Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Data Science | Kundensicherheit und -vertrauen |
| Microsoft | Microsoft |
Abstract – Die Identifizierung von Sicherheitsfehlerberichten (SBRs) ist ein wichtiger Schritt im Lebenszyklus der Softwareentwicklung. Bei überwachten maschinellen Lernansätzen wird üblicherweise davon ausgegangen, dass ganze Fehlerberichte für Schulungen verfügbar sind und dass ihre Bezeichnungen geräuschfrei sind. Nach unserem besten Wissen ist dies die erste Studie, die zeigt, dass genaue Labelvorhersagen für SBRs möglich sind, selbst wenn nur der Titel verfügbar ist und bei Vorhandensein von Labelrauschen.
Indexbegriffe — Machine Learning, Falschbezeichnung, Rauschen, Sicherheitsfehlerbericht, Fehlerrepositorys
Ich. EINLEITUNG
Das Identifizieren von sicherheitsbezogenen Problemen zwischen gemeldeten Fehlern ist ein dringender Bedarf an Softwareentwicklungsteams, z. B. Probleme, die beschleunigte Korrekturen erfordern, um Complianceanforderungen zu erfüllen und die Integrität der Software- und Kundendaten sicherzustellen.
Maschinelles Lernen und Künstliche Intelligenz Tools versprechen, die Softwareentwicklung schneller, agil und korrekt zu machen. Mehrere Forscher haben maschinelles Lernen auf das Problem der Identifizierung von Sicherheitsfehlern angewendet [2], [7], [8], [18]. In früheren veröffentlichten Studien wurde davon ausgegangen, dass der gesamte Fehlerbericht zur Schulung und Bewertung eines Machine Learning-Modells verfügbar ist. Dies ist nicht unbedingt der Fall. Es gibt Situationen, in denen der gesamte Fehlerbericht nicht verfügbar gemacht werden kann. Beispielsweise kann der Fehlerbericht Kennwörter, personenbezogene Informationen (PII) oder andere Arten vertraulicher Daten enthalten – ein Fall, mit dem wir derzeit bei Microsoft konfrontiert sind. Daher ist es wichtig zu ermitteln, wie gut die Identifizierung von Sicherheitsfehlern mit weniger Informationen durchgeführt werden kann, z. B. wenn nur der Titel des Fehlerberichts verfügbar ist.
Darüber hinaus enthalten Bugrepositorys häufig falsch bezeichnete Einträge [7]: Nicht sicherheitsrelevante Fehlerberichte, die als sicherheitsbezogene und umgekehrt klassifiziert wurden. Es gibt mehrere Gründe für das Auftreten von Fehlbezeichnungen, von der mangelnden Expertise des Entwicklungsteams in der Sicherheit bis hin zur Fuzzlichkeit bestimmter Probleme, z. B. ist es möglich, dass nicht sicherheitsrelevante Fehler auf indirekte Weise ausgenutzt werden, um eine Sicherheitsimpluzierung zu verursachen. Dies ist ein ernstes Problem, da die Fehlbezeichnung von SBRs dazu führt, dass Sicherheitsexperten die Fehlerdatenbank manuell in einem kostspieligen und zeitaufwendigen Aufwand überprüfen müssen. Das Verständnis, wie sich Störungen auf verschiedene Klassifikatoren auswirken und wie robust (oder anfällig) unterschiedliche Verfahren des maschinellen Lernens in der Gegenwart von Datensätzen sind, die mit verschiedenen Arten von Störungen kontaminiert sind, ist ein Problem, das behoben werden muss, um die automatische Klassifizierung in die Praxis der Softwaretechnik zu integrieren.
Vorläufige Arbeiten argumentieren, dass Fehlerrepositorys intrinsisch laut sind und dass das Rauschen negative Auswirkungen auf die Leistungs-Machine Learning-Klassifizierer haben könnte [7]. Es fehlt jedoch jede systematische und quantitative Studie darüber, wie sich verschiedene Ebenen und Arten von Geräuschen auf die Leistung verschiedener überwachter Machine Learning-Algorithmen für das Problem der Identifizierung von Sicherheitsfehlerberichten (SRBs) auswirken.
In dieser Studie zeigen wir, dass die Klassifizierung von Fehlerberichten auch dann durchgeführt werden kann, wenn nur der Titel für Schulungen und Bewertungen verfügbar ist. Meines Wissens nach ist dies die erste Arbeit, die dies tut. Darüber hinaus liefern wir die erste systematische Studie über die Wirkung von Lärm in der Fehlerberichtsklassifizierung. Wir machen eine vergleichende Studie zur Robustheit von drei maschinellen Lerntechniken (logistikbasierte Regression, naïve Bayes und AdaBoost) gegen klassenunabhängiges Rauschen.
Während es einige analytische Modelle gibt, die den allgemeinen Einfluss von Rauschen für einige einfache Klassifizierer [5], [6] erfassen, bieten diese Ergebnisse keine engen Grenzen für die Wirkung des Rauschens auf Genauigkeit und sind nur für eine bestimmte maschinelle Lerntechnik gültig. Eine genaue Analyse des Effekts von Rauschen in Machine Learning-Modellen wird in der Regel durch die Ausführung von Rechenexperimenten durchgeführt. Solche Analysen wurden für mehrere Szenarien durchgeführt, die von Softwaremessdaten [4], bis hin zur Satellitenbildklassifizierung [13] und medizinischen Daten [12] reichen. Diese Ergebnisse können jedoch nicht in unser spezifisches Problem übersetzt werden, da sie aufgrund ihrer hohen Abhängigkeit von der Art der Datensätze und dem zugrunde liegenden Klassifikationsproblem stark abhängig sind. Nach unserem besten Wissen gibt es keine veröffentlichten Ergebnisse zu dem spezifischen Problem der Auswirkungen von rauschenden Datensätzen auf die Klassifizierung von Sicherheitsfehlerberichten.
