Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält einige Beispielszenarien für jedes der drei möglichen Ergebnisse für die Abfragefaltung. Es enthält auch einige Vorschläge, wie Sie das Beste aus dem Abfragefaltungsmechanismus herausholen können, und den Effekt, den er in Ihren Abfragen haben kann.
Das Szenario
Stellen Sie sich ein Szenario vor, in dem Sie mithilfe der Wide World Importers-Datenbank für die SQL-Datenbank von Azure Synapse Analytics eine Abfrage im Power Query-Editor erstellen, die eine Verbindung mit der fact_Sale Tabelle herstellt und die letzten 10 Verkäufe nur mit den folgenden Feldern abruft:
- Verkaufsschlüssel
- Kundenschlüssel
- Rechnungsdatenschlüssel
- Description
- Menge
Hinweis
Zu Demonstrationszwecken verwendet dieser Artikel die Datenbank, die im Lernprogramm zum Laden der Datenbank für Wide World Importers in Azure Synapse Analytics beschrieben wird. Der Hauptunterschied in diesem Artikel ist, dass die Tabelle fact_Sale nur Daten für das Jahr 2000 enthält und insgesamt 3.644.356 Zeilen umfasst.
Obwohl die Ergebnisse möglicherweise nicht genau mit den Ergebnissen übereinstimmen, die Sie erhalten, indem Sie das Lernprogramm aus der Azure Synapse Analytics-Dokumentation ausführen, besteht das Ziel dieses Artikels darin, die Kernkonzepte und Auswirkungen zu präsentieren, die die Abfragefaltung in Ihren Abfragen haben kann.

In diesem Artikel werden drei Möglichkeiten vorgestellt, um das gleiche Ergebnis mit unterschiedlichen Stufen der Abfragefaltung zu erzielen.
- Keine Abfragefaltung
- Teilweise Abfragefaltung
- Vollständige Abfragefaltung
Beispiel ohne Abfragefaltung
Von Bedeutung
Abfragen, die ausschließlich auf unstrukturierten Datenquellen basieren oder nicht über ein Computemodul verfügen, z. B. CSV- oder Excel-Dateien, verfügen nicht über Abfragefaltungsfunktionen. Dies bedeutet, dass Power Query alle erforderlichen Datentransformationen mithilfe des Power Query-Moduls auswertet.
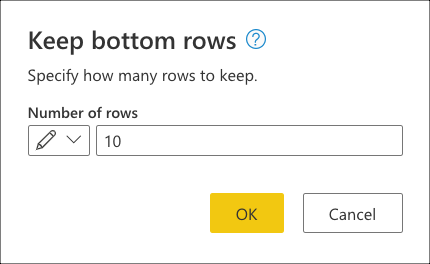
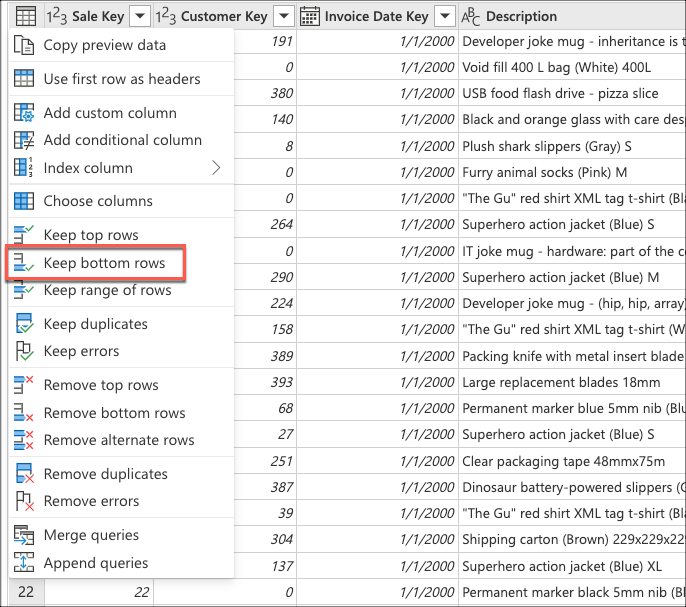
Nachdem Sie eine Verbindung mit Ihrer Datenbank hergestellt und zur fact_Sale Tabelle navigiert haben, wählen Sie die Transformation " Untere Zeilen beibehalten " in der Gruppe " Zeilen reduzieren " auf der Registerkarte " Start " aus.

Nachdem Sie diese Transformation ausgewählt haben, wird ein neues Dialogfeld angezeigt. In diesem neuen Dialogfeld können Sie die Anzahl der Zeilen eingeben, die Sie beibehalten möchten. Geben Sie für diesen Fall den Wert 10 ein, und wählen Sie dann "OK" aus.
