Internetinformationsdienste
Skalieren von ASP.NET-Anwendungen: Gewonnene Erfahrungen
Richard Campbell
Auf einen Blick:
- Die Bedeutung der Entwickler-/IT-Zusammenarbeit
- Verständnis der wichtigsten Skalierungsstrategien
- Weitergabe von Kenntnissen über Teams hinweg
- Einigung auf einen Kernsatz an Kenntnissen
Inhalt
Grundlagen der Skalierung
Gedanken- und Erfahrungsaustausch
Was Netzwerkmitarbeiter von den Entwicklern wissen müssen
Was Entwickler von Netzwerkmitarbeitern wissen müssen
Rückkehr zum Skalieren
Kooperative Problemlösung
In meiner Rolle als Berater war jede erfolgreich skalierende ASP.NET-Anwendung, mit der ich je gearbeitet habe, das Ergebnis einer gemeinsamen Initiative zwischen Entwicklern (die sie erstellt haben) und Netzwerkmitarbeitern (die sie ausführen). Leider ist es nicht immer zu Beginn des Lebenszyklus einer Anwendung
absehbar, dass diese Zusammenarbeit notwendig ist. Daher habe ich fast nie Gelegenheit, zu Beginn des Lebenszyklus einer Anwendung involviert zu sein, sondern nur am bitteren Ende, wenn es Schwierigkeiten gibt.
Die schlichte Wahrheit ist, dass keine Anwendung direkt beim ersten Mal effizient skaliert – es ist unmöglich, alles direkt am Anfang fehlerlos hinzubekommen. Um eine Anwendung erfolgreich zu skalieren, müssen Sie verstehen, wie die Anwendung erstellt wurde und wie die Betriebsumgebung, unter der sie ausgeführt wird, funktioniert. Anders gesagt: Sie benötigen Informationen sowohl von den Entwicklern als auch den Netzwerkmitarbeitern. Ohne dieses geteilte Wissen kann es keinen Erfolg geben.
Grundlagen der Skalierung
Bevor wir uns näher mit der Materie auseinandersetzen, sehen wir uns einmal an, was genau die Skalierung einer ASP.NET-Anwendung beinhaltet. Es gibt hierfür zwei grundlegende Strategien, die in der Regel eingesetzt werden, und die meisten großen, skalierenden ASP.NET-Anwendungen wenden beide Strategien an. Außerdem lassen sich alle Regeln der Kunst, die Ihrer ASP.NET-Anwendung beim Skalieren behilflich sind, auf eine der beiden Strategien zurückführen.
Die Spezialisierung erfordert eine Trennung von Elementen der Anwendung, sodass sie unabhängig voneinander skaliert werden können. So können Sie beispielsweise dedizierte Abbildserver erstellen, statt dieselben Server zu verwenden, die die ASP.NET-Seiten rendern. Die optimale Konfiguration eines Abbildservers unterscheidet sich erheblich von einem ASP.NET-Server. Die Trennung Ihrer Abbildanforderungen vom Rest der Anwendung eröffnet die Möglichkeit, Ressourcen von Drittanbietern für das Abbildangebot zu verwenden. Der gleiche Ansatz kann für andere Ressourcendateien Anwendung finden.
Andererseits beinhaltet eine Verteilung die symmetrische Verbreitung der Anwendung über mehrere Server hinweg, was auch als Webfarm bezeichnet wird. ASP.NET-Anwendungen sind besonders für eine Verteilung geeignet, da jede einzelne Seitenanforderung relativ klein ist und die Interaktionen eines bestimmten Benutzers zum größten Teil unabhängig von anderen Benutzern sind. Die Verteilung ist in Wirklichkeit die Manifestation der Skalierungsphilosophie, in der mehrere Server mit mittlerer Leistung zusammenarbeiten, im Unterschied zum Skalierungsansatz, bei dem ein riesiger Server allein für alle Aufgaben verantwortlich ist.
Die Kombination von Spezialisierung und Verteilung erhöht die Effizienz – Sie müssen nur die Elemente der Anwendung verteilen, die eine zusätzliche Leistung erfordern. Wenn Sie beispielsweise spezialisierte Abbildserver erstellt haben, das Abbildangebot aber nach wie vor unzureichend ist, können Sie Abbildserver hinzufügen, statt Server für die gesamte Anwendung hinzuzufügen. Es ist wichtig, diese Strategien für eine Verbesserung der Leistung und Skalierbarkeit Ihrer ASP.NET-Anwendung zu bedenken.
