Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Sie können Tiling verwenden, um die Beschleunigung Ihrer App zu maximieren. Bei der Kachelung werden Threads in gleich große rechteckige Teilmengen oder Kacheln unterteilt. Wenn Sie eine geeignete Kachelgröße und einen Tile-Algorithmus verwenden, können Sie noch mehr Beschleunigung aus Ihrem C++ AMP-Code erzielen. Die grundlegenden Komponenten der Tilung sind:
tile_staticVariablen. Der Hauptvorteil der Tilung ist der Leistungszuwachs durch den Zugriff mittile_static. Der Zugriff auf Daten imtile_staticArbeitsspeicher kann wesentlich schneller sein als der Zugriff auf Daten im globalen Raum (arrayoderarray_viewObjekte). Eine Instanz einertile_static-Variable wird für jeden Tile erstellt, und alle Threads in den Tile haben Zugriff auf die Variable. In einem typischen kachelbasierten Algorithmus werden Daten einmal aus dem globalen Speicher in dentile_staticSpeicher kopiert und dann mehrmals auf dentile_staticSpeicher zugegriffen.tile_barrier::wait-Methode. Ein Aufruf an
tile_barrier::waitunterbricht die Ausführung des aktuellen Threads, bis alle Threads in derselben Kachel den Aufruf antile_barrier::waiterreichen. Sie können die Reihenfolge nicht garantieren, in der die Threads ausgeführt werden, nur dass keine Threads innerhalb der Kachel über den Aufruf vontile_barrier::waithinaus ausgeführt werden, bis alle Threads den Aufruf erreicht haben. Dies bedeutet, dass Sie mithilfe dertile_barrier::waitMethode Aufgaben auf Kachel-nach-Kachel-Basis anstelle von Thread-nach-Thread-Basis ausführen können. Ein typischer Tilingalgorithmus verfügt über Code zum Initialisieren destile_staticSpeichers für die gesamte Kachel gefolgt von einem Aufruf vontile_barrier::wait. Der folgendetile_barrier::waitCode enthält Berechnungen, die Zugriff auf alletile_staticWerte benötigen.Lokale und globale Indizierung. Sie haben Zugriff auf den Index des Threads relativ zum gesamten
arrayObjekt und relativ zur Kachel. Die Verwendung des lokalen Indexes erleichtert das Lesen und Debuggen des Codes. In der Regel verwenden Sie lokale Indizierung für den Zugriff auftile_staticVariablen und globale Indizierung für Zugriffarrayundarray_viewVariablen.tiled_extent-Klasse und tiled_index-Klasse. Sie verwenden ein
tiled_extentObjekt anstelle einesextentObjekts imparallel_for_eachAufruf. Sie verwenden eintiled_indexObjekt anstelle einesindexObjekts imparallel_for_eachAufruf.
Um die Tilung zu nutzen, muss Ihr Algorithmus die Computedomäne in Kacheln partitionieren und dann die Kacheldaten in tile_static Variablen kopieren, um schneller darauf zugreifen zu können.
Beispiel für globale, Tile-, und lokale Indizes
Hinweis
C++AMP-Header sind ab Visual Studio 2022, Version 17.0, veraltet.
Wenn alle AMP-Header einbezogen werden, führt dies zu Buildfehlern. Definieren Sie _SILENCE_AMP_DEPRECATION_WARNINGS , bevor Sie AMP-Header einschließen, um die Warnungen zu stillen.
Das folgende Diagramm stellt eine 8x9-Matrix von Daten dar, die in 2x3-Kacheln angeordnet ist.