Tipp
In diesem Fall führt die Ausführung dieses Vorgangs zum Ergebnis der letzten 10 Verkäufe. In den meisten Szenarien wird empfohlen, eine explizitere Logik bereitzustellen, die definiert, welche Zeilen zuletzt angesehen werden, indem Sie einen Sortiervorgang auf die Tabelle anwenden.
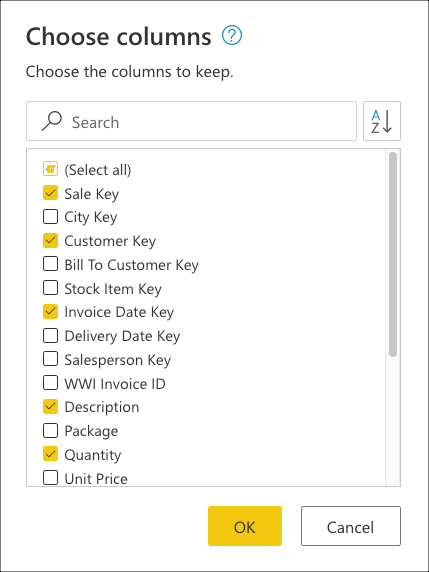
Wählen Sie als Nächstes die Transformation " Spalten auswählen " in der Gruppe " Spalten verwalten" auf der Registerkarte " Start " aus. Anschließend können Sie die Spalten auswählen, die Sie aus der Tabelle behalten möchten, und den Rest entfernen.

Wählen Sie schließlich im Dialogfeld "Spalten auswählen" die Sale KeySpalten , die Spalten Customer KeyInvoice Date KeyDescriptionQuantityund dann "OK" aus.
Das folgende Codebeispiel ist das vollständige M-Skript für die von Ihnen erstellte Abfrage:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(
#"Kept bottom rows",
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
)
in
#"Choose columns""
Keine Abfragefaltung: Grundlegendes zur Abfrageauswertung
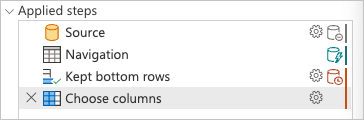
Beachten Sie unter "Angewendete Schritte " im Power Query-Editor, dass die Abfragefaltungsindikatoren für "Gespeicherte untere Zeilen" und "Spalten auswählen " als Schritte gekennzeichnet sind, die außerhalb der Datenquelle ausgewertet werden, d. h. vom Power Query-Modul.
Sie können mit der rechten Maustaste auf den letzten Schritt Ihrer Abfrage, der mit dem Namen "Spalten auswählen" versehen ist, klicken und die Option auswählen, die mit Abfrageplan anzeigen beschriftet ist. Das Ziel des Abfrageplans besteht darin, Ihnen eine detaillierte Ansicht der Ausführung Ihrer Abfrage zu bieten. Weitere Informationen zu diesem Feature finden Sie im Abfrageplan.

Jedes Feld im vorherigen Bild wird als Knoten bezeichnet. Ein Knoten stellt die Vorgangsstruktur dar, um diese Abfrage zu erfüllen. Knoten, die Datenquellen darstellen, z. B. SQL Server im vorherigen Beispiel und der Value.NativeQuery Knoten, stellen dar, welcher Teil der Abfrage in die Datenquelle entladen wird. In diesem Fall werden die restlichen Knoten, Table.LastN und Table.SelectColumns, die im Rechteck im vorherigen Bild hervorgehoben sind, von der Power Query-Engine ausgewertet. Diese beiden Knoten stellen die beiden Transformationen dar, die Sie hinzugefügt haben, Untere Zeilen beibehalten und Spalten wählen. Der Rest der Knoten stellt Vorgänge dar, die auf Datenquellenebene auftreten.
Um die genaue Anforderung anzuzeigen, die an Ihre Datenquelle gesendet wird, wählen Sie " Details anzeigen " im Value.NativeQuery Knoten aus.

Diese Datenquellenanforderung befindet sich in der nativen Sprache Ihrer Datenquelle. In diesem Fall ist diese Sprache SQL, und diese Anweisung stellt eine Anforderung für alle Zeilen und Felder aus der fact_Sale Tabelle dar.
