TripPin Teil 5 - Paging
Dieser mehrteilige Lehrgang behandelt die Erstellung einer neuen Datenquellenerweiterung für Power Query. Der Lehrgang sollte nacheinander durchgeführt werden - jede Lektion baut auf dem in den vorangegangenen Lektionen erstellten Connector auf und fügt dem Connector schrittweise neue Funktionen hinzu.
In dieser Lektion lernen Sie Folgendes:
- Hinzufügen von Paging-Unterstützung für den Connector
Viele Rest-APIs geben Daten in "Seiten" zurück, sodass die Kunden mehrere Anfragen stellen müssen, um die Ergebnisse zusammenzufügen. Obwohl es einige gemeinsame Konventionen für die Paginierung gibt (z. B. RFC 5988), variiert sie im Allgemeinen von API zu API. Glücklicherweise ist TripPin ein OData-Service, und der OData-Standard definiert eine Möglichkeit der Paginierung unter Verwendung von odata.nextLink Werten, die im Hauptteil der Antwort zurückgegeben werden.
Um frühere Iterationen des Connectors zu vereinfachen, war die Funktion TripPin.Feed nicht seitenorientiert. Es parst einfach das JSON, das von der Anfrage zurückgegeben wurde, und formatiert es als Tabelle. Diejenigen, die mit dem OData-Protokoll vertraut sind, haben vielleicht bemerkt, dass viele falsche Annahmen über das Format der Antwort gemacht wurden (z. B. die Annahme, dass es ein value Feld gibt, das ein Array von Datensätzen enthält).
In dieser Lektion werden Sie Ihre Logik für die Antwortverarbeitung verbessern, indem Sie sie seitenabhängig machen. Zukünftige Tutorials werden die Logik der Seitenbearbeitung robuster machen und mehrere Antwortformate (einschließlich Fehler vom Dienst) verarbeiten können.
Hinweis
Bei Connectors, die auf OData.Feedbasieren, brauchen Sie keine eigene Paging-Logik zu implementieren, da dies alles automatisch für Sie erledigt wird.
Checkliste für das Paging
Wenn Sie die Unterstützung von Paging implementieren, müssen Sie die folgenden Dinge über Ihre API wissen:
- Wie können Sie die nächste Seite mit Daten anfordern?
- Beinhaltet der Paging-Mechanismus die Berechnung von Werten, oder extrahieren Sie die URL für die nächste Seite aus der Antwort?
- Woher wissen Sie, wann Sie aufhören sollten, die Seiten aufzurufen?
- Gibt es Parameter im Zusammenhang mit dem Paging, die Sie kennen sollten? (wie z. B. "Seitengröße")
Die Antwort auf diese Fragen wird sich auf die Art und Weise auswirken, wie Sie Ihre Auslagerungslogik implementieren. Es gibt zwar eine gewisse Wiederverwendung von Code in verschiedenen Paging-Implementierungen (z. B. die Verwendung von Table.GenerateByPage), aber für die meisten Connectors ist letztendlich eine eigene Logik erforderlich.
Hinweis
Diese Lektion enthält eine Auslagerungslogik für einen OData-Dienst, die einem bestimmten Format folgt. Lesen Sie die Dokumentation Ihrer API, um festzustellen, welche Änderungen Sie in Ihrem Connector vornehmen müssen, um das Paging-Format zu unterstützen.
Überblick über OData Paging
Das OData-Paging wird durch nextLink-Annotationen gesteuert, die in der Nutzlast der Antwort enthalten sind. Der Wert nextLink enthält die URL zur nächsten Seite der Daten. Sie werden wissen, ob es eine weitere Seite mit Daten gibt, indem Sie nach einem odata.nextLink Feld im äußersten Objekt in der Antwort suchen. Wenn es kein odata.nextLink Feld gibt, haben Sie alle Ihre Daten gelesen.