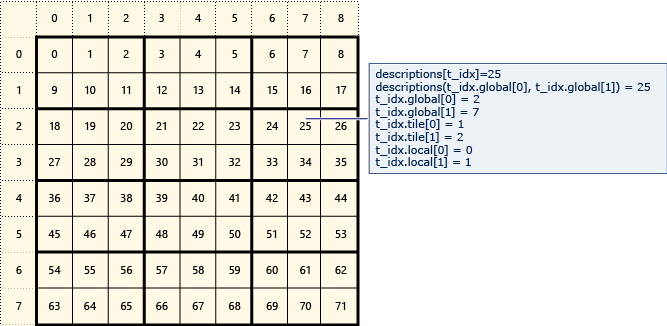
Im folgenden Beispiel werden die globalen, Kachel- und lokalen Indizes dieser nebeneinander angeordneten Matrix angezeigt. Ein array_view Objekt wird mithilfe von Elementen vom Typ Descriptionerstellt. Die Description enthält die globalen, Kachel- und lokalen Indizes des Elements in der Matrix. Der Code im Aufruf von parallel_for_each legt die Werte der globalen, tile und lokalen Indizes der einzelnen Elemente fest. Die Ausgabe zeigt die Werte in den Description Strukturen an.
#include <iostream>
#include <iomanip>
#include <Windows.h>
#include <amp.h>
using namespace concurrency;
const int ROWS = 8;
const int COLS = 9;
// tileRow and tileColumn specify the tile that each thread is in.
// globalRow and globalColumn specify the location of the thread in the array_view.
// localRow and localColumn specify the location of the thread relative to the tile.
struct Description {
int value;
int tileRow;
int tileColumn;
int globalRow;
int globalColumn;
int localRow;
int localColumn;
};
// A helper function for formatting the output.
void SetConsoleColor(int color) {
int colorValue = (color == 0) 4 : 2;
SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), colorValue);
}
// A helper function for formatting the output.
void SetConsoleSize(int height, int width) {
COORD coord;
coord.X = width;
coord.Y = height;
SetConsoleScreenBufferSize(GetStdHandle(STD_OUTPUT_HANDLE), coord);
SMALL_RECT* rect = new SMALL_RECT();
rect->Left = 0;
rect->Top = 0;
rect->Right = width;
rect->Bottom = height;
SetConsoleWindowInfo(GetStdHandle(STD_OUTPUT_HANDLE), true, rect);
}
// This method creates an 8x9 matrix of Description structures.
// In the call to parallel_for_each, the structure is updated
// with tile, global, and local indices.
void TilingDescription() {
// Create 72 (8x9) Description structures.
std::vector<Description> descs;
for (int i = 0; i < ROWS * COLS; i++) {
Description d = {i, 0, 0, 0, 0, 0, 0};
descs.push_back(d);
}
// Create an array_view from the Description structures.
extent<2> matrix(ROWS, COLS);
array_view<Description, 2> descriptions(matrix, descs);
// Update each Description with the tile, global, and local indices.
parallel_for_each(descriptions.extent.tile< 2, 3>(),
[=] (tiled_index< 2, 3> t_idx) restrict(amp)
{
descriptions[t_idx].globalRow = t_idx.global[0];
descriptions[t_idx].globalColumn = t_idx.global[1];
descriptions[t_idx].tileRow = t_idx.tile[0];
descriptions[t_idx].tileColumn = t_idx.tile[1];
descriptions[t_idx].localRow = t_idx.local[0];
descriptions[t_idx].localColumn= t_idx.local[1];
});
// Print out the Description structure for each element in the matrix.
// Tiles are displayed in red and green to distinguish them from each other.
SetConsoleSize(100, 150);
for (int row = 0; row < ROWS; row++) {
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Value: " << std::setw(2) << descriptions(row, column).value << " ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Tile: " << "(" << descriptions(row, column).tileRow << "," << descriptions(row, column).tileColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Global: " << "(" << descriptions(row, column).globalRow << "," << descriptions(row, column).globalColumn << ") ";
}
std::cout << "\n";
for (int column = 0; column < COLS; column++) {
SetConsoleColor((descriptions(row, column).tileRow + descriptions(row, column).tileColumn) % 2);
std::cout << "Local: " << "(" << descriptions(row, column).localRow << "," << descriptions(row, column).localColumn << ") ";
}
std::cout << "\n";
std::cout << "\n";
}
}
int main() {
TilingDescription();
char wait;
std::cin >> wait;
}
Die Hauptarbeit des Beispiels befindet sich in der Definition des array_view Objekts und des Aufrufs von parallel_for_each.
