Verwenden von Gruppen mit Lastenausgleich zum Gruppieren von MySQL unter Linux
Wichtig
Klassische VMs werden am 1. März 2023 eingestellt.
Wenn Sie IaaS-Ressourcen aus ASM verwenden, müssen Sie die Migration bis zum 1. März 2023 abschließen. Es wird empfohlen, den Wechsel früher vorzunehmen, um die vielen verbesserten Features in Azure Resource Manager zu nutzen.
Weitere Informationen finden Sie unter Migrieren Ihrer IaaS-Ressourcen bis zum 1. März 2023 zu Azure Resource Manager.
Hinweis
Azure verfügt über zwei verschiedene Bereitstellungsmodelle zum Erstellen und Arbeiten mit Ressourcen: Azure Resource Manager und klassisch. Dieser Artikel befasst sich mit der Verwendung des klassischen Bereitstellungsmodells. Microsoft empfiehlt für die meisten neuen Bereitstellungen die Verwendung des Ressourcen-Manager-Modells. Eine Resource Manager-Vorlage ist verfügbar, wenn Sie einen MySQL-Cluster bereitstellen müssen.
Ab dem 15. November 2017 sind virtuelle Computer nur in der Azure-Portal verfügbar.
Der Zweck dieses Artikels besteht darin, die unterschiedlichen verfügbaren Ansätze für die Bereitstellung hoch verfügbarer Linux-basierter Dienste in Microsoft Azure zu untersuchen und zu veranschaulichen, wobei primär die Hochverfügbarkeit von MySQL Server untersucht wird. Ein Video, das diesen Ansatz veranschaulicht, steht unter Channel 9zur Verfügung.
Wir beschreiben eine auf DRBD, Corosync und Pacemaker basierende hoch verfügbare Einzelmaster-MYSQL-Lösung mit zwei Knoten, die nichts gemeinsam nutzen. Nur auf einem Knoten wird jeweils MySQL ausgeführt. Das Lesen und Schreiben von der DRBD-Ressource wird auch nur jeweils auf einen Knoten begrenzt.
Es besteht keine Notwendigkeit einer VIP-Lösung wie LVS, da Sie die Gruppen mit Lastenausgleich von Microsoft Azure verwenden, um eine Roundrobin-Funktionalität und die Endpunktermittlung sowie die Entfernung und die normale Wiederherstellung der VIP bereitzustellen. Die VIP ist eine globale routbare IPv4-Adresse, die beim ersten Erstellen des Clouddiensts durch Microsoft Azure zugewiesen wird.
Es gibt weitere mögliche Architekturen für MySQL, einschließlich NBD Cluster, Percona und Galera, sowie verschiedene Middleware-Lösungen, worunter mindestens eine als ein virtueller Computer auf VM Depotverfügbar ist. Solange diese Lösungen auf Unicast gegenüber Multicast repliziert werden können oder Übertragungen vornehmen und nicht auf dem gemeinsamen Speicher oder mehreren Netzwerkschnittstellen aufbauen, sollten die Szenarien auf Microsoft Azure einfach bereitzustellen sein.
Diese Clusteringarchitekturen können auf andere Produkte wie PostgreSQL und OpenLDAP auf ähnliche Weise erweitert werden. Diese Lastenausgleichsprozedur ohne gemeinsam genutzte Inhalte wurde beispielsweise erfolgreich mit Multimaster-OpenLDAP getestet. Und Sie können sie in unserem Channel 9-Blog ansehen.
Vorbereiten
Sie benötigen die folgenden Ressourcen und Fähigkeiten:
- Ein Microsoft Azure-Konto mit gültigem Abonnement, das mindestens zwei virtuelle Computer erstellen kann (in diesem Beispiel wurde XS verwendet)
- Ein Netzwerk und ein Subnetz
- Eine Affinitätsgruppe
- Eine Verfügbarkeitsgruppe
- Die Fähigkeit zum Erstellen von VHDs in der Region des Clouddiensts und deren Anfügen an die Linux-VMs
Getestete Umgebung
- Ubuntu 13.10
- DRBD
- MySQL Server
- Corosync und Pacemaker
Affinitätsgruppe
Erstellen Sie eine Affinitätsgruppe für die Lösung, indem Sie sich beim Azure-Portal anmelden, Einstellungen auswählen und eine neue Affinitätsgruppe erstellen. Später zugeordnete Ressourcen werden zu dieser Affinitätsgruppe zugewiesen.
