TripPin Teil 10 - Grundlegendes Query Folding
Hinweis
Dieser Inhalt verweist derzeit auf Inhalte aus einer Vorversion-Implementierung für Protokolle in Visual Studio. Der Inhalt wird in Naher Zukunft aktualisiert, um das neue Power Query SDK in Visual Studio Code abzudecken.
Dieser mehrteilige Lehrgang behandelt die Erstellung einer neuen Datenquellenerweiterung für Power Query. Der Lehrgang sollte nacheinander durchgeführt werden - jede Lektion baut auf dem in den vorangegangenen Lektionen erstellten Connector auf und fügt dem Connector schrittweise neue Funktionen hinzu.
In dieser Lektion lernen Sie Folgendes:
- Lernen Sie die Grundlagen des Query Folding
- Erfahren Sie mehr über die Funktion Table.View
- Replizieren Sie OData Query Folding Handler für:
$top$skip$count$select$orderby
Eine der leistungsstarken Funktionen der M-Sprache ist die Möglichkeit, Transformationsarbeiten auf eine oder mehrere zugrunde liegende Datenquellen zu übertragen. Diese Fähigkeit wird als Query Folding bezeichnet (andere Tools/Technologien bezeichnen eine ähnliche Funktion auch als Predicate Pushdown oder Query Delegation).
Wenn Sie einen benutzerdefinierten Connector erstellen, der eine M-Funktion mit integrierten Abfrage-Faltfunktionen verwendet, wie OData.Feed oder Odbc.DataSource, erbt Ihr Connector diese Funktion automatisch und kostenlos.
In diesem Tutorial wird das eingebaute Query Folding-Verhalten für OData repliziert, indem Funktionshandler für die Funktion Table.View implementiert werden. In diesem Teil des Tutorials werden einige der einfacher zu implementierenden Handler implementiert (d.h. solche, die kein Parsen von Ausdrücken und keine Statusverfolgung erfordern).
Weitere Informationen zu den Abfragemöglichkeiten, die ein OData-Dienst bieten kann, finden Sie unter OData v4 URL Conventions.
Hinweis
Wie bereits erwähnt, bietet die Funktion OData.Feed automatisch die Möglichkeit, Abfragen zu falten. Da die TripPin-Serie den OData-Dienst als reguläre REST-API behandelt und Web.Contents statt OData.Feedverwendet, müssen Sie die Abfrage-Falt-Handler selbst implementieren. Für den praktischen Einsatz empfehlen wir, wann immer möglich, OData.Feed zu verwenden.
Unter Übersicht über die Abfrageauswertung und Abfrageumfaltung in Power Query finden Sie weitere Informationen zum Query Folding.
Tabelle.Ansicht verwenden
Mit der Funktion Table.View kann ein benutzerdefinierter Connector die Standardtransformationshandler für Ihre Datenquelle außer Kraft setzen. Eine Implementierung von Table.View wird eine Funktion für einen oder mehrere der unterstützten Handler bereitstellen. Wenn ein Handler nicht implementiert ist oder während der Auswertung ein error zurückgibt, greift die M-Engine auf ihren Standard-Handler zurück.
Wenn ein benutzerdefinierter Connector eine Funktion verwendet, die kein implizites Query Folding unterstützt, wie Web.Contents, werden Standardtransformationshandler immer lokal ausgeführt. Wenn die REST-API, mit der Sie eine Verbindung herstellen, Abfrageparameter als Teil der Abfrage unterstützt, können Sie mit Table.View Optimierungen hinzufügen, die es ermöglichen, die Transformationsarbeit an den Dienst zu übertragen.
Die Funktion Table.View hat die folgende Signatur:
Table.View(table as nullable table, handlers as record) as table
Ihre Implementierung umhüllt Ihre Hauptfunktion der Datenquelle. Es gibt zwei erforderliche Handler für Table.View:
GetType-gibt das erwartetetable typedes Abfrageergebnisses zurückGetRows-gibt das aktuelletableErgebnis Ihrer Datenquellenfunktion zurück
Die einfachste Umsetzung wäre etwa die folgende (Beispiel):
TripPin.SuperSimpleView = (url as text, entity as text) as table =>
Table.View(null, [
GetType = () => Value.Type(GetRows()),
GetRows = () => GetEntity(url, entity)
]);
Aktualisieren Sie die TripPinNavTable-Funktion, sodass sie TripPin.SuperSimpleView und nicht GetEntityaufruft:
withData = Table.AddColumn(rename, "Data", each TripPin.SuperSimpleView(url, [Name]), type table),
Wenn Sie die Unit-Tests erneut ausführen, werden Sie feststellen, dass sich das Verhalten Ihrer Funktion nicht geändert hat. In diesem Fall wird Ihre Table.View Implementierung einfach den Aufruf von GetEntitydurchreichen. Da Sie (noch) keine Transformationshandler implementiert haben, bleibt der ursprüngliche Parameter url unangetastet.