UNSERE FORSCHUNGSBEITRÄGE:
Wir schulen Klassifizierer zur Identifizierung von Sicherheitsfehlerberichten (SBRs), die ausschließlich auf dem Titel der Berichte basieren. Nach unserem besten Wissen ist dies die erste Arbeit, die dies tut. In früheren Arbeiten wurde entweder der vollständige Fehlerbericht verwendet oder der Fehlerbericht mit zusätzlichen ergänzenden Features verbessert. Die Klassifizierung von Fehlern, die ausschließlich auf der Kachel basieren, ist besonders relevant, wenn die vollständigen Fehlerberichte aufgrund von Datenschutzbedenken nicht verfügbar gemacht werden können. Beispielsweise ist es berüchtigt, dass Fehlerberichte Kennwörter und andere vertrauliche Daten enthalten.
Wir bieten auch die erste systematische Untersuchung der Bezeichnungslärmtoleranz verschiedener Machine Learning Modelle und Techniken, die für die automatische Klassifizierung von SBRs verwendet werden. Wir machen eine vergleichende Studie der Robustität von drei unterschiedlichen maschinellen Lerntechniken (Logistik regression, naïve Bayes und AdaBoost) gegen klassenabhängige und klassenunabhängige Geräusche.
Der Rest des Papiers wird wie folgt dargestellt: In Abschnitt II stellen wir einige der bisherigen Werke in der Literatur vor. In Abschnitt III beschreiben wir die Datengruppe und wie Daten vorverarbeitet werden. Die Methodik wird in Abschnitt IV und die Ergebnisse unserer Experimente beschrieben, die in Abschnitt V analysiert wurden. Schließlich werden unsere Schlussfolgerungen und zukünftigen Arbeiten in VI vorgestellt.
II. VORHERIGE ARBEITEN
AUF MASCHINELLEM LERNEN BASIERENDE ANWENDUNGEN FÜR FEHLERREPOSITORYS
Es gibt eine umfangreiche Literatur zur Anwendung von Text Mining, natürlicher Sprachverarbeitung und maschinellem Lernen auf Fehlerrepositorys, um mühsame Aufgaben wie die Sicherheitsfehlererkennung [2], [7], [8], [18], Fehlerduplikatidentifizierung [3], Fehlertriage [1], [11] zu automatisieren, um einige Anwendungen zu nennen. Im Idealfall reduziert die Ehe von Maschinellem Lernen (ML) und natürlicher Sprachverarbeitung potenziell die manuelle Arbeit, die zum Zusammenstellen von Bugdatenbanken erforderlich ist, verkürzt die erforderliche Zeit für die Durchführung dieser Aufgaben und kann die Zuverlässigkeit der Ergebnisse erhöhen.
In [7] schlagen die Autoren ein Modell für natürliche Sprachen vor, um die Klassifizierung von SBRs basierend auf der Beschreibung des Fehlers zu automatisieren. Die Autoren extrahieren ein Vokabular aus allen Fehlerbeschreibungen im Schulungsdatensatz und zusammenstellen es manuell in drei Wörterlisten: relevante Wörter, Stoppwörter (häufige Wörter, die für die Klassifizierung irrelevant erscheinen) und Synonyme. Sie vergleichen die Leistung von Sicherheitsfehlerklassifizierern, die auf Daten trainiert wurden, die alle von Sicherheitsingenieuren ausgewertet wurden, und von einem Klassifizierer, der auf Daten trainiert wurde, die von Bug-Reportern im Allgemeinen bezeichnet wurden. Obwohl das Modell deutlich effektiver ist, wenn es mit von Sicherheitsingenieuren überprüften Daten trainiert wird, basiert das vorgeschlagene Modell auf einem manuell abgeleiteten Vokabular, das es von der menschlichen Kuration abhängig macht. Darüber hinaus gibt es keine Analyse, wie sich unterschiedliche Geräuschpegel auf ihr Modell auswirken, wie verschiedene Klassifizierer auf Rauschen reagieren und ob sich Rauschen in beiden Klassen auf die Leistung unterschiedlich auswirkt.
Zou et. al [18] verwenden mehrere Arten von Informationen, die in einem Fehlerbericht enthalten sind, die die nicht-textbezogenen Felder eines Fehlerberichts (Metafeatures, z. B. Zeit, Schweregrad und Priorität) und den Textinhalt eines Fehlerberichts (Textfeatures, d. h. den Text in Zusammenfassungsfeldern) umfassen. Basierend auf diesen Features erstellen sie ein Modell, um die SBRs automatisch über natürliche Sprachverarbeitung und maschinelle Lerntechniken zu identifizieren. In [8] führen die Autoren eine ähnliche Analyse durch, vergleichen aber zusätzlich die Leistung von überwachten und nicht überwachten maschinellen Lerntechniken und untersuchen, wie viel Daten zum Trainieren ihrer Modelle benötigt werden.
