Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Machine Learning Studio (klassisch)
Machine Learning Studio (klassisch)  Azure Machine Learning
Azure Machine Learning
Wichtig
Der Support für Machine Learning Studio (klassisch) endet am 31. August 2024. Es wird empfohlen, bis zu diesem Datum auf Azure Machine Learning umzustellen.
Ab dem 1. Dezember 2021 können Sie keine neuen Ressourcen in Machine Learning Studio (klassisch) mehr erstellen. Bis zum 31. August 2024 können Sie die vorhandenen Ressourcen in Machine Learning Studio (klassisch) weiterhin verwenden.
- Weitere Informationen zum Verschieben von Machine-Learning-Projekten von ML Studio (klassisch) zu Azure Machine Learning finden Sie unter Azure Machine Learning.
- Weitere Informationen zu Azure Machine Learning
Die Dokumentation zu ML Studio (klassisch) wird nicht mehr fortgeführt und kann künftig nicht mehr aktualisiert werden.
In diesem Artikel erstellen Sie ein Machine-Learning-Experiment in Machine Learning Studio (Classic), mit dem der Preis eines Automobils basierend auf verschiedenen Variablen vorhergesagt wird, z. B. Marke und technische Daten.
Falls maschinelles Lernen neu für Sie ist, hilft Ihnen die Videoreihe Data Science für Anfänger weiter. Hierbei handelt es sich um eine gute Einführung in maschinelles Lernen in alltäglicher Sprache und mit entsprechenden Konzepten.
In dieser Schnellstartanleitung wird der Standardworkflow für ein Experiment verfolgt:
- Erstellen des Modells
- Trainieren Sie das Modell
- Bewerten und Testen des Modells
Abrufen von Daten
Grundvoraussetzung für maschinelles Lernen sind Daten. Studio (klassisch) enthält bereits einige Beispieldatasets, die Sie verwenden können. Alternativ hierzu können Sie auch Daten aus vielen anderen Quellen importieren. Für dieses Beispiel verwenden wir das Beispieldataset Automobile price data (Raw), das in Ihrem Arbeitsbereich zu finden ist. Dieses Dataset enthält Einträge für eine Reihe verschiedener Automobile, einschließlich Informationen wie Marke, Modell, technische Angaben und Preis.
Tipp
Eine Arbeitskopie des folgenden Experiments finden Sie im Azure KI-Katalog. Wechseln Sie zu Ihr erstes Data Science-Experiment – Vorhersage von Automobilpreisen, und klicken Sie auf In Studio öffnen, um eine Kopie des Experiments in Ihren Machine Learning Studio-Arbeitsbereich (klassisch) herunterzuladen.
Hier wird erklärt, wie Sie das Dataset in Ihr Experiment importieren.
Erstellen Sie ein neues Experiment, indem Sie unten im Machine Learning Studio-Fenster (klassisch) auf + NEU klicken. Wählen Sie EXPERIMENT>Blank Experiment (Leeres Experiment).
Dem Experiment wird ein Standardname zugewiesen, den Sie oben auf der Leinwand sehen können. Wählen Sie diesen Text aus und benennen Sie ihn in etwas Aussagekräftiges um, z.B. Automobile price prediction. Der Name muss nicht eindeutig sein.
Links vom Experimentbereich finden Sie eine Palette mit Datensätzen und Modulen. Geben Sie im oberen Bereich dieser Palette automobile in das Suchfeld ein, um das Dataset mit dem Namen Automobile price data (Raw) zu finden. Ziehen Sie den Datensatz auf die Experimentleinwand.
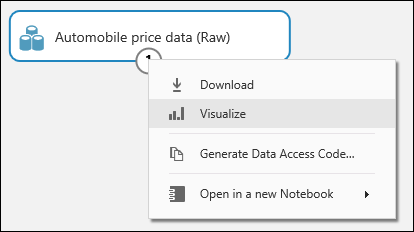
Sie können auf den Ausgabeport im unteren Bereich des Automobil-Datasets klicken und dann Visualisieren wählen, um die enthaltenen Daten anzuzeigen.