Gedanken- und Erfahrungsaustausch
Während des Lebenszyklus jeder ASP.NET-Anwendung gibt es irgendwann einen Zeitpunkt, zu dem sich die Entwickler und die Netzwerk-/IT-Mitarbeiter treffen. Mit etwas Glück ist dies der Fall, bevor die Anwendung bereitgestellt wird, manchmal passiert dies aber erst, wenn ein Problem auftritt – beispielsweise, wenn die Anwendung in der Testumgebung einwandfrei funktioniert, daraufhin an die Benutzer gesendet wird und dort nur noch im Schneckentempo arbeitet. (Dies ist der Punkt, an dem Berater wie ich zu Rat gezogen werden.)
Wenn Entwickler und Netzwerkmitarbeiter aufeinander treffen, besteht das primäre Ziel darin, Informationen auszutauschen. Die Entwickler verfügen über wichtige Kenntnisse der Anwendung, so wie die Netzwerkmitarbeiter sich mit der Betriebsumgebung bestens auskennen. Jede Gruppe muss die Daten der anderen Gruppe verstehen, und je früher sie sich im Lebenszyklus der Anwendung treffen, desto besser.
Dieses Treffen sollte nicht erstmals bei einer Krise stattfinden. Ohne ein grundlegendes gegenseitiges Verständnis der beiden Teams ist es sehr schwer herauszufinden, weshalb die Anwendung nicht gemäß den Anforderungen funktioniert. Außerdem wäre es sehr einfach, sich zu rechtfertigen und die Schuld allein dem anderen Team zuzuweisen. Denn das entspricht einfach nie der Wahrheit – es sind immer beide Parteien für das Lösen eines sehr komplexen Problems erforderlich.
Selbst in guten Zeiten kann ein solches Treffen jedoch eine große Herausforderung sein. Jene, die ich organisiert habe, beginnen normalerweise mit den Netzwerkmitarbeitern auf der einen Seite und den Entwicklern auf der anderen. Daraufhin beäugt man sich zunächst gegenseitig skeptisch. Um eine Unterhaltung in Gang zu bringen, skizziere ich das Ziel des Treffens, insbesondere den Austausch von Wissen. Dabei ist es egal, wer damit anfängt. Ich beginne damit, was die Netzwerkmitarbeiter von den Entwicklern wissen müssen.
Was Netzwerkmitarbeiter von den Entwicklern wissen müssen
Jede ASP.NET-Anwendung hat ihre speziellen Eigenarten, aber es gibt ein paar wichtige Elemente, die in jedem Fall Anwendung finden. Die web.config-Datei ist eines dieser Elemente (siehe Abbildung 1). Web.config ist eine Schnittstelle zwischen Entwicklung und Netzwerk. Manchmal wird sie von den Entwicklern konfiguriert, manchmal von den Netzwerkmitarbeitern. In jedem Fall aber schränkt der Inhalt von web.config die Hardware- und Netzwerkkonfiguration ein und wirkt sich direkt auf den Betrieb der Anwendung aus. Die detaillierte Untersuchung jedes kleinen Aspekts der web.config-Datei würde schnell ein ganzes Buch füllen. Worauf es hier ankommt, ist, dass beide Gruppen sich mit der web.config-Datei befassen und sich darin einig sein müssen, was die von ihr dargestellte Konfiguration bedeutet und welchen Einfluss die verschiedenen Einstellungen auf die Anwendung und die Umgebung haben werden.