Der Vektor von
DescriptionStrukturen wird in ein 8x9-Objektarray_viewkopiert.Die
parallel_for_eachMethode wird mit einemtiled_extentObjekt als Computedomäne aufgerufen. Dastiled_extentObjekt wird durch Aufrufen derextent::tile()Methode derdescriptionsVariablen erstellt. Die Typparameter des Aufrufsextent::tile()von<2,3>geben an, dass 2x3 Kacheln erstellt werden. Daher wird die 8x9-Matrix in 12 Kacheln, vier Zeilen und drei Spalten unterteilt.Die
parallel_for_eachMethode wird mithilfe einestiled_index<2,3>Objekts (t_idx) als Index aufgerufen. Die Typparameter des Indexes (t_idx) müssen den Typparametern der Computedomäne (descriptions.extent.tile< 2, 3>()) entsprechen.Wenn jeder Thread ausgeführt wird, gibt der Index
t_idxInformationen darüber zurück, in welcher Kachel sich der Thread befindet (tiled_index::tileEigenschaft) und die Position des Threads innerhalb der Kachel (tiled_index::localEigenschaft).
Kachelsynchronisierung – tile_static und tile_barrier::wait
Das vorherige Beispiel veranschaulicht das Kachellayout und die Indizes, ist aber nicht selbst sehr nützlich. Die Kachelung wird nützlich, wenn die Kacheln wesentlicher Bestandteil des Algorithmus sind und die tile_static Variablen ausnutzen. Da alle Threads in einer Kachel Zugriff auf tile_static Variablen haben, werden Aufrufe tile_barrier::wait verwendet, um den Zugriff auf die tile_static Variablen zu synchronisieren. Obwohl alle Threads in einer Kachel Zugriff auf die tile_static Variablen haben, gibt es keine garantierte Reihenfolge der Ausführung von Threads in der Kachel. Das folgende Beispiel zeigt, wie tile_static Variablen und die tile_barrier::wait Methode verwendet werden, um den Mittelwert jeder Kachel zu berechnen. Hier sind die Schlüssel zum Verständnis des Beispiels:
Die rawData wird in einer 8x8-Matrix gespeichert.
Die Kachelgröße beträgt 2x2. Dadurch wird ein 4x4-Raster mit Kacheln erstellt, und die Mittelwerte können mithilfe eines
arrayObjekts in einer 4x4-Matrix gespeichert werden. Es gibt nur eine begrenzte Anzahl von Typen, die Sie in einer AMP-eingeschränkten Funktion referenzieren können. DiearrayKlasse ist eine davon.Die Matrixgröße und die Stichprobengröße werden mithilfe von
#defineAnweisungen definiert, da die Typparameter fürarray,array_view, ,extentundtiled_indexmüssen Konstantenwerte sein. Sie können auch Deklarationen verwendenconst int static. Als zusätzlicher Vorteil ist es trivial, die Stichprobengröße zu ändern, um den Durchschnitt über 4x4 Kacheln zu berechnen.Für jede Kachel wird ein
tile_static2x2-Array mit Float-Werten deklariert. Obwohl sich die Deklaration im Codepfad für jeden Thread befindet, wird für jede Kachel in der Matrix nur ein Array erstellt.Es gibt eine Codezeile, um die Werte in jeder Kachel in das
tile_staticArray zu kopieren. Nach dem Kopieren des Werts in das Array wird für jeden Thread die Ausführung im Thread aufgrund des Aufrufstile_barrier::waitbeendet.Wenn alle Threads in einer Kachel die Barriere erreicht haben, kann der Mittelwert berechnet werden. Da der Code für jeden Thread ausgeführt wird, gibt es eine
ifAnweisung, um den Mittelwert nur für einen Thread zu berechnen. Der Mittelwert wird in der Mittelwertvariablen gespeichert. Die Barriere ist im Wesentlichen das Konstrukt, das Berechnungen nach Kachel steuert, ähnlich wie Sie eine Schleifeforverwenden können.Die Daten in der
averagesVariablen, da es sich um einarrayObjekt handelt, müssen wieder in den Host kopiert werden. In diesem Beispiel wird der Vektorkonvertierungsoperator verwendet.Im vollständigen Beispiel können Sie SAMPLESIZE in 4 ändern und der Code wird ohne andere Änderungen ordnungsgemäß ausgeführt.