Netzwerke
Ein neues Netzwerk wird erstellt, und ein Subnetz wird im Netzwerk erstellt. In diesem Beispiel wird ein Netzwerk des Typs „10.10.10.0/24“ mit nur einem Subnetz des Typs „/24“ verwendet.
Virtuelle Computer
Der erste virtuelle Computer unter Ubuntu 13.10 wird mithilfe eines unterstützten Ubuntu Gallery-Images erstellt und heißt hadb01. Während des Vorgangs wird der neue Clouddienst "hadb" erstellt. Dieser Name veranschaulicht die gemeinsame Nutzung mit Lastenausgleich, die der Dienst aufweist, wenn weitere Ressourcen hinzugefügt werden. Das Erstellen von hadb01 ist einfach und erfolgt über das Portal. Für SSH wird automatisch ein Endpunkt erstellt, und das neue Netzwerk wird ausgewählt. Sie können nun eine Verfügbarkeitsgruppe für die VMs erstellen.
Nachdem der erste virtuelle Computer erstellt wurde (im Prinzip während der Erstellung des Clouddiensts), erstellen Sie als Nächstes den zweiten virtuellen Computer, hadb02. Für den zweiten virtuellen Computer verwenden Sie ebenfalls den virtuellen Computer unter Ubuntu 13.10 aus dem Katalog mithilfe des Portals. Verwenden Sie jedoch den vorhandenen Clouddienst hadb.cloudapp.net, anstatt einen neuen zu erstellen. Das Netzwerk und die Verfügbarkeitsgruppe sollten automatisch ausgewählt sein. Es wird auch ein SSH-Endpunkt erstellt.
Nachdem beide virtuellen Computer erstellt wurden, notieren Sie den (automatisch durch Azure zugewiesenen) SSH-Port für hadb01 (TCP 22) und hadb02.
Angeschlossener Speicher
Fügen Sie an beide virtuellen Computer einen neuen Datenträger an, und erstellen Sie dabei 5-GB-Datenträger. Die Datenträger werden im VHD-Container gehostet, der für unsere Datenträger für das Hauptbetriebssystem verwendet wird. Nach dem Erstellen und Anfügen der Datenträger muss Linux nicht neu gestartet werden, da der Kernel das neue Gerät erkennt. Dieses Gerät ist in der Regel /dev/sdc. Überprüfen Sie dmesg auf die Ausgabe.
Erstellen Sie auf jedem virtuellen Computer mithilfe von cfdisk eine Partition (primäre Linux-Partition), und schreiben Sie die neue Partitionstabelle. Erstellen Sie kein Dateisystem auf dieser Partition.
Einrichten des Clusters
Verwenden Sie auf beiden virtuellen Ubuntu-Computern APT zum Installieren von Corosync, Pacemaker und DRBD. Um dies mit apt-get auszuführen, führen Sie den folgenden Code aus:
sudo apt-get install corosync pacemaker drbd8-utils.
Installieren Sie MySQL nicht zu diesem Zeitpunkt. Debian- und Ubuntu-Installationsskripts initialisieren ein MySQL-Datenverzeichnis unter /var/lib/mysql. Da das Verzeichnis jedoch durch ein DRBD-Dateisystem abgelöst wird, müssen Sie MySQL später installieren.
Überprüfen Sie (mithilfe von /sbin/ifconfig), ob beide virtuellen Computer Adressen im Subnetz „10.10.10.0/24“ verwenden und sich anhand des Namens gegenseitig pingen können. Sie können auch ssh-keygen und ssh-copy-id verwenden, um sicherzustellen, dass beide virtuellen Computer per SSH kommunizieren können, ohne dass dafür ein Kennwort nötig ist.
Einrichten von DRBD
Erstellen Sie eine DRBD-Ressource, die mithilfe der zugrunde liegenden Partition /dev/sdc1 die Ressource /dev/drbd1 generiert. Diese kann mit ext3 formatiert und sowohl auf primären als auch sekundären Knoten verwendet werden.