Erste Implementierung von Table.View
Die obige Implementierung von Table.View ist einfach, aber nicht sehr nützlich. Die folgende Implementierung dient als Grundlage - sie implementiert keine Faltfunktionalität, bietet aber das Gerüst, das Sie dafür benötigen.
TripPin.View = (baseUrl as text, entity as text) as table =>
let
// Implementation of Table.View handlers.
//
// We wrap the record with Diagnostics.WrapHandlers() to get some automatic
// tracing if a handler returns an error.
//
View = (state as record) => Table.View(null, Diagnostics.WrapHandlers([
// Returns the table type returned by GetRows()
GetType = () => CalculateSchema(state),
// Called last - retrieves the data from the calculated URL
GetRows = () =>
let
finalSchema = CalculateSchema(state),
finalUrl = CalculateUrl(state),
result = TripPin.Feed(finalUrl, finalSchema),
appliedType = Table.ChangeType(result, finalSchema)
in
appliedType,
//
// Helper functions
//
// Retrieves the cached schema. If this is the first call
// to CalculateSchema, the table type is calculated based on
// the entity name that was passed into the function.
CalculateSchema = (state) as type =>
if (state[Schema]? = null) then
GetSchemaForEntity(entity)
else
state[Schema],
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity])
in
urlWithEntity
]))
in
View([Url = baseUrl, Entity = entity]);
Wenn Sie sich den Aufruf von Table.Viewansehen, sehen Sie eine Extra-Wrapper-Funktion um den Datensatz handlers -Diagnostics.WrapHandlers. Diese Hilfsfunktion befindet sich im Diagnosemodul (das in der Lektion Hinzufügen von Diagnosen vorgestellt wurde) und bietet Ihnen eine nützliche Möglichkeit, alle von einzelnen Handlern ausgelösten Fehler automatisch zu verfolgen.
Die Funktionen GetType und GetRows werden aktualisiert, um zwei neue Hilfsfunktionen – CalculateSchema und CalculateUrl – zu nutzen. Im Moment sind die Implementierungen dieser Funktionen ziemlich einfach – Sie werden feststellen, dass sie Teile dessen enthalten, was zuvor von der Funktion GetEntity erledigt wurde.
Schließlich werden Sie feststellen, dass Sie eine interne Funktion (View) definieren, die einen state Parameter akzeptiert.
Wenn Sie weitere Handler implementieren, werden diese rekursiv die interne Funktion View aufrufen und dabei state aktualisieren und weitergeben.
Aktualisieren Sie die Funktion TripPinNavTable noch einmal, indem Sie den Aufruf von TripPin.SuperSimpleView durch einen Aufruf der neuen Funktion TripPin.View ersetzen, und führen Sie die Einheitstests erneut aus. Sie werden noch keine neuen Funktionen sehen, aber Sie haben jetzt eine solide Grundlage für Tests.
Implementierung von Query Folding
Da die M-Engine automatisch auf die lokale Verarbeitung zurückgreift, wenn eine Abfrage nicht gefaltet werden kann, müssen Sie einige Extra-Schritte unternehmen, um zu überprüfen, ob Ihre Table.View Handler korrekt funktionieren.
Die manuelle Methode zur Validierung des Faltungsverhaltens besteht darin, die URL-Anfragen Ihrer Unit-Tests mit einem Tool wie Fiddler zu beobachten. Alternativ gibt die Diagnoseprotokollierung, die Sie TripPin.Feed hinzugefügt haben, die vollständige URL aus, die die OData-Abfrage-String-Parameter enthalten sollte, die Ihre Handler hinzufügen werden.