Die Beratung dieser Datenquellenanfrage kann Ihnen helfen, die Geschichte, die der Abfrageplan zu vermitteln versucht, besser zu verstehen:
-
Sql.Database: Dieser Knoten stellt den Datenquellenzugriff dar. Stellt eine Verbindung mit der Datenbank und sendet Metadatenanforderungen, um seine Funktionen zu verstehen. -
Value.NativeQuery: Stellt die Anforderung dar, die von Power Query generiert wurde, um die Abfrage zu erfüllen. Power Query sendet die Datenanforderungen in einer nativen SQL-Anweisung an die Datenquelle. In diesem Fall stellt das alle Datensätze und Felder (Spalten) aus derfact_SaleTabelle dar. Für dieses Szenario ist dieser Fall unerwünscht, da die Tabelle Millionen von Zeilen enthält und das Interesse nur in den letzten 10 liegt. -
Table.LastN: Sobald Power Query alle Datensätze aus derfact_SaleTabelle empfängt, verwendet es das Power Query-Modul, um die Tabelle zu filtern und nur die letzten 10 Zeilen beizubehalten. -
Table.SelectColumns: Power Query verwendet die Ausgabe desTable.LastN-Knotens und wendet eine neue Transformation namensTable.SelectColumnsan, die spezifische Spalten auswählt, die Sie aus einer Tabelle behalten möchten.
Für die Auswertung musste diese Abfrage alle Zeilen und Felder aus der fact_Sale Tabelle herunterladen. Diese Abfrage dauerte durchschnittlich 6 Minuten und 1 Sekunde, um in einer Standardinstanz von Power BI-Datenflüssen verarbeitet zu werden (was die Auswertung und das Laden von Daten in Datenflüsse berücksichtigt).
Beispiel zur partiellen Abfragefaltung
Nachdem Sie eine Verbindung mit der Datenbank hergestellt und zur fact_Sale Tabelle navigiert haben, wählen Sie zunächst die Spalten aus, die Sie aus der Tabelle beibehalten möchten. Wählen Sie die Transformation " Spalten auswählen " in der Gruppe " Spalten verwalten " auf der Registerkarte " Start " aus. Diese Transformation hilft Ihnen, die Spalten explizit auszuwählen, die Sie aus der Tabelle behalten möchten, und den Rest zu entfernen.
Im Dialogfeld Spalten auswählen wählen Sie die Sale Key, Customer Key, Invoice Date Key, Description und Quantity Spalten aus und klicken dann auf OK.
Sie erstellen nun logik, die die Tabelle sortiert, um den letzten Umsatz am Ende der Tabelle zu haben. Wählen Sie die Sale Key Spalte aus, bei der es sich um den Primärschlüssel und die inkrementelle Reihenfolge oder den Index der Tabelle handelt. Sortieren Sie die Tabelle nur mit diesem Feld in aufsteigender Reihenfolge aus dem Kontextmenü für die Spalte.

Wählen Sie als Nächstes das Kontextmenü der Tabelle aus und wählen Sie die Transformation untere Zeilen beibehalten aus.
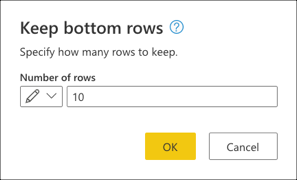
Geben Sie in "Untere Zeilen beibehalten" den Wert 10 ein, und wählen Sie dann "OK" aus.
Das folgende Codebeispiel ist das vollständige M-Skript für die von Ihnen erstellte Abfrage:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Partielles Abfragefaltungs-Beispiel: Verständnis der Abfrageauswertung
Wenn Sie den Bereich für angewendete Schritte überprüfen, stellen Sie fest, dass die Abfragefaltungsindikatoren zeigen, dass die letzte hinzugefügte Transformation als Schritt markiert ist, Kept bottom rowsder außerhalb der Datenquelle ausgewertet wird, oder mit anderen Worten vom Power Query-Modul.

Sie können mit der rechten Maustaste auf den letzten Schritt Ihrer Abfrage, den benannten Kept bottom rows, klicken und die Abfrageplanoption auswählen, um besser zu verstehen, wie Ihre Abfrage ausgewertet werden kann.

Jedes Feld im vorherigen Bild wird als Knoten bezeichnet. Ein Knoten stellt jeden Prozess dar, der (von links nach rechts) erfolgen muss, damit Ihre Abfrage ausgewertet werden kann. Einige dieser Knoten können an Ihrer Datenquelle ausgewertet werden, während andere, wie der Knoten für Table.LastN, dargestellt durch den Schritt " Beibehaltene untere Zeilen ", mithilfe des Power Query-Moduls ausgewertet werden.
Um die genaue Anforderung anzuzeigen, die an Ihre Datenquelle gesendet wird, wählen Sie " Details anzeigen " im Value.NativeQuery Knoten aus.