Öffnen Sie
/etc/drbd.d/r0.res, und kopieren Sie die folgende Ressourcendefinition auf beide virtuellen Computer.resource r0 { on `hadb01` { device /dev/drbd1; disk /dev/sdc1; address 10.10.10.4:7789; meta-disk internal; } on `hadb02` { device /dev/drbd1; disk /dev/sdc1; address 10.10.10.5:7789; meta-disk internal; } }Initialisieren Sie die Ressource mit
drbdadmauf beiden virtuellen Computern:sudo drbdadm -c /etc/drbd.conf role r0 sudo drbdadm up r0Erzwingen Sie auf dem primären virtuellen Computer (
hadb01) den (primären) Besitz der DRBD-Ressource:sudo drbdadm primary --force r0
Wenn Sie die Inhalte von "/proc/drbd" (sudo cat /proc/drbd) auf beiden virtuellen Computern prüfen, sollten Sie Primary/Secondary auf hadb01 und Secondary/Primary auf hadb02 sehen, wobei die Konsistenz mit der Lösung zu diesem Zeitpunkt gegeben ist. Der 5-GB-Datenträger wird über das „10.10.10.0/24“-Netzwerk synchronisiert, was für Kunden kostenlos ist.
Nach der Synchronisierung des Datenträgers können Sie das Dateisystem auf hadb01 erstellen. Für Testzwecke haben wir ext2 verwendet. Mit der folgenden Anweisung wird jedoch ein ext3-Dateisystem erstellt:
mkfs.ext3 /dev/drbd1
Bereitstellen der DRBD-Ressource
Sie können nun auf hadb01 die DRBD-Ressourcen bereitstellen. Debian und Ableitungen verwenden /var/lib/mysql als das MySQL-Datenverzeichnis. Da MySQL nicht installiert ist, erstellen Sie das Verzeichnis und stellen die DRBD-Ressource bereit. Um diese Option auszuführen, führen Sie den folgenden Code auf hadb01 aus:
sudo mkdir /var/lib/mysql
sudo mount /dev/drbd1 /var/lib/mysql
Einrichten von MySQL
Nun sind Sie bereit, MySQL auf hadb01zu installieren:
sudo apt-get install mysql-server
Für hadb02haben Sie zwei Möglichkeiten. Sie können nun „mysql-server“ installieren, wodurch „/var/lib/mysql“ erstellt wird. Füllen Sie es mit einem neuen Datenverzeichnis auf, und entfernen Sie anschließend den Inhalt. Um diese Option auszuführen, führen Sie den folgenden Code auf hadb02 aus:
sudo apt-get install mysql-server
sudo service mysql stop
sudo rm –rf /var/lib/mysql/*
Die zweite Option ist das Failover auf hadb02, um „mysql-server“ anschließend dort zu installieren. Installationsskripts erkennen die vorhandene Installation und lassen sie unverändert.
Führen den folgenden Code auf hadb01 aus:
sudo drbdadm secondary –force r0
Führen den folgenden Code auf hadb02 aus:
sudo drbdadm primary –force r0
sudo apt-get install mysql-server
Wenn Sie zu diesem Zeitpunkt kein Failover von DRBD planen, ist die erste Option einfacher, aber wohl weniger elegant. Nachdem Sie dies eingerichtet haben, können Sie mit der Arbeit in Ihrer MySQL-Datenbank beginnen. Führen Sie den folgenden Code auf hadb02 (oder auf dem gemäß DRBD gerade aktiven Server) aus:
mysql –u root –p
CREATE DATABASE azureha;
CREATE TABLE things ( id SERIAL, name VARCHAR(255) );
INSERT INTO things VALUES (1, "Yet another entity");
GRANT ALL ON things.\* TO root;
Warnung
Diese letzte Anweisung deaktiviert die Authentifizierung effektiv für den Stammbenutzer in dieser Tabelle. Diese sollte durch Ihre produktionsfähigen GRANT-Anweisungen ersetzt werden und dient nur zur Veranschaulichung.