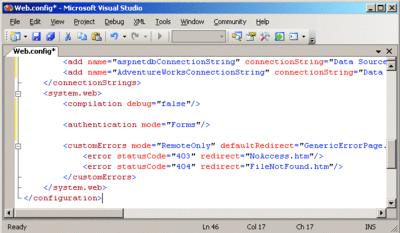
Abbildung 1 Einfache web.config-Datei mit einigen Anwendungseinstellungen und benutzerdefinierter Fehlerkonfiguration (zum Vergrößern auf das Bild klicken)
Der Abschnitt <authorization> der web.config-Datei legt beispielsweise fest, wie Benutzer in der Anwendung authentifiziert werden, und definiert damit eine Abhängigkeit. Wenn die Anwendung Windows®-Authentifizierung verwendet, hängt sie möglicherweise von Active Directory® ab. Wenn sie formularbasierte Authentifizierung verwendet, basiert die Abhängigkeit auf einem Datenspeicher mit Benutzerkonten. Das ist sicherlich eine Unterhaltung wert.
Der Abschnitt <customErrors> sollte erwähnt werden, da er sich darauf auswirkt, wie Fehler angezeigt werden. Dies ist keine komplizierte Einstellung, ist aber eine Untersuchung wert, um zu verstehen, wie die Fehlerseiten aussehen werden. Bei der Zusammenarbeit gibt es zu Beginn wahrscheinlich keine benutzerdefinierten Fehlerseiten – auch dies ist eine Unterhaltung wert.
Der Abschnitt <appSettings> von web.config kann besonders wichtig sein. An dieser Stelle speichern Entwickler üblicherweise globale Werte, wie Verbindungszeichenfolgen für Datenbanken. Dies ist eine großartige Quelle für Abhängigkeiten und ein wichtiger Bestandteil für das Planen von Failover, Migration und so weiter. Da der Abschnitt <appSettings> vollständig benutzerdefiniert ist, kann er nahezu alles enthalten und erfordert möglicherweise eine umfangreiche Erläuterung, um zu verstehen, was dort vorhanden ist. Häufig werden in diesem Abschnitt Waisen zurückgelassen – Werte, die nirgendwo in der Anwendung verwendet werden.
Selbst wenn Ihre Entwickler <appSettings> nicht verwenden, erwarten die Netzwerk-/Betriebsmitarbeiter dies möglicherweise dennoch von ihnen – mit allen Datenbankverbindungszeichenfolgen ist dies eine effiziente Möglichkeit, eine einfache Failoverstrategie zu erstellen. Wenn der Datenbankserver permanent fehlschlägt, kann eine Ersetzungszeichenfolge eingefügt werden, um auf einen anderen Datenbankserver zu verweisen. Ein früher Einsatz dieser Möglichkeit während des Entwicklungszyklus kann die Zuverlässigkeit und die Wartbarkeit der Anwendung erhöhen.
Abschließend sollten Sie beachten, dass ein extrem wichtiger Wert in web.config aus der Skalierungsperspektive das Tag <sessionState> ist, das bestimmt, wo Sitzungsdaten für die Anwendung gespeichert werden. Standardmäßig werden Sitzungsdaten in „InProc“ oder im Prozessbereich der ASP.NET-Anwendung gespeichert. Wenn die Sitzungsdaten prozessintern konfiguriert werden, bedeutet dies, dass jeglicher Lastenausgleich dafür sorgen muss, dass ein bestimmter Benutzer immer zum selben Server zurückgeleitet wird, auf dem sich die Sitzungsdaten befinden. Hierbei handelt es sich um ein extrem wichtiges Gesprächsthema zwischen Entwicklern und Netzwerkmitarbeitern, da es eine direkte Auswirkung auf die Art der Skalierung und auf die Art des Failovers hat. Ein frühzeitiges Gespräch zu diesem Thema kann das Debuggen der Anwendung erheblich erleichtern.
Wenn sich die Unterhaltung dem Sitzungsstatus zuwendet, ist es einfach, zu den Lastenausgleichsanforderungen der Anwendung im Allgemeinen überzugehen. Einige Umgebungen verfügen über dedizierte Lastenausgleichshardware mit bestimmten Features – wenn die Anwendung diese Features aber nicht verarbeiten kann, werden sie von geringer Bedeutung sein. Ich habe Situationen erlebt, in denen Hardwarelastenausgleich mit einer ASP.NET-Anwendung verwendet wurde, die über prozessinterne Sitzungsdaten verfügte. Die Folge waren gelegentlich verlorene Sitzungen ohne Erklärung. Es sah ganz nach einem Fehler in der Anwendung aus, der aber keiner war – es handelte sich um einen Konfigurationsfehler.