In [2] untersuchen die Autoren auch verschiedene Maschinelle Lerntechniken, um Fehler basierend auf ihren Beschreibungen als SBRs oder NSBRs (Non-Security Bug Report) zu klassifizieren. Sie schlagen eine Pipeline für die Datenverarbeitung und Modellschulung basierend auf TFIDF vor. Des Weiteren vergleichen sie die vorgeschlagene Pipeline mit einem Bag-of-Words-Modell, das den Naive-Bayes-Klassifizierer verwendet. Wijayasekara et al. [16] verwendete auch Textminingtechniken, um den Featurevektor jedes Fehlerberichts basierend auf häufigen Wörtern zu generieren, um versteckte Auswirkungsfehler (HIBs) zu identifizieren. Yang et al. (2016) [17] konnten laut eigener Aussage Fehlerberichte mit großen Auswirkungen (z. B. sicherheitsrelevante Fehlerberichte) mithilfe der Vorkommenshäufigkeit (Term Frequency, TF) und dem Naive-Bayes-Klassifizierer erkennen. In [9] schlagen die Autoren ein Modell vor, um den Schweregrad eines Fehlers vorherzusagen.
LABELRAUSCHEN
Das Problem des Umgangs mit Datensätzen mit Bezeichnungsgeräuschen wurde umfassend untersucht. Frénay und Verleysen (2014) [6] schlagen eine Taxonomie für Labelrauschen vor, um unterschiedliche Typen von verrauschten Labels zu unterscheiden. Die Autoren schlagen drei verschiedene Arten von Rauschen vor: Bezeichnungsgeräusche, die unabhängig von der tatsächlichen Klasse und den Werten der Instanzfeatures auftreten; Beschriftungsgeräusche, die nur vom tatsächlichen Etikett abhängen; und Beschriftungsgeräusche, bei denen die Falschbezeichnungswahrscheinlichkeit auch von den Featurewerten abhängt. In unserer Arbeit untersuchen wir die ersten beiden Arten von Lärm. Aus theoretischer Sicht verringert Bezeichnungsgeräusche in der Regel die Leistung eines Modells [10], außer in bestimmten Fällen [14]. Robuste Methoden verarbeiten Labelrauschen im Allgemeinen, indem Übereinpassung vermieden wird [15]. Die Untersuchung von Rauscheffekten in der Klassifizierung wurde zuvor in vielen Bereichen wie der Satellitenbildklassifizierung [13], der Softwarequalitätsklassifizierung [4] und der medizinischen Domänenklassifizierung [12] durchgeführt. Zum Besten unseres Wissens gibt es keine veröffentlichten Werke, die die genaue Quantifizierung der Auswirkungen von lauten Bezeichnungen im Problem der SBRs-Klassifizierung untersuchen. In diesem Szenario wurde die genaue Beziehung zwischen Rauschpegeln, Rauschtypen und Leistungsbeeinträchtigungen nicht festgelegt. Darüber hinaus lohnt es sich zu verstehen, wie sich unterschiedliche Klassifizierer im Vorhandensein von Rauschen verhalten. Im Allgemeinen sind wir uns keiner Arbeit bewusst, die systematisch die Wirkung von lauten Datensätzen auf die Leistung verschiedener Machine Learning-Algorithmen im Kontext von Softwarefehlerberichten untersucht.
III. BESCHREIBUNG DES DATENSATZES
Unser Datensatz besteht aus 1.073.149 Bugtiteln, von denen 552.073 SBRs und 521.076 NSBRs entsprechen. Die Daten wurden in den Jahren 2015, 2016, 2017 und 2018 von verschiedenen Teams in Microsoft gesammelt. Die Labels wurden entweder durch signaturbasierte Fehlerüberprüfungssysteme oder durch Mitarbeiter vergeben. Fehlertitel in unserem Dataset sind sehr kurze Texte, die etwa 10 Wörter enthalten, mit einer Übersicht über das Problem.
A. Datenvorverarbeitung: Wir analysieren jeden Fehlertext anhand seiner Leerzeichen, was zu einer Liste von Tokens führt. Wir verarbeiten jede Liste von Token wie folgt:
Entfernen aller Token, die Dateipfade sind
Geteilte Token, bei denen die folgenden Symbole vorhanden sind: { , (, ), -, }, {, [, ], }
Entfernen Sie Stoppwörter , Token, die nur von numerischen Zeichen und Token bestehen, die weniger als 5 Mal im gesamten Korpus angezeigt werden.
IV. METHODOLOGIE
Der Prozess der Schulung unserer Machine Learning-Modelle besteht aus zwei Hauptschritten: Codieren der Daten in Featurevektoren und Schulung überwachter Machine Learning-Klassifizierer.
A. Featurevektoren und Maschinelle Lerntechniken
Zunächst werden Daten wie bei Behl et al. (2014) [2] mithilfe des Tf-idf-Algorithmus in Featurevektoren codiert. Tf-idf ist eine Methode aus dem Information-Retrieval-Bereich, bei der die Vorkommenshäufigkeit (Term Frequency, TF) und deren inverse Dokumenthäufigkeit (Inverse Document Frequency, IDF) gewichtet werden. Jedes Wort oder jeder Ausdruck hat seine jeweilige TF- und IDF-Bewertung. Der Algorithmus TF-IDF weist diesem Wort basierend auf der Anzahl der Vorkommen im Dokument die Wichtigkeit zu und überprüft, wie relevant das Schlüsselwort in der Gesamtheit der Titel im Datensatz ist. Wir haben drei Klassifikationstechniken trainiert und verglichen: naïve Bayes (NB), verstärkte Entscheidungsbäume (AdaBoost) und logistische Regression (LR). Wir haben diese Techniken ausgewählt, da sie für die damit verbundene Aufgabe der Identifizierung von Sicherheitsfehlerberichten auf der Grundlage des gesamten Berichts in der Literatur gut geeignet sind. Diese Ergebnisse wurden in einer vorläufigen Analyse bestätigt, bei der diese drei Klassifizierer die unterstützenden Vektormaschinen und Random Forests übertrafen. In unseren Experimenten nutzen wir die Scikit-Learn-Bibliothek für Codierungs- und Modellschulungen.
