Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Einleitung
Nachdem Sie die Diagnose aufgezeichnet haben, die Sie verwenden möchten, besteht der nächste Schritt darin, zu verstehen, was Sie sagen.
Es ist hilfreich, ein gutes Verständnis darüber zu haben, was genau jede Spalte im Abfragediagnoseschema bedeutet, was wir in diesem kurzen Lernprogramm nicht wiederholen werden. Hier gibt es einen vollständigen Bericht.
Im Allgemeinen empfiehlt es sich, beim Erstellen von Visualisierungen die vollständige detaillierte Tabelle zu verwenden. Denn unabhängig davon, wie viele Zeilen es sind, betrachten Sie wahrscheinlich eine Darstellung davon, wie sich die in verschiedenen Ressourcen aufgewendete Zeit summiert, oder was die ausgegebene systemeigene Abfrage war.
Wie in unserem Artikel zur Aufzeichnung der Diagnose erwähnt, arbeite ich mit den OData- und SQL-Traces für dieselbe Tabelle (oder fast dieselbe Tabelle) – die Tabelle "Kunden" aus Northwind. Insbesondere werde ich mich auf die häufigsten Anliegen unserer Kunden konzentrieren und auf eine der einfacher zu interpretierenden Gruppen von Ablaufverfolgungen eingehen: die vollständige Aktualisierung des Datenmodells.
Erstellen der Visualisierungen
Wenn Sie mit Ablaufverfolgungen arbeiten, stehen Ihnen viele Möglichkeiten zur Verfügung, diese auszuwerten. In diesem Artikel konzentrieren wir uns auf eine Aufteilung der Visualisierung in zwei Teile—einer, um die für Sie wichtigen Details anzuzeigen, und der andere, um die zeitlichen Beiträge verschiedener Faktoren leicht zu überblicken. Für die erste Visualisierung wird eine Tabelle verwendet. Sie können die Felder auswählen, die Sie möchten, aber die Felder, die für einen einfachen, allgemeinen Überblick über das Geschehen empfohlen sind:
- Id
- Startzeit
- Abfrage
- Schritt
- Datenquellenabfrage
- Exklusive Dauer (%)
- Zeilenanzahl
- Kategorie
- Ist Benutzeranfrage
- Pfad
Für die zweite Visualisierung empfiehlt sich die Verwendung eines gestapelten Säulendiagramms. Im Parameter "Axis" möchten Sie möglicherweise "ID" oder "Step" verwenden. Wenn wir die Aktualisierung betrachten, da sie nichts mit Schritten im Editor selbst zu tun hat, möchten wir wahrscheinlich nur "ID" betrachten. Für den Parameter "Legende" sollten Sie "Category" oder "Operation" (abhängig von der gewünschten Granularität) festlegen. Legen Sie für den Wert "Exklusive Dauer" fest (und stellen Sie sicher, dass es sich nicht um die %ist, sodass Sie den Rohdauerwert erhalten). Legen Sie abschließend für die QuickInfo "Früheste Startzeit" fest.
Nachdem Ihre Visualisierung erstellt wurde, stellen Sie sicher, dass Sie nach "Früheste Startzeit" aufsteigend sortieren, damit Sie die Reihenfolge der Vorgänge sehen können.
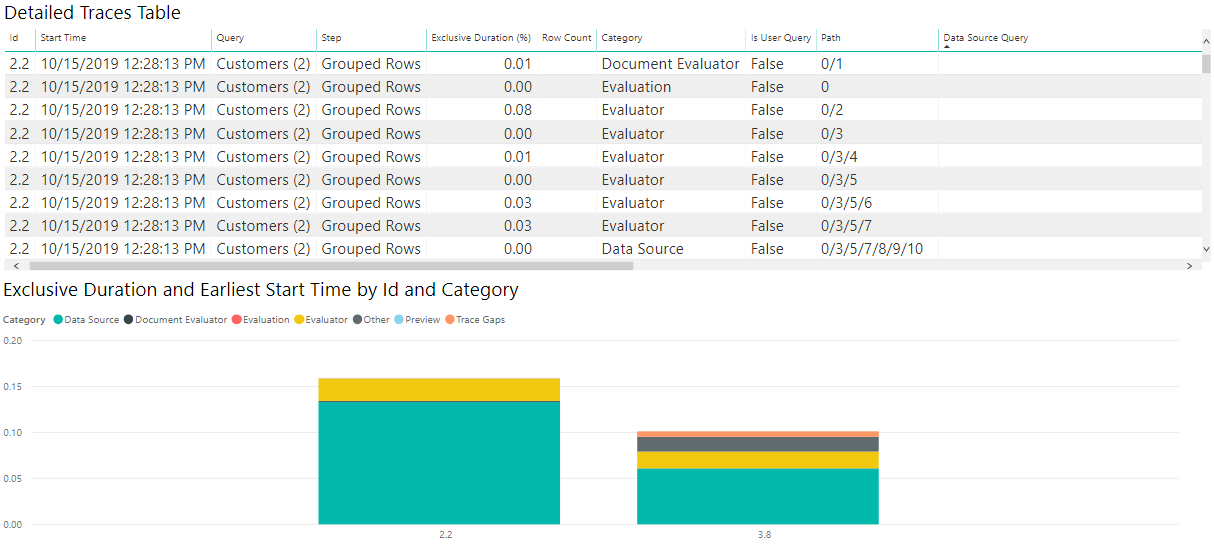
Obwohl sich Ihre genauen Anforderungen unterscheiden können, ist diese Kombination von Diagrammen ein guter Ausgangspunkt, um zahlreiche Diagnosedateien zu betrachten und für verschiedene Zwecke zu nutzen.
