Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Power Query-Features wie fuzzy merge, cluster values, and fuzzy grouping use the same mechanisms to work as fuzzy matching.
In diesem Artikel werden viele Szenarien erläutert, die veranschaulichen, wie Sie die Optionen nutzen können, die der Fuzzy-Abgleich hat, mit dem Ziel, "Fuzzy" klar zu machen.
Hinweis
Obwohl die Option "Clusterwerte" nur in Power Query Online verfügbar ist, gelten die in diesem Abschnitt gezeigten Mechanismen auch für Fuzzyzusammenführung und Fuzzygruppierung.
Anpassen des Ähnlichkeitsschwellenwerts
Das beste Szenario für die Anwendung des Algorithmus für Fuzzyvergleiche besteht darin, dass alle Textzeichenfolgen in einer Spalte nur die Zeichenfolgen enthalten, die verglichen werden müssen, und keine zusätzlichen Komponenten. Der Vergleich mit Apples4ppl3s der Ergibt z. B. höhere Ähnlichkeitsergebnisse als vergleicht ApplesMy favorite fruit, by far, is Apples. I simply love them!.
Da das Wort Apples in der zweiten Zeichenfolge nur ein kleiner Teil der gesamten Textzeichenfolge ist, führt dieser Vergleich zu einer niedrigeren Ähnlichkeitsbewertung.
Der folgende Datensatz besteht beispielsweise aus Antworten aus einer Umfrage, die nur eine Frage hatte: "Was ist Ihre Lieblingsobst?"
| Obst |
|---|
| Heidelbeeren |
| Blaue Beeren sind einfach die besten |
| Erdbeeren |
| Erdbeeren = <3 |
| Apples |
| 'sples |
| 4ppl3s |
| Bananen |
| Fav Obst ist Bananen |
| Banas |
| Meine Lieblingsobst, weit, ist Äpfel. Ich liebe sie einfach! |
Die Umfrage stellte ein einzelnes Textfeld zur Eingabe des Werts bereit und hatte keine Überprüfung.
Jetzt werden Sie mit dem Clustering der Werte beauftragt. Laden Sie dazu die vorherige Tabelle mit Früchten in Power Query, wählen Sie die Spalte aus, und wählen Sie dann die Option "Clusterwerte " auf der Registerkarte " Spalte hinzufügen " im Menüband aus.
![]()
Das Dialogfeld "Clusterwerte " wird angezeigt, in dem Sie den Namen der neuen Spalte angeben können. Benennen Sie diesen neuen Spaltencluster , und wählen Sie "OK" aus.
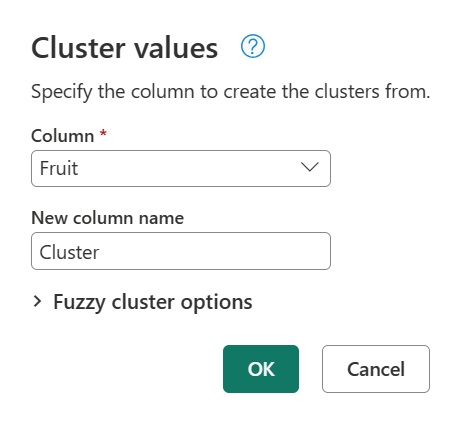
Power Query verwendet standardmäßig einen Ähnlichkeitsschwellenwert von 0,8 (oder 80%). Der Mindestwert von 0,00 bewirkt, dass alle Werte mit jeder Ähnlichkeitsstufe einander übereinstimmen, und der Maximalwert von 1,00 lässt nur genaue Übereinstimmungen zu. Eine fuzzy "genaue Übereinstimmung" ignoriert möglicherweise Unterschiede wie Groß-/Kleinschreibung, Wortreihenfolge und Interpunktion. Das Ergebnis des vorherigen Vorgangs liefert die folgende Tabelle mit einer neuen Clusterspalte .