Tipp
Datasets und Module verfügen über Ein- und Ausgabe-Anschlüsse, die in Form kleiner Kreise dargestellt werden: Eingabe-Anschlüsse oben und Ausgabe-Anschlüsse unten. Zum Erstellen eines Datenflusses über Ihr Experiment verbinden Sie einen Ausgabeport eines Moduls mit dem Eingabeport eines anderen Moduls. Sie können zu einem beliebigen Zeitpunkt auf den Ausgabe-Anschluss eines Datasets oder eines Moduls klicken, um die Daten an diesem Punkt im Datenfluss anzuzeigen.
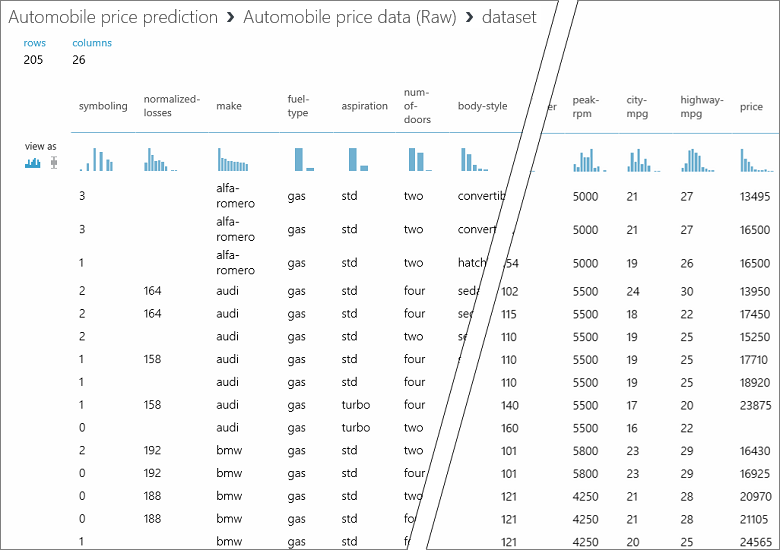
In diesem Dataset steht jede Zeile für ein Fahrzeug, und die Variablen, die den einzelnen Fahrzeugen zugeordnet sind, werden als Spalten angezeigt. Wir werden den Preis in der äußersten rechten Spalte (Spalte 26 mit dem Titel „Price“) vorhersagen, indem wir die Variablen für ein bestimmtes Fahrzeug verwenden.
Schließen Sie das Visualisierungsfenster, indem Sie auf das "X" in der oberen rechten Ecke klicken.
Vorbereiten der Daten
DataSets müssen vor der Analyse normalerweise vorverarbeitet werden. Möglicherweise sind Ihnen bereits die fehlenden Werte in den Spalten verschiedener Zeilen aufgefallen. Damit das Modell die Daten richtig analysieren kann, müssen diese fehlenden Werte bereinigt werden. Wir entfernen alle Zeilen, in denen Werte fehlen. Außerdem enthält die Spalte normalisierte Verluste viele fehlende Werte, daher schließen wir diese Spalte komplett aus dem Modell aus.
Tipp
Die Bereinigung fehlender Werte aus den Eingabedaten ist eine Voraussetzung für die Verwendung der meisten Module.
Zuerst fügen wir ein Modul hinzu, mit dem die Spalte normalized-losses vollständig entfernt wird. Anschließend fügen wir ein weiteres Modul hinzu, mit dem alle Zeilen entfernt werden, in denen Daten fehlen.
Geben Sie im oberen Bereich der Modulpalette select columns (Spalten auswählen) in das Suchfeld ein, um nach dem Modul Select Columns in Dataset (Spalten im Dataset auswählen) zu suchen. Ziehen Sie es dann in den Experimentierbereich. Mit diesem Modul können wir auswählen, welche Daten wir in unserem Modell ein- bzw. ausschließen möchten.
Verbinden Sie den Ausgabeport des Datasets Automobile price data (Raw) (Automobilpreisdaten (roh)) mit dem Eingabeport von „Spalten im Dataset auswählen“.
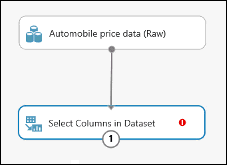
Klicken Sie auf das Modul Select Columns in Dataset (Spalten im Dataset auswählen) und auf Spaltenauswahl starten im Bereich Eigenschaften.
