SQL Server
Reduce Downtime: Implement SQL Server 2000 On A Cluster
Stephen Strong
At a Glance:
- Implement a SQL Server cluster for more uptime
- Configure your heartbeat networks and nodes
- Set partition sizes and allocate memory usage
- Employ the correct security settings
SQL Server
Windows Server 2003
Microsoft Cluster Service
DTC
Hardware failures are inevitable. Even the firmware that provides hardware redundancy at the server, storage, or network level can fail. Failover clustering is an option that provides you with more uptime for your SQL Server installation.
While no feature-rich system can eliminate downtime completely, installing Microsoft® SQL Server™ 2000 on a Windows Server™ 2003 failover cluster should provide more uptime by alleviating your reliance on a single server. Clustering reduces single points of failure by spreading the load and adding redundancy. In this article I'll discuss the merits of clustering with SQL Server 2000 Enterprise Edition on Windows Server 2003 Enterprise Edition using the Microsoft Cluster Service (MSCS), or on Windows Server 2003 Datacenter Edition using the Cluster Service, which is a component of both of these versions of Windows® (not to be confused with Network Load Balancing clustering).
Although many of the concepts discussed apply equally to SQL Server 2000 64-bit on Windows Server 2003 64-bit, I will cover the 32-bit scenarios.
The Cluster Configuration
The first place to start, of course, is with a look at your hardware. Clustered solutions need to be carefully planned and the hardware configuration you use must be supported by both Microsoft and the hardware vendor. A good list of supported hardware solutions is available in the Windows Server Catalog.
The next thing to consider is the network configuration. A basic MSCS cluster must have at least two separate networks. The first network connects the clustered server nodes to other essential applications, such as domain controllers (DC), DNS servers, and application servers. In this article I'll refer to this as the public network.
Also mandatory is the heartbeat network, which connects each of the cluster nodes to one another. It glues the cluster together and keeps it alive. When one node stops responding, the other nodes recognize this and take ownership of resources that were running on the failed node.
It is good practice to have two heartbeat networks. Although a single-heartbeat network is a permitted configuration (with the public network as a backup), it is far from desirable. Nodes send IsAlive messages to each other every 1.2 seconds. This pulsing of messages requires that network latency on the heartbeat network between the nodes must be less than 500ms; therefore, the isolated heartbeat network must not be burdened with non-cluster service traffic. When there's only one heartbeat network and it encounters a failure, the public network (which carries all kinds of other application traffic as well) must take over the job of the heartbeat network at a reduced capacity. Therefore, a more suitable arrangement is to have two heartbeat networks, each with its own switch. Having two identical heartbeat networks permits one heartbeat network to fail and the other to continue providing identical functionality. Figure 1 shows the architecture of the network I am building here.
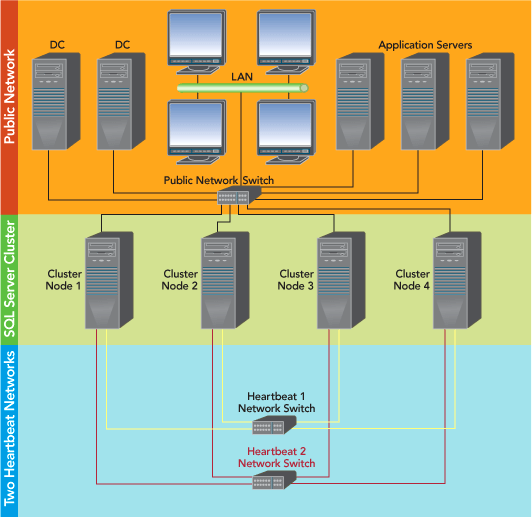
Figure 1** SQL Server Failover Cluster with Two Heartbeat Networks **
Now let's look at the network interface cards (NICs). Network card teaming, where a number of network cards in a single server all operate as a team, is not supported on heartbeat networks. Running multiple heartbeat or public networks on VLAN-configured switches is also not supported by Microsoft. In this clustering solution, no network can share a single point of failure with another network.