Sie müssen den Netzwerkbetrieb für MySQL aktivieren, wenn Sie Abfragen von außerhalb der virtuellen Computer vornehmen möchten (worin der Zweck dieses Leitfadens besteht). Öffnen Sie auf beiden virtuellen Computer /etc/mysql/my.cnf, und wechseln Sie zu bind-address. Ändern Sie die Adresse von 127.0.0.1 in 0.0.0.0. Stellen Sie nach dem Speichern der Datei einen sudo service mysql restart auf Ihrem aktuellen primären Computer aus.
Erstellen der MySQL-Gruppe mit Lastenausgleich
Wechseln Sie zurück im Portal zu hadb01, und wählen Sie Endpunkte. Wählen Sie zum Erstellen eines Endpunkts in der Dropdownliste „MySQL (TCP-Port 3306)“ und dann Gruppe mit Lastenausgleich erstellen aus. Nennen Sie den Endpunkt mit Lastenausgleich lb-mysql. Legen Sie Zeit auf mindestens fünf Sekunden fest.
Nachdem Sie den Endpunkt erstellt haben, wechseln Sie zu hadb02. Wählen Sie Endpunkte, und erstellen Sie einen Endpunkt. Wählen Sie lb-mysql und dann in der Dropdownliste „MySQL“ aus. Sie können auch die Azure-Befehlszeilenschnittstelle für diesen Schritt verwenden.
Nun haben Sie alles, was für einen manuellen Betrieb des Clusters benötigt wird.
Testen der Gruppe mit Lastenausgleich
Tests können auf einem externen Computer mit einem beliebigen MySQL-Client oder mithilfe bestimmter Anwendungen erfolgen, z.B. mit PhpMyAdmin, das als Azure-Website ausgeführt wird. In diesem Fall haben Sie das MySQL Befehlszeilentool auf einem anderen Linux-Computer verwendet:
mysql azureha –u root –h hadb.cloudapp.net –e "select * from things;"
Manuelles Failover
Sie können Failover simulieren, indem Sie MySQL herunterfahren, den primären Computer von DRBD wechseln und MySQL erneut starten.
Um diese Option auszuführen, führen Sie den folgenden Code auf „hadb01“ aus:
service mysql stop && umount /var/lib/mysql ; drbdadm secondary r0
Dann auf hadb02:
drbdadm primary r0 ; mount /dev/drbd1 /var/lib/mysql && service mysql start
Nachdem das manuelle Failover erfolgt ist, können Sie Ihre Remoteabfrage wiederholen, die perfekt funktionieren sollte.
Einrichten von Corosync
Corosync ist die zugrunde liegende Clusterinfrastruktur, die erforderlich ist, damit Pacemaker funktioniert. Für Heartbeat (und andere Methoden wie Ultramonkey) bietet Corosync einen Teil der CRM-Funktionalitäten, während Pacemaker in puncto Funktionalität Heartbeart ähnlicher ist.
Die Haupteinschränkung für Corosync auf Azure besteht darin, dass Corosync Multicast- über Übertragungs- über Unicast-Kommunikationen bevorzugt. Das Microsoft Azure-Netzwerk unterstützt jedoch nur Unicast.
Glücklicherweise bietet Corosync einen funktionierenden Unicastmodus. Die einzige wirkliche Einschränkung besteht darin, dass Sie die Knoten in Ihren Konfigurationsdateien definieren müssen, einschließlich ihrer IP-Adressen (da nicht alle Knoten miteinander kommunizieren). Wir können die Corosync-Beispieldateien für Unicast verwenden und einfach die BIND-Adresse, Knotenlisten und das Protokollierungsverzeichnis ändern (Ubuntu verwendet /var/log/corosync, während in der Beispieldatei /var/log/cluster verwendet wird) sowie Quorumtools aktivieren.
Hinweis
Beachten Sie unten die Direktive transport: udpu sowie die manuell definierten IP-Adressen für beide Knoten.