Diese Anforderung befindet sich in der Muttersprache Ihrer Datenquelle. In diesem Fall ist diese Sprache SQL, und diese Anweisung stellt eine Anforderung für alle Zeilen dar, wobei nur die angeforderten Felder aus der fact_Sale Tabelle nach dem Sale Key Feld sortiert sind.
Die Beratung dieser Datenquellenanfrage kann Ihnen helfen, die Geschichte besser zu verstehen, die der vollständige Abfrageplan zu vermitteln versucht. Die Reihenfolge der Knoten ist ein sequenzieller Prozess, der damit beginnt, dass die Daten aus der Datenquelle angefordert werden.
-
Sql.Database: Stellt eine Verbindung mit der Datenbank und sendet Metadatenanforderungen, um seine Funktionen zu verstehen. -
Value.NativeQuery: Stellt die von Power Query generierte Anforderung dar, um die Abfrage zu erfüllen. Power Query sendet die Datenanforderungen in einer nativen SQL-Anweisung an die Datenquelle. In diesem Fall stellt dies alle Datensätze dar, wobei nur die angeforderten Felder aus der Tabelle in derfact_SaleDatenbank nach demSales KeyFeld in aufsteigender Reihenfolge sortiert sind. -
Table.LastN: Sobald Power Query alle Datensätze aus derfact_SaleTabelle empfängt, verwendet es das Power Query-Modul, um die Tabelle zu filtern und nur die letzten 10 Zeilen beizubehalten.
Für die Auswertung musste diese Abfrage alle Zeilen und nur die erforderlichen Felder aus der fact_Sale Tabelle herunterladen. Es dauerte durchschnittlich 3 Minuten und 4 Sekunden, um in einer Standardinstanz von Power BI-Datenflüssen verarbeitet zu werden (was die Auswertung und das Laden von Daten in Datenflüsse berücksichtigt).
Vollständiges Abfragezusammenfassungsbeispiel
Nachdem Sie eine Verbindung mit der Datenbank hergestellt und zur fact_Sale Tabelle navigiert haben, wählen Sie zunächst die Spalten aus, die Sie aus der Tabelle beibehalten möchten. Wählen Sie die Transformation " Spalten auswählen " in der Gruppe " Spalten verwalten " auf der Registerkarte " Start " aus. Diese Transformation hilft Ihnen, die Spalten explizit auszuwählen, die Sie aus der Tabelle behalten möchten, und den Rest zu entfernen.
Wählen Sie in "Spalten auswählen" die Sale Key, Customer Key, Invoice Date Key, Description, und Quantity aus, und wählen Sie dann OK aus.
Sie erstellen nun Logik, mit der die Tabelle sortiert wird, um den letzten Umsatz am Anfang der Tabelle zu haben. Wählen Sie die Sale Key Spalte aus, bei der es sich um den Primärschlüssel und die inkrementelle Reihenfolge oder den Index der Tabelle handelt. Sortieren Sie die Tabelle nur mithilfe dieses Felds in absteigender Reihenfolge aus dem Kontextmenü für die Spalte.
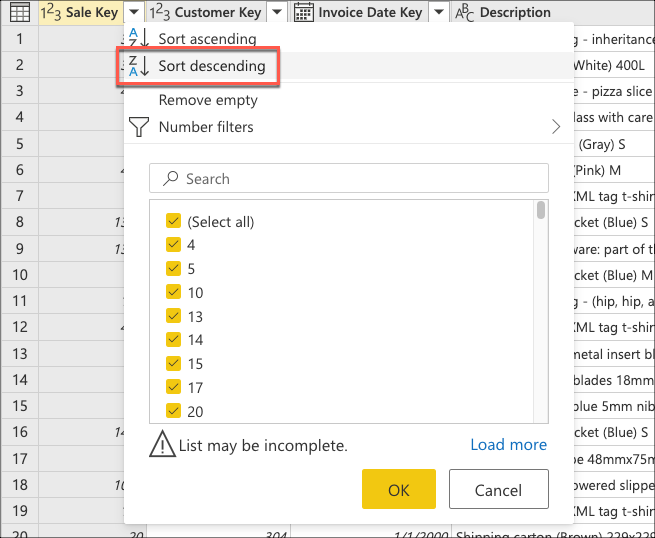
Wählen Sie als Nächstes das Kontextmenü der Tabelle aus, und wählen Sie die Transformation der obersten Zeilen beibehalten .