Network cards, like other hardware components, are prone to failure. Many organizations use Network Card Teaming on the public network to provide greater resilience. Although Microsoft doesn't fully support Network Card Teaming in a SQL Server failover cluster, it will allow it on the public network provided it is removed for troubleshooting purposes if a particular problem is related to network connectivity.
If the Teaming solution you use has options for fault tolerance and load balancing, select fault tolerance. If there is a requirement for faster network throughput on the public network, purchase faster NICs and network switches rather than allowing yourself to be tempted by load balancing NIC software which introduces another single point of failure. For information on configuration, see the sidebar "Configuring Heartbeat NICS."
As a final note on configuration, while we've been told that antivirus software is essential everywhere, you shouldn't install it on the SQL Server failover cluster. You'll need to investigate other ways to protect the servers from viruses. Not only will antivirus software negatively impact performance on a SQL Server 2000 failover cluster, it may also destabilize it.
Using Multiple Groups
Patches
Apart from the DTC patch there are also some memory leaks in the Volume Shadow Copy Service that may affect the servers if a backup agent is used to back up session state or the file system. For more information on this, see Backup Program Causes Gradually Declining Performance and A memory leak occurs in an application using the Volume Shadow Copy Service on a computer that is running Windows Server 2003.
There is a bug in the clures.dll that can cause a resource to fail to restart during a group move or failover between nodes after expanding virtual disks on a cluster. See the Knowledge Base article at Volume information is lost when you extend a partition by using the DiskPart tool and then move the volume in a Windows Server 2003 cluster.
The minimum SQL Server 2000 version should be 8.00.818 (SP3A + 818 hotfix) as this is covered in the latest security bulletin. I'd recommend 8.00.952 or start with 8.00.818 and move straight to SP4 (due in 2005). Information on 8.00.818 can be obtained from Cumulative Security Patch for SQL Server.
A list of all patches that precede SQL Server 2000 SP4 can be found here.
Clustering uses multiple groups or partitions where you place your applications or, more correctly, cluster resources. When a cluster is first created it has at least one group which contains the cluster IP address, the cluster Network Name, and the Quorum disk (more on disks later).
When building a SQL Server failover cluster, at least three groups are required. The cluster group, a Microsoft Distributed Transaction Coordinator (DTC) group, and a SQL Server 2000 instance group. Each SQL Server 2000 clustered instance requires its own group.
Groups should be named in a logical manner that is easy to understand. One method is to use a combination of the server name and the group function (see Figure 2), where [ClusterName] is the AD name of the cluster (like "MyCluster").
Figure 2 Naming Groups
[ClusterName]DTC = Group that hosts the MSDTC resources
[ClusterName]SQL1 = Group that hosts first SQL Instance
[ClusterName]SQL2 = Group that hosts second SQL Instance
...
[ClusterName]SQLn = Group that hosts the nth SQL Instance
In a large organization with 50 or more SQL Server failover clusters, it is important to name the clusters according to an enterprise-wide naming standard. Without such a naming standard, the organization's DBAs could get confused very quickly. Each group can be moved or failed over to another physical cluster node independently of any other group.
Microsoft DTC
The DTC requires some special considerations on a cluster. To enable external applications to participate in distributed transactions, you must enable Network DTC Access, a Control Panel setting in Windows Server 2003 under Add/Remove Windows Components (see How to enable network DTC access in Windows Server 2003).
Once you've enabled DTC access, you can install the DTC, as explained at How to configure Microsoft Distributed Transaction Coordinator on a Windows Server 2003 cluster. Be aware, though, that there is an undocumented bug in msdtcprox.dll. If the DTC resource is offline when a SQL Server 2000 instance on the same cluster is also offline, and the SQL Server 2000 instance comes back online before the DTC resource does, then distributed transactions will fail (see Availability of Windows Server 2003 COM+ 1.5 Rollup Package 1, specifically the section with the header "SQL Service May Fail Because of a Nonexistent MSDTC Service"). A workaround for this is to turn the SQL Server 2000 instance off and then back on, but this is not ideal in a high-availability environment. There is a fix provided in Windows Server 2003 SP1, and the patched DLL should also be available from Microsoft Customer Support Services (CSS).