Die Netzwerkmitarbeiter müssen von den Entwicklern klare Informationen dazu erhalten, welche konkreten Lastenausgleichsmaßnahmen für die Anwendung funktionieren werden. Hier handelt es sich um ein wechselseitiges Gespräch darüber, welche Lastenausgleichsmaßnahmen verfügbar sind und was die Anwendung tolerieren kann. Ein wesentlicher Vorteil eines frühen Gesprächs im Lebenszyklus der Anwendung ist, dass Sie im Voraus eine prozessexterne Lastenausgleichsmaßnahme ohne Affinität planen könnten.
Bis eine ASP.NET-Anwendung für die Bereitstellung bereit ist (oder sich bereits in ihrer anfänglichen Bereitstellung befindet), werden die Entwicklungsmitarbeiter ziemlich genau wissen, welche Anwendungsbereiche schnell und welche langsam sind. Vor allem werden sie die Engpässe oder potentiellen Krisenpunkte im System kennen. Wenn das Netzwerk-/Betriebsteam diese Engpässe kennt, kann es sich auf Probleme vorbereiten und diese möglicherweise sogar ganz abwenden.
Beispielsweise habe ich einmal mit einer Anwendung gearbeitet, die während der Ausfallzeit jede Nacht einen gewaltigen Datenladeprozess beinhaltete. Die Entwickler haben den Datenladeprozess erstellt und getestet und verstanden seine Funktionsweise. Sie wussten, dass dies für die Datenbank sehr anstrengend war, aber auch, dass es effektiv war und eine gute Möglichkeit zur Lösung des Problems darstellte.
Sie haben es aber versäumt, das Netzwerkteam davon unterrichten, dass dieser Prozess stattfand oder dass sie die Ausführung der Datenbanksicherungen für genau 1 Uhr morgens eingerichtet hatten. Die Datenbank blieb online, lief aber sehr viel langsamer während der Sicherungszeit, da alle Transaktionen, die an die Datenbank gesendet wurden, im Transaktionsprotokoll festgehalten wurden.
Der Konflikt wurde erst durch die Kombination aus Laden der Daten und gleichzeitiger Sicherung identifiziert, die dazu führte, dass das Datenbank-Transaktionsprotokollvolume nicht mehr über genügend Speicherplatz verfügte. Eine Verschiebung des Beginns das Ladens der Daten auf 3 Uhr morgens löste das Problem vollständig, aber erst nach mehreren Krisentagen.
Ein frühes Gespräch über diese Arten der Arbeitsauslastungselemente in Ihrer Anwendung kann Ihnen eine Unmenge an Ärger zu einem späteren Zeitpunkt ersparen.
Was Entwickler von Netzwerkmitarbeitern wissen müssen
Mein bevorzugter Ausgangspunkt für den Teil des Treffens, bei dem die Netzwerkmitarbeiter den Entwicklern ihre Welt erklären, ist das Netzwerkdiagramm. Viel zu häufig sehen die Entwickler das Netzwerk wie in Abbildung 2 – d. h. kein Netzwerk, sondern lediglich Webserver, Browser und das Internet.
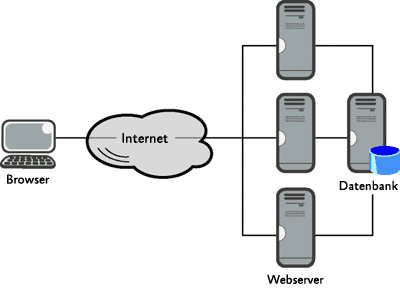
Abbildung 2 Einfaches Netzwerk aus Sicht des Entwicklers (zum Vergrößern auf das Bild klicken)
Die Realität ist selbstverständlich sehr viel komplizierter. Ein Diagramm wie Abbildung 3 entspricht schon eher der Wahrheit, auch wenn es ebenfalls vereinfacht ist. Wenn Sie Abbildung 3 betrachten, stellen sich sofort mehr Fragen, wie z. B. „wie arbeiten die Benutzer eines virtuellen privaten Netzwerks mit der Anwendung“ oder „was ist der Authentifizierungsunterschied zwischen einem internen Benutzer und einem öffentlichen Benutzer“ und so weiter.