Eine automatisierte Methode zur Validierung von Query Folding besteht darin, die Ausführung von Unit-Tests zum Scheitern zu bringen, wenn eine Abfrage nicht vollständig gefaltet wird. Sie können dies tun, indem Sie die Projekteigenschaften öffnen und Error on Folding Failure auf Truesetzen. Wenn diese Einstellung aktiviert ist, führt jede Abfrage, die eine lokale Verarbeitung erfordert, zu der folgenden Fehlermeldung:
Wir konnten den Ausdruck nicht auf die Quelle zurückführen. Bitte versuchen Sie es mit einem einfacheren Ausdruck.
Sie können dies testen, indem Sie eine neue Fact zu Ihrer Unit-Test-Datei hinzufügen, die eine oder mehrere Tabellenumwandlungen enthält.
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
)
Hinweis
Die Einstellung Error on Folding Failure ist ein "Alles-oder-Nichts"-Ansatz. Wenn Sie Abfragen testen möchten, die nicht als Teil Ihrer Unit-Tests gefaltet werden sollen, müssen Sie eine bedingte Logik hinzufügen, um die Tests entsprechend zu aktivieren/deaktivieren.
In den übrigen Abschnitten dieses Tutorials wird jeweils ein neuer Table.View Handler hinzugefügt. Sie verfolgen einen Test Driven Development (TDD) Ansatz, bei dem Sie zunächst fehlgeschlagene Unit-Tests hinzufügen und dann den M-Code implementieren, um sie zu beheben.
Die folgenden Abschnitte zum Handler beschreiben die vom Handler bereitgestellten Funktionen, die OData-äquivalente Abfragesyntax, die Unittests und die Implementierung. Bei Verwendung des zuvor beschriebenen Gerüstcodes sind für jede Handler-Implementierung zwei Änderungen erforderlich:
- Hinzufügen des Handlers zu Table.View, der den Datensatz
stateaktualisiert. - Ändern von
CalculateUrl, um die Werte vonstateabzurufen und zu den Parametern der URL und/oder des Abfrage-Strings hinzuzufügen.
Behandlung von Table.FirstN mit OnTake
Der OnTake -Handler erhält einen count -Parameter, der die maximale Anzahl von Zeilen angibt, die von GetRowsübernommen werden sollen.
In OData-Begriffen können Sie dies mit dem Abfrageparameter $top übersetzen.
Sie werden die folgenden Einheitstests verwenden:
// Query folding tests