The CSS group (Support Options from Microsoft Services) has escalation paths that go directly to the Windows Server 2003 platform and SQL Server development teams. If you want to implement SQL Server 2000 failover clusters in your organization, CSS will prove to be a valuable resource.
Utilizing Your Resources
When bulk copying data, it is often useful to have clustered file shares associated with a SQL Server 2000 instance. The file share permissions should be set to include at least the SQL Server 2000 service account, the Cluster Service account and your DBA group (all with Full Access). I'd recommend removing the default read-only access for the Everyone group. Don't forget to set the directory-level permissions. Before bringing the newly created file share online, select the Advanced tab from the Clustered File Share resource property page and uncheck "Affect the group". Unless there is a specific reason to do so, you don't want a file share failure to cause the SQL Server 2000 instance in the group to fail over to another node (and worse still, attempt to fail over to yet another node when the file share fails to come online on the next node).
Many organizations require guaranteed message delivery between applications. This often involves sending data stored in SQL Server 2000 to either another SQL Server 2000 instance (local or remote) or to another application. This message delivery functionality will be available inside SQL Server 2005 as a subset of the SQL Server Service Broker feature. Most organizations currently use Microsoft Message Queue (MSMQ) to similar effect. Windows Server 2003 comes with MSMQ 3.0, which provides vast improvements in ease of installation and stability over previous versions (especially when coupled with a Windows Server 2003 Active Directory® in native mode). Place each MSMQ installation in its own cluster group so that it may fail over independently from other applications like SQL Server 2000 instances.
MSMQ may consume large blocks of physical RAM. If the process that writes to the queue is considerably faster than the process that reads from the queue memory for MSMQ, the queue can ramp up to between 1.6 and 1.8GB. Ideally, MSMQ should be run on a node separate from that of SQL Server 2000.
For the sake of security, scalability, and stability I would not recommend using other cluster resources like Domain Host Configuration Protocol (DHCP), Print Spooler, Windows Internet Name Service (WINS), or generic applications on the SQL Server failover clusters.
Employing Security
You can't take chances with poor security in the enterprise space, so you have to make sure your permissions settings are correct. To ensure security, both the Cluster service domain account and the SQL Server service domain account should be standard user accounts in Active Directory, set to "User Cannot Change Password" and "Password Never Expires". The Cluster Service domain account will need to be a member of the administrators group on each cluster node. The SQL Server service domain account will be granted the following local policy user rights assignments on the cluster nodes (there is no need to add these rights to a group policy):
- Act as part of the operation system
- Allow log on locally
- Bypass traverse checking
- Lock pages in memory
- Log on as a batch job
- Log on as a service
- Replace a process-level token
The SQL Server service account needs to have "Account is Trusted for Delegation" selected and "Account is sensitive and cannot be delegated" unselected if Kerberos Authentication is enabled on the SQL Network Name [Virtual Name] resource. If Kerberos is used, two Service Principal Names (SPN) will need to be created. First set the SQL Server 2000 instance to a predetermined TCP/IP port number using the Server Network Utility. Then create two SPNs per instance:
setspn -A MSSQLSvc/<FQDN> <DOMAIN>\<SQLAcct>
setspn -A MSSQLSvc/<FQDN>:<PORT> <DOMAIN>\<SQLAcct>
Here, FQDN is the fully qualified domain name of the SQL Server 2000 Instance Network Name; PORT is the numeric TCP/IP port number set with the Server Network Utility; DOMAIN is the NetBIOS name of the Windows Server 2003 domain; and SQLAcct is the name of the account that the SQL Server service runs under. The following script can be used to verify that the objects in Active Directory have been updated correctly:
setspn –L <DOMAIN>\<SQLAcct>
Supported Instances
Microsoft supports up to 16 SQL Server 2000 instances on a Windows Server 2003 cluster. Most organizations will not require this many instances unless they are Internet service providers or application service providers with many clients. Although 16 is the supported number of instances, the practical limit is generally far lower. So why have more than one instance? There are many practical reasons, but here are the most common:
Security Although each database within an instance can have its own permissions, business-line owners often don't trust administrators from another business line. For instance, Finance administrators often don't trust Human Resources, and Sales administrators don't trust Marketing.