Klicken Sie auf der linken Seite auf With rules
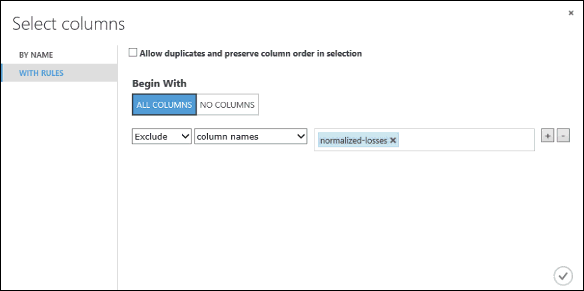
Klicken Sie unter Begin With (Beginnen mit) auf All columns (Alle Spalten). Mit diesen Regeln wird Select Columns in Dataset angewiesen, alle Spalten zu durchlaufen (mit Ausnahme derer, die wir jetzt ausschließen werden).
Wählen Sie in den Dropdownlisten die Optionen Ausschließen und Spaltennamen aus, und klicken Sie auf das Textfeld. Eine Liste von Spalten wird angezeigt. Wählen Sie normalized-losses aus, und es wird dem Textfeld hinzugefügt.
Klicken Sie auf die Schaltfläche mit dem Häkchen („OK“), um die Spaltenauswahl zu schließen (unten rechts).
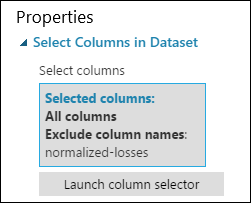
Der Eigenschaftenbereich für Select Columns in Dataset zeigt nun an, dass mit Ausnahme von normalized-losses alle Spalten des Datasets übergeben werden.
Tipp
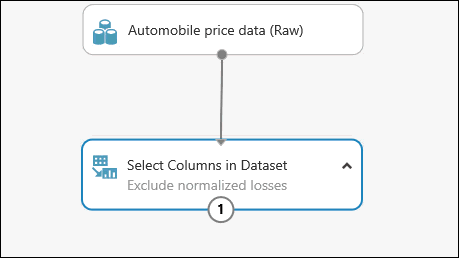
Sie können einen Kommentar zu einem Modul eingeben, indem Sie auf das Modul doppelklicken und Text eingeben. Auf diese Weise können Sie mit einem Blick sehen, welche Funktion das Modul in Ihrem Experiment erfüllt. Doppelklicken Sie in diesem Fall auf das Modul Select Columns in Dataset (Spalten im Dataset auswählen), und geben Sie den Kommentar „Exclude normalized losses“ (Normalisierte Verluste ausschließen) ein.
Ziehen Sie das Modul Clean Missing Data in den Experimentbereich, und verbinden Sie es mit dem Modul Select Columns in Dataset. Klicken Sie im Eigenschaftenbereich unter Cleaning mode (Reinigungsmodus) auf die Option Remove entire row (Gesamte Zeile entfernen). Mit diesen Optionen wird Clean Missing Data (Fehlende Daten bereinigen) angewiesen, Daten durch das Entfernen von Zeilen mit fehlenden Werten zu bereinigen. Doppelklicken Sie auf das Modul, und geben Sie den Kommentar "Fehlwerte entfernen" ein.
Stellen Sie den Reinigungsmodus für das Modul „Clean Missing Data“ auf „ganze Zeile entfernen“ ein.
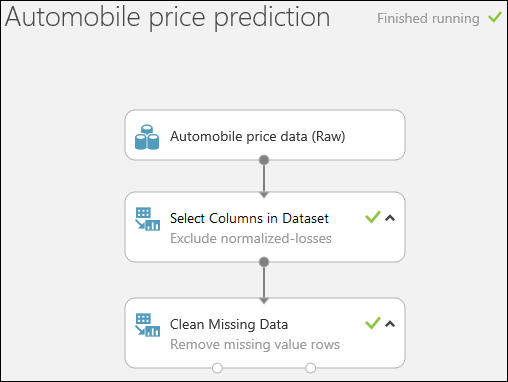
Führen Sie das Experiment, indem Sie am unteren Rand der Seite auf AUSFÜHREN klicken.