B. Arten von Rauschen
Das in dieser Arbeit untersuchte Rauschen ist das Rauschen in den Klassenlabels der Trainingsdaten. In Anwesenheit solcher Geräusche werden der Lernprozess und das resultierende Modell durch falsch bezeichnete Beispiele beeinträchtigt. Wir analysieren die Auswirkungen verschiedener Lärmpegel, die auf die Klassendaten angewandt werden. Arten von Bezeichnungsgeräuschen wurden zuvor in der Literatur unter Verwendung verschiedener Terminologie diskutiert. In unserer Arbeit analysieren wir die Auswirkungen von zwei verschiedenen Labelrauschen in unseren Klassifizierern: klassenunabhängiges Labelrauschen, das durch zufälliges Auswählen von Instanzen und Vertauschen ihrer Beschriftung eingeführt wird; und klassenabhängiges Rauschen, bei der Klassen unterschiedliche Wahrscheinlichkeiten für Geräuschbelastung haben.
a) Klassenunabhängiges Rauschen: Klassenunabhängiges Rauschen bezieht sich auf das Rauschen, das unabhängig von der tatsächlichen Klasse der Instanzen auftritt. Bei dieser Art von Rauschen ist die Wahrscheinlichkeit, pbr falsch zu bezeichnen, für alle Instanzen im Dataset identisch. Klassenunabhängiges Rauschen wird in die für diese Studie verwendeten Datasets eingeführt, indem jedes Label in den Datasets nach dem Zufallsprinzip mit der Wahrscheinlichkeit pbr umgekehrt wird.
b) Klassenabhängiges Rauschen: Klassenabhängiges Rauschen bezieht sich auf das Rauschen, das von der tatsächlichen Klasse der Instanzen abhängt. Bei dieser Art von Rauschen ist die Wahrscheinlichkeit einer Fehlzuordnung in der Klasse SBR psbr und die Wahrscheinlichkeit einer Fehlzuordnung in der Klasse NSBR ist pnsbr. Klassenabhängiges Rauschen wird in das in dieser Studie verwendeten Dataset eingeführt, indem jeder Eintrag in den Datasets, dessen echtes Label „sicherheitsrelevanter Fehlerbericht“ lautet, mit der Wahrscheinlichkeit psbr umgekehrt wird. Analog dazu wird das Klassenlabel von Instanzen von nicht sicherheitsrelevanten Fehlerberichten mit der Wahrscheinlichkeit pnsbr umgekehrt.
c) Einklassengeräusche: Einzelklassengeräusche sind ein Sonderfall klassenabhängiger Rauschen, wobei pnsbr = 0 und psbr> 0. Beachten Sie, dass für klassenunabhängiges Rauschen psbr = pnsbr = pbr gilt.
C. Erzeugung von Rauschen
Die im Rahmen dieser Studie durchgeführten Experimente untersuchen die Auswirkungen verschiedener Arten von Rauschen und Rauschpegel beim Trainieren von Klassifizierern für sicherheitsrelevante Fehlerberichte. In unseren Experimenten legen wir 25% des Datasets als Testdaten fest, 10% als Validierung und 65% als Schulungsdaten.
Anschließend wird den Trainings- und Validierungsdatasets für verschiedene Pegel von pbr, psbr und pnsbr Rauschen hinzugefügt. Wir nehmen keine Änderungen am Testdatensatz vor. Die verwendeten unterschiedlichen Rauschpegel sind P = {0.05 × i|0 < i < 10}.
In klassenunabhängigen Rauschexperimenten gehen wir für pbr ∈ P wie folgt vor:
Generieren von Rauschen für Trainings- und Validierungsdatasets
Trainieren Sie logistische Regression, naive Bayes- und AdaBoost-Modelle mit Trainingsdatensatz (mit Rauschen); * Optimieren von Modellen mit Validierungsdatensatz (mit Rauschen);
Testmodelle mit Testdatensatz (rauschfrei).
In Experimenten zum klassenabhängigen Rauschen wird für psbr ∈ P und pnsbr ∈ P für alle Kombinationen von psbr und pnsbr wie folgt vorgegangen:
Generieren von Rauschen für Trainings- und Validierungsdatasets
Trainieren Sie logistische Regression, naive Bayes- und AdaBoost-Modelle mit Trainingsdatensatz (mit Rauschen);
Modelle mithilfe eines Validierungsdatensatzes optimieren (mit Rauschen);
Testmodelle mit Testdatensatz (rauschfrei).
V. EXPERIMENTELLE ERGEBNISSE
In diesem Abschnitt analysieren sie die Ergebnisse von Experimenten gemäß der in Abschnitt IV beschriebenen Methodik.
a) Modellleistung ohne Rauschen im Schulungsdatensatz: Einer der Beiträge dieses Papiers ist der Vorschlag eines Machine Learning-Modells zur Identifizierung von Sicherheitsfehlern, indem nur der Titel des Fehlers als Daten für die Entscheidungsfindung verwendet wird. Dies ermöglicht die Schulung von Machine Learning-Modellen auch dann, wenn Entwicklungsteams fehlerberichte aufgrund der Anwesenheit vertraulicher Daten nicht vollständig freigeben möchten. Wir vergleichen die Leistung von drei Machine Learning-Modellen, wenn sie nur mit Bugtiteln trainiert werden.
