Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Damit Ihr Datenmodell in einer Datenbank gespeichert werden kann, muss es in ein Format konvertiert werden, das die Datenbank verstehen kann. Für unterschiedliche Datenbanken sind unterschiedliche Speicherschemas und Formate erforderlich. Einige haben ein strenges Schema, das eingehalten werden muss, während andere zulassen, dass das Schema vom Benutzer definiert wird.
Die von Semantic Kernel bereitgestellten Vektorspeicher-Connectoren verfügen über integrierte Mapper, die Ihr Datenmodell auf die Datenbankschemata abbilden und umgekehrt. Weitere Informationen dazu, wie die integrierten Mapper Daten für jede Datenbank zuordnen, finden Sie auf der Seite für jeden Connector.
Damit Ihr Datenmodell entweder als Klasse oder definition in einer Datenbank gespeichert werden kann, muss es in einem Format serialisiert werden, das die Datenbank verstehen kann.
Es gibt zwei Möglichkeiten, dies zu tun: entweder durch die Verwendung der integrierten Serialisierung, die vom Semantic Kernel bereitgestellt wird, oder durch Bereitstellung Ihrer eigenen Serialisierungslogik.
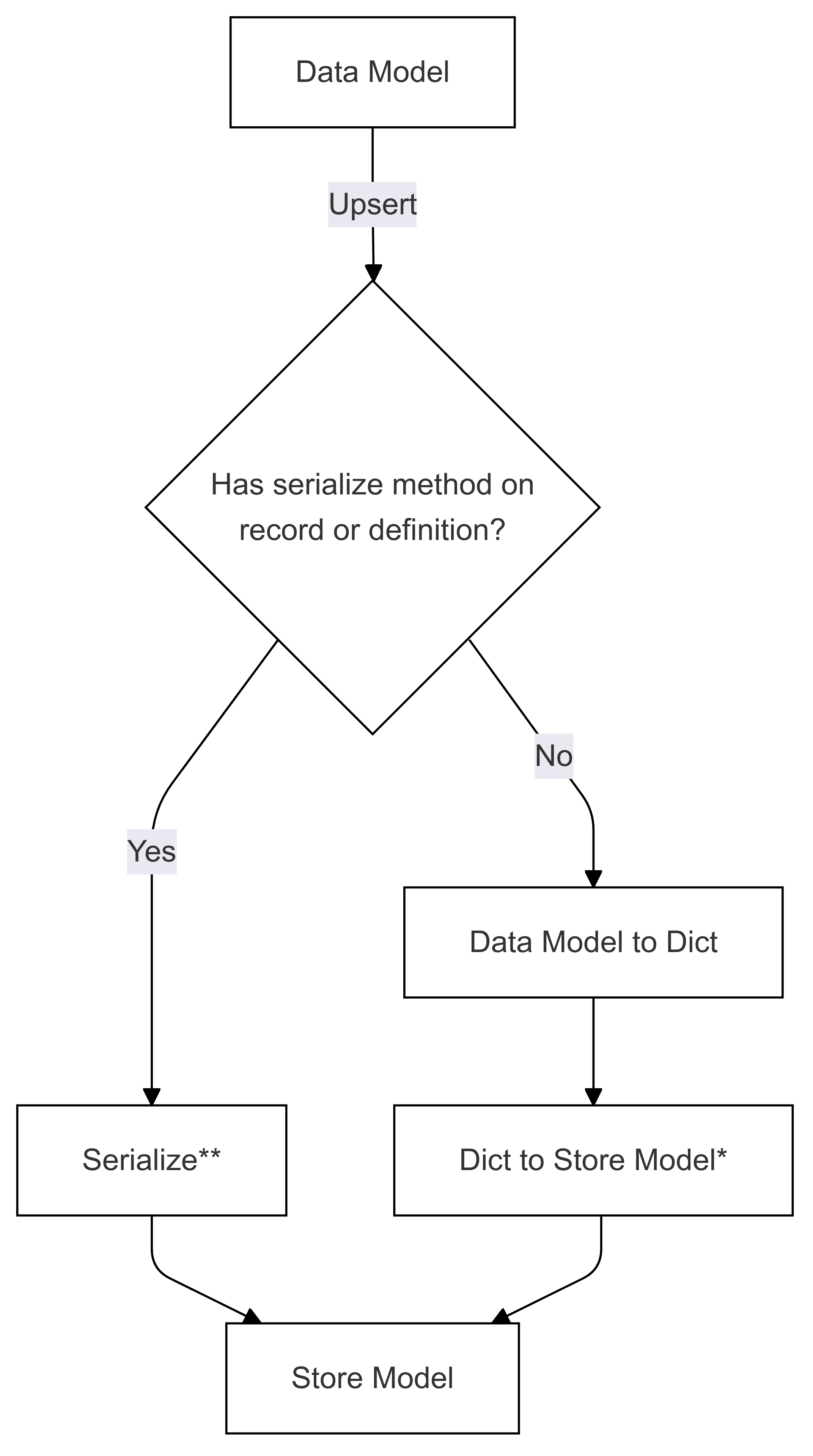
Die folgenden zwei Diagramme zeigen die Abläufe für die Serialisierung und Deserialisierung von Datenmodellen zu und von einem Speichermodell.