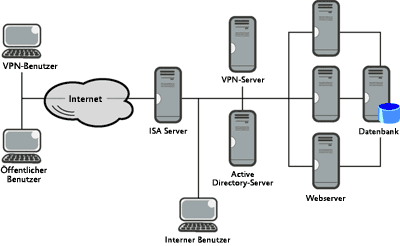
Abbildung 3 Das tatsächliche Netzwerk, das die Entwickler verstehen müssen (zum Vergrößern auf das Bild klicken)
Natürlich reicht es nicht aus, einfach ein Netzwerkdiagramm bereitzustellen. Es ist auch wichtig, das Netzwerk im Detail darzustellen, da es durch bloße Ansicht eines Diagramms sonst nicht möglich ist vorherzusehen, welche Elemente sich auf die Anwendung auswirken werden. Sie müssen den tatsächlichen Verbindungsprozess eines öffentlichen Benutzers, eines VPN-Benutzers und eines internen Benutzers erklären. Eine Diskussion der verschiedenen vorhandenen Firewallregeln, insbesondere in komplexeren Netzwerkarchitekturen im DMZ-Stil, wird selbstverständlich potenzielle Probleme der Anwendung ans Licht bringen.
Natürlich wäre es von Vorteil, diese Diskussionen zu führen, bevor die Anwendung bereitgestellt oder sogar gestartet wird, aber diese Diskussion muss in jedem Fall irgendwann stattfinden, und es ist wichtig, dass alle bei einem Treffen versammelten Personen das gesamte Netzwerkdiagramm verstehen.
Netzwerke sind auch der Schauplatz für Failover- und Redundanzmodelle, aber ohne jegliche Softwareunterstützung oder zumindest die Kenntnis des Verhaltens funktionieren diese Modelle selten wie geplant. Es muss eine detaillierte Diskussion darüber stattfinden, wie unterschiedliche Fehlschlagszenarios aussehen können. Wenn in der Datenbank Clustering eingerichtet ist, wirkt sich dies auf Code aus, der mit dem Zugriff auf die Datenbank in Zusammenhang steht. Können die Abfragen z. B. nach einem Serverwechsel den Vorgang wiederholen? Wenn eine redundante Site vorhanden ist, wie werden dann Daten auf der Site repliziert? Wie erfolgt ein Wechsel von einer Site zur anderen?
Auch hier hilft eine frühzeitige Unterhaltung, aber besser spät als nie – alle, die an der Anwendung beteiligt sind, müssen diese Prozesse verstehen. Es gibt nichts Frustrierenderes, als über eine Failoverlösung zu verfügen, die nicht funktioniert, wenn sie wirklich gebraucht wird.
Schließlich gibt es noch eine weitere wichtige Netzwerkressource, die diskutiert werden muss, und zwar Produktionsprotokolle. Ich empfehle immer, dem Entwicklungsteam Produktionsprotokolle zur Verfügung zu stellen. Die übliche Reaktion der Netzwerkmitarbeiter auf diese Anfrage ist „Fragen Sie mich danach, und ich schicke sie Ihnen“. Ich denke nicht, dass dies ausreicht. Es ist sehr viel effektiver, Entwicklern die Möglichkeit zu geben, die Protokolle selbst abzurufen, normalerweise von einer Sicherungssite.
Produktionsprotokolle sind in einer Krise unverzichtbar. Sie sind häufig die beste (und einzige) Quelle echter, empirischer Daten darüber, was tatsächlich passiert ist. Sie sind aber gleichermaßen wertvoll unter gewöhnlicheren Umständen. Wenn Entwickler generellen Zugriff auf Produktionsprotokolle haben, können sie dadurch prüfen, wie sich ein neues Feature verhält. Dies ist eine großartige Methode, um herauszufinden, dass Ihr Feature sich nicht wie erwartet verhält, und das Problem zu beheben, bevor es sich zu einer Krise entwickelt. Wenn alle Zugriff auf Protokolle haben, können Sie schneller auf Probleme reagieren und sie frühzeitiger lösen.
