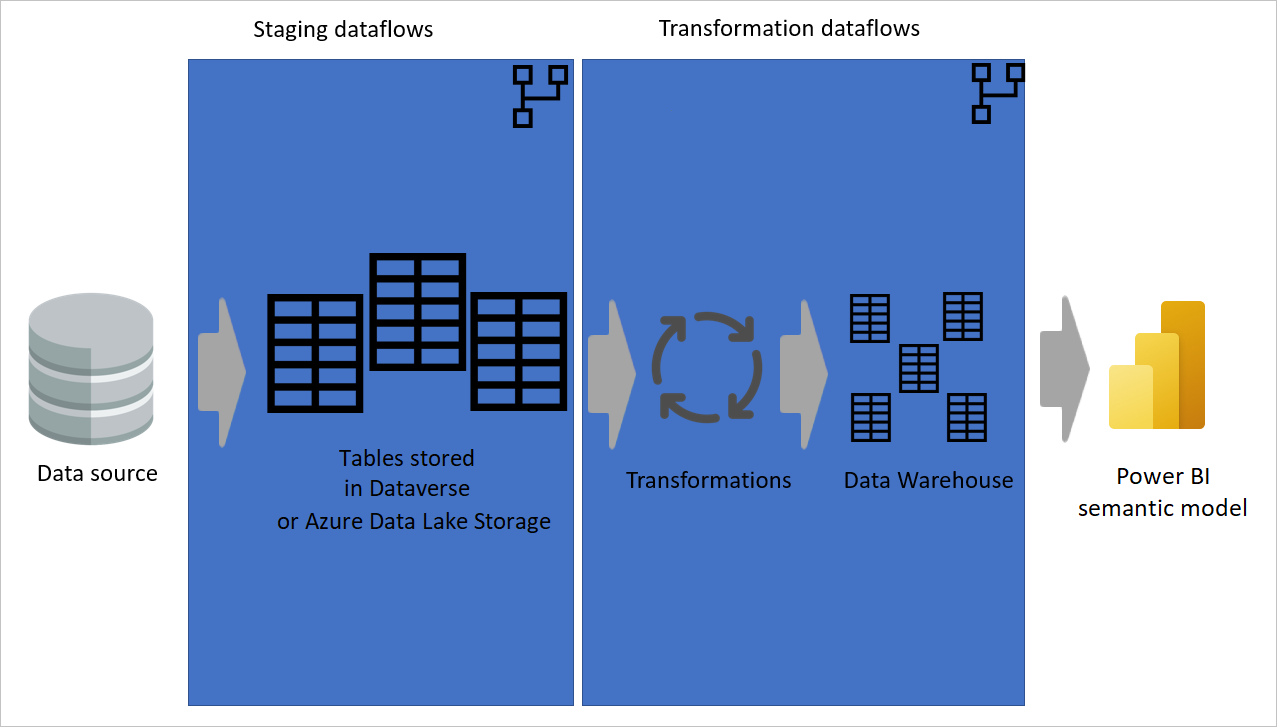
Abbildung, die zeigt, wie Daten aus einer Datenquelle extrahiert und in Datenflüsse zur Zwischenspeicherung überführt werden, wobei die Tabellen entweder in Dataverse oder Azure Data Lake Storage gespeichert werden. Anschließend werden die Daten in Transformationsdatenflüsse verschoben, in denen die Daten transformiert und in die Data Warehouse-Struktur konvertiert werden. Anschließend werden die Daten in das semantische Modell verschoben.
Verwenden von benutzerdefinierten Funktionen
Benutzerdefinierte Funktionen sind in Szenarien hilfreich, in denen eine bestimmte Anzahl von Schritten für eine Reihe von Abfragen aus verschiedenen Quellen ausgeführt werden muss. Benutzerdefinierte Funktionen können über die grafische Benutzeroberfläche im Power Query-Editor oder mithilfe eines M-Skripts entwickelt werden. Funktionen können in einem Datenfluss in beliebig vielen Tabellen wiederverwendet werden.
Wenn Sie eine benutzerdefinierte Funktion verwenden, müssen Sie nur eine einzige Version des Quellcodes verwenden, sodass Sie den Code nicht duplizieren müssen. Daher ist die Aufrechterhaltung der Power Query-Transformationslogik und des gesamten Datenflusses wesentlich einfacher. Weitere Informationen hierzu können Sie im folgenden Blogbeitrag anzeigen: Benutzerdefinierte Funktionen, die in Power BI Desktop einfach gemacht wurden.
Hinweis
Manchmal erhalten Sie möglicherweise eine Benachrichtigung, die Ihnen informiert, dass eine Premiumkapazität erforderlich ist, um einen Datenfluss mit einer benutzerdefinierten Funktion zu aktualisieren. Sie können diese Nachricht ignorieren und den Datenfluss-Editor erneut öffnen. Dadurch wird Ihr Problem in der Regel gelöst, es sei denn, Ihre Funktion bezieht sich auf eine "Load enabled"-Abfrage.