Serialisierungsfluss (verwendet in Upsert)
Deserialisierungsablauf (verwendet in Abrufen und Suchen)
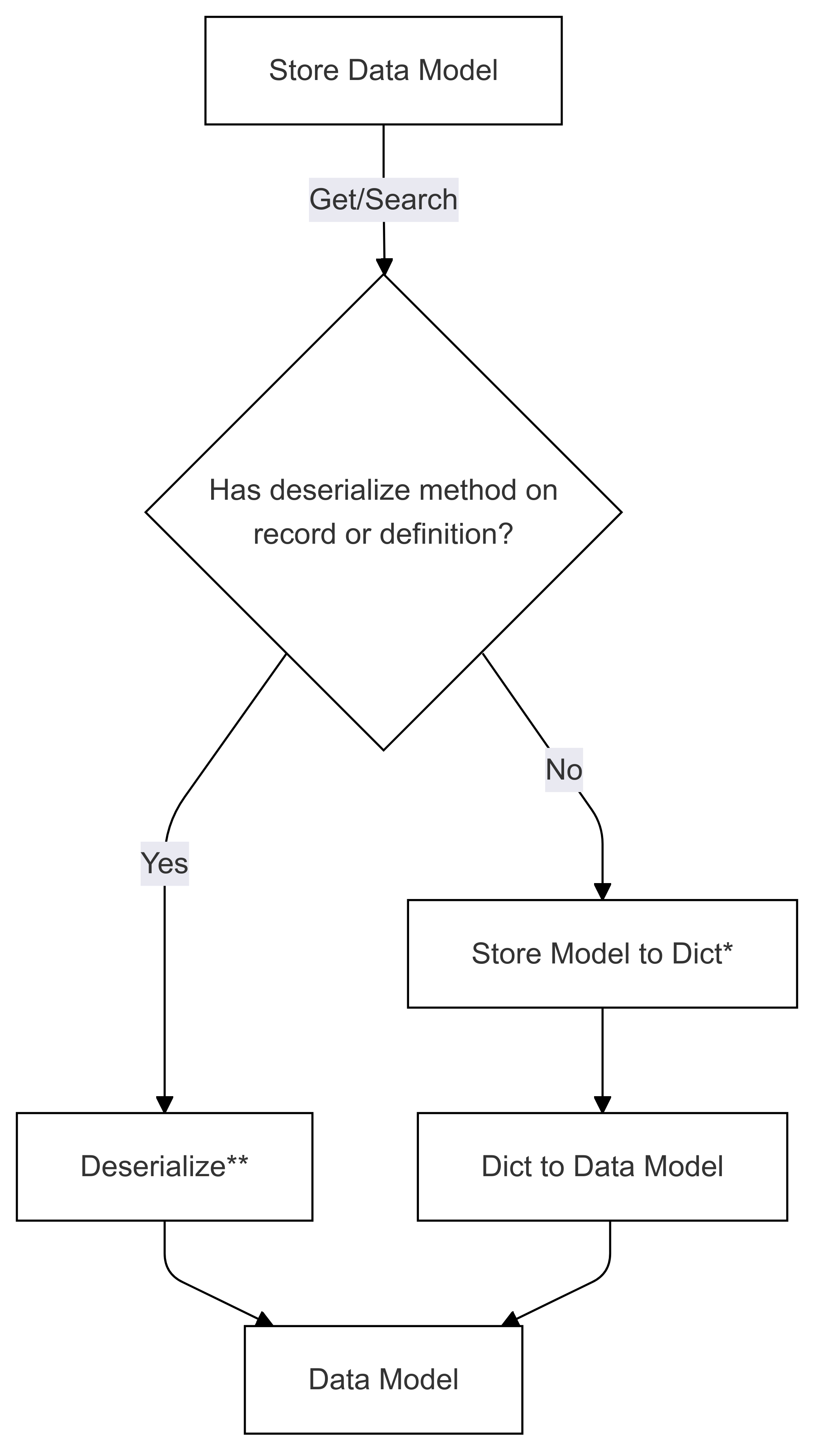
Die Schritte, die mit * (in beiden Diagrammen) gekennzeichnet sind, werden vom Entwickler eines bestimmten Connectors implementiert und unterscheiden sich für jeden Shop. Die mit ** (in beiden Diagrammen) markierten Schritte werden entweder als Methode für einen Datensatz oder als Teil der Datensatzdefinition bereitgestellt, dies wird immer vom Benutzer bereitgestellt, weitere Informationen finden Sie unter Direct Serialization .
(De-)Serialisierungsansätze
Direkte Serialisierung (Datenmodell zu Speichermodell)
Die direkte Serialisierung ist die beste Möglichkeit, um die vollständige Kontrolle darüber zu gewährleisten, wie Ihre Modelle serialisiert werden und um die Leistung zu optimieren. Der Nachteil besteht darin, dass es spezifisch für einen Datenspeicher ist und daher bei Verwendung dieses Systems man nicht so leicht zwischen verschiedenen Speichern mit demselben Datenmodell wechseln kann.