Fact("Fold $top 1 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Airlines, 1)
),
Fact("Fold $top 0 on Airports",
#table( type table [Name = text, IataCode = text, Location = record] , {} ),
Table.FirstN(Airports, 0)
),
Diese Tests verwenden beide Table.FirstN, um die Ergebnismenge auf die erste X Anzahl von Zeilen zu filtern. Wenn Sie diese Tests mit Error on Folding Failure auf False (die Standardeinstellung) ausführen, sollten die Tests erfolgreich sein, aber wenn Sie Fiddler ausführen (oder die Trace-Protokolle überprüfen), stellen Sie fest, dass die gesendete Anforderung keine OData-Abfrageparameter enthält.
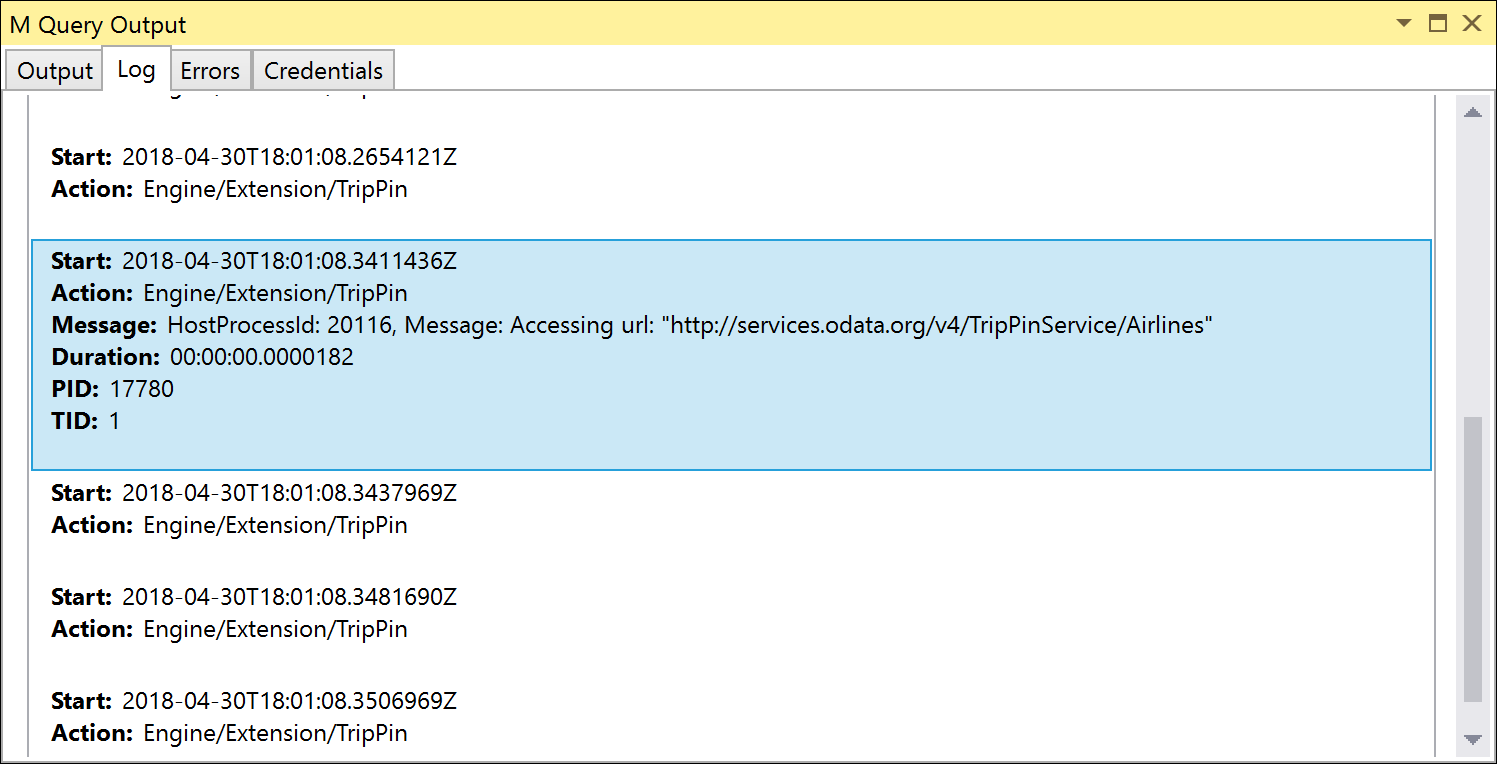
Wenn Sie Error on Folding Failure auf Truesetzen, schlagen die Tests mit dem Fehler Please try a simpler expression. fehl. Um diesen Fehler zu beheben, müssen Sie Ihren ersten Table.View Handler für OnTake definieren.
Der OnTake-Handler sieht wie der folgende Code aus:
OnTake = (count as number) =>
let
// Add a record with Top defined to our state
newState = state & [ Top = count ]
in
@View(newState),
Die Funktion CalculateUrl wird aktualisiert, um den Wert Top aus dem Datensatz state zu extrahieren und den richtigen Parameter in der Abfragezeichenfolge zu setzen.
// Calculates the final URL based on the current state.
CalculateUrl = (state) as text =>
let
urlWithEntity = Uri.Combine(state[Url], state[Entity]),
// Uri.BuildQueryString requires that all field values
// are text literals.
defaultQueryString = [],
// Check for Top defined in our state
qsWithTop =
if (state[Top]? <> null) then
// add a $top field to the query string record
defaultQueryString & [ #"$top" = Number.ToText(state[Top]) ]
else
defaultQueryString,
encodedQueryString = Uri.BuildQueryString(qsWithTop),
finalUrl = urlWithEntity & "?" & encodedQueryString
in
finalUrl
Wenn Sie die Unit-Tests erneut ausführen, werden Sie feststellen, dass die URL, auf die Sie zugreifen, jetzt den Parameter $top enthält. Aufgrund der URL-Kodierung erscheint $top als %24top, aber der OData-Dienst ist intelligent genug, um es automatisch umzuwandeln.