Führen den folgenden Code auf /etc/corosync/corosync.conf für beide Knoten aus:
totem {
version: 2
crypto_cipher: none
crypto_hash: none
interface {
ringnumber: 0
bindnetaddr: 10.10.10.0
mcastport: 5405
ttl: 1
}
transport: udpu
}
logging {
fileline: off
to_logfile: yes
to_syslog: yes
logfile: /var/log/corosync/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
nodelist {
node {
ring0_addr: 10.10.10.4
nodeid: 1
}
node {
ring0_addr: 10.10.10.5
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
}
Kopieren Sie diese Konfigurationsdatei auf beide virtuellen Computer, und starten Sie Corosync auf beiden Knoten:
sudo service start corosync
Kurz nach dem Start des Diensts sollten der Cluster im aktuellen Ring hergestellt und das Quorum errichtet sein. Wir können diese Funktionalität prüfen, indem die entsprechenden Protokolle angezeigt oder der folgenden Code ausgeführt wird:
sudo corosync-quorumtool –l
Eine Ausgabe ähnlich der folgenden Abbildung wird angezeigt:
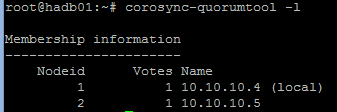
Einrichten von Pacemaker
Pacemaker verwendet den Cluster zum Überwachen auf Ressourcen, zum Definieren, wann primäre Computer heruntergefahren werden und zum Wechseln dieser Ressourcen zu sekundären Computern. Ressourcen können unter anderem über eine Reihe verfügbarer Skripts oder über (init-ähnliche) LSB-Skripts definiert werden.
Wir möchten, dass Pacemaker die DRBD-Ressource, den Bereitstellungspunkt und den MySQL-Dienst „besitzt“. Wenn Pacemaker DRBD aktivieren und deaktivieren, bereitstellen und die Bereitstellung von DRBD aufheben sowie MySQL in der richtigen Reihenfolge starten/anhalten kann, sobald ein Fehler auf dem primären Computer vorliegt, ist unsere Einrichtung abgeschlossen.
Beim ersten Installieren von Pacemaker sollte Ihre Konfiguration einfach genug sein, und zwar in etwa so:
node $id="1" hadb01
attributes standby="off"
node $id="2" hadb02
attributes standby="off"
Überprüfen Sie die Konfiguration durch Ausführen von
sudo crm configure show.Erstellen Sie dann eine Datei (z.B.
/tmp/cluster.conf) mit den folgenden Ressourcen:primitive drbd_mysql ocf:linbit:drbd \ params drbd_resource="r0" \ op monitor interval="29s" role="Master" \ op monitor interval="31s" role="Slave" ms ms_drbd_mysql drbd_mysql \ meta master-max="1" master-node-max="1" \ clone-max="2" clone-node-max="1" \ notify="true" primitive fs_mysql ocf:heartbeat:Filesystem \ params device="/dev/drbd/by-res/r0" \ directory="/var/lib/mysql" fstype="ext3" primitive mysqld lsb:mysql group mysql fs_mysql mysqld colocation mysql_on_drbd \ inf: mysql ms_drbd_mysql:Master order mysql_after_drbd \ inf: ms_drbd_mysql:promote mysql:start property stonith-enabled=false property no-quorum-policy=ignoreLaden Sie die Datei in die Konfiguration. Dies ist nur auf einem Knoten erforderlich.
sudo crm configure load update /tmp/cluster.conf commit exitStellen Sie sicher, dass Pacemaker beim Booten auf beiden Knoten startet:
sudo update-rc.d pacemaker defaultsStellen Sie mithilfe von
sudo crm_mon –Lsicher, dass einer Ihrer Knoten zum Master für den Cluster geworden ist und alle Ressourcen ausführt. Sie können "mount" und "ps" verwenden, um zu überprüfen, ob die Ressourcen ausgeführt werden.
Der folgende Screenshot zeigt crm_mon mit einem angehaltenen Knoten (Beenden mit STRG-C).
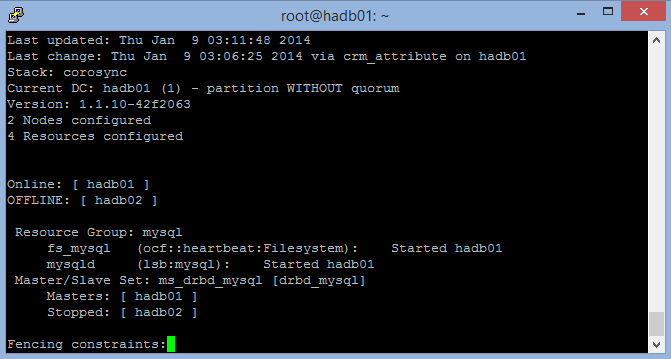
Dieser Screenshot zeigt beide Knoten, den Master und den untergeordneten Knoten:

Testen
Sie sind bereit für eine automatische Failoversimulation. Hierfür gibt es zwei Möglichkeiten: „weich“ und „hart“.