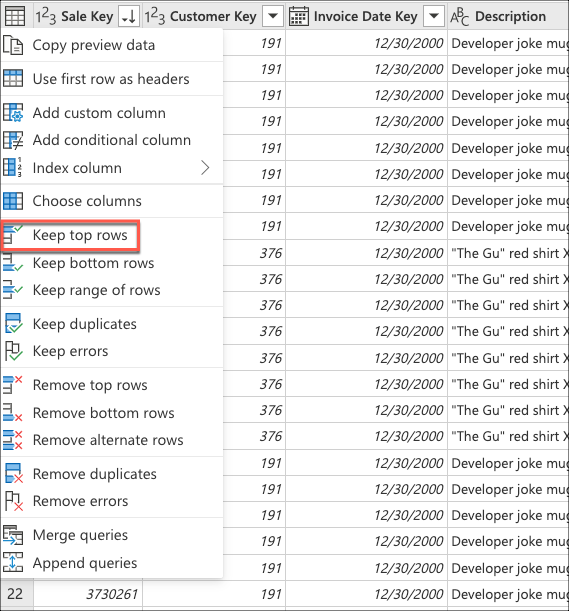
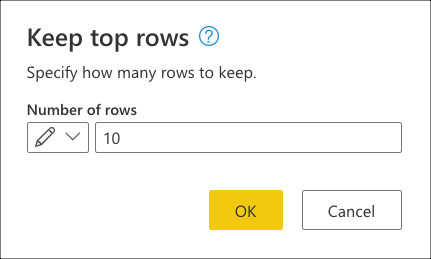
Geben Sie in Obere Zeilen beibehalten den Wert 10 ein, und wählen Sie dann OK aus.
Das folgende Codebeispiel ist das vollständige M-Skript für die von Ihnen erstellte Abfrage:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Vollständiges Abfragefaltungsbeispiel: Grundlegendes zur Abfrageauswertung
Beachten Sie beim Überprüfen des Bereichs angewendeter Schritte, dass die Abfragefaltungsindikatoren zeigen, dass die von Ihnen hinzugefügten Transformationen, "Spalten auswählen", "Sortierte Zeilen" und "Oberste Zeilen beibehalten", als Schritte gekennzeichnet sind, die an der Datenquelle ausgewertet werden.

Sie können mit der rechten Maustaste auf den letzten Schritt Ihrer Abfrage klicken, den, der Gehaltene oberste Zeilen genannt wird, und die Option Abfrageplan auswählen.

Diese Anforderung befindet sich in der Muttersprache Ihrer Datenquelle. In diesem Fall ist diese Sprache SQL, und diese Anweisung stellt eine Anforderung für alle Zeilen und Felder aus der fact_Sale Tabelle dar.
Durch die Abfrage dieser Datenquelle können Sie die Geschichte besser verstehen, die der vollständige Abfrageplan zu vermitteln versucht.
-
Sql.Database: Stellt eine Verbindung mit der Datenbank und sendet Metadatenanforderungen, um seine Funktionen zu verstehen. -
Value.NativeQuery: Stellt die von Power Query generierte Anforderung dar, um die Abfrage zu erfüllen. Power Query sendet die Datenanforderungen in einer nativen SQL-Anweisung an die Datenquelle. In diesem Fall stellt dies eine Anforderung nur für die obersten 10 Datensätze derfact_SaleTabelle dar, wobei nur die erforderlichen Felder nach der Sortierung in absteigender Reihenfolge mithilfe desSale KeyFelds vorhanden sind.
Hinweis
Es gibt zwar keine Klausel, die zum AUSWÄHLEN der unteren Zeilen einer Tabelle in der T-SQL-Sprache verwendet werden kann, aber es gibt eine TOP-Klausel, die die obersten Zeilen einer Tabelle abruft.
Für die Auswertung lädt diese Abfrage nur 10 Zeilen mit nur den Feldern herunter, die Sie aus der fact_Sale Tabelle angefordert haben. Diese Abfrage dauerte durchschnittlich 31 Sekunden, um in einer Standardinstanz von Power BI-Datenflüssen verarbeitet zu werden (was die Auswertung und das Laden von Daten in Datenflüsse berücksichtigt).
Leistungsvergleich
Um den Effekt, den die Abfragefaltung in diesen Abfragen hat, besser zu verstehen, können Sie Ihre Abfragen aktualisieren, die Zeit aufzeichnen, die zum vollständigen Aktualisieren jeder Abfrage benötigt wird, und diese vergleichen. Aus Gründen der Einfachheit bietet dieser Artikel die durchschnittliche Aktualisierungsdauer, die mithilfe des Aktualisierungsmechanismus der Power BI-Datenflüsse erfasst wird, bei der Verbindung zu einer dedizierten Azure Synapse Analytics-Umgebung mit DW2000c als Servicelevel.