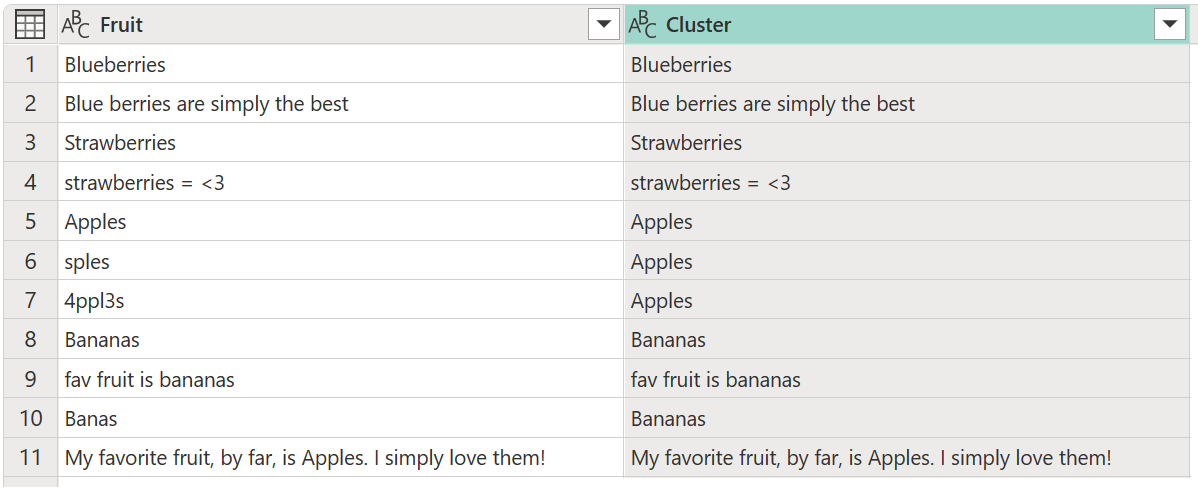
Während das Clustering abgeschlossen ist, erhalten Sie nicht die erwarteten Ergebnisse für alle Zeilen. Die Zeilennummer 2 (2) weist weiterhin den Wert Blue berries are simply the bestauf, sollte jedoch gruppiert Blueberrieswerden, und etwas ähnliches geschieht mit den Textzeichenfolgen Strawberries = <3, fav fruit is bananasund My favorite fruit, by far, is Apples. I simply love them!.
Um zu bestimmen, was dieses Clustering verursacht, doppelklicken Sie im Bereich "Angewendete Schritte" auf "Gruppierte Werte", um das Dialogfeld "Clusterwerte" wieder anzuzeigen. Erweitern Sie in diesem Dialogfeld Fuzzy-Clusteroptionen. Aktivieren Sie die Option "Ähnlichkeitsbewertungen anzeigen ", und wählen Sie dann "OK" aus.
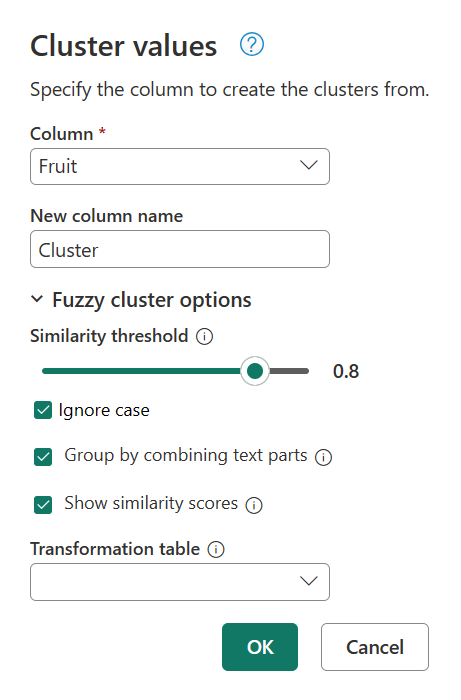
Wenn Sie die Option "Ähnlichkeitsbewertungen anzeigen " aktivieren, wird in Ihrer Tabelle eine neue Spalte erstellt. In dieser Spalte wird die genaue Ähnlichkeitsbewertung zwischen dem definierten Cluster und dem ursprünglichen Wert angezeigt.

Bei genauerer Überprüfung konnte Power Query keine anderen Werte im Ähnlichkeitsschwellenwert für die Textzeichenfolgen Blue berries are simply the best,Strawberries = <3, fav fruit is bananasund My favorite fruit, by far, is Apples. I simply love them!.