Uptime requirements You don't want Application X to go down if Application Y goes down first, as would happen with two SQL Server 2000 instances installed on a three-node cluster.
Collation configuration SQL Server 2000 supports collation configuration at the column, database, or instance level. Problems arise when two databases have different collations in the same instance and they need to use tempdb. One of the databases will have to convert the collation of data used within tempdb, and this incurs a performance penalty. By placing the database component of different applications with different collation requirements in different instances, these problems are overcome.
Instances installed with SQL Server 2000 SP3 or later sometimes have difficulties building full-text indexes. This can generally be overcome by running the following script on each node:
Regsvr32 "C:\program files\common files\system\mssearch\bin\tquery.dll"
In a high-availability environment, the N+1 rule is often applied, where for N active instances there is one node for each instance and one additional node to fail over to (see SQL Server 2000 Failover Clustering). The optimum price/performance ratio is achieved with three SQL Server 2000 instances on a four-node cluster (with three active nodes and one standby). Of course this must be weighed against the possibility of two instances failing over to the spare node at the same time. Instead, you might consider an N+I configuration, where for N active instances there are I inactive nodes to which they can fail over.
Sharing Disks
Clusters require shared-disk resources. All nodes must be able to get exclusive access to the disks that it has been tasked to manage (one at a time). The current owner of a cluster group that contains disk resources will attempt to secure an exclusive lock on the disks. If it fails, the disk resources within the particular cluster group will not come online and the application that depends on them (SQL Server 2000, in this case) will also fail to come online.
The shared disks must be either SCSI or fiber attached. Most large organizations use one or more Storage Array Networks (SAN) with fiber-attached disks, giving the flexibility of a centrally managed storage area.
On HP and EMC SANs, create partitions with a 64-sector offset. Windows uses the first 63 sectors of a track. On systems that use 64 sectors per track, this can lead to track alignment problems. Setting the partition to start on the beginning of the next track rather than on the last sector of the first track prevents single read/write operations spanning two physical disks when reading from the first or last sector of a disk.
Do not partition disks from Windows Server 2003. Each partition that is available to SQL Server 2000 should be on its own volume or logical unit number (LUN), which may be striped across multiple disks at the storage layer. Separate disk arrays or groups should be used for data, log, and backup partitions. Although it is tempting to mix data, log, and/or backup volumes on the same striped physical disks, this is a recipe for poor I/O performance.
All SQL Server 2000 failover clusters should have a minimum of five shared volumes. A simple formula to compute the number of shared volumes is this:
((Data + Logs + Backup) * (# of SQL SERVER 2000 Instances)) + Quorum Drive + MSDTC
Due to the lack of support for mount points (mounted volumes) in SQL Server 2000 failover clusters, the practical limit for the number of SQL Server 2000 instances in one cluster is seven. Using the formula I just explained, you get:
((1+1+1)*7) + 1 + 1 + local C drive + CDROM = 25 disks
Data, log, and backup partitions should be formatted with 64KB per cluster. SQL Server 2000 allocates data in 64KB extents (8?8KB pages) and typically performs its I/O in 8KB or 64KB chunks. If the disk controllers can be configured in this area, consider changing them to read/write in 64KB blocks. Consult your SAN vendor and don't forget to test repeatedly with production-size workloads. As SQL Server 2000 stores data in 8KB pages, certain workloads may perform better using an 8KB cluster size. The key here is that there are no magic one-size-fits-all answers. If an organization isn't willing to invest in performance tuning at the infrastructure level, use 64KB cluster sizes.