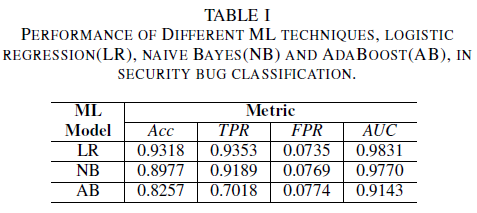
Das logistische Regressionsmodell ist der leistungsstärkste Klassifizierer. Dieser Klassifizierer hat mit 0,9826 den höchsten AUC-Wert und einen Recall von 0,9353 bei einem FPR-Wert von 0,0735. Der naive Bayes Klassifizierer präsentiert etwas niedrigere Leistung als der logistische Regressionsklassifizierer mit einer AUC von 0,9779 und einem Rückruf von 0,9189 für eine FPR von 0,0769. Der AdaBoost-Klassifizierer hat im Vergleich zu den beiden zuvor erwähnten Klassifizierern eine minderwertige Leistung. Er erzielt einen AUC-Wert von 0,9143 und einen Recall von 0,7018 bei einem FPR-Wert von 0,0774. Der Bereich unter der ROC-Kurve (AUC) ist eine gute Metrik für den Vergleich der Leistungen mehrerer Modelle, da er die Beziehung zwischen TPR und FPR in einem einzelnen Wert zusammenfasst. In der nachfolgenden Analyse beschränken wir unsere vergleichende Analyse auf AUC-Werte.
A. Klassenrauschen: einzelne Klasse
Man kann sich ein Szenario vorstellen, in dem standardmäßig alle Fehler der Klasse NSBR zugewiesen sind, und ein Fehler wird nur der Klasse SBR zugewiesen, wenn ein Sicherheitsexperte das Bug-Repository überprüft. Dieses Szenario wird in der experimentellen Einzelklassenumgebung dargestellt, in der wir davon ausgehen, dass pnsbr = 0 und 0 < psbr< 0,5 ist.
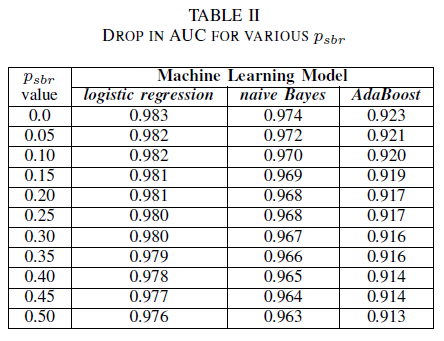
Aus Tabelle II beobachten wir für alle drei Klassifizierer einen sehr geringen Einfluss auf die AUC. Die AUC-ROC eines Modells, das mit psbr = 0 trainiert wurde, unterscheidet sich um 0,003 für logistische Regression, 0,006 für naive Bayes und 0,006 für AdaBoost im Vergleich zu einem AUC-ROC eines Modells, bei dem psbr = 0,25. Im Falle von psbr = 0.50 unterscheiden sich die für jedes der Modelle gemessene AUC um 0,007 für logistische Regression, 0,011 für naive Bayes und 0,010 für AdaBoost von dem Modell, das mit psbr = 0 trainiert wurde. Der logistische Regressionsklassifizierer, der bei Rauschen in einer einzelnen Klasse trainiert wurde, weist die geringste Variation in seiner AUC-Metrik auf, d. h. ein robusteres Verhalten, im Vergleich zu unseren naiven Bayes- und AdaBoost-Klassifizierern.
B. Klassenrauschen: klassenunabhängig
In diesem Experiment wurde die Leistung der drei Klassifizierer für den Fall verglichen, dass das Trainingsdataset durch klassenunabhängiges Rauschen beschädigt wurde. Der AUC-Wert wird für jedes Modell gemessen, das mit unterschiedlichen pbr-Werten trainiert wurde.
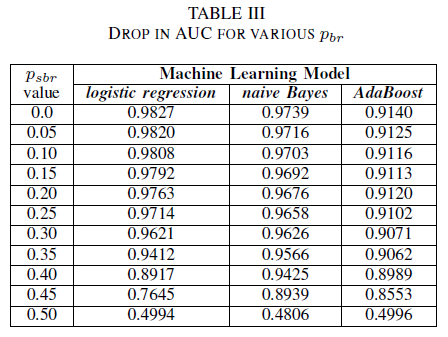
Tabelle III zeigt, dass der AUC-ROC-Wert bei jeder Zunahme von Rauschen im Experiment sinkt. Der AUC-ROC-Wert, der für ein mit nicht verrauschten Daten trainiertes Modell gemessen wird, weicht bei der logistischen Regression um 0,011, beim Naive-Bayes-Klassifizierer um 0,008 und beim AdaBoost-Klassifizierer um 0,0038 von dem AUC-ROC-Wert eines Modells ab, das mit klassenunabhängigem Rauschen und pbr = 0,25 trainiert wurde. Tabelle III zeigt, dass der AUC-Wert der Naive-Bayes- und AdaBoost-Klassifizierer nicht signifikant durch Labelrauschen beeinträchtigt wird, wenn der Rauschpegel geringer als 40 % ist. Der AUC-Wert des auf der logistischen Regression basierenden Klassifizierers sinkt jedoch bereits bei einem Rauschpegel von mehr als 30 %.