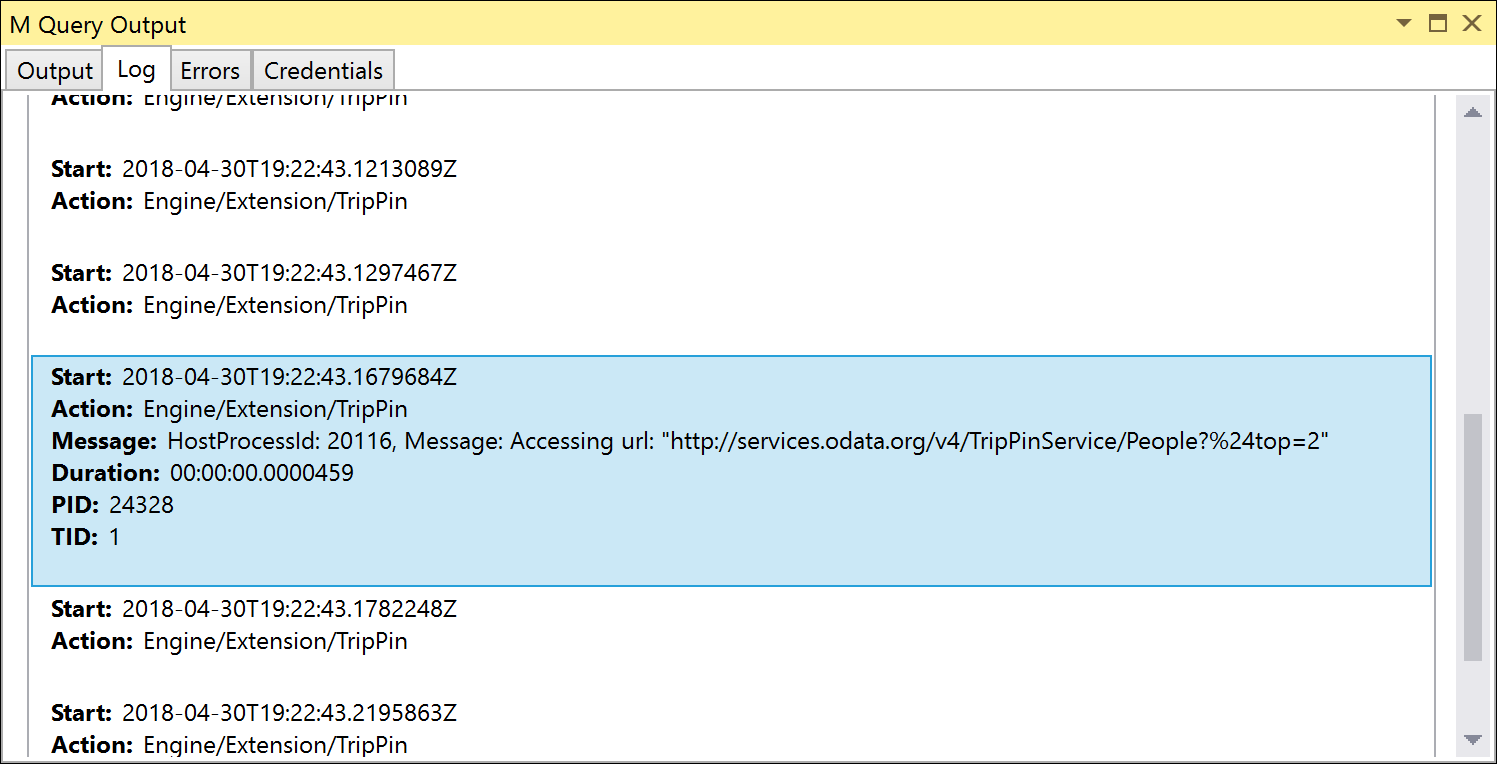
Behandlung von Table.Skip mit OnSkip
Der OnSkip Handler ist dem OnTakesehr ähnlich. Er erhält einen count-Parameter, der die Anzahl der Zeilen angibt, die aus der Ergebnismenge übersprungen werden sollen. Dieser Handler lässt sich gut mit dem Abfrageparameter OData $skip übersetzen.
Einheitstests:
// OnSkip
Fact("Fold $skip 14 on Airlines",
#table( type table [AirlineCode = text, Name = text] , {{"EK", "Emirates"}} ),
Table.Skip(Airlines, 14)
),
Fact("Fold $skip 0 and $top 1",
#table( type table [AirlineCode = text, Name = text] , {{"AA", "American Airlines"}} ),
Table.FirstN(Table.Skip(Airlines, 0), 1)
),
Implementierung:
// OnSkip - handles the Table.Skip transform.
// The count value should be >= 0.
