Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Eine genaue Datenidentifikation und -klassifizierung ist die Grundlage für eine stabile Datensicherheit. Es ermöglicht Unternehmen, Datenschutzrichtlinien für ihre digitalen Ressourcen sicher bereitzustellen. Microsoft Purview unterstützt diesen wichtigen Schritt mit typen vertraulichen Informationen (SENSITIVE INFORMATION Types, SITs) und erweiterten Klassifizierungstechnologien wie Exact Data Match (EDM),trainierbaren Klassifizierern und Dokumentenfingerabdrücken.
Um jedoch die Menge falsch positiver Ergebnisse zu steuern, müssen Sie diese Tools konfigurieren und in den richtigen Kontexten und Szenarien anwenden. Falsch positiv bedeutet, dass das System etwas fälschlicherweise als Übereinstimmung kennzeichnet, obwohl dies nicht der Fall ist. Falsch positive Ergebnisse:
- Erhöhen der Warnungsmüdigkeit: Überlastet Sicherheits- und Complianceteams und erhöht die Wahrscheinlichkeit, dass echte Risiken durchrutschen.
- Zeit und Ressourcen ausgleichen: Die Überprüfung falsch positiver Ergebnisse führt zu einer Eskalation der Betriebskosten, insbesondere für Unternehmen, die große Datenmengen verarbeiten.
- Unnötige Hindernisse schaffen: Zugriffseinschränkungen, die fälschlicherweise auf nicht sensible Inhalte angewendet werden, führen zu Reibungsverlusten in Workflows und Produktivität.
- Verringern der Benutzervertrauensstellung: Verringert die allgemeine Produktakzeptanz.
Daher ist es wichtig, ein klares Verständnis der Nützlichkeit und Relevanz von SITs und erweiterten Klassifizierern für die Vielfalt der Geschäftsszenarien in einem Unternehmen zu haben.
Informationen zu diesem Leitfaden
Dieser Leitfaden enthält die folgenden Artikel:
- Einführung (dieser Artikel)
- Schritt 1: Konfigurieren der musterbasierten Erkennung vertraulicher Daten
- Schritt 2: Implementieren einer genauen Datenabgleichung für einen präzisen Abgleich
- Schritt 3: Verwenden trainierbarer Klassifizierer für komplexe Inhalte
- Schritt 4: Anwenden des Dokumentfingerabdrucks auf Vorlagen
Bevor Sie beginnen
Dieser Leitfaden richtet sich an Administratoren mit Kenntnissen zu Microsoft Purview Data Loss Prevention (DLP) und Klassifizierungstechnologien. Wenn Sie mit diesen Lösungen noch nicht vertraut sind, lesen Sie die folgenden Artikel, um mehr zu erfahren:
- Informationen zu Typen vertraulicher Informationen
- Informationen zu Typen vertraulicher Informationen basierend auf genauer Datenübereinstimmung
- Weitere Informationen zu trainierbaren Klassifizierern
- Informationen zum Dokumentfingerabdruck
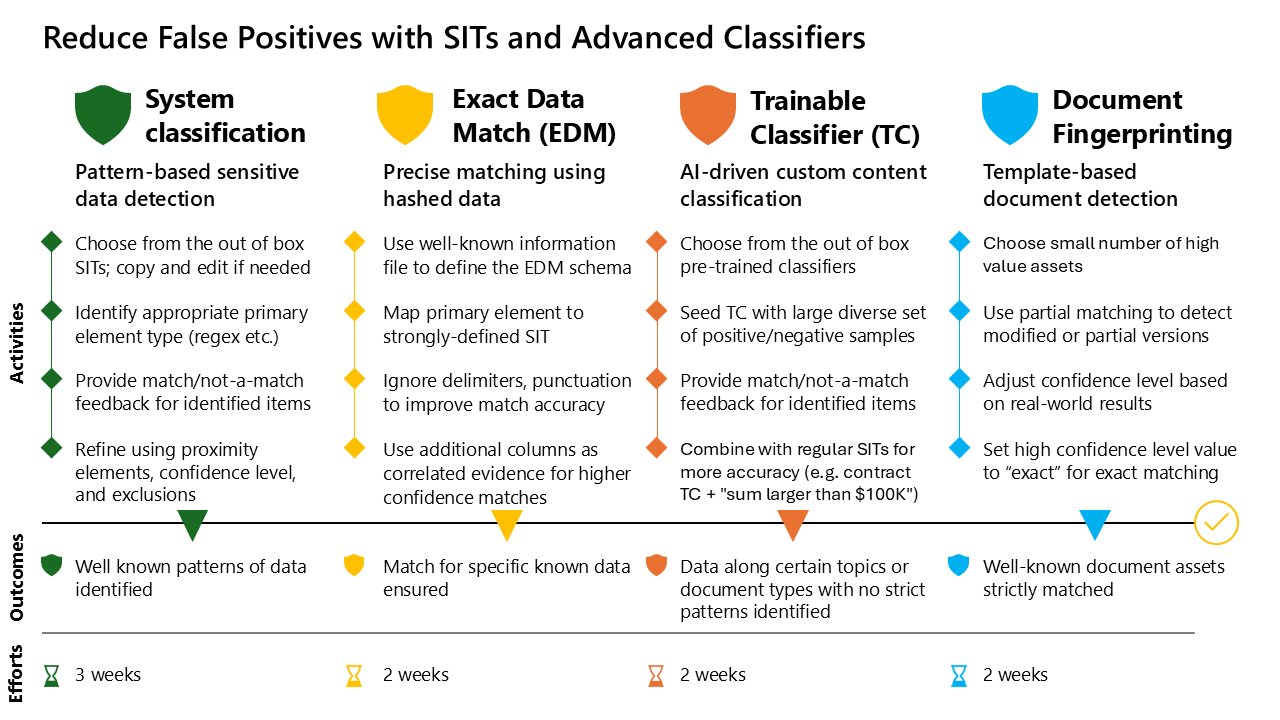
Übersicht über Klassifizierungstechnologien