Die Aktualisierungszeit für jede Abfrage lautete wie folgt:
| Example | Etikett | Zeit in Sekunden |
|---|---|---|
| Keine Abfragefaltung | Nichts | 361 |
| Teilweise Abfragefaltung | Partial | 184 |
| Vollständige Abfragefaltung | Alles | 31 |
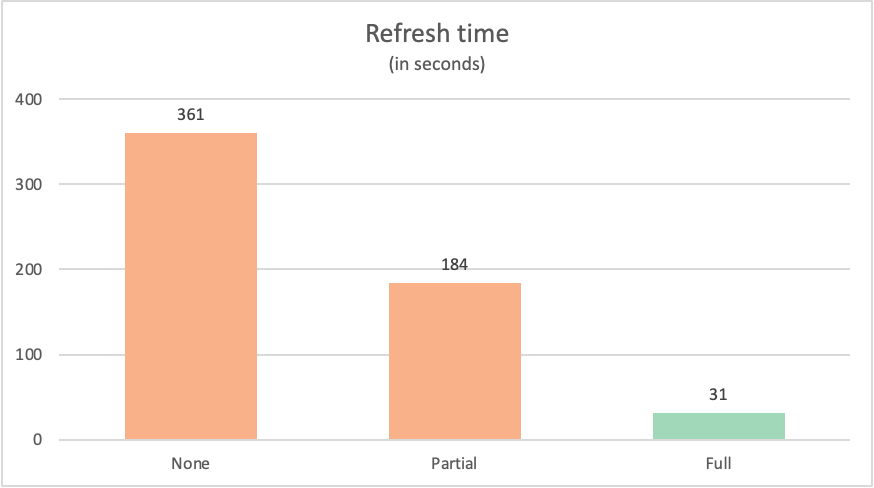
Es ist häufig der Fall, dass eine Abfrage, die vollständig in die Datenquelle zurück gefaltet wird, ähnliche Abfragen überschreibt, die nicht vollständig zurück zur Datenquelle gefaltet werden. Es könnte viele Gründe geben, warum dies der Fall ist. Diese Gründe reichen von der Komplexität der Transformationen, die Ihre Abfrage ausführt, bis hin zu den Abfrageoptimierungen, die in Ihrer Datenquelle implementiert werden, z. B. Indizes und dedizierte Computer sowie Netzwerkressourcen. Dennoch gibt es zwei Schlüsselprozesse, die von der Abfragefaltung verwendet werden, um die Auswirkungen dieser Prozesse in Power Query zu minimieren.
- Daten im Transit
- Vom Power Query-Modul ausgeführte Transformationen
In den folgenden Abschnitten wird der Effekt erläutert, den diese beiden Prozesse in den zuvor erwähnten Abfragen haben.
Daten im Transit
Wenn eine Abfrage ausgeführt wird, versucht sie, die Daten aus der Datenquelle als eines der ersten Schritte abzurufen. Welche Daten aus der Datenquelle abgerufen werden, wird durch den Abfragefaltungsmechanismus definiert. Dieser Mechanismus identifiziert die Schritte aus der Abfrage, die in die Datenquelle entladen werden können.
In der folgenden Tabelle sind die Anzahl der zeilen aufgeführt, die aus der fact_Sale Tabelle der Datenbank angefordert wurden. Die Tabelle enthält auch eine kurze Beschreibung der SQL-Anweisung, die gesendet wird, um solche Daten aus der Datenquelle anzufordern.
| Example | Etikett | Angeforderte Zeilen | Description |
|---|---|---|---|
| Keine Abfragefaltung | Nichts | 3644356 | Anforderung für alle Felder und alle Datensätze aus der fact_Sale Tabelle |
| Teilweise Abfragefaltung | Partial | 3644356 | Anforderung für alle Datensätze, aber nur erforderliche Felder aus der fact_Sale Tabelle, nachdem sie nach dem Sale Key Feld sortiert wurde |
| Vollständige Abfragefaltung | Alles | 10 | Anforderung nur für die erforderlichen Felder und die TOP 10-Datensätze der fact_Sale Tabelle, nachdem sie nach dem Sale Key Feld in absteigender Reihenfolge sortiert wurden |

Wenn Sie Daten aus einer Datenquelle anfordern, muss die Datenquelle die Ergebnisse für die Anforderung berechnen und dann die Daten an den Anforderer senden. Obwohl die Rechenressourcen bereits erwähnt wurden, können die Netzwerkressourcen, die zur Übertragung der Daten von der Datenquelle zu Power Query verwendet werden, und die Fähigkeit von Power Query, die Daten effektiv zu verarbeiten und für die lokal durchgeführten Transformationen vorzubereiten, je nach Größe der Daten einiges an Zeit beanspruchen.