Interpretieren der Visualisierungen
Wie bereits erwähnt, gibt es viele Fragen, die Sie mit der Abfragediagnose beantworten können, aber die beiden, die am häufigsten angezeigt werden, fragen, wie Zeit aufgewendet wird und welche Abfrage an die Quelle gesendet wird.
Zu fragen, wie die Zeit genutzt wird, ist einfach und bei den meisten Steckverbindungen ähnlich. Eine Warnung hinsichtlich der Abfragediagnose, wie an anderer Stelle erwähnt, besteht darin, dass je nach Anschluss drastisch unterschiedliche Funktionen verfügbar sind. Viele ODBC-basierte Connectors verfügen beispielsweise nicht über eine genaue Aufzeichnung der Abfrage, die an das eigentliche Back-End-System gesendet wird, da Power Query nur sieht, was sie an den ODBC-Treiber sendet.
Wenn wir sehen möchten, wie die Zeit aufgewendet wird, können wir nur die Visualisierungen betrachten, die wir oben erstellt haben.
Wenn die Zeitwerte für die hier verwendeten Beispielabfragen so klein sind, ist es besser, die Spalte „Exklusive Dauer“ im Power Query-Editor in „Sekunden“ zu konvertieren, wenn wir mit der Zeiterfassung in Power BI arbeiten möchten. Sobald wir diese Konvertierung durchführen, können wir uns unser Diagramm ansehen und eine anständige Vorstellung davon erhalten, wo Zeit aufgewendet wird.
Für meine OData-Ergebnisse sehe ich in dem Bild, dass die überwiegende Mehrheit der Zeit für das Abrufen der Daten aus der Quelle aufgewendet wurde – wenn ich das Element "Datenquelle" in der Legende auswählte, zeigt es mir alle verschiedenen Vorgänge im Zusammenhang mit dem Senden einer Abfrage an die Datenquelle.

Wenn wir alle gleichen Vorgänge ausführen und ähnliche Visualisierungen erstellen, aber mit den SQL-Ablaufverfolgungen anstelle der ODATA-Ablaufverfolgungen können wir sehen, wie die beiden Datenquellen verglichen werden!