OnSkip = (count as number) =>
let
newState = state & [ Skip = count ]
in
@View(newState),
Entsprechende Aktualisierungen auf CalculateUrl:
qsWithSkip =
if (state[Skip]? <> null) then
qsWithTop & [ #"$skip" = Number.ToText(state[Skip]) ]
else
qsWithTop,
Weitere Informationen: Tabelle.überspringen
Behandlung von Table.SelectColumns mit OnSelectColumns
Der OnSelectColumns Handler wird aufgerufen, wenn der Benutzer Spalten aus der Ergebnismenge auswählt oder entfernt. Der Handler erhält eine list von text Werten, die die auszuwählende(n) Spalte(n) darstellen, die ausgewählt werden solle(n).
In OData-Begriffen entspricht dieser Vorgang der Abfrageoption $select.
Der Vorteil der gefalteten Spaltenauswahl wird deutlich, wenn Sie mit Tabellen mit vielen Spalten zu tun haben. Der $select-Operator entfernt unselektierte Spalten aus der Ergebnismenge, was zu effizienteren Abfragen führt.
Einheitstests:
// OnSelectColumns
Fact("Fold $select single column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode"}), 1)
),
Fact("Fold $select multiple column",
#table( type table [UserName = text, FirstName = text, LastName = text],{{"russellwhyte", "Russell", "Whyte"}}),
Table.FirstN(Table.SelectColumns(People, {"UserName", "FirstName", "LastName"}), 1)
),
Fact("Fold $select with ignore column",
#table( type table [AirlineCode = text] , {{"AA"}} ),
Table.FirstN(Table.SelectColumns(Airlines, {"AirlineCode", "DoesNotExist"}, MissingField.Ignore), 1)
),
Die ersten beiden Tests wählen mit Table.SelectColumnseine unterschiedliche Anzahl von Spalten aus und enthalten zur Vereinfachung des Testfalls einen Aufruf Table.FirstN.
Hinweis
Wenn der Test lediglich die Spaltennamen (unter Verwendung von Table.ColumnNames ) und keine Daten zurückgibt, wird die Anfrage an den OData-Dienst nie gesendet. Der Grund dafür ist, dass der Aufruf von GetType das Schema zurückgibt, das alle Informationen enthält, die die M-Engine zur Berechnung des Ergebnisses benötigt.
Der dritte Test verwendet die Option MissingField.Ignore, mit der die M-Engine angewiesen wird, alle ausgewählten Spalten zu ignorieren, die in der Ergebnismenge nicht vorhanden sind. Der OnSelectColumns-Handler braucht sich um diese Option nicht zu kümmern – die M-Engine erledigt das automatisch (d. h. fehlende Spalten werden nicht in die columns-Liste aufgenommen).
Hinweis
Die andere Option für Table.SelectColumns, MissingField.UseNull, erfordert einen Connector, der den OnAddColumn Handler implementiert. Dies wird in einer der nächsten Lektionen geschehen.
Die Implementierung für OnSelectColumns erfüllt zwei Aufgaben:
- Fügt die Liste der ausgewählten Spalten zu
statehinzu. - Berechnet den
Schema-Wert neu, damit Sie den richtigen Tabellentyp einstellen können.
OnSelectColumns = (columns as list) =>
let
// get the current schema
currentSchema = CalculateSchema(state),
// get the columns from the current schema (which is an M Type value)
rowRecordType = Type.RecordFields(Type.TableRow(currentSchema)),
existingColumns = Record.FieldNames(rowRecordType),
// calculate the new schema
columnsToRemove = List.Difference(existingColumns, columns),
updatedColumns = Record.RemoveFields(rowRecordType, columnsToRemove),
newSchema = type table (Type.ForRecord(updatedColumns, false))
in
@View(state &
[
SelectColumns = columns,
Schema = newSchema
]
),
CalculateUrl wird aktualisiert, um die Liste der Spalten aus dem Status abzurufen und sie (mit einem Trennzeichen) für den Parameter $select zu kombinieren.
// Check for explicitly selected columns
qsWithSelect =
if (state[SelectColumns]? <> null) then
qsWithSkip & [ #"$select" = Text.Combine(state[SelectColumns], ",") ]
else
qsWithSkip,
Behandlung von Table.Sort mit OnSort
Der OnSort Handler erhält eine Liste von Datensätzen des Typs:
type [ Name = text, Order = Int16.Type ]
Jeder Datensatz enthält ein Name-Feld, das den Namen der Spalte angibt, und ein Order-Feld, das gleich Order.Ascending oder Order.Descending ist.