Für die vorgestellten Beispiele musste Power Query mehr als 3,6 Millionen Zeilen aus der Datenquelle für die Beispiele ohne Abfragefaltung und für teilweise Abfragefaltung anfordern. Für das vollständige Abfragefaltungsbeispiel wurden nur 10 Zeilen angefordert. Für die angeforderten Felder hat das Beispiel ohne Abfragefaltung alle verfügbaren Felder aus der Tabelle abgefragt. Sowohl die teilweise Abfragefaltung als auch die vollständigen Abfragefaltungsbeispiele haben nur eine Anforderung für genau die felder übermittelt, die sie benötigten.
Vorsicht
Es wird empfohlen, inkrementelle Aktualisierungslösungen zu implementieren, die Abfragefaltung für Abfragen oder Tabellen mit großen Datenmengen verwenden. Verschiedene Produktintegrationen von Power Query implementieren Timeouts, um lange ausgeführte Abfragen zu beenden. Einige Datenquellen implementieren auch Timeouts für lange laufende Sitzungen, wenn versucht wird, kostspielige Abfragen gegen ihre Server auszuführen. Weitere Informationen: Verwenden der inkrementellen Aktualisierung mit Datenflüssen und inkrementelle Aktualisierung für semantische Modelle
Vom Power Query-Modul ausgeführte Transformationen
In diesem Artikel wurde gezeigt, wie Sie den Abfrageplan verwenden können, um besser zu verstehen, wie Ihre Abfrage ausgewertet werden kann. Innerhalb des Abfrageplans können Sie die genauen Knoten der Transformationsvorgänge sehen, die vom Power Query-Modul ausgeführt werden.
In der folgenden Tabelle werden die Knoten aus den Abfrageplänen der vorherigen Abfragen dargestellt, die vom Power Query-Modul ausgewertet wurden.
| Example | Etikett | Transformationsknoten der Power Query-Engine |
|---|---|---|
| Keine Abfragefaltung | Nichts |
Table.LastN, Table.SelectColumns |
| Teilweise Abfragefaltung | Partial | Table.LastN |
| Vollständige Abfragefaltung | Alles | — |
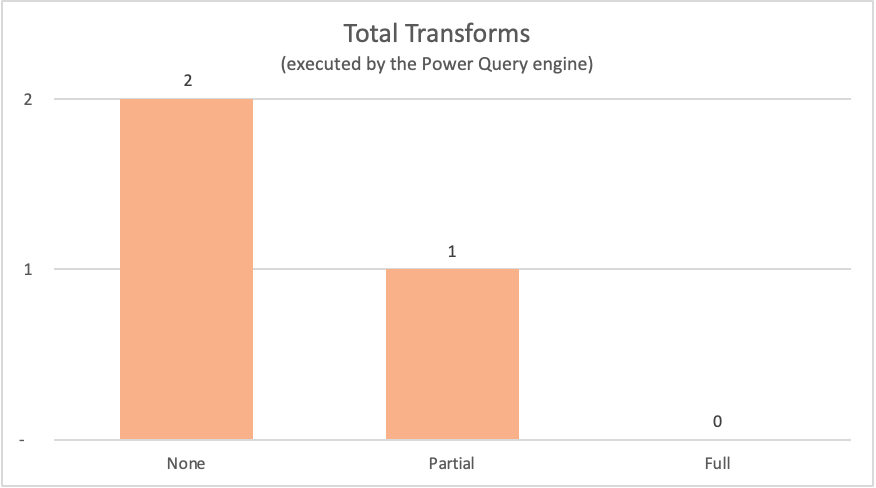
Für die in diesem Artikel vorgestellten Beispiele erfordert das vollständige Abfragefaltungsbeispiel keine Transformationen innerhalb des Power Query-Moduls, da die erforderliche Ausgabetabelle direkt aus der Datenquelle stammt. Im Gegensatz dazu mussten die beiden anderen Abfragen eine Berechnung im Power Query-Modul durchführen. Aufgrund der Datenmenge, die von diesen beiden Abfragen verarbeitet werden muss, dauert der Prozess für diese Beispiele mehr Zeit als das vollständige Abfragefaltungsbeispiel.