#include <iostream>
#include <amp.h>
using namespace concurrency;
#define SAMPLESIZE 2
#define MATRIXSIZE 8
void SamplingExample() {
// Create data and array_view for the matrix.
std::vector<float> rawData;
for (int i = 0; i < MATRIXSIZE * MATRIXSIZE; i++) {
rawData.push_back((float)i);
}
extent<2> dataExtent(MATRIXSIZE, MATRIXSIZE);
array_view<float, 2> matrix(dataExtent, rawData);
// Create the array for the averages.
// There is one element in the output for each tile in the data.
std::vector<float> outputData;
int outputSize = MATRIXSIZE / SAMPLESIZE;
for (int j = 0; j < outputSize * outputSize; j++) {
outputData.push_back((float)0);
}
extent<2> outputExtent(MATRIXSIZE / SAMPLESIZE, MATRIXSIZE / SAMPLESIZE);
array<float, 2> averages(outputExtent, outputData.begin(), outputData.end());
// Use tiles that are SAMPLESIZE x SAMPLESIZE.
// Find the average of the values in each tile.
// The only reference-type variable you can pass into the parallel_for_each call
// is a concurrency::array.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before you calculate the average.
t_idx.barrier.wait();
// If you remove the if statement, then the calculation executes for every
// thread in the tile, and makes the same assignment to averages each time.
if (t_idx.local[0] == 0 && t_idx.local[1] == 0) {
for (int trow = 0; trow < SAMPLESIZE; trow++) {
for (int tcol = 0; tcol < SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE * SAMPLESIZE);
}
});
// Print out the results.
// You cannot access the values in averages directly. You must copy them
// back to a CPU variable.
outputData = averages;
for (int row = 0; row < outputSize; row++) {
for (int col = 0; col < outputSize; col++) {
std::cout << outputData[row*outputSize + col] << " ";
}
std::cout << "\n";
}
// Output for SAMPLESIZE = 2 is:
// 4.5 6.5 8.5 10.5
// 20.5 22.5 24.5 26.5
// 36.5 38.5 40.5 42.5
// 52.5 54.5 56.5 58.5
// Output for SAMPLESIZE = 4 is:
// 13.5 17.5
// 45.5 49.5
}
int main() {
SamplingExample();
}
Rennbedingungen
Es kann verlockend sein, eine tile_static Variable namens total zu erstellen und die Variable wie folgt für jeden Thread zu inkrementieren:
// Do not do this.
tile_static float total;
total += matrix[t_idx];
t_idx.barrier.wait();
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
Das erste Problem bei diesem Ansatz besteht darin, dass tile_static Variablen keine Initialisierer haben können. Das zweite Problem besteht darin, dass es eine Race-Condition für die Zuordnung total gibt, da alle Threads in der Kachel Zugriff auf die Variable in keiner bestimmten Reihenfolge haben. Sie könnten einen Algorithmus programmieren, um nur einem Thread den Zugriff auf die Gesamtsumme bei jeder Barriere zu ermöglichen, wie im nächsten dargestellt. Diese Lösung ist jedoch nicht erweiterbar.
