Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum zu Azure Machine Learning zu wechseln.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Informationen zum Verschieben von Machine Learning-Projekten von ML Studio (klassisch) zu Azure Machine Learning.
- Weitere Informationen zu Azure Machine Learning
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
In diesem Thema wird das Auswählen der richtigen Hyperparameter für einen Algorithmus im Azure Machine Learning Studio (Classic) beschrieben. Für die meisten Machine Learning-Algorithmen müssen Parameter festgelegt werden. Wenn Sie ein Modell trainieren, müssen Sie Werte für diese Parameter bereitstellen. Die Wirksamkeit des trainierten Modells ist abhängig von den gewählten Parametern. Der Prozess der Suche nach den optimalen Parametern wird als Modellauswahl bezeichnet.
Es gibt verschiedene Möglichkeiten zur Modellauswahl. Beim maschinellen Lernen ist die Kreuzvalidierung eine der am häufigsten verwendeten Methoden für die Modellauswahl und der Standardmechanismus für die Modellauswahl im Azure Machine Learning Studio (Classic). Da das Azure Machine Learning Studio (Classic) sowohl R als auch Python unterstützt, können Sie mithilfe von R oder Python Ihren eigenen Modellauswahlmechanismus implementieren.
Das Ermitteln des besten Parametersatzes umfasst vier Schritte:
- Definieren Sie den Parameterbereich: Entscheiden Sie zunächst für den Algorithmus die genauen Parameterwerte, die Sie berücksichtigen möchten.
- Definieren Sie die Einstellungen für die Cross-Validation: Entscheiden Sie, wie Faltungen für die Kreuzvalidierung für den Datensatz ausgewählt werden sollen.
- Definieren Sie die Metrik: Entscheiden Sie, welche Metrik verwendet werden soll, um den besten Satz von Parametern zu bestimmen, z. B. Genauigkeit, Stammwert quadratischer Fehler, Genauigkeit, Rückruf oder F-Score.
- Trainieren, auswerten und vergleichen: Bei jeder eindeutigen Kombination der Parameterwerte wird die Kreuzüberprüfung von und basierend auf der von Ihnen definierten Fehlermetrik durchgeführt. Nach Auswertung und Vergleich können Sie das leistungsfähigste Modell auswählen.
Die folgende Abbildung veranschaulicht, wie dies im Azure Machine Learning Studio (Classic) erreicht werden kann.
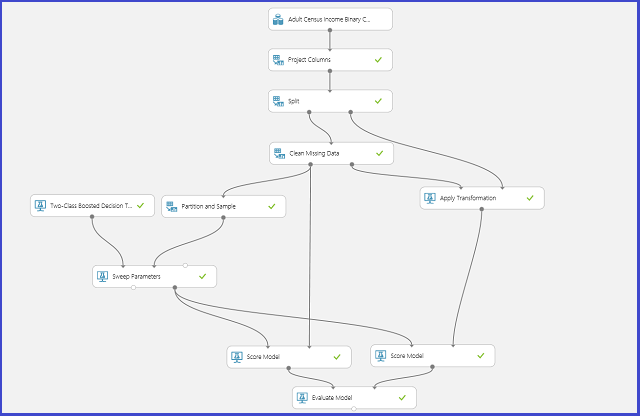
Definieren des Parameterraums
Der Parametersatz kann bei der Initialisierung des Modells definiert werden. Der Parameterbereich aller Machine Learning-Algorithmen verfügt über zwei Trainermodi: Einzelparameter und Parameterbereich. Wählen Sie den Modus "Parameterbereich" aus. Im Modus „Parameter Range“ können Sie für jeden Parameter mehrere Werte eingeben. Sie können in das Textfeld durch Trennzeichen getrennte Werte eingeben.
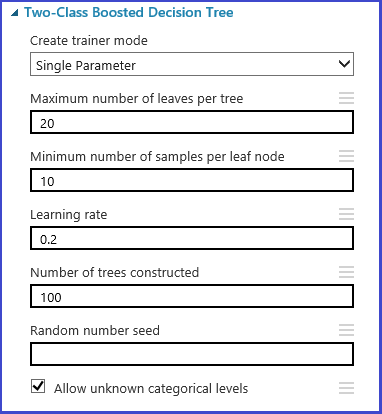
Alternativ können Sie die maximalen und minimalen Punkte des Rasters und die Gesamtanzahl der punkte definieren, die mit dem Bereichs-Generator generiert werden sollen. Standardmäßig werden die Parameterwerte auf einer linearen Skala generiert. Wenn die Protokollskala jedoch überprüft wird, werden die Werte in der Protokollskala generiert (d. a. das Verhältnis der angrenzenden Punkte ist konstant statt deren Differenz). Für als ganze Zahl angegebene Parameter können Sie einen Bereich mithilfe eines Bindestrichs definieren. „1-10“ bedeutet beispielsweise, dass alle ganzen Zahlen von 1 bis 10 den Parametersatz bilden. Ein gemischter Modus wird ebenfalls unterstützt. Der Parametersatz „1-10, 20, 50“ enthält z. B. die ganzen Zahlen 1 bis 10, 20 und 50.