| Klassifizierungstechnologie | Typischer Anwendungsfall | Warum? |
|---|---|---|
| Sitzt | Identifizierung gängiger vertraulicher Datentypen, die allgemein anerkannt sind und standardisierten Mustern folgen. Beispiel: Guthaben Karte Nummern, SSNs. | Schnelle Bereitstellung mit minimaler Konfiguration sowie integrierter Unterstützung. |
| Genaue Datenübereinstimmung | Szenarien, die einen präzisen Datenabgleich aus einer bekannten Datenquelle erfordern. Beispielsweise das Erkennen bestimmter Kundenkontonummern, Mitarbeiter-IDs oder Patienten-IDs. | Minimiert falsch positive Ergebnisse, indem nur Daten gekennzeichnet werden, die exakt mit Einträgen in der hochgeladenen Verweisdatentabelle übereinstimmen. |
| Trainierbare Klassifizierer | Identifizieren komplexer und kontextbezogener Daten, Dokumente mit unterschiedlicher Struktur und unvorhersehbarem Format, in denen herkömmliche Muster nicht angewendet werden. Beispielsweise juristische Dokumente mit unterschiedlichen Klauseln und Formaten. | Bietet einen anpassbaren und intelligenten Ansatz für komplexe Datentypen. |
| Dokumentfingerabdrücke | Anwendungsfälle, in denen Dokumentvorlagen und Formatierungen im gesamten organization konsistent sind. Beispielsweise Geschäftsverträge, Rechnungen, RFPs oder Standardformulare, die vertrauliche Daten enthalten. | Bietet gezielten Schutz für kritische, strukturierte Dokumente. |
Übersicht über die Bereitstellung
Das Bereitstellungsmodell unterbricht den Ansatz in vier Schritte, die sich jeweils auf eine andere Klassifizierungstechnologie konzentrieren:
| Schritt | Klassifizierungstechnologie | Beschreibung |
|---|---|---|
| Schritt 1: Konfigurieren der musterbasierten Erkennung vertraulicher Daten | Typen vertraulicher Informationen (SITs) | Auswählen, Anpassen und Verfeinern von SITs für eine genaue musterbasierte Erkennung. |
| Schritt 2: Implementieren einer genauen Datenabgleichung für einen präzisen Abgleich | Exact Data Match (EDM) | Verwenden Sie Hashverweisdaten, um bekannte vertrauliche Daten präzise zu identifizieren. |
| Schritt 3: Verwenden trainierbarer Klassifizierer für komplexe Inhalte | Trainierbare Klassifizierungsmerkmale | Verwenden Sie KI-gesteuerte Klassifizierer für komplexe Inhalte, die nicht den Standardmustern folgen. |
| Schritt 4: Anwenden des Dokumentfingerabdrucks auf Vorlagen | Dokumentfingerabdrücke | Erkennen bestimmter Dokumentvorlagen und Dokumente im festen Format. |
Microsoft Purview-Bereitstellungsblaupause
Szenariobasierte Datenklassifizierungsstrategien
Die folgende Tabelle enthält Bereitstellungsanleitungen mit Beispielen für die empfohlenen Datenklassifizierungstechniken für verschiedene Szenarien.