// Do not do this.
tile_static float total;
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
total = matrix[t_idx];
}
t_idx.barrier.wait();
if (t_idx.local[0] == 0&& t_idx.local[1] == 1) {
total += matrix[t_idx];
}
t_idx.barrier.wait();
// etc.
Speicherzäune
Es gibt zwei Arten von Speicherzugriffen, die synchronisiert werden müssen: globaler Speicherzugriff und tile_static Speicherzugriff. Ein concurrency::array Objekt weist nur den globalen Speicher zu. Ein concurrency::array_view kann, je nachdem, wie es erstellt wurde, auf globalen Speicher, tile_static Speicher oder beides verweisen. Es gibt zwei Arten von Arbeitsspeicher, die synchronisiert werden müssen:
Globaler Speicher
tile_static
Ein Speicherzaun stellt sicher, dass Speicherzugriffe für andere Threads in der Threadkachel verfügbar sind und dass Speicherzugriffe gemäß der Programmreihenfolge ausgeführt werden. Um dies sicherzustellen, ordnen Compiler und Prozessoren Lese- und Schreibvorgänge nicht über die Speicherbarriere hinweg neu an. In C++ AMP wird ein Speicherzaun durch einen Aufruf einer der folgenden Methoden erstellt:
tile_barrier::wait-Methode: Erstellt eine Barriere sowohl um den globalen als auch um den Speicher.
tile_barrier::wait_with_all_memory_fence Methode: Erstellt einen Zaun sowohl um den globalen als
tile_staticauch den Arbeitsspeicher.tile_barrier::wait_with_global_memory_fence-Methode: Erstellt eine Sperre nur um den globalen Speicher.
tile_barrier::wait_with_tile_static_memory_fence-Methode: Erstellt einen Zaun nur
tile_staticum den Arbeitsspeicher.
Das Aufrufen des spezifischen Zauns, den Sie benötigen, kann die Leistung Ihrer App verbessern. Der Barrieretyp beeinflusst, wie der Compiler und die Hardware Anweisungen neu anordnen. Wenn Sie beispielsweise einen globalen Speicherzaun verwenden, gilt er nur für globalen Speicherzugriff und daher kann der Compiler und die Hardware Lese- und Schreibvorgänge in tile_static Variablen auf den beiden Seiten des Zauns neu anordnen.
Im nächsten Beispiel synchronisiert die Barriere die Schreibvorgänge mit tileValueseiner tile_static Variablen. In diesem Beispiel wird tile_barrier::wait_with_tile_static_memory_fence anstelle von tile_barrier::wait aufgerufen.
// Using a tile_static memory fence.
parallel_for_each(matrix.extent.tile<SAMPLESIZE, SAMPLESIZE>(),
[=, &averages] (tiled_index<SAMPLESIZE, SAMPLESIZE> t_idx) restrict(amp)
{
// Copy the values of the tile into a tile-sized array.
tile_static float tileValues[SAMPLESIZE][SAMPLESIZE];
tileValues[t_idx.local[0]][t_idx.local[1]] = matrix[t_idx];
// Wait for the tile-sized array to load before calculating the average.
t_idx.barrier.wait_with_tile_static_memory_fence();
// If you remove the if statement, then the calculation executes
// for every thread in the tile, and makes the same assignment to
// averages each time.
if (t_idx.local[0] == 0&& t_idx.local[1] == 0) {
for (int trow = 0; trow <SAMPLESIZE; trow++) {
for (int tcol = 0; tcol <SAMPLESIZE; tcol++) {
averages(t_idx.tile[0],t_idx.tile[1]) += tileValues[trow][tcol];
}
}
averages(t_idx.tile[0],t_idx.tile[1]) /= (float) (SAMPLESIZE* SAMPLESIZE);
}
});
Siehe auch
C++ AMP (C++-Beschleunigter massiver Parallelismus)
tile_static-Schlüsselwort