Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
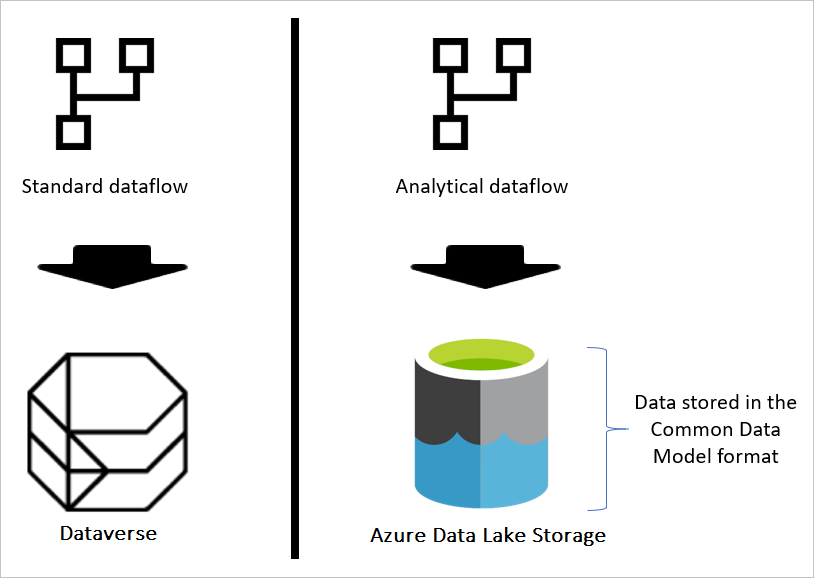
Analytische Dataflows speichern sowohl Daten als auch Metadaten in Azure Data Lake Storage. Dataflows nutzen eine Standardstruktur zum Speichern und Beschreiben der im See erstellten Daten, die als Common Data Model Folders bezeichnet wird. In diesem Artikel erfahren Sie mehr über den Speicherstandard, den Dataflows hinter den Kulissen verwenden.
Speicherung braucht eine Struktur für einen analytischen Dataflow
Wenn der Dataflow der Standard ist, dann werden die Daten in Dataverse gespeichert. Dataverse ist wie ein Datenbanksystem; es hat das Konzept von Tabellen, Ansichten und so weiter. Dataverse ist eine strukturierte Datenspeicheroption, die von Standarddatenströmen verwendet wird.
Wenn der Dataflow jedoch analytisch ist, werden die Daten in Azure Data Lake Storage gespeichert. Die Daten und Metadaten eines Dataflows werden in einem gemeinsamen Datenmodellordner gespeichert. Da in einem Speicherkonto mehrere Dataflows gespeichert sein können, wurde eine Hierarchie von Ordnern und Unterordnern eingeführt, um die Organisation der Daten zu erleichtern. Je nach Produkt, in dem der Dataflow erstellt wurde, können die Ordner und Unterordner Arbeitsbereiche (oder Umgebungen) darstellen, und dann den Ordner Common Data Model des Dataflows. Im Ordner Common Data Model werden sowohl das Schema als auch die Daten der Dataflowtabellen gespeichert. Diese Struktur entspricht den für das Gemeinsame Datenmodell festgelegten Standards.
Was ist die Speicherstruktur des Gemeinsamen Datenmodells?
Common Data Model ist eine Metadatenstruktur, die definiert wurde, um Konformität und Konsistenz bei der Verwendung von Daten über mehrere Plattformen hinweg zu gewährleisten. Common Data Model ist nicht die Datenspeicherung, sondern die Art und Weise, wie die Daten gespeichert und definiert werden.
Gemeinsame Datenmodellordner definieren, wie das Schema einer Tabelle und ihre Daten gespeichert werden sollen. In Azure Data Lake Storage sind die Daten in Ordnern organisiert. Ordner können einen Arbeitsbereich oder eine Umgebung darstellen. Unter diesen Ordnern werden Unterordner für jeden Dataflow erstellt.
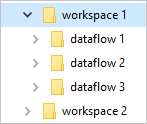
Was befindet sich in einem Dataflowordner?
Jeder Dataflowordner enthält einen Unterordner für jede Tabelle und eine Metadatendatei namens model.json.