Transformationen können in die folgenden Kategorien gruppiert werden:
| Operatortyp | Description |
|---|---|
| Abgelegen | Operatoren, die Datenquellenknoten sind. Die Auswertung dieser Operatoren tritt außerhalb von Power Query auf. |
| Streaming | Operatoren sind Pass-Through-Operatoren. Mit einem einfachen Filter kann Table.SelectRows die Ergebnisse normalerweise direkt beim Durchlaufen des Operators filtern, ohne die Notwendigkeit, alle Zeilen zu sammeln, bevor die Daten weitergegeben werden.
Table.SelectColumns und Table.ReorderColumns sind andere Beispiele für diese Art von Operatoren. |
| Vollständige Überprüfung | Operatoren, die alle Zeilen sammeln müssen, bevor die Daten zum nächsten Operator in der Kette wechseln können. Zum Sortieren von Daten muss Power Query beispielsweise alle Daten sammeln. Weitere Beispiele für vollständige Scanoperatoren sind Table.Group, Table.NestedJoinund Table.Pivot. |
Tipp
Obwohl nicht jede Transformation aus Sicht der Leistung gleich ist, ist es in den meisten Fällen besser, weniger Transformationen zu haben.
Überlegungen und Vorschläge
- Befolgen Sie die bewährten Methoden beim Erstellen einer neuen Abfrage, wie in den bewährten Methoden in Power Query angegeben.
- Verwenden Sie die Abfragefaltungsindikatoren , um zu überprüfen, welche Schritte verhindern, dass Ihre Abfrage gefaltet wird. Ordnen Sie sie bei Bedarf neu an, um die Faltung zu verbessern.
- Verwenden Sie den Abfrageplan, um zu bestimmen, welche Transformationen im Power Query-Modul für einen bestimmten Schritt ausgeführt werden. Erwägen Sie, Ihre vorhandene Abfrage zu ändern, indem Sie Ihre Schritte neu anordnen. Überprüfen Sie dann den Abfrageplan des letzten Schritts der Abfrage erneut, und überprüfen Sie, ob der Abfrageplan besser aussieht als die vorherige. Beispielsweise verfügt der neue Abfrageplan über weniger Knoten als das vorherige, und die meisten Knoten sind "Streaming"-Knoten und nicht "vollständiger Scan". Bei Datenquellen, die das Falten unterstützen, sind im Abfrageplan alle Knoten, außer
Value.NativeQueryund den Datenquellenzugriffsknoten, Transformationen, die nicht gefaltet wurden. - Wenn verfügbar, können Sie die Option " Native Abfrage anzeigen " (oder "Datenquellenabfrage anzeigen") verwenden, um sicherzustellen, dass Ihre Abfrage wieder in die Datenquelle gefaltet werden kann. Wenn diese Option für Ihren Schritt deaktiviert ist und Sie eine Quelle verwenden, die sie normalerweise aktiviert, haben Sie einen Schritt erstellt, der die Abfragefaltung beendet. Wenn Sie eine Quelle verwenden, die diese Option nicht unterstützt, können Sie sich auf die Abfragefaltungsindikatoren und den Abfrageplan verlassen.
- Verwenden Sie die Abfragediagnosetools, um die Anforderungen, die an Ihre Datenquelle gesendet werden, besser zu verstehen, wenn Abfragefaltungsfunktionen für den Connector verfügbar sind.
- Wenn Sie Datenquellen aus der Verwendung mehrerer Connectors kombinieren, versucht Power Query, so viel Arbeit wie möglich an beide Datenquellen zu übertragen und gleichzeitig die für jede Datenquelle definierten Datenschutzstufen einzuhalten.
- Lesen Sie den Artikel zu Datenschutzstufen , um Ihre Abfragen vor einem Datenschutzfirewallfehler zu schützen.
- Verwenden Sie andere Tools, um die Abfragefaltung aus der Perspektive der von der Datenquelle empfangenen Anforderung zu überprüfen. Basierend auf dem Beispiel in diesem Artikel können Sie den Microsoft SQL Server Profiler verwenden, um die anforderungen zu überprüfen, die von Power Query gesendet und von Microsoft SQL Server empfangen wurden.
- Wenn Sie einer vollständig gefalteten Abfrage einen neuen Schritt hinzufügen und der neue Schritt ebenfalls gefaltet wird, sendet Power Query möglicherweise eine neue Anforderung an die Datenquelle, anstatt eine zwischengespeicherte Version des vorherigen Ergebnisses zu verwenden. In der Praxis kann dieser Prozess zu scheinbar einfachen Vorgängen in einer kleinen Menge von Daten führen, die länger dauern, bis sie in der Vorschau aktualisiert werden als erwartet. Diese längere Aktualisierung ist darauf zurückzuführen, dass Power Query die Datenquelle erneut abfragt, anstatt eine lokale Kopie der Daten zu deaktivieren.