Nach Abschluss des Experiments sind alle Module mit einem grünen Häkchen markiert, um anzuzeigen, dass diese erfolgreich abgeschlossen wurden. Beachten Sie auch den Status Finished running in der oberen rechten Ecke.
Tipp
Warum haben wir das Experiment nun ausgeführt? Durch das Durchführen des Experiments durchlaufen die Spaltendefinitionen für unsere Daten das Dataset, das Select Columns in Dataset Modul (Spalten im Dataset auswählen) und das Clean Missing Data Modul (Fehlende Daten bereinigen). Dies bedeutet, dass alle Module, die wir mit Clean Missing Data (Fehlende Daten bereinigen) verbinden, über dieselben Informationen verfügen.
Wir verfügen jetzt über bereinigte Daten. Wenn Sie das bereinigte Dataset anzeigen möchten, klicken Sie auf den linken Ausgabeport des Moduls Clean Missing Data (Fehlende Daten bereinigen), und wählen Sie Visualize (Visualisieren) aus. Beachten Sie, dass die Spalte normalized-losses nicht mehr aufgeführt wird und keine fehlenden Werte auftreten.
Nach der Bereinigung der Daten können wir nun angeben, welche Funktionen wir im Vorhersagemodell verwenden möchten.
Definieren der Funktionen
Bei Machine Learning sind Funktionen einzeln messbare Eigenschaften des untersuchten Gesamtobjekts. In unserem DataSet stellt jede Zeile ein Automobil dar, und jede Spalte ist eine Funktion dieses Automobils.
Einen guten Satz von Funktionen für die Erstellung eines Vorhersagemodells finden Sie durch Ausprobieren und Kenntnisse des zu lösenden Problems. Manche Funktionen eignen sich besser für die Vorhersage des Ziels als andere. Einige Funktionen weisen eine starke Korrelation mit anderen Funktionen auf und können entfernt werden. So stehen „city-mpg“ und „highway-mpg“ z.B. in enger Beziehung. Wir können also eines behalten und das andere ohne bedeutende Auswirkungen auf die Vorhersage entfernen.
Wir werden ein Modell erstellen, das eine Teilmenge der Funktionen in unserem Datensatz verwendet. Sie können später jederzeit andere Funktionen auswählen, das Experiment erneut ausführen und versuchen, bessere Ergebnisse zu erhalten. Hier probieren wir vorerst die folgenden Funktionen aus:
Marke, Karosseriestil, Radstand, Motorgröße, PS, Drehzahl bei maximaler Leistung, Autobahnverbrauch, Preis
Ziehen Sie ein weiteres Modul vom Typ Select Columns in Dataset (Spalten im Dataset auswählen) in den Experimentbereich. Verbinden Sie den linken Ausgabeport des Moduls Clean Missing Data (Fehlende Daten bereinigen) mit dem Eingabeport des Moduls Select Columns in Dataset (Spalten im Dataset auswählen).
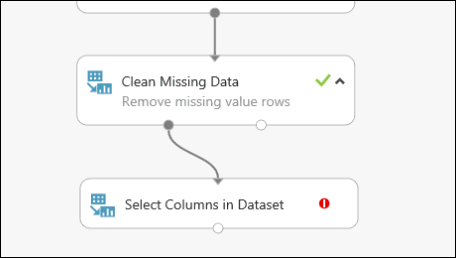
Doppelklicken Sie auf das Modul, und geben Sie "Merkmale zur Vorhersage wählen" ein.
Klicken Sie im Bereich Eigenschaften auf Spaltenauswahl starten.