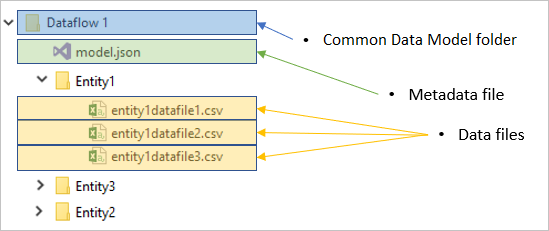
Die Metadaten-Datei: model.json
Die Datei model.json ist die Metadatendefinition des Dataflows. Dies ist die Datei, die alle Dataflow-Metadaten enthält. Sie enthält eine Liste von Tabellen, die Spalten und ihre Datentypen in jeder Tabelle, die Beziehung zwischen den Tabellen usw. Sie können diese Datei problemlos aus einem Dataflow exportieren, auch wenn Sie keinen Zugriff auf die Ordnerstruktur des Common Data Model haben.
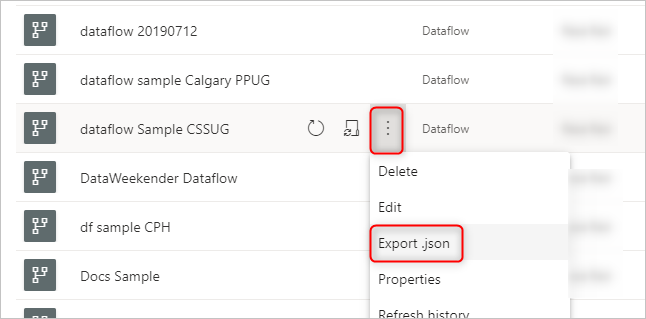
Sie können diese JSON-Datei verwenden, um Ihren Dataflow in einen anderen Arbeitsbereich oder eine andere Umgebung zu migrieren (oder zu importieren).
Was die Metadaten-Datei model.json genau enthält, erfahren Sie unter Die Metadaten-Datei (model.json) für das Common Data Model.
Datendateien
Neben der Metadaten-Datei enthält der Dataflow-Ordner weitere Unterordner. Ein Dataflow speichert die Daten für jede Tabelle in einem Unterordner mit dem Namen der Tabelle. Die Daten für eine Tabelle können in mehrere Datenpartitionen aufgeteilt sein, die im CSV-Format gespeichert werden.
Wie man die Ordner des Gemeinsamen Datenmodells sieht oder darauf zugreift
Wenn Sie Dataflows verwenden, deren Speicherplatz von dem Produkt bereitgestellt wird, in dem sie erstellt wurden, haben Sie keinen direkten Zugang zu diesen Ordnern. In solchen Fällen ist es erforderlich, die Daten aus den Dataflows mit dem Microsoft Power Platform-Dataflow-Connector abzurufen, der unter Daten abrufen in den Produkten Power BI Service, Power Apps und Dynamics 35 Customer Insights oder in Power BI Desktop verfügbar ist.
Wie Dataflows und die interne Data Lake Storage-Integration funktionieren, erfahren Sie unter Dataflows und Azure Data Lake-Integration (Vorschau).
Wenn Ihr Unternehmen Dataflows aktiviert hat, um die Vorteile seines Data Lake-Speicherkontos zu nutzen, und als Ladeziel für Dataflows ausgewählt wurde, können Sie weiterhin Daten aus dem Dataflow abrufen, indem Sie den Power Platform-Dataflow-Connector wie oben erwähnt verwenden. Sie können aber auch direkt über den Lake auf den Common Data Model-Ordner des Dataflows zugreifen, sogar außerhalb der Power Platform-Tools und -Dienste. Der Zugriff auf den See ist über das Azure-Portal, den Microsoft Azure Storage Explorer oder jeden anderen Dienst oder jede Erfahrung möglich, die Azure Data Lake Storage unterstützt. Weitere Informationen: Verbinden von Azure Data Lake Storage Gen2 für den Dataflow-Speicher
Nächste Schritte
Verwenden Sie das Common Data Model zur Optimierung von Azure Data Lake Storage Gen2
Die Metadaten-Datei (model.json) für das Gemeinsame Datenmodell
Hinzufügen eines CDM-Ordners zu Power BI als Dataflow (Vorschau)
Verbinden Sie Azure Data Lake Storage Gen2 für die Dataflowspeicherung
Konfigurieren von Datafloweinstellungen im Arbeitsbereich (Vorschauversion)