| Szenario | Bevorzugte Methode | Alternative Methoden | Techniken zur Reduzierung falsch positiver Ergebnisse |
|---|---|---|---|
| Erkennen von PII/PHI für bekannte Personen (Kunden oder Patienten) | EDM für Daten aus loB-App-Extrakt | Benutzerdefinierte SITs einschließlich Mitarbeiter-ID und gängige PII-SITs (z. B. SSN) | Wenn Sie reguläre SITs verwenden, sollten Sie das Vorhandensein aller vollständigen Namen erwägen und Regeln auf Dokumente mit einer bestimmten Mindestanzahl von Übereinstimmungen beschränken. |
| Erkennen von PII/PHI für Mitarbeiter oder Auftragnehmer | EDM für Daten aus HR-Systemextraktion | Benutzerdefinierte SITs einschließlich Mitarbeiter-ID + benannte Entitäten (z. B. alle vollständigen Namen) + allgemeine PII-SITs | Wenn Sie reguläre SITs verwenden, sollten Sie das Vorhandensein aller vollständigen Namen erwägen und Regeln auf Dokumente mit einer bestimmten Mindestanzahl von Übereinstimmungen beschränken. |
| Erkennen von Formularen mit personenbezogenen Daten | Formularfingerabdrücke + Standard-SITs oder Fingerabdruck + benutzerdefinierte SITs | Benutzerdefinierte SITs + OCR (für gescannte Formulare) | Verwenden Sie EDM anstelle von benutzerdefinierten SITs, wenn Sie keinen Fingerabdruck verwenden. |
| Verträge, rechtliche Dokumente oder andere Geschäftsformen | Benutzerdefinierte trainierbare Klassifizierer (+ OCR) | Integrierte trainierbare Klassifizierer + OCR | Identifizieren Sie Dokumente in Ihrem organization, die der integrierte TC ordnungsgemäß identifiziert, kopieren Sie sie in ein Repository, und verwenden Sie sie zum Trainieren eines benutzerdefinierten TC. |
| Wichtige Verträge oder andere Dokumente | Trainierbare Klassifizierer + Vertraulichkeitsbezeichnung | Trainierbare Klassifizierer + benutzerdefiniertes SIT (z. B. RegEx zum Erkennen von Geldbeträgen über 100.000 USD) | Kombinieren Sie mehrere TCs in einer einzigen Regel, z. B. "Verträge" und "Dokumente zu Projekt X". |
| Allgemeine PII oder PHI von unbekannten Personen | Integrierte SITs (falls verfügbar) oder benutzerdefinierte SITs | Manuelle Bezeichnung | Kopieren und bearbeiten Sie eine vorhandene SIT, um die Schlüsselwort (keyword) Anforderungen zu optimieren. Fügen Sie Anforderungen für benannte Entitäten hinzu, z. B. Alle vollständigen Namen. |
| Gescannte Identitätskarten (oder ähnliches) | Integrierte oder benutzerdefinierte SITs + OCR | Benutzerdefiniertes SIT mit Schlüsselwort (keyword) Listen + OCR | Fügen Sie Anforderungen für benannte Entitäten (Namen oder Adressen) hinzu, wenn erwartet wird, dass sie in einer Zeile geschrieben werden. |
| Projektdaten | Standortbasierte Bezeichnung (z. B. Standardbezeichnung für Bibliothek) | Manuelle Bezeichnung oder benutzerdefinierte trainierbare Klassifizierer | Sobald die standortbasierte Bezeichnung genügend relevante Dokumente identifiziert hat, verwenden Sie diese zum Trainieren eines benutzerdefinierten TC. |
Optimieren der DLP-Richtlinienkonfiguration
Wenn Sie Klassifizierer in Ihren DLP-Richtlinien (Data Loss Prevention) verwenden, passen Sie die anzahl der instance an, um falsch positive Ergebnisse zu reduzieren. Halten Sie den Mindestschwellenwert für instance Anzahl bei einem höheren Wert, wenn kleine oder triviale Vorkommen vertraulicher Daten keine Aktion erfordern. Wenn Ihr Geschäftskontext jedoch eine verschärfte Datensicherheit erfordert, verwenden Sie eine niedrigere instance Anzahl, um auch nur ein einzelnes Vorkommen zu blockieren. Passen Sie die instance anzahl an die Vertraulichkeitsstufe der Daten an.
Content Explorer ist Ihr zentraler Hub für die Ermittlung vertraulicher Inhalte in Ihrem gesamten Datenbestand. Sie bietet umfassende Einblicke in die Typen und Speicherorte vertraulicher Daten. Indem Sie instance Schwellenwerte optimieren und die geeigneten Konfidenzstufen für die Erkennung festlegen, können Sie sicherstellen, dass Warnungen nur ausgelöst werden, wenn der Kontext dem Risikostatus Ihrer Organisation entspricht.