Platzieren von Abfragen in Ordnern
Die Verwendung von Ordnern für Abfragen hilft beim Gruppieren verwandter Abfragen. Verbringen Sie beim Entwickeln des Datenflusses etwas mehr Zeit, um Abfragen in Ordnern anzuordnen, die sinnvoll sind. Mit diesem Ansatz können Sie Abfragen in Zukunft einfacher finden und die Verwaltung des Codes ist viel einfacher.
Verwenden von berechneten Tabellen
Berechnete Tabellen machen Ihren Datenfluss nicht nur verständlicher, sie bieten auch eine bessere Leistung. Wenn Sie eine berechnete Tabelle verwenden, erhalten die anderen Tabellen, auf die verwiesen wird, Daten aus einer "bereits verarbeiteten und gespeicherten" Tabelle. Die Transformation ist viel einfacher und schneller.
Nutzen Sie die erweiterte Rechen-Engine
Stellen Sie für datenflüsse, die im Power BI-Verwaltungsportal entwickelt wurden, sicher, dass Sie das erweiterte Computemodul nutzen, indem Sie Verknüpfungen und Filtertransformationen zuerst in einer berechneten Tabelle durchführen, bevor Sie andere Transformationstypen ausführen.
Aufteilen vieler Schritte in mehrere Abfragen
Es ist schwierig, eine große Anzahl von Schritten in einer Tabelle nachzuverfolgen. Stattdessen sollten Sie eine große Anzahl von Schritten in mehrere Tabellen unterteilen. Sie können "Laden aktivieren" für andere Abfragen verwenden und sie deaktivieren, wenn sie Zwischenabfragen sind, und nur die endgültige Tabelle über den Datenfluss laden. Wenn Sie mehrere Abfragen haben, bei denen jeder in kleinere Schritte unterteilt ist, ist es einfacher, das Abhängigkeitsdiagramm zu verwenden und jede Abfrage für eine genauere Untersuchung zu verfolgen, anstatt sich durch Hunderte von Schritten in einer einzigen Abfrage zu arbeiten.
Hinzufügen von Eigenschaften für Abfragen und Schritte
Die Dokumentation ist der Schlüssel zur einfachen Verwaltung von Code. In Power Query können Sie den Tabellen Eigenschaften hinzufügen und auch Schritte ausführen. Der Text, den Sie in den Eigenschaften hinzufügen, wird als Tooltip angezeigt, wenn Sie mit der Maus auf diese Abfrage oder diesen Schritt zeigen. Diese Dokumentation hilft Ihnen, Ihr Modell in Zukunft zu verwalten. Mit einem Blick auf eine Tabelle oder einen Schritt können Sie verstehen, was dort passiert, anstatt zu überdenken und sich daran zu erinnern, was Sie in diesem Schritt getan haben.
Sicherstellen, dass sich die Kapazität in derselben Region befindet
Datenflüsse unterstützen derzeit nicht mehrere Länder oder Regionen. Die Premium-Kapazität muss sich in derselben Region wie Ihr Power BI-Mandant befinden.
Trennen lokaler Quellen von Cloudquellen
Es wird empfohlen, einen separaten Datenfluss für jeden Quelltyp zu erstellen, z. B. lokal, Cloud, SQL Server, Spark und Dynamics 365. Das Trennen von Datenflüssen nach Quelltyp erleichtert die schnelle Problembehandlung und vermeidet interne Grenzwerte, wenn Sie Ihre Datenflüsse aktualisieren.
Trennen von Datenflüssen basierend auf der geplanten Aktualisierung, die für Tabellen erforderlich ist
Wenn Sie eine Verkaufstransaktionstabelle haben, die alle Stunde im Quellsystem aktualisiert wird und Sie eine Produktzuordnungstabelle haben, die jede Woche aktualisiert wird, unterteilen Sie diese beiden Tabellen in zwei Datenflüsse mit unterschiedlichen Datenaktualisierungszeitplänen.
Vermeiden Sie das Einplanen von Aktualisierungen für verknüpfte Tabellen im selben Arbeitsbereich.
Wenn Sie regelmäßig aus Ihren Datenflüssen gesperrt werden, die verknüpfte Tabellen enthalten, kann dies durch einen entsprechenden, abhängigen Datenfluss im selben Arbeitsbereich verursacht werden, der während der Datenflussaktualisierung gesperrt ist. Eine solche Sperrung bietet Transaktionsgenauigkeit und stellt sicher, dass beide Datenflüsse erfolgreich aktualisiert werden, aber sie können die Bearbeitung blockieren.
Wenn Sie einen separaten Zeitplan für den verknüpften Datenfluss einrichten, können Datenflüsse unnötig aktualisiert werden und die Bearbeitung des Datenflusses blockieren. Es gibt zwei Empfehlungen, um dieses Problem zu vermeiden:
- Legen Sie keinen Aktualisierungszeitplan für einen verknüpften Datenfluss im selben Arbeitsbereich wie den Quelldatenfluss fest.
- Wenn Sie einen Aktualisierungszeitplan separat konfigurieren und das Sperrverhalten vermeiden möchten, verschieben Sie den Datenfluss in einen separaten Arbeitsbereich.