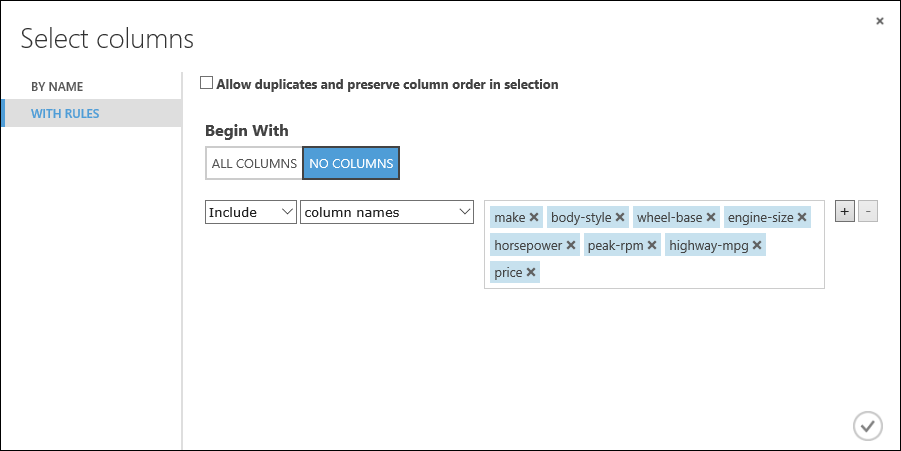
Klicken Sie auf With rules(Mit Regeln).
Klicken Sie unter Begin With auf No columns. Wählen Sie in der Filterzeile Include (Einbeziehen) und column names (Spaltennamen) aus, und wählen Sie im Textfeld unsere Liste mit Spaltennamen aus. Mit diesem Filter wird das Modul angewiesen, keine Spalten (Merkmale) außer den von uns angegebenen durchzulassen.
Klicken Sie auf das Häkchen ("OK").
Mit diesem Modul wird ein gefiltertes Dataset erstellt, das nur diejenigen Funktionen enthält, die wir an den im nächsten Schritt verwendeten Lernalgorithmus übergeben möchten. Sie können den Vorgang später jederzeit mit einer anderen Auswahl an Funktionen wiederholen.
Auswählen und Anwenden eines Algorithmus
Nachdem die Daten vorbereitet sind, können Sie das Vorhersagemodell anhand von Training und Tests erarbeiten. Wir werden das Modell zunächst mit unseren Daten trainieren und dann testen, wie genau seine Preisvorhersagen zutreffen.
Klassifizierung und Regression sind zwei Algorithmen für beaufsichtigtes maschinelles Lernen. Mit der Klassifizierung wird eine Antwort aus einem definierten Satz von Kategorien vorhergesagt, z. B. eine Farbe (Rot, Blau oder Grün). Die Regression wird verwendet, um eine Zahl vorherzusagen.
Da wir einen Preis vorhersagen möchten (also eine Zahl), verwenden wir einen Regressionsalgorithmus. In diesem Beispiel verwenden wir ein lineares Regressionsmodell.
Wir trainieren das Modell, indem wir einen Datensatz mit dem Preis einspeisen. Das Modell überprüft die Daten und sucht nach Korrelationen zwischen den Funktionen eines Automobils und seinem Preis. Anschließend testen wir das Modell: Wir geben einen Satz von Funktionen für bekannte Automobile ein und testen, wie exakt das Modell den bekannten Preis vorhersagt.
Wir verwenden unsere Daten sowohl für das Trainieren als auch das Testen des Modells, indem die Daten in separate Trainings- und Testdatasets aufgeteilt werden.
Ziehen Sie das Modul Split Data (Daten aufteilen) in den Experimentbereich, und verbinden Sie es mit dem letzten Modul vom Typ Select Columns in Dataset (Spalten im Dataset auswählen).
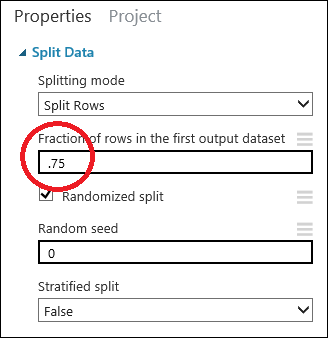
Klicken Sie auf das Modul Split Data (Daten aufteilen), um es auszuwählen. Suchen Sie den Bruchteil der Zeilen im ersten Ausgabedataset (Fraction of rows in the first output dataset) im Eigenschaftenbereich rechts neben der Arbeitsfläche und legen Sie die Einstellung auf 0,75 fest. Mit dieser Einstellung verwenden wir 75 Prozent der Daten zum Trainieren des Modells und halten 25 Prozent für Tests zurück.