Die weiche Variante verwendet die Funktion zum Herunterfahren des Clusters: crm_standby -U `uname -n` -v on. Wenn diese auf dem Master verwendet wird, übernimmt der untergeordnete Knoten. Vergessen Sie nicht, diese Einstellung wieder auf „Off“ zurückzusetzen. Wenn Sie dies nicht tun, zeigt „crm_mon“ einen Knoten als „Standby“ an.
Die „harte“ Variante ist das Herunterfahren des primären virtuellen Computers (hadb01) im Portal oder Ändern der Ausführungsebene auf dem virtuellen Computer (d.h. „halt, shutdown“). Dies hilft Corosync und Pacemaker, indem signalisiert wird, dass der Master ausfällt. Sie können dies testen (nützlich für Wartungsfenster). Sie können das Szenario jedoch auch erzwingen, indem der virtuelle Computer eingefroren wird.
STONITH
Es sollte möglich sein, das Herunterfahren eines virtuellen Computers über die Azure-Befehlszeilenschnittstelle auszulösen (anstelle eines STONITH-Skripts, das ein physisches Gerät steuert). Sie können /usr/lib/stonith/plugins/external/ssh als Basis verwenden und STONITH in der Konfiguration des Clusters aktivieren. Die Azure CLI muss global installiert sein, und die Veröffentlichungseinstellungen/-profile müssen für den Benutzer des Clusters geladen sein.
Beispielcode für die Ressourcen finden Sie auf GitHub. Ändern Sie die Konfiguration des Clusters, indem Sie sudo crm configure Folgendes hinzufügen:
primitive st-azure stonith:external/azure \
params hostlist="hadb01 hadb02" \
clone fencing st-azure \
property stonith-enabled=true \
commit
Hinweis
Das Skript führt keine Überprüfungen nach oben/unten aus. Die ursprüngliche SSH-Ressource wies 15 Pingüberprüfungen auf. Doch die Wiederherstellungszeit für einen virtuellen Azure-Computer ist möglicherweise unterschiedlich.
Einschränkungen
Es gelten die folgenden Einschränkungen:
- Das DRBD-Ressourcenskript „linbit“, das DRBD als eine Ressource in Pacemaker verwaltet, verwendet beim Herunterfahren eines Knotens
drbdadm down, selbst wenn der Knoten gerade in den Standbymodus wechselt. Dies ist nicht optimal, da der untergeordnete Knoten die DRBD-Ressource nicht synchronisiert, während der Master Schreibvorgänge abruft. Wenn das Failover des Masters nicht ordnungsgemäß erfolgt, kann der untergeordnete Knoten einen älteren Dateisystemstatus übernehmen. Zur Behebung dieses Problems stehen zwei potenzielle Möglichkeiten zur Verfügung:- Erzwingen eines
drbdadm up r0auf allen Clusterknoten über einen lokalen (nicht gruppierten) Watchdog - Bearbeiten des DRBD-Skripts „linbit“, wodurch sichergestellt wird, dass
downnicht in/usr/lib/ocf/resource.d/linbit/drbdaufgerufen wird
- Erzwingen eines
- Der Lastenausgleich benötigt mindestens fünf Sekunden für eine Reaktion, damit Anwendungen clusterfähig und toleranter für Timeouts werden. Andere Architekturen wie In-App-Warteschlangen und Abfrage-Middlewares können auch hilfreich sein.
- Die MySQL-Feinabstimmung ist erforderlich, um sicherzustellen, dass der Schreibvorgang in einer vernünftigen Geschwindigkeit erfolgt und Zwischenspeicherungen möglichst häufig auf den Datenträger übertragen werden, um Speicherverluste zu vermeiden.
- Die Schreibleistung hängt vom Interconnect des virtuellen Computers im virtuellen Switch ab, da es sich hierbei um den Mechanismus handelt, der durch DRBD zum Replizieren des Geräts verwendet wird.