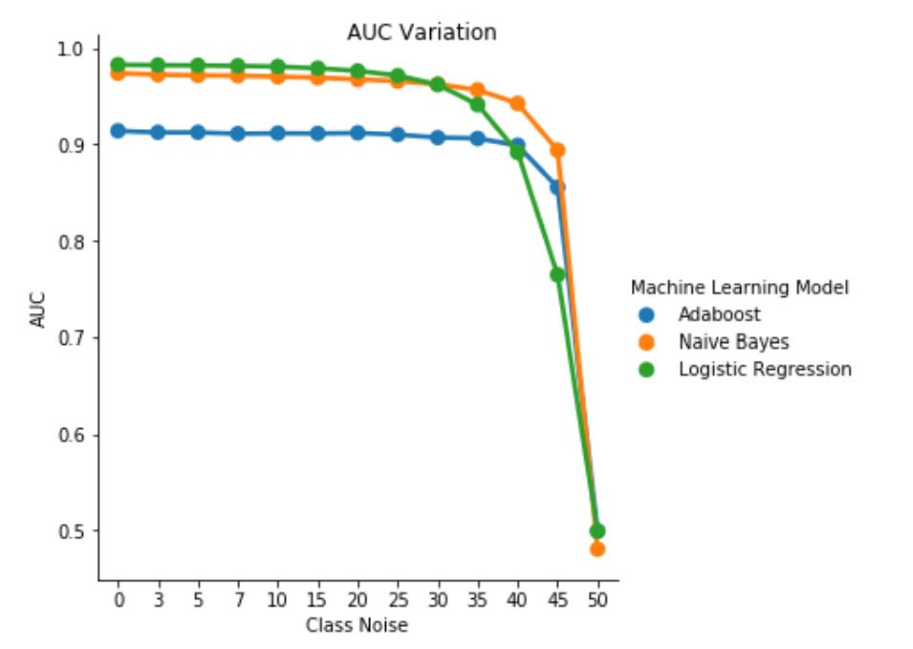
Abb. 1. Schwankung des AUC-ROC-Werts bei klassenunabhängigem Rauschen. Bei einem Rauschpegel von pbr = 0,5 verhält sich der Klassifizierer willkürlich (d. h. AUC ≈ 0,5). Wir können jedoch feststellen, dass der Logistische Regressionslerner für niedrigere Geräuschpegel (pbr ≤0.30) im Vergleich zu den anderen beiden Modellen eine bessere Leistung darstellt. Bei 0,35 ≤ pbr ≤ 0,45 zeigt hingegen der Naive-Bayes-Klassifizierer bessere AUC-ROC-Metriken.
C. Klassenrauschen: klassenabhängig
In der letzten Reihe von Experimenten betrachten wir ein Szenario, in dem verschiedene Klassen unterschiedliche Rauschpegel enthalten, d. h. psbr ≠ pnsbr. psbr und pnsbr werden im Trainingsdatatset systematisch und unabhängig voneinander um 0,05 erhöht, um die Änderungen im Verhalten der drei Klassifizierer zu messen.
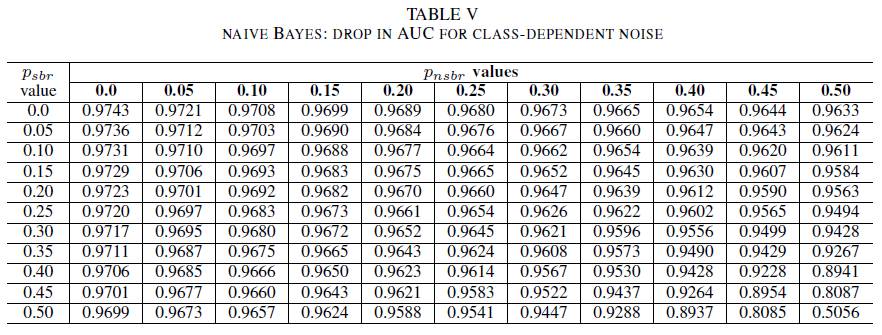
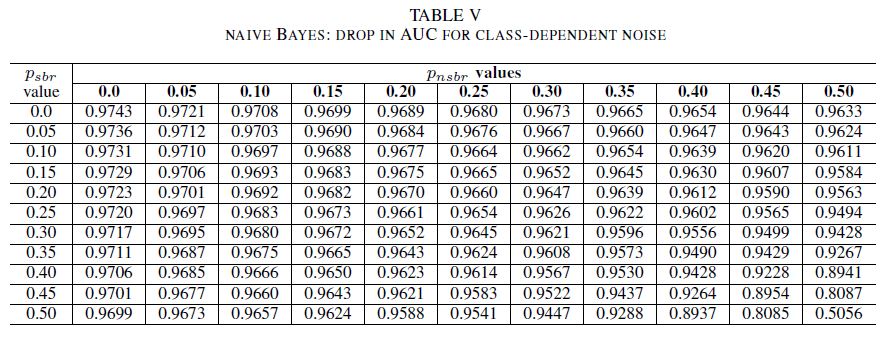
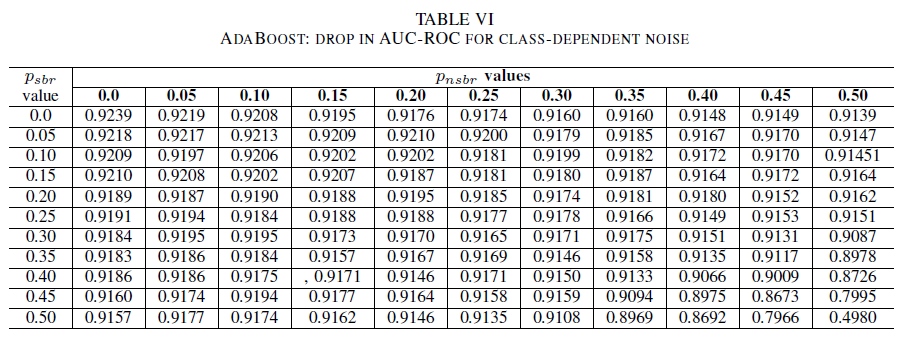
Die Tabellen IV, V, VI zeigen die Variation der AUC, wenn in jeder Klasse das Rauschen auf verschiedenen Ebenen erhöht wird: für logistische Regression in Tabelle IV, für Naive Bayes in Tabelle V und für AdaBoost in Tabelle VI. Alle Klassifizierer zeigen Schwankungen der AUC-Metrik, wenn beide Klassen Rauschpegel von mehr als 30 % aufweisen. Der Naive-Bayes-Klassifizierer verhält sich hier am robustesten. Die Schwankungen des AUC-Werts sind sehr gering, selbst wenn 50 % der Labels in der positiven Klasse umgekehrt werden. Dies setzt jedoch voraus, dass der Anteil an verrauschten Labels in der negativen Klasse 30 % oder weniger beträgt. In diesem Fall liegt der Rückgang der AUC bei 0,03. AdaBoost stellte das robusteste Verhalten aller drei Klassifizierer dar. Eine erhebliche Änderung der AUC erfolgt nur für Geräuschpegel, die größer als 45% in beiden Klassen sind. In diesem Fall beginnen wir, einen AUC-Verfall größer als 0,02 zu beobachten.
D. Über das Vorhandensein von Restgeräuschen im Originaldatensatz
Unser Dataset wurde von signaturbasierten automatisierten Systemen und von menschlichen Experten gekennzeichnet. Darüber hinaus wurden alle Fehlerberichte von menschlichen Experten weiter überprüft und geschlossen. Wir gehen zwar davon aus, dass die Rauschmenge in unserer Datenmenge minimal und nicht statistisch signifikant ist, aber das Vorhandensein von Restgeräuschen macht unsere Schlussfolgerungen nicht ungültig. Nehmen wir zur Veranschaulichung tatsächlich an, dass der Originaldatensatz durch ein klassenunabhängiges Rauschen gleich 0 < p < 1/2 unabhängig und identisch verteilt (i.i.d) für jeden Eintrag verfälscht wird.