{
"odata.context": "...",
"odata.count": 37,
"value": [
{ },
{ },
{ }
],
"odata.nextLink": "...?$skiptoken=342r89"
}
Einige OData-Dienste erlauben es den Kunden, eine maximale Seitengröße anzugeben, aber es liegt in der Hand des Dienstes, ob er dies beachtet oder nicht. Power Query sollte in der Lage sein, Antworten beliebiger Größe zu verarbeiten, sodass Sie sich nicht um die Angabe einer bevorzugten Seitengröße kümmern müssen - Sie können alles unterstützen, was der Dienst Ihnen vorgibt.
Weitere Informationen über Server-Driven Paging sind in der OData-Spezifikation zu finden.
Prüfung von TripPin
Bevor Sie Ihre Paging-Implementierung korrigieren, bestätigen Sie das aktuelle Verhalten der Erweiterung aus dem vorherigen Tutorial. Die folgende Testabfrage ruft die Tabelle Personen ab und fügt eine Indexspalte hinzu, um die aktuelle Zeilenzahl anzuzeigen.
let
source = TripPin.Contents(),
data = source{[Name="People"]}[Data],
withRowCount = Table.AddIndexColumn(data, "Index")
in
withRowCount
Aktivieren Sie Fiddler, und führen Sie die Abfrage im Power Query SDK aus. Sie werden feststellen, dass die Abfrage eine Tabelle mit 8 Zeilen zurückgibt (Index 0 bis 7).
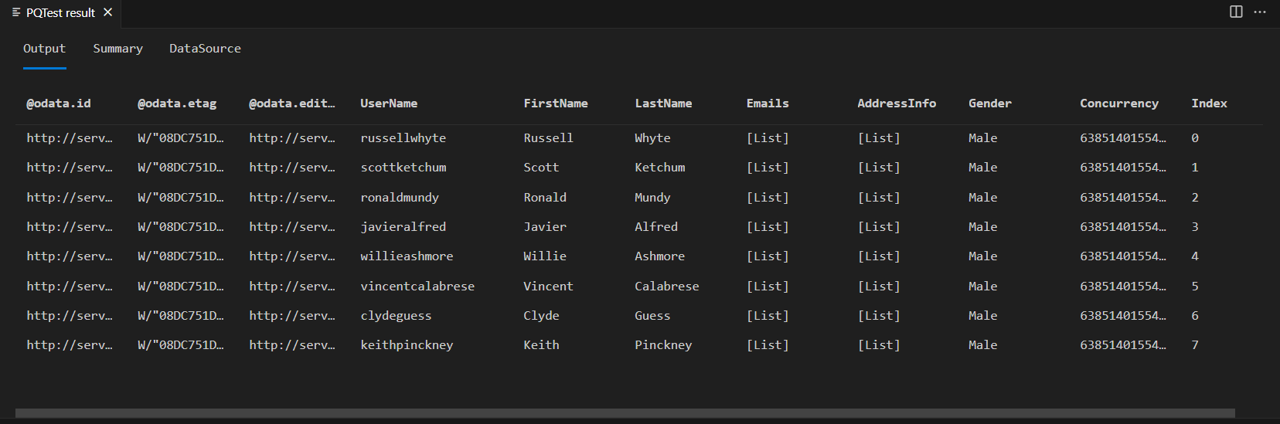
Wenn Sie sich den Textkörper der Antwort von fiddler ansehen, werden Sie feststellen, dass er tatsächlich ein Feld @odata.nextLink enthält, das anzeigt, dass weitere Seiten mit Daten verfügbar sind.
{
"@odata.context": "https://services.odata.org/V4/TripPinService/$metadata#People",
"@odata.nextLink": "https://services.odata.org/v4/TripPinService/People?%24skiptoken=8",
"value": [
{ },
{ },
{ }
]
}
Implementierung des Paging für TripPin
Sie werden nun die folgenden Änderungen an Ihrer Erweiterung vornehmen:
- Importieren Sie die gemeinsame Funktion
Table.GenerateByPage - Fügen Sie eine
GetAllPagesByNextLinkFunktion hinzu, dieTable.GenerateByPageverwendet, um alle Seiten zusammenzukleben - Hinzufügen einer
GetPageFunktion, die eine einzelne Seite von Daten lesen kann - Fügen Sie eine
GetNextLinkFunktion hinzu, um die nächste URL aus der Antwort zu extrahieren - Aktualisieren Sie
TripPin.Feed, um die neuen Page-Reader-Funktionen zu nutzen
Hinweis
Wie bereits erwähnt, variiert die Logik für das Paging je nach Datenquelle. Die Implementierung hier versucht, die Logik in Funktionen aufzubrechen, die für Quellen wiederverwendbar sein sollten, die next links in der Antwort zurückgeben.