In OData-Begriffen entspricht dieser Vorgang der Abfrageoption $orderby.
Die Syntax $orderby besteht aus dem Spaltennamen, gefolgt von asc oder desc, um auf- oder absteigende Reihenfolge anzugeben. Beim Sortieren nach mehreren Spalten werden die Werte durch ein Komma getrennt. Wenn der Parameter columns mehr als ein Element enthält, ist es wichtig, die Reihenfolge beizubehalten, in der sie erscheinen.
Einheitstests:
// OnSort
Fact("Fold $orderby single column",
#table( type table [AirlineCode = text, Name = text], {{"TK", "Turkish Airlines"}}),
Table.FirstN(Table.Sort(Airlines, {{"AirlineCode", Order.Descending}}), 1)
),
Fact("Fold $orderby multiple column",
#table( type table [UserName = text], {{"javieralfred"}}),
Table.SelectColumns(Table.FirstN(Table.Sort(People, {{"LastName", Order.Ascending}, {"UserName", Order.Descending}}), 1), {"UserName"})
)
Implementierung:
// OnSort - receives a list of records containing two fields:
// [Name] - the name of the column to sort on
// [Order] - equal to Order.Ascending or Order.Descending
// If there are multiple records, the sort order must be maintained.
//
// OData allows you to sort on columns that do not appear in the result
// set, so we do not have to validate that the sorted columns are in our
// existing schema.
OnSort = (order as list) =>
let
// This will convert the list of records to a list of text,
// where each entry is "<columnName> <asc|desc>"
sorting = List.Transform(order, (o) =>
let
column = o[Name],
order = o[Order],
orderText = if (order = Order.Ascending) then "asc" else "desc"
in
column & " " & orderText
),
orderBy = Text.Combine(sorting, ", ")
in
@View(state & [ OrderBy = orderBy ]),
Aktualisierungen auf CalculateUrl:
qsWithOrderBy =
if (state[OrderBy]? <> null) then
qsWithSelect & [ #"$orderby" = state[OrderBy] ]
else
qsWithSelect,
Behandlung von Table.RowCount mit GetRowCount
Im Gegensatz zu den anderen Abfrage-Handlern, die Sie implementieren, gibt der GetRowCount-Handler einen einzigen Wert zurück – die Anzahl der erwarteten Zeilen in der Ergebnismenge. In einer M-Abfrage wäre dieser Wert normalerweise das Ergebnis der Transformation Table.RowCount.
Sie haben verschiedene Möglichkeiten, wie Sie diesen Wert als Teil einer OData-Abfrage handhaben können:
- Der Abfrageparameter $count, der die Anzahl als separates Feld in der Ergebnismenge zurückgibt.
- Das Pfadsegment /$count, das nur die Gesamtzahl als Einzelwert zurückgibt.
Der Nachteil des Abfrageparameter-Ansatzes ist, dass Sie immer noch die gesamte Abfrage an den OData-Dienst senden müssen. Da die Zählung inline als Teil der Ergebnismenge zurückkommt, müssen Sie die erste Seite der Daten aus der Ergebnismenge verarbeiten. Dieser Prozess ist zwar immer noch effizienter als das Lesen der gesamten Ergebnismenge und das Zählen der Zeilen, aber es ist wahrscheinlich immer noch mehr Arbeit, als Sie tun möchten.
Der Vorteil des Pfadsegmentansatzes ist, dass Sie im Ergebnis nur einen einzigen Einzelwert erhalten. Dieser Ansatz macht den gesamten Vorgang sehr viel effizienter. Wie in der OData-Spezifikation beschrieben, gibt das Pfadsegment /$count jedoch einen Fehler zurück, wenn Sie andere Abfrageparameter wie $top oder $skipeinschließen, was seine Nützlichkeit einschränkt.
In diesem Tutorial werden Sie den GetRowCount Handler mit Hilfe des Pfadsegmentansatzes implementieren. Um die Fehler zu vermeiden, die Sie erhalten würden, wenn andere Abfrageparameter enthalten sind, werden Sie nach anderen Statuswerten suchen und einen nicht implementierten Fehler (...) zurückgeben, wenn Sie einen finden. Die Rückgabe eines Fehlers von einem Table.View Handler teilt der M-Engine mit, dass die Operation nicht gefaltet werden kann und sie stattdessen auf den Standard-Handler zurückgreifen sollte (was in diesem Fall das Zählen der Gesamtzahl der Zeilen wäre).