Rückkehr zum Skalieren
Bei einem Treffen der Netzwerkmitarbeiter und Entwickler geht es darum, die vollständige Bandbreite der Probleme zu verstehen, die beim Skalieren einer ASP.NET-Anwendung auftreten können. Die tatsächliche Umgebung, in der die Anwendung läuft, wirkt sich direkt darauf aus, wie der Code, der die Anwendung ausführt, funktioniert. Alle Strategien in Bezug auf das Skalieren wirken sich auf das Verhalten in der Umgebung aus. Das Anwenden einer Spezialisierungsstrategie wie z. B. die Herausnahme der SSL-bezogenen Bestandteile der Anwendung erfordert möglicherweise Änderungen der Netzwerkumgebung und der Server selbst.
Selbst eine offensichtlich codezentrierte Änderung wie die Verwendung von Zwischenspeicherung kann sich auf die Umgebung auswirken. Der Grund hierfür ist, dass, wenn Sie die Zwischenspeicherung von Daten Ihrer ASP.NET-Anwendung hinzufügen, Sie die Zahl der Datenbankaufrufe im Tausch gegen eine erhöhte Speicherauslastung verringern. Als Folge daraus müssen Sie möglicherweise die Zahl der ASP.NET-Server, die Sie benötigen, erhöhen, oder die Zahl der Arbeitsthread-Recyclevorgänge auf den Servern erhöhen, was Ereignisse auf der Seite der Netzwerküberwachung auslösen würde.
Das Skalieren Ihrer ASP.NET-Anwendung hat sowohl Auswirkungen auf die Entwicklung als auch auf die Netzwerkmitarbeiter – daher lohnt es sich, beide Gruppen in den Entscheidungsfindungsprozess einzubeziehen. Häufig führt die Zusammenarbeit zu originellen Lösungen, die die Teams unabhängig voneinander nicht finden würden. Zum Beispiel kennen Netzwerkmitarbeiter möglicherweise vorhandene Hardwarelösungen innerhalb des Unternehmens, die den Entwicklern helfen können, den Leistungs- und Skalierungsanforderungen gerecht zu werden. Eine Besprechung der Anwendungs- und Umgebungsdetails fördert diese Möglichkeiten zutage.
Kooperative Problemlösung
Ressourcen für das Skalieren von ASP.NET-Anwendungen
- Entwickeln von Hochleistungs-ASP.NET-Anwendungen
- Gewusst wie: Skalieren von .NET-Anwendungen
- Gewusst wie: Abstimmen und Skalieren der Leistung von auf .NET Framework basierenden Anwendungen
- Implementieren einer skalierbaren Architektur
- Maximieren der IIS-Leistung
- Skalierungsstrategien für ASP.NET-Anwendungen
Eine Krise beim Skalieren ist nicht notwendigerweise schlecht – sie ist normalerweise sogar positiv zu werten, da sie von zu vielen Benutzern verursacht wird, die Ihre Anwendung ausführen wollen, was den Wert der Anwendung unter Beweis stellt! Jetzt müssen Sie sie allerdings zum Laufen bringen.
Manchmal werden Skalierungskrisen durch ein anderes Ereignis verursacht – vielleicht führt Ihr Unternehmen gerade eine Werbeaktion durch, oder es wurde ein Blog über Sie geschrieben, oder eine Website für soziale Netzwerke hat gleichzeitig eine große Anzahl von Benutzern auf Ihre Website verwiesen. Auf einmal haben Sie alle Hände voll zu tun, die Anwendung am Laufen zu halten. Wie Sie sich denken können, ist es ratsam, dieses Szenario durchzuspielen, bevor es tatsächlich eintritt. Eine Vorführung, wie eine Zusammenarbeit einem Unternehmen bei der Bewältigung einer solchen Krise helfen kann, ist eine großartige Möglichkeit, ihr Treffen von Entwicklern und Netzwerkmitarbeitern zu beenden.
Die erste Frage zur Bewältigung der Krise lautet „Wie können wir feststellen, dass die Site unter der Last zusammenbricht?“ Die Antwort ist allzu häufig: „Wir bekommen einen Anruf vom CTO.“ Wenn das erste Zeichen dafür, dass Ihre Website in Schwierigkeiten ist, ein externer Anruf ist, haben Sie ein Problem. Eine vernünftige Messung sollte Sie über Probleme informieren, bevor das Telefon klingelt. Das wird zwar nicht das Klingeln Ihres Telefons verhindern, aber Ihnen zumindest einen Vorsprung dafür geben, Ihre Antwort zu finden. Eine ahnungslose Reaktion dem CTO gegenüber wirkt sich wahrscheinlich nicht gut auf die Karriere aus.