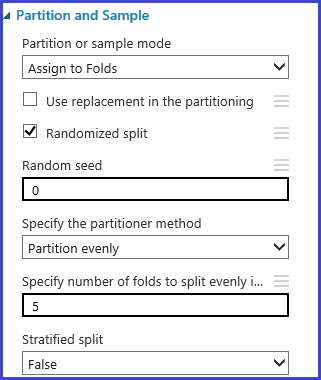
Kreuvalidierungsfalten definieren
Das Partitions- und Beispielmodul kann zum zufälligen Zuweisen von Faltungen zu den Daten verwendet werden. In der folgenden Beispielkonfiguration für das Modul definieren wir fünf Teilmengen und weisen den Beispielinstanzen die Teilmengennummern nach dem Zufallsprinzip zu.
Definieren der Metrik
Das Tune Model Hyperparameters-Modul bietet Unterstützung für die empirische Auswahl der besten Parameter für einen bestimmten Algorithmus und Dataset. Zusätzlich zu anderen Informationen zur Schulung des Modells enthält der Eigenschaftenbereich dieses Moduls die Metrik zum Bestimmen des besten Parametersatzes. Er verfügt über zwei verschiedene Dropdownlistenfelder für Klassifizierungs- und Regressionsalgorithmen. Wenn der untersuchte Algorithmus ein Klassifizierungsalgorithmus ist, wird die Regressionskennzahl ignoriert und umgekehrt. In diesem spezifischen Beispiel ist die Metrik "Genauigkeit".
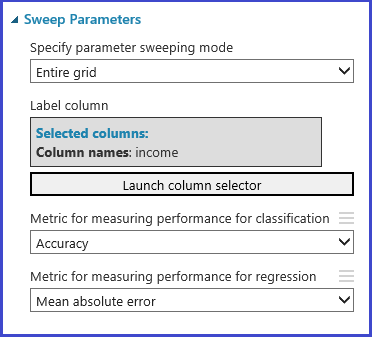
Trainieren, Evaluieren und Vergleichen
Dasselbe Tune Model Hyperparameters-Modul trainiert alle Modelle, die dem Parametersatz entsprechen, wertet verschiedene Metriken aus und erstellt dann das am besten trainierte Modell basierend auf der von Ihnen ausgewählten Metrik. Dieses Modul hat zwei obligatorische Eingaben:
- Den untrainierten Lernenden
- Das Dataset
Das Modul hat auch eine optionale Dataseteingabe. Verbinden Sie den Datensatz mit Faltinformationen mit der obligatorischen Datensatz-Eingabe. Wenn dem Datensatz keine Faltinformationen zugewiesen sind, erfolgt automatisch eine 10-fache Kreuzvalidierung. Wenn die Faltzuweisung nicht erfolgt und ein Dataset zur Validierung bei dem optionalen Datensatzport bereitgestellt wird, wird ein Trainings-Test-Modus ausgewählt, und das erste Dataset wird verwendet, um das Modell für jede Parameterkombination zu trainieren.
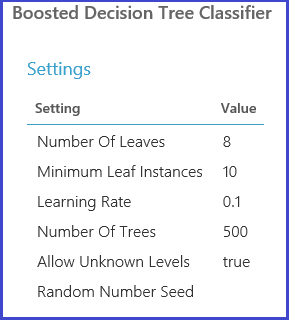
Anschließend wird das Modell für das Validierungsdataset ausgewertet. Der linke Ausgabeport des Moduls weist verschiedene Metriken als Funktionen von Parameterwerten auf. Der richtige Ausgabeport gibt das trainierte Modell an, das dem leistungsstärksten Modell entsprechend der gewählten Metrik entspricht (Genauigkeit in diesem Fall).
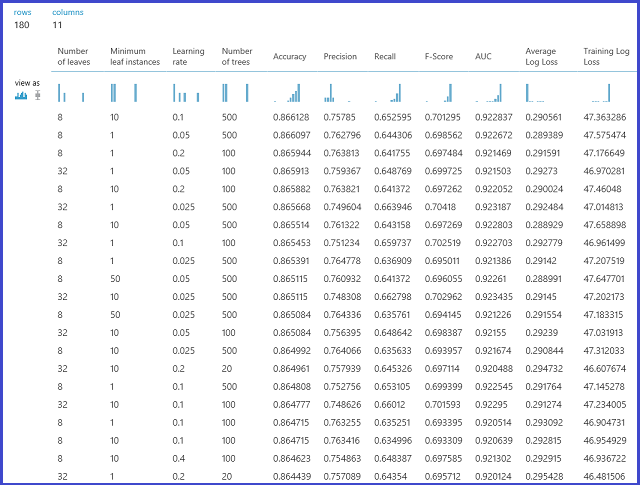
Sie können die gewählten Parameter mithilfe einer Visualisierung des rechten Ausgabeports anzeigen. Dieses Modell kann nach dem Speichern als trainiertes Modell für die Bewertung von Testsätzen oder in einem operationalisierten Webdienst verwendet werden.