Wechseln Sie erneut zum Dialogfeld "Clusterwerte", indem Sie im Bereich "Angewendete Schritte" auf "Gruppierte Werte" doppelklicken. Ändern Sie den Ähnlichkeitsschwellenwert von 0,8 auf 0,6, und wählen Sie dann OK aus.
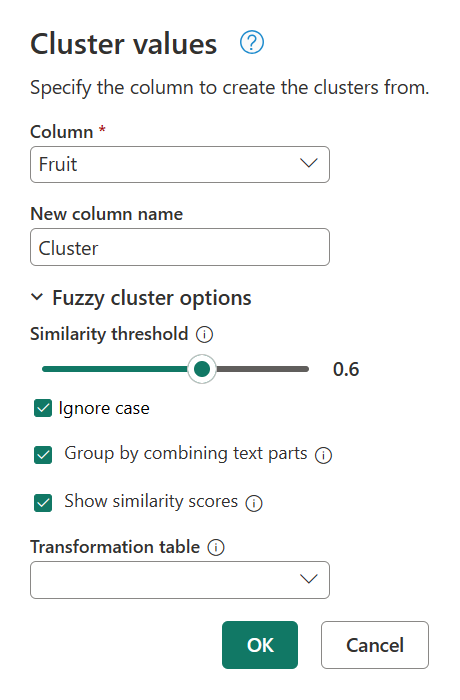
Diese Änderung nähert sich dem Ergebnis, nach dem Sie suchen, mit Ausnahme der Textzeichenfolge My favorite fruit, by far, is Apples. I simply love them!. Wenn Sie den Schwellenwert für Ähnlichkeit von 0,8 auf 0,6 geändert haben, konnte Power Query nun die Werte mit einer Ähnlichkeitsbewertung verwenden, die von 0,6 bis zu 1 beginnt.

Hinweis
Power Query verwendet immer den Wert, der dem Schwellenwert am nächsten kommt, um die Cluster zu definieren. Der Schwellenwert definiert die untere Grenze der Ähnlichkeitsbewertung, die akzeptabel ist, um den Wert einem Cluster zuzuweisen.
Sie können es erneut versuchen, indem Sie die Ähnlichkeitsbewertung von 0,6 auf eine niedrigere Zahl ändern, bis Sie die gewünschten Ergebnisse erhalten. Ändern Sie in diesem Fall die Ähnlichkeitsbewertung auf 0,5. Diese Änderung liefert das genaue Ergebnis, das Sie mit der Textzeichenfolge My favorite fruit, by far, is Apples. I simply love them! erwarten, die jetzt dem Cluster Appleszugewiesen ist.

Hinweis
Derzeit stellt nur das Feature "Clusterwerte " in Power Query Online eine neue Spalte mit der Ähnlichkeitsbewertung bereit.
Besondere Überlegungen zur Transformationstabelle
Mithilfe der Transformationstabelle können Sie Werte aus Ihrer Spalte zu neuen Werten zuordnen, bevor Sie den Fuzzyabgleichsalgorithmus ausführen.
Einige Beispiele für die Verwendung der Transformationstabelle:
- Transformationstabelle in Clusterwerten
- Transformationstabelle in Fuzzy-Zusammenführungsabfragen
- Transformationstabelle in Gruppe nach
Von Bedeutung
Wenn die Transformationstabelle verwendet wird, beträgt die maximale Ähnlichkeitsbewertung für die Werte aus der Transformationstabelle 0,95. Diese absichtliche Strafe von 0,05 ist vorhanden, um zu unterscheiden, dass der ursprüngliche Wert von dieser Spalte nicht den Werten entspricht, mit denen sie verglichen wurde, seit einer Transformation aufgetreten ist.
Für Szenarien, in denen Sie zuerst Ihre Werte zuordnen und dann den Fuzzy-Abgleich ohne 0,05 Strafe durchführen möchten, empfehlen wir, die Werte aus Ihrer Spalte zu ersetzen und dann den Fuzzy-Abgleich durchzuführen.