Tipp
Sie können den Parameter Zufälliger Ausgangswert ändern, um unterschiedliche zufällige Proben für Training und Tests zu erstellen. Dieser Parameter steuert die Initialisierung des Pseudo-Zufallszahlengenerators.
Führen Sie das Experiment aus. Wenn das Experiment ausgeführt wird, können die Module Select Columns in Dataset (Spalten im Dataset auswählen) und Split Data (Daten aufteilen) die Spaltendefinitionen an die Module übergeben, die wir als Nächstes hinzufügen.
Um den Lernalgorithmus auszuwählen, erweitern Sie die Kategorie Machine Learning in der Modulpalette links vom Experimentbereich, und erweitern Sie anschließend Modell initialisieren. Daraufhin werden verschiedene Kategorien von Modulen angezeigt, die zur Initialisierung eines Algorithmus für maschinelles Lernen verwendet werden können. Wählen Sie für dieses Experiment in der Kategorie Regression das Modul Linear Regression (Lineare Regression) aus, und ziehen Sie es in den Experimentbereich. (Sie können das Modul auch suchen, indem Sie „linear regression“ in das Suchfeld der Palette eingeben.)
Suchen Sie das Modul Train Model und ziehen Sie es auf die Experiment-Canvas. Verbinden Sie die Ausgabe des Moduls Linear Regression (Lineare Regression) mit der linken Eingabe des Moduls Train Model (Modell trainieren), und verbinden Sie die Ausgabe der Trainingsdaten (den linken Port) des Moduls Split Data (Daten aufteilen) mit der rechten Eingabe des Moduls Train Model (Modell trainieren).
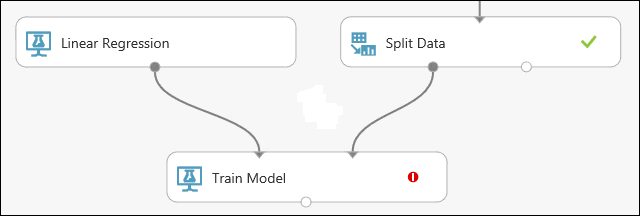
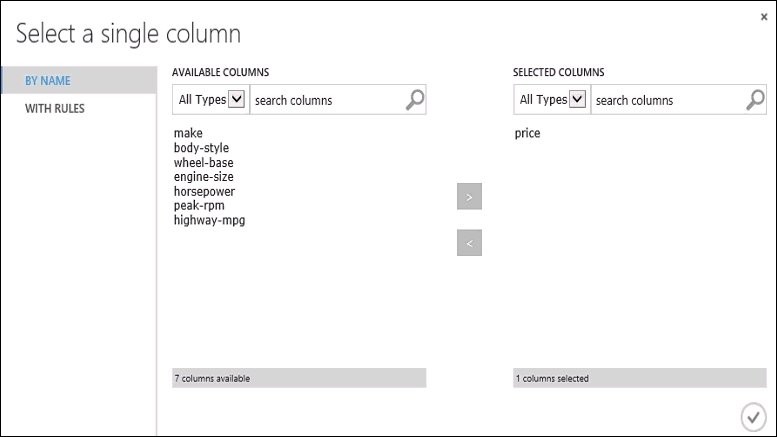
Klicken Sie auf das Modul Train Model, klicken Sie im Eigenschaftenbereich Spaltenauswahl starten, und wählen Sie dann die Spalte price aus. price ist der Wert, den unser Modell vorhersagen wird.
Wählen Sie die Spalte Price in der Spaltenauswahl aus, indem Sie sie aus der Liste Available columns (Verfügbare Spalten) in die Liste Selected columns (Ausgewählte Spalten) verschieben.
Führen Sie das Experiment aus.
Als Ergebnis erhalten Sie ein trainiertes Regressionsmodell, mit dem Sie neue Automobildaten bewerten können, um Preisvorhersagen zu treffen.