Tabelle.GenerateByPage
Um die (potenziell) mehreren von der Quelle zurückgegebenen Seiten in einer einzigen Tabelle zusammenzufassen, verwenden wir Table.GenerateByPage. Diese Funktion nimmt als Argument eine getNextPage-Funktion, die genau das bewirken soll, was ihr Name vermuten lässt: die nächste Seite der Daten abrufen. Table.GenerateByPage ruft die Funktion getNextPage wiederholt auf und übergibt ihr jedes Mal die Ergebnisse des letzten Aufrufs, bis sie null zurückgibt, um zu signalisieren, dass keine weiteren Seiten verfügbar sind.
Da diese Funktion nicht Teil der Standardbibliothek von Power Query ist, müssen Sie ihren Quellcode in Ihre.pq-Datei kopieren.
Implementierung von GetAllPagesByNextLink
Der Körper Ihrer Funktion GetAllPagesByNextLink implementiert das getNextPage-Funktionsargument für Table.GenerateByPage. Sie ruft die Funktion GetPage auf und ruft die URL für die nächste Seite der Daten aus dem Feld NextLink des Datensatzes meta des vorherigen Aufrufs ab.
// Read all pages of data.
// After every page, we check the "NextLink" record on the metadata of the previous request.
// Table.GenerateByPage will keep asking for more pages until we return null.
GetAllPagesByNextLink = (url as text) as table =>
Table.GenerateByPage((previous) =>
let
// if previous is null, then this is our first page of data
nextLink = if (previous = null) then url else Value.Metadata(previous)[NextLink]?,
// if NextLink was set to null by the previous call, we know we have no more data
page = if (nextLink <> null) then GetPage(nextLink) else null
in
page
);
Implementierung von GetPage
Ihre Funktion GetPage wird Web.Contents verwenden, um eine einzelne Seite mit Daten vom TripPin-Dienst abzurufen und die Antwort in eine Tabelle zu konvertieren. Übergibt die Antwort von Web.Contents an die GetNextLink-Funktion, um die URL der nächsten Seite zu extrahieren, und setzt sie in den Datensatz meta der zurückgegebenen Tabelle (Datenseite).
Diese Implementierung ist eine leicht abgewandelte Version des Aufrufs TripPin.Feed aus den vorangegangenen Tutorials.
GetPage = (url as text) as table =>
let
response = Web.Contents(url, [ Headers = DefaultRequestHeaders ]),
body = Json.Document(response),
nextLink = GetNextLink(body),
data = Table.FromRecords(body[value])
in
data meta [NextLink = nextLink];
Implementierung von GetNextLink
Ihre Funktion GetNextLink prüft einfach den Textkörper der Antwort auf ein @odata.nextLink Feld und gibt dessen Wert zurück.
// In this implementation, 'response' will be the parsed body of the response after the call to Json.Document.
// Look for the '@odata.nextLink' field and simply return null if it doesn't exist.
GetNextLink = (response) as nullable text => Record.FieldOrDefault(response, "@odata.nextLink");
Zusammenfügen des Gesamtbilds
Der letzte Schritt bei der Implementierung Ihrer Auslagerungslogik besteht darin, TripPin.Feed zu aktualisieren, um die neuen Funktionen zu verwenden. Im Moment rufen Sie einfach GetAllPagesByNextLinkauf, aber in den folgenden Tutorials werden Sie neue Funktionen hinzufügen (z. B. die Erzwingung eines Schemas und die Abfrageparameterlogik).
TripPin.Feed = (url as text) as table => GetAllPagesByNextLink(url);
Wenn Sie dieselbe Testabfrage von vorhin erneut ausführen, sollten Sie jetzt den Seitenleser in Aktion sehen. Sie sollten auch sehen, dass Sie 24 Zeilen in der Antwort haben, anstatt 8.