As a general rule, separating indexes onto separate disks from data on a SAN doesn't provide the I/O gains that it did on direct attached storage (DAS). Depending upon the nature of the workload, there may still be gains in splitting tempdb from the data partitions provided that it resides on different physical disks.
All volumes should be RAID 1+0. RAID 5 should only be used when under extreme duress from the finance department as performance will suffer (please ignore the protests of the SAN vendor on this point). If the virtualizing disk volumes at the storage layer and the data and/or backup disk pools are RAID 5, don't mix virtual RAID 5 volumes with virtual RAID 1+0 volumes within the same pool.
Allocating Memory
Configuring the Heartbeat NIC
- Rename the Network Connections "Cluster Network Connection 1" and "Cluster Network Connection 2," or "Heartbeat 1" and "Heartbeat 2," or something similar.
- Set the NIC to 100 Mbps Half Duplex.
- Remove the Client for Microsoft Networks File and Print Share service.
- Clear the "Register this connection's address in DNS" setting.
- Disable NetBIOS over TCP/IP in WINS.
- Set the IP address to 192.168.0.x where x is the node number (for example, 1, 2, 3, or 4) for the first heartbeat network. Set the subnet mask to 255.255.255.0.
- Set the IP address to 192.168.1.x for the second heartbeat network. Set the subnet mask to 255.255.255.0.
Note: Select a different IP address range from that used by the public network so as not to get confused. For instance, if the organization is already using a 192.168.x.x range for the public network, use the 172.16.x.x range for the heartbeat NIC.
SQL Server 2000 Enterprise Edition on Windows Server 2003 Enterprise Edition 32-bit can address up to 32GB RAM (when using Address Windowing Extensions, or AWE). If the hardware supports it, Windows Server 2003 supports Hot-Add memory for those who absolutely need to be online all the time. However, you will need to wait for SQL Server 2005 for dynamic AWE support (in SQL Server 2000 the amount of AWE memory allocated to an instance is fixed at instance startup time, whereas SQL Server 2005 will allow changing AWE memory allocation without a service restart). If running an N+1 cluster, memory can be more generously allocated to each instance. If a single node failure would cause multiple instances to run on each node, more consideration must be given to how the dependencies in each of these scenarios will be played out. Sometimes a mixture of AWE-enabled and dynamic memory allocation is the best solution when there are instances that are more memory-critical than others. Sometimes an organization will say Instance X absolutely cannot suffer performance degradation after a hardware failure but we really don't care about Instance Y as long as it's up and the application still functions (albeit at lower performance levels). Note that AWE-enabled instances behave differently in different scenarios during a failover. If the AWE memory is already allocated to another instance on the node, there will be no AWE memory to allocate to the newly failed over instance, resulting in lower performance than expected. Don't over-allocate AWE memory if multiple instances may end up on the same node, and don't forget to test scenarios both when the cluster is under load and when it is idle. When it's under load, Windows Server 2003 will likely consume more memory than when idle.
Node Recovery
Disaster recovery is outside the scope of this article, but it should be mentioned that it is possible to remove a node from a cluster, rebuild it, and install SQL Server 2000 (including Service Pack 3A) on the rebuilt node without causing further outages. However, in order to hotfix a SQL Server 2000 instance, an outage is required on all nodes in the cluster.
Conclusion
SQL Server is a mature relational database management system that is used in a variety of organizations from single-office environments to the largest of corporations. It is gaining momentum in the enterprise space due to its out-of-the-box rich functionality, ease of use, performance, and cost-effectiveness. When you deploy your SQL Server installations in a cluster, as I've explained here, you can achieve the high availability your organization needs to meet your customers' expectations.
Stephen Strong as a SQL Server Architect in Canberra, Australia, working as a contractor to Microsoft at a large client site. He has been working with SQL Server since version 4.21a. You can contact him at stephen@scsm.com.au.
© 2008 Microsoft Corporation and CMP Media, LLC. All rights reserved; reproduction in part or in whole without permission is prohibited.