Wenn wir über das ursprüngliche Rauschen ein klassenunabhängiges Rauschen mit Wahrscheinlichkeit pbr i.i.d hinzufügen, wird das resultierende Rauschen pro Eintrag als p∗ = p(1 − pbr )+(1 − p)pbr beschrieben. Für 0 < p,pbr< 1/2 haben wir, dass das tatsächliche Rauschen pro Bezeichnung p∗ streng größer ist als das Rauschen, das wir künstlich dem Dataset pbr hinzufügen. So wäre die Leistung unserer Klassifizierer noch besser, wenn sie zunächst mit einem völlig rauschlosen Datensatz (p = 0) trainiert worden wären. Zusammenfassend bedeutet das Vorhandensein von Restgeräuschen im tatsächlichen Dataset, dass die Resilienz gegen Rauschen unserer Klassifizierer besser ist als die hier dargestellten Ergebnisse. Hinzu kommt, dass wenn das residuale Rauschen im Dataset statistisch relevant wäre, der AUC-Wert der Klassifizierer bei einem Rauschpegel, der streng kleiner als 0,5 ist, ebenfalls bei 0,5 läge (zufällige Schätzung). Wir beobachten dieses Verhalten in unseren Ergebnissen nicht.
VI. SCHLUSSFOLGERUNGEN UND ZUKÜNFTIGE ARBEITEN
Unser Beitrag in diesem Dokument ist zweifach.
Zunächst haben wir die Machbarkeit der Klassifizierung des Sicherheitsfehlerberichts basierend auf dem Titel des Fehlerberichts gezeigt. Dies ist insbesondere in Szenarien relevant, in denen der gesamte Fehlerbericht aufgrund von Datenschutzeinschränkungen nicht verfügbar ist. In unserem Fall enthielten die Fehlerberichte beispielsweise private Informationen wie Kennwörter und kryptografische Schlüssel und waren für die Schulung der Klassifizierer nicht verfügbar. Unser Ergebnis zeigt, dass die SBR-Identifikation bei hoher Genauigkeit durchgeführt werden kann, auch wenn nur Berichtstitel verfügbar sind. Unser Klassifizierungsmodell, das eine Kombination aus TF-IDF und logistischer Regression verwendet, erreicht eine AUC von 0,9831.
Zweitens haben wir die Auswirkung falsch bezeichneter Schulungs- und Validierungsdaten analysiert. Wir verglichen drei bekannte Machine Learning Klassifikationstechniken (naïve Bayes, logistische Regression und AdaBoost) in Bezug auf ihre Robustheit gegenüber verschiedenen Lärmtypen und Lärmpegeln. Alle drei Klassifizierer sind robust gegenüber Einzelklassenrauschen. Das Rauschen in den Schulungsdaten hat keine erhebliche Auswirkung auf den resultierenden Klassifizierer. Die Abnahme des AUC-Werts ist bei einem Rauschpegel von 50 % sehr gering (0,01). Für Geräusche, die in beiden Klassen vorhanden sind und klassenunabhängig sind, stellen naive Bayes- und AdaBoost-Modelle signifikante Abweichungen in AUC nur dann dar, wenn sie mit einem Datensatz mit Rauschpegeln trainiert werden, der größer als 40%ist.