Sie können dies verwenden, indem Sie eine Methode implementieren, die dem SerializeMethodProtocol-Protokoll in Ihrem Datenmodell folgt, oder indem Sie Funktionen hinzufügen, die dem SerializeFunctionProtocol in Ihrer Datensatzdefinition folgen, und beides finden Sie in semantic_kernel/data/vector_store_model_protocols.py.
Wenn eine dieser Funktionen vorhanden ist, wird sie verwendet, um das Datenmodell direkt auf das Speichermodell zu serialisieren.
Sie könnten sogar nur eine der beiden Implementierungen vornehmen und die integrierte (De-)Serialisierung für die andere Richtung verwenden. Dies könnte beispielsweise nützlich sein, wenn Sie mit einer Sammlung arbeiten, die außerhalb Ihrer Kontrolle erstellt wurde, und Sie Anpassungen an der Art und Weise vornehmen müssen, wie sie deserialisiert wird (und Sie ohnehin kein Upsert durchführen können).
Eingebaute (De-)Serialisierung (Datenmodell zu Dict und Dict zu Store-Modell und umgekehrt)
Die integrierte Serialisierung erfolgt, indem das Datenmodell zuerst in ein Wörterbuch umgewandelt und dann für jedes Geschäft, das anders ist und als Teil des integrierten Connectors definiert ist, in das Modell serialisiert wird, das dieses Geschäft versteht. Die Deserialisierung erfolgt in umgekehrter Reihenfolge.
Serialisierung Schritt 1: Datenmodell zu Dict
Je nachdem, welche Art von Datenmodell Sie haben, werden die Schritte auf unterschiedliche Weise ausgeführt. Es gibt vier Möglichkeiten, wie das Datenmodell in ein Wörterbuch serialisiert werden kann:
-
to_dictMethode in der Definition (entspricht dem Attribut to_dict des Datenmodells, nach demToDictFunctionProtocol) - überprüfen, ob der Datensatz ein „
ToDictMethodProtocol“ ist und die „to_dict“-Methode verwenden - Überprüfen Sie, ob der Datensatz ein Pydantic-Modell ist, und verwenden Sie das
model_dumpdes Modells. Siehe die unten stehende Anmerkung für weitere Informationen. - Durchlaufen Sie die Felder in der Definition und erstellen Sie das Wörterbuch
Optional: Einbetten
Wenn Sie über ein Datenmodell mit einem embedding_generator Feld verfügen oder die Sammlung ein embedding_generator Feld enthält, wird die Einbettung generiert und dem Wörterbuch hinzugefügt, bevor sie dem Speichermodell serialisiert wird.
Serialisierung Schritt 2: Diktat zur Speicherung des Modells
Eine Methode muss vom Connector bereitgestellt werden, um das Wörterbuch in das Store-Modell zu konvertieren. Dies wird durch den Entwickler des Connectors ausgeführt und unterscheidet sich für jeden Shop.
Deserialisierung Schritt 1: Modell in Dict speichern
Eine Methode muss vom Connector bereitgestellt werden, um das Store-Modell in ein Wörterbuch zu konvertieren. Dies wird durch den Entwickler des Connectors ausgeführt und unterscheidet sich für jeden Shop.
Deserialisierung Schritt 2 Von Dict zu Datenmodell
Die Deserialisierung erfolgt in umgekehrter Reihenfolge, sie versucht diese Optionen:
-
from_dictMethode in der Definition (entspricht dem from_dict-Attribut des Datenmodells, folgend auf „FromDictFunctionProtocol“) - prüfen, ob der Datensatz ein
FromDictMethodProtocolist und diefrom_dict-Methode verwenden - Überprüfen Sie, ob der Datensatz ein Pydantic-Modell ist und verwenden Sie das
model_validatedes Modells, siehe die unten stehende Anmerkung für weitere Informationen. - Durchlaufen Sie die Felder in der Definition und setzen Sie die Werte. Dann wird dieses Wörterbuch als benannte Argumente in den Konstruktor des Datenmodells übergeben (es sei denn, das Datenmodell ist selbst ein Wörterbuch, in diesem Fall wird es unverändert zurückgegeben).
Anmerkung
Verwenden von Pydantic mit integrierter Serialisierung
Wenn Sie Ihr Modell mit einem Pydantic BaseModel definieren, werden die Methoden „model_dump“ und „model_validate“ verwendet, um das Datenmodell in ein Wörterbuch zu serialisieren und daraus zu deserialisieren. Dies erfolgt mithilfe der model_dump-Methode ohne Angabe von Parametern. Wenn Sie dies steuern möchten, ziehen Sie in Betracht, die ToDictMethodProtocol in Ihrem Datenmodell zu implementieren, da dies zuerst versucht wird.
In Kürze verfügbar
Weitere Informationen folgen in Kürze.