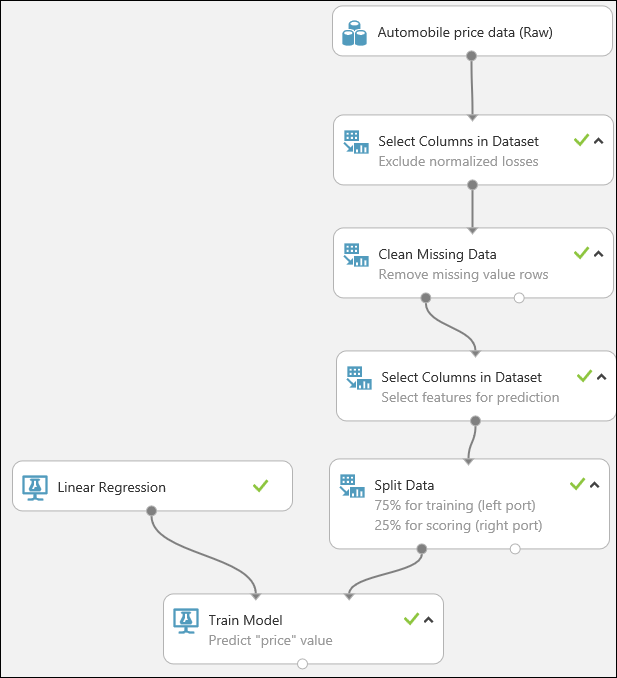
Erstellen von Preisprognosen für neue Fahrzeuge
Wir haben das Modell nun unter Verwendung von 75 Prozent unserer Daten trainiert und können die restlichen 25 Prozent der Daten dafür aufwenden, zu bewerten, wie gut unser Modell funktioniert.
Finden Sie das Modul Score Model und ziehen Sie es auf die Experimentoberfläche. Verbinden Sie die Ausgabe des Moduls Train Model mit dem linken Eingabeport des Moduls Score Model. Verbinden Sie die Testdatenausgabe (den rechten Port) des Moduls Split Data mit dem rechten Eingabeport des Moduls Score Model.
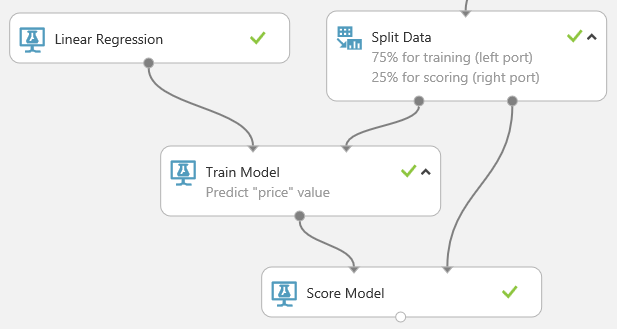
Führen Sie das Experiment aus, und zeigen Sie die Ausgabe des Moduls Score Model (Modell bewerten) an. Klicken Sie hierzu auf den Ausgabeport des Moduls Score Model (Modell bewerten), und wählen Sie Visualize (Visualisieren) aus. Die Ausgabe zeigt die vorhergesagten Preiswerte zusammen mit den bekannten Werten aus den Testdaten an.
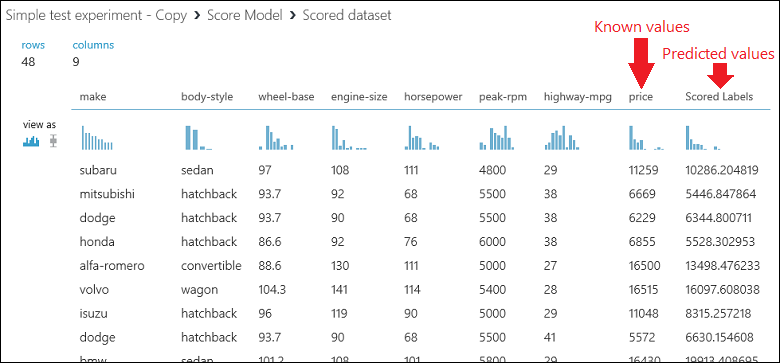
Schließlich testen wir die Qualität der Ergebnisse. Wählen Sie das Modul Evaluate Model (Modell auswerten) aus, und ziehen Sie es in den Experimentbereich. Verbinden Sie die Ausgabe des Moduls Score Model (Modell bewerten) mit der linken Eingabe des Moduls Evaluate Model (Modell auswerten). Das endgültige Experiment sollte in etwa wie folgt aussehen:
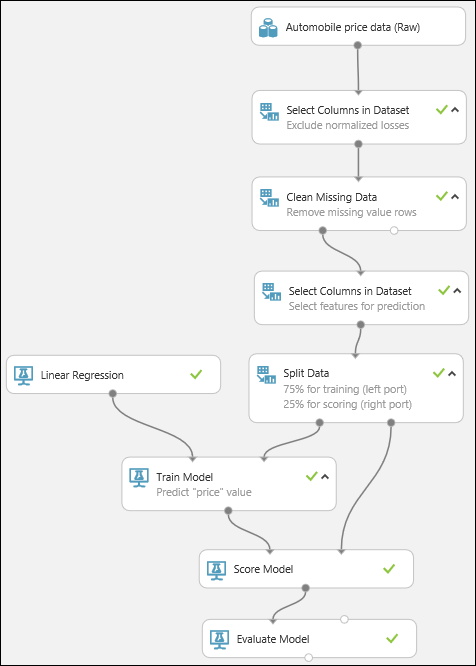
Führen Sie das Experiment aus.