Zuletzt ist festzustellen, dass sich das klassenabhängige Rauschen nur dann erheblich auf den AUC-Wert auswirkt, wenn der Rauschpegel in beiden Klassen höher als 35 % ist. AdaBoost zeigte die größte Robustheit. Die Schwankungen des AUC-Werts sind sehr gering, selbst wenn 50 % der Labels in der positiven Klasse verrauscht sind. Dies setzt jedoch voraus, dass der Anteil an verrauschten Labels in der negativen Klasse 45 % oder weniger beträgt. In diesem Fall ist der Rückgang der AUC kleiner als 0,03. Nach unserem besten Wissen ist dies die erste systematische Studie über die Auswirkungen von fehlerhaften Datensätzen bei der Identifizierung von Berichten über Sicherheitslücken.
ZUKÜNFTIGE ARBEITEN
In diesem Dokument haben wir mit der systematischen Untersuchung der Auswirkungen von Geräuschen in der Leistung von Machine Learning-Klassifizierern zur Identifizierung von Sicherheitsfehlern begonnen. Es gibt mehrere interessante Fortsetzungen zu dieser Arbeit, darunter: Untersuchen der Wirkung von lauten Datensätzen bei der Ermittlung des Schweregrads eines Sicherheitsfehlers; die Auswirkungen des Klassenungleichgewichts auf die Resilienz der trainierten Modelle gegen Lärm zu verstehen; Verstehen der Auswirkungen von Rauschen, die in der Datenmenge adversariell eingeführt werden.
REFERENZEN
[1] John Anvik, Lyndon Hiew und Gail C Murphy. Wer sollte diesen Fehler beheben? In: Proceedings of the 28th international conference on Software engineering, S. 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa und Anuja Arora. Ein Tool zur Bug-Mining zum Identifizieren und Analysieren von Sicherheitsfehlern mithilfe von Naive Bayes und tf-idf. In: Optimization, Reliability, and Information Technology (ICROIT), 2014 International Conference on, S. 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann und Sunghun Kim. Werden doppelte Fehlerberichte als wirklich schädlich angesehen? In Softwarewartung, 2008. ICSM 2008. IEEE Internationale Konferenz über, Seiten 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse und Lofton Bullard. Identifizierung von Lernenden, die robust gegenüber Daten von niedriger Qualität sind. In Information Reuse and Integration, 2008. IRI 2008. IEEE International Conference on, Seiten 190–195. IEEE, 2008.
[5] Benoît Frénay. Uncertainty and label noise in machine learning. Doktorarbeit, katholische Universität Louvain, Louvain-la-Neuve, Belgien, 2013.
[6] Benoˆıt Frenay und Michel Verleysen. Classification in the presence of label noise: a survey. IEEE-Transaktionen in neuralen Netzwerken und Lernsystemen, 25(5):845–869, 2014.
[7] Michael Gegick, Pete Rotella und Tao Xie. Identifizieren von Sicherheitsfehlerberichten über Text Mining: Eine industrielle Fallstudie. In: Mining software repositories (MSR), 2010 7th IEEE working conference on, S. 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova und Jacob Tyo. Identifizierung sicherheitsbezogener Fehlerberichte über Text Mining mithilfe der überwachten und nicht überwachten Klassifizierung. In 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), Seiten 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger und Bart Goethals. Vorhersagen des Schweregrads eines gemeldeten Fehlers. In: Mining Software Repositories (MSR), 2010 7th IEEE Working Conference on, S. 1–10. IEEE, 2010.
[10] Naresh Manwani und PS Sastry. Lärmtoleranz bei Risikominimierung. IEEE Transaktionen zu Cybernetik, 43(3):1146–1151, 2013.
[11] G Murphy und D Cubranic. Automatische Fehlertriegung mithilfe der Textkategorisierung. In Tagungsband der Sechzehnten Internationalen Konferenz über Software Engineering und Wissensengineering. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen und Oleksandr Pechenizkiy. Klassengeräusche und überwachtes Lernen in medizinischen Bereichen: Die Wirkung der Featureextraktion. In: null, S. 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre und Gerard Dedieu. Wirkung von Beschriftungsrauschen in Trainingsklassen auf die Klassifizierungsleistung bei der Kartierung der Bodenbedeckung mit Zeitreihen von Satellitenbildern. Fernerkundung, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra und Naresh Manwani. Ein Team von Continuous Action Learning-Automaten für rauschtolerantes Lernen von Halbräumen. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 40(1):19–28, 2010.
[15] Choh-Man Teng. Ein Vergleich der Geräuschbehandlungstechniken. In FLAIRS Conference, Seiten 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic und Miles McQueen. Identifizierung und Klassifizierung von Sicherheitsrisiken über Text Mining-Fehlerdatenbanken. In Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, Seiten 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia und Jianling Sun. Automatisierte Erkennung von Fehlerberichten mit hohem Einfluss unter Anwendung ungleichgewichteter Lernstrategien. In: Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, Band 1, S. 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li und Hai Jin. Automatische Identifizierung von Sicherheitslückenberichten über die Analyse multitypischer Merkmale. In Australasian Conference on Information Security and Privacy, Seiten 619–633. Springer, 2018.