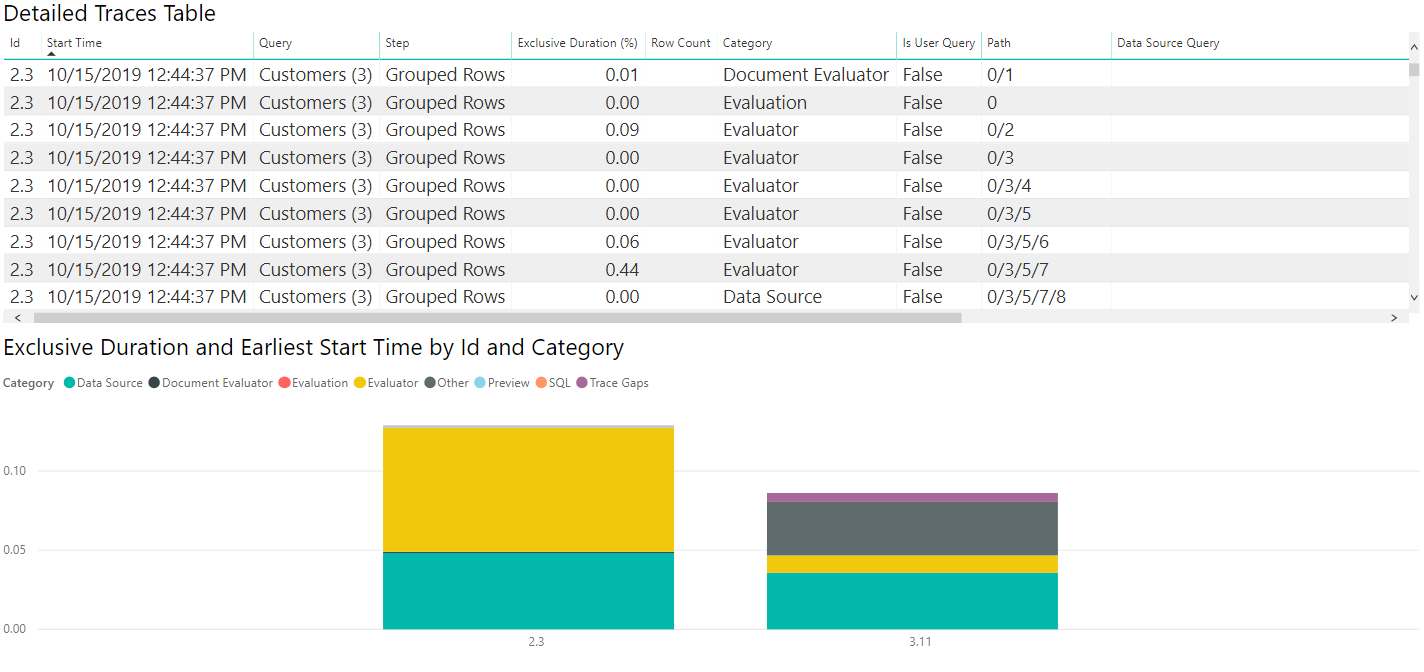
Wenn wir die Datenquelle-Tabelle auswählen, wie bei der ODATA-Diagnose sehen wir, dass die erste Auswertung (2.3 in dieser Abbildung) Metadatenabfragen ausgibt, wobei die zweite Auswertung tatsächlich die daten abruft, die wir interessieren. Da wir in diesem Fall kleine Datenmengen abrufen, dauert das Abrufen der zurückgezogenen Daten eine kleine Zeit (weniger als ein Zehntel einer Sekunde für die gesamte zweite Auswertung, wobei weniger als ein Zwanzigstel einer Sekunde für den Datenabruf selbst zutrifft), aber das gilt in allen Fällen nicht.
Wie oben beschrieben können wir die Kategorie "Datenquelle" in der Legende auswählen, um die ausgegebenen Abfragen anzuzeigen.
Eintauchen in die Daten
Betrachten von Pfaden
Wenn Sie sich dies ansehen, könnte es sein, dass die verbrachte Zeit seltsam erscheint – z. B. bei der OData-Abfrage sehen Sie möglicherweise, dass eine Datenquellenabfrage mit folgender Wert vorhanden ist:
Request:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle%20eq%20%27Sales%20Representative%27&$select=CustomerID%2CCountry HTTP/1.1
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
<Content placeholder>
Response:
Content-Type: application/json;odata.metadata=minimal;q=1.0,application/json;odata=minimalmetadata;q=0.9,application/atomsvc+xml;q=0.8,application/atom+xml;q=0.8,application/xml;q=0.7,text/plain;q=0.7
Content-Length: 435
<Content placeholder>
Diese Datenquellenabfrage ist einem Vorgang zugeordnet, der nur 1% der exklusiven Dauer in Anspruch nimmt. Unterdessen gibt es eine ähnliche:
Request:
GET https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry HTTP/1.1
Response:
https://services.odata.org/V4/Northwind/Northwind.svc/Customers?$filter=ContactTitle eq 'Sales Representative'&$select=CustomerID%2CCountry
HTTP/1.1 200 OK
Diese Datenquellenabfrage ist einem Vorgang zugeordnet, der fast 75% der exklusiven Dauer dauert. Wenn Sie den Pfad aktivieren, entdecken Sie, dass letztere tatsächlich ein Kind des ersteren ist. Dies bedeutet, dass die erste Abfrage im Wesentlichen eine kurze Zeitverzögerung verursacht hat, während der tatsächliche Datenabruf durch die 'innere' Abfrage überwacht wird.
Dies sind extreme Werte, aber sie befinden sich innerhalb der Grenzen, die angezeigt werden können.