Um die Ausgabe des Moduls Evaluate Model (Modell auswerten) anzuzeigen, klicken Sie auf den Ausgabeport und wählen dann Visualize (Visualisieren) aus.
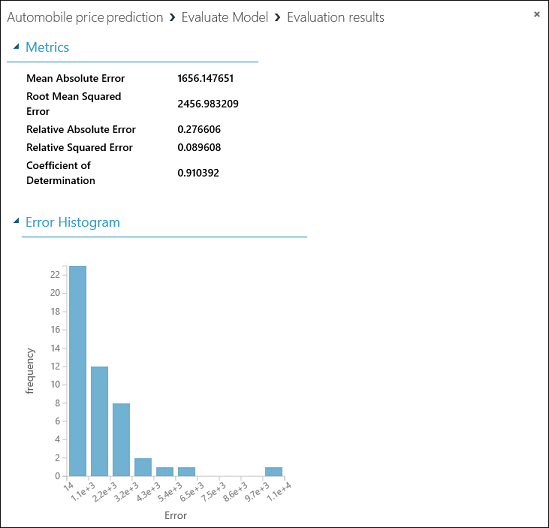
Die folgenden Statistiken werden für unser Modell angezeigt:
- Mean Absolute Error (MAE) – der Mittelwert der absoluten Fehler (ein Fehler ist die Differenz zwischen vorhergesagtem und tatsächlichem Wert).
- Root Mean Squared Error (RMSE) (Wurzel des mittleren quadratischen Fehlers): Die Quadratwurzel des Durchschnitts der quadrierten Vorhersagefehler für den Testdatensatz.
- Relative Absolute Error: Der Mittelwert der absoluten Fehler relativ zur absoluten Differenz zwischen tatsächlichen Werten und dem Durchschnitt aller tatsächlichen Werte.
- Relative Squared Error: Der Durchschnitt der quadrierten Fehler relativ zur quadrierten Differenz zwischen tatsächlichen Werten und dem Durchschnitt aller tatsächlichen Werte.
- Coefficient of Determination – dieser auch als R-Quadrat bekannte Wert ist eine statistische Kenngröße, die angibt, wie gut ein Modell zu den Daten passt.
Für jede Fehlerstatistik sind kleinere Werte besser. Ein kleinerer Wert gibt an, dass die Vorhersagen genauer mit den tatsächlichen Werten übereinstimmen. Für den Bestimmungskoeffizientengilt: Je näher der Bestimmungskoeffizient am Wert eins (1,0) liegt, desto besser die Vorhersage.
Bereinigen von Ressourcen
Wenn Sie die in diesem Artikel erstellten Ressourcen nicht mehr benötigen, löschen Sie sie, um eventuell anfallende Kosten zu vermeiden. Informationen dazu finden Sie im Artikel Exportieren und Löschen von im Produkt enthaltenen Benutzerdaten.
Nächste Schritte
In dieser Schnellstartanleitung haben Sie anhand eines Beispieldatasets ein einfaches Experiment erstellt. Fahren Sie mit dem Tutorial zur prädiktiven Lösung fort, um sich eingehender mit dem Prozess zum Erstellen und Bereitstellen eines Modells zu beschäftigen.