Nächste Frage – wer wird zuerst angerufen? Wer reagiert auf das Ereignis? Häufig erhält ein Netzwerkmitarbeiter eine erste Warnung, und diese Person ist möglicherweise relativ unerfahren. Daher muss ein klarer Eskalationsplan vorhanden sein. Wer wird als Nächstes angerufen? Die Herausforderung besteht darin, eine frühe, schnelle Diagnose zu stellen, um die Art des aktuellen Problems zu ermitteln. Wenn es ein Netzwerkausfall ist, ist das eine Sache. Wenn es aber ein Skalierungsproblem ist, ist das etwas ganz anderes. Bei Skalierungsproblem ist es ratsam, jemanden aus dem Entwicklungsteam frühzeitig zu Rate zu ziehen.
Alle an der Problemlösung Beteiligten benötigen detaillierte Informationen. Daher ist effektiver Zugriff sehr wichtig. Das Ziel besteht darin, so viele Informationen wie möglich zu verbreiten, damit eine effektive Diagnose gestellt werden kann. Dies sollte letztlich den Umfang der Lösung bestimmen.
Wenn die einzige Lösung im Schreiben von Code besteht, ist das Ereignis häufig bereits vorüber, bevor der Code geschrieben werden kann. Selbstverständlich sollte das Ereignis notiert werden, um Entwicklungsprioritäten für die Zukunft aufzustellen. Es ist aber nicht vertretbar (oder klug) zu versuchen, eine Menge Code zu schreiben und diesen ohne vorheriges gründliches Testen in Produktion zu geben. Regel Nr. 1 einer jeden Problemlösung – machen Sie die Lage nicht noch schlimmer.
Bei Skalierungsproblemen liegt die Lösung manchmal darin, einfach abzuwarten. Diese Entscheidung kann aber immer noch getroffen werden.
Gleichzeitig bedeutet die Planung für eine dieser Eventualitäten, dass verschiedene Techniken schnell angewendet werden können. Die Einbringung sowohl von Netzwerk- als auch von Entwicklungsressourcen zur Lösung eines Skalierungsproblems führt häufig erstaunlich schnell zu einem Ergebnis, vielleicht sogar so schnell, dass die Werbeaktion umso mehr zu einem Erfolg wird.
Zusammenfassend lauten die aus Netzwerksicht gewonnenen Erfahrungen, dass eine hochskalierende, leistungsstarke ASP.NET-Anwendung das Ergebnis einer erfolgreichen Zusammenarbeit der Anwendungsentwickler sowie derjenigen, die sie bereitstellen und bedienen, ist.
Die Zusammenarbeit ist unvermeidlich. Daher ist es ratsam, früh mit Treffen zwischen den Teams zum Austausch von Informationen zu beginnen. Das Ziel der Treffen ist die Entwicklung eines Verständnisses sowie die Einigung hinsichtlich aller Elemente der Anwendung, was sie leistet, wie sie funktioniert, wovon sie abhängt, wie sie unter Belastung arbeitet und wie sie mit Problemen, die mit der Zeit entstehen, fertig wird.
Wenn diese Zusammenarbeit wirklich effektiv ist, ist das Ergebnis ein flexibleres Unternehmen, das schnell auf Probleme reagieren kann und das klare Ziele hinsichtlich der Anforderungen der Anwendung festlegen kann, um in Zukunft erfolgreich zu sein.
Richard Campbell ist Microsoft Regional Director, ein MVP für ASP.NET und Mitmoderator von .NET Rocks, der Internet-Audiotalkshow für .NET-Entwickler (dotnetrocks.com). Er hat Jahre mit der Beratung von Unternehmen in Bezug auf die Leistung und Skalierung von ASP.NET verbracht und ist außerdem einer der Mitbegründer von Strangeloop Networks.
© 2008 Microsoft Corporation und CMP Media, LLC. Alle Rechte vorbehalten. Die nicht genehmigte teilweise oder vollständige Vervielfältigung ist nicht zulässig.