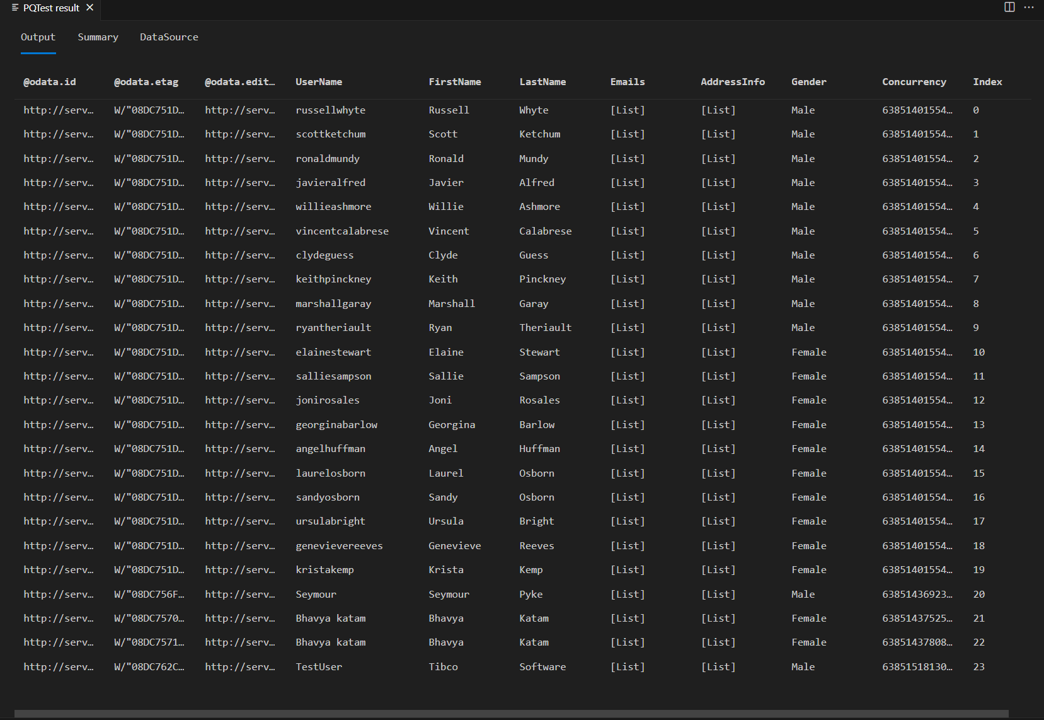
Wenn Sie sich die Anfragen in fiddler ansehen, sollten Sie nun für jede Seite der Daten separate Anfragen sehen.
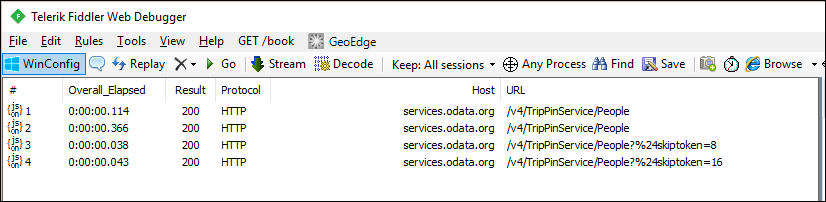
Hinweis
Sie werden feststellen, dass die erste Seite der Daten vom Dienst doppelt angefordert wird, was nicht ideal ist. Die zusätzliche Anforderung ergibt sich aus dem Schemaprüfverhalten der M-Engine. Ignorieren Sie dieses Problem vorerst und lösen Sie es im nächsten Tutorial, wo Sie ein explizites Schema anwenden werden.
Zusammenfassung
In dieser Lektion haben Sie gelernt, wie man die Unterstützung für Paginierung für eine Rest-API implementiert. Während die Logik zwischen den APIs wahrscheinlich variieren wird, sollte das hier festgelegte Muster mit geringfügigen Änderungen wiederverwendbar sein.
In der nächsten Lektion werden Sie sich ansehen, wie Sie ein explizites Schema auf Ihre Daten anwenden können, das über die einfachen text und number Datentypen hinausgeht, die Sie von Json.Documenterhalten.