Fügen Sie zunächst einen Unittest hinzu:
// GetRowCount
Fact("Fold $count", 15, Table.RowCount(Airlines)),
Da das Pfadsegment /$count einen einzelnen Wert (im Klartextformat) und keinen JSON-Ergebnissatz zurückgibt, müssen Sie auch eine neue interne Funktion (TripPin.Scalar) hinzufügen, um die Anfrage zu stellen und das Ergebnis zu verarbeiten.
// Similar to TripPin.Feed, but is expecting back a scalar value.
// This function returns the value from the service as plain text.
TripPin.Scalar = (url as text) as text =>
let
_url = Diagnostics.LogValue("TripPin.Scalar url", url),
headers = DefaultRequestHeaders & [
#"Accept" = "text/plain"
],
response = Web.Contents(_url, [ Headers = headers ]),
toText = Text.FromBinary(response)
in
toText;
Die Implementierung wird dann diese Funktion verwenden (wenn keine anderen Abfrageparameter in der state gefunden werden):
GetRowCount = () as number =>
if (Record.FieldCount(Record.RemoveFields(state, {"Url", "Entity", "Schema"}, MissingField.Ignore)) > 0) then
...
else
let
newState = state & [ RowCountOnly = true ],
finalUrl = CalculateUrl(newState),
value = TripPin.Scalar(finalUrl),
converted = Number.FromText(value)
in
converted,
Die Funktion CalculateUrl wird aktualisiert, um /$count an die URL anzuhängen, wenn das Feld RowCountOnly in stategesetzt ist.
// Check for $count. If all we want is a row count,
// then we add /$count to the path value (following the entity name).
urlWithRowCount =
if (state[RowCountOnly]? = true) then
urlWithEntity & "/$count"
else
urlWithEntity,
Der neue Table.RowCount Unit-Test sollte nun erfolgreich sein.
Um den Fallback-Fall zu testen, fügen Sie einen weiteren Test hinzu, der den Fehler erzwingt.
Fügen Sie zunächst eine Hilfsmethode hinzu, die das Ergebnis einer try Operation auf einen Faltungsfehler überprüft.
// Returns true if there is a folding error, or the original record (for logging purposes) if not.
Test.IsFoldingError = (tryResult as record) =>
if ( tryResult[HasError]? = true and tryResult[Error][Message] = "We couldn't fold the expression to the data source. Please try a simpler expression.") then
true
else
tryResult;
Fügen Sie dann einen Test hinzu, der sowohl Table.RowCount als auch Table.FirstN verwendet, um den Fehler zu erzwingen.
// test will fail if "Fail on Folding Error" is set to false
Fact("Fold $count + $top *error*", true, Test.IsFoldingError(try Table.RowCount(Table.FirstN(Airlines, 3)))),
Ein wichtiger Hinweis an dieser Stelle ist, dass dieser Test nun einen Fehler zurückgibt, wenn Error on Folding Error auf falsegesetzt ist, da die Operation Table.RowCount auf den lokalen (Standard-)Handler zurückgreift. Wenn Sie die Tests mit der Einstellung Error on Folding Error auf true durchführen, schlägt Table.RowCount fehl, und der Test ist erfolgreich.
Zusammenfassung
Die Implementierung von Table.View für Ihren Connector erhöht die Komplexität Ihres Codes erheblich. Da die M-Engine alle Transformationen lokal verarbeiten kann, ermöglicht das Hinzufügen von Table.View Handlern keine neuen Szenarien für Ihre Benutzer, führt aber zu einer effizienteren Verarbeitung (und potenziell zufriedeneren Benutzern). Einer der Hauptvorteile der optionalen Handler von Table.View besteht darin, dass Sie schrittweise neue Funktionen hinzufügen können, ohne die Rückwärtskompatibilität Ihres Connectors zu beeinträchtigen.
Für die meisten Connectors ist ein wichtiger (und grundlegender) Handler, der implementiert werden muss, OnTake (was in OData mit $top übersetzt wird), da er die Anzahl der zurückgegebenen Zeilen begrenzt. Power Query führt bei der Anzeige von Vorschauen im Navigator und im Abfrage-Editor immer eine OnTake von 1000 Zeilen aus, sodass Ihre Benutzer bei der Arbeit mit größeren Datensätzen erhebliche Leistungsverbesserungen feststellen können.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für