Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie PolyBase auf einem Analytics Platform System (PDW) oder APS-Anwendung verwenden, um externe Daten in Hadoop abzufragen.
Voraussetzungen
PolyBase unterstützt zwei Hadoop-Anbieter: Hortonworks Data Platform (HDP) und Cloudera Distributed Hadoop (CDH). Hadoop folgt dem Muster „Hauptversion.Nebenversion“ für neue Releases, und alle Versionen, die zu einer unterstützten Haupt- und Nebenversion gehören, werden unterstützt. Folgende Hadoop-Anbieter werden unterstützt:
- Hortonworks HDP 1.3 auf Linux/Windows Server
- Hortonworks HDP 2.1 - 2.6 unter Linux
- Hortonworks HDP 3.0 - 3.1 unter Linux
- Hortonworks HDP 2.1 – 2.3 unter Windows Server
- Cloudera CDH 4.3 unter Linux
- Cloudera CDH 5.1 - 5.5, 5.9 - 5.13, 5.15 & 5.16 unter Linux
Konfigurieren der Hadoop-Konnektivität
Konfigurieren Sie zunächst APS für die Verwendung Ihres spezifischen Hadoop-Anbieters.
Führen Sie sp_configure mit „hadoop connectivity“ aus, und legen Sie einen geeigneten Wert für Ihren Anbieter fest. Informationen zum Ermitteln des Werts für Ihren Anbieter finden Sie unter Konfiguration der PolyBase-Konnektivität.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 and 3.0 - 3.1 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOStarten Sie die APS-Region mithilfe der Seite "Dienststatus" in Appliance Configuration Manager neu.
Aktivieren der Pushdownberechnung
Um die Abfrageleistung zu verbessern, aktivieren Sie die Weitergabeberechnung für Ihren Hadoop-Cluster:
Öffnen Sie eine Remotedesktopverbindung mit dem APS PDW Control-Knoten.
Suchen Sie die Datei
yarn-site.xmlauf dem Knoten "Steuerelement". Normalerweise lautet der Pfad:C:\Program Files\Microsoft SQL Server Parallel Data Warehouse\100\Hadoop\conf\.Suchen Sie auf dem Hadoop-Computer die analoge Datei im Hadoop-Konfigurationsverzeichnis. Suchen und kopieren Sie in der Datei den Wert des Konfigurationsschlüssels
yarn.application.classpath.Suchen Sie auf dem Knoten "Steuerelement" in der
yarn.site.xmlDatei dieyarn.application.classpathEigenschaft. Fügen Sie den Wert vom Hadoop-Computer in das Element „Value“ ein.Für alle CDH 5.X-Versionen müssen Sie die
mapreduce.application.classpathKonfigurationsparameter entweder am Ende deryarn.site.xmlDatei oder in dermapred-site.xmlDatei hinzufügen. HortonWorks enthält diese Konfigurationen innerhalb deryarn.application.classpathKonfigurationen. Beispiele finden Sie unter PolyBase-Konfiguration.
XML-Beispieldateien für CDH 5.X-Clusterstandardwerte
Yarn-site.xml mit yarn.application.classpath und mapreduce.application.classpath Konfiguration.
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Wenn Sie ihre beiden Konfigurationseinstellungen in die mapred-site.xml und die yarn-site.xmlDateien aufteilen möchten, sind die Dateien wie folgt:
Für yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CLIENT_CONF_DIR,$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Für mapred-site.xml:
Beachten Sie die Eigenschaft mapreduce.application.classpath. In CDH 5.x finden Sie die Konfigurationswerte unter derselben Benennungskonvention in Ambari.
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<property>
<name>mapred.min.split.size</name>
<value>1073741824</value>
</property>
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH</value>
</property>
<!--kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>mapreduce.jobhistory.principal</name>
<value></value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value></value>
</property>
-->
</configuration>
Beispiel-XML-Dateien für HDP 3.X-Clusterstandardwerte
Für yarn-site.xml:
<?xml version="1.0" encoding="utf-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>yarn.resourcemanager.connect.max-wait.ms</name>
<value>40000</value>
</property>
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>30000</value>
</property>
<!-- Applications' Configuration-->
<property>
<description>CLASSPATH for YARN applications. A comma-separated list of CLASSPATH entries</description>
<!-- Please set this value to the correct yarn.application.classpath that matches your server side configuration -->
<!-- For example: $HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,$HADOOP_YARN_HOME/share/hadoop/yarn/*,$HADOOP_YARN_HOME/share/hadoop/yarn/lib/* -->
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,/usr/hdp/3.1.0.0-78/hadoop/*,/usr/hdp/3.1.0.0-78/hadoop/lib/*,/usr/hdp/current/hadoop-hdfs-client/*,/usr/hdp/current/hadoop-hdfs-client/lib/*,/usr/hdp/current/hadoop-yarn-client/*,/usr/hdp/current/hadoop-yarn-client/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/*,/usr/hdp/3.1.0.0-78/hadoop-yarn/lib/*,/usr/hdp/3.1.0.0-78/hadoop-mapreduce/lib/*,/usr/hdp/share/hadoop/common/*,/usr/hdp/share/hadoop/common/lib/*,/usr/hdp/share/hadoop/tools/lib/*</value>
</property>
<!-- kerberos security information, PLEASE FILL THESE IN ACCORDING TO HADOOP CLUSTER CONFIG
<property>
<name>yarn.resourcemanager.principal</name>
<value></value>
</property>
-->
</configuration>
Konfigurieren einer externen Tabelle
Um die Daten in Ihrer Hadoop-Datenquelle abzufragen, müssen Sie eine externe Tabelle definieren, die in Transact-SQL-Abfragen verwendet werden soll. Die folgenden Schritte beschreiben, wie Sie die externe Tabelle konfigurieren.
Erstellen Sie einen Hauptschlüssel in der Datenbank. Es ist erforderlich, um den geheimen Anmeldeinformationsschlüssel zu verschlüsseln.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';Erstellen Sie datenbankweite Anmeldeinformationen für Hadoop-Cluster, die mit Kerberos gesichert sind.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Erstellen Sie mit CREATE EXTERNAL DATA SOURCE eine externe Datenquelle.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Erstellen Sie mit CREATE EXTERNAL FILE FORMAT ein externes Dateiformat.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE)Erstellen Sie mit CREATE EXTERNAL TABLE eine externe Tabelle, die auf in Hadoop gespeicherte Daten verweist. In diesem Beispiel handelt es sich bei den externen Daten um Kfz-Sensordaten.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Erstellen Sie Statistiken für eine externe Tabelle.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
PolyBase-Abfragen
Es gibt drei Funktionen, für die PolyBase geeignet ist:
- Ad-hoc-Abfragen von externen Tabellen
- Importieren von Daten
- Exportieren von Daten
Die folgenden Abfragen stellen fiktive Kfz-Sensordaten für das Beispiel bereit.
Ad-hoc-Abfragen
Die folgende Ad-hoc-Abfrage verknüpft relationale Daten mit Hadoop-Daten. Es wählt Kunden aus, die schneller als 35 mph fahren und strukturierte Kundendaten verbinden, die in APS gespeichert sind, mit autosensorischen Daten, die in Hadoop gespeichert sind.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Daten importieren
Die folgende Abfrage importiert externe Daten in APS. In diesem Beispiel werden Daten für schnelle Treiber in APS importiert, um eine eingehendere Analyse durchzuführen. Um die Leistung zu verbessern, nutzt sie die Columnstore-Technologie in APS.
CREATE TABLE Fast_Customers
WITH
(CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey))
AS
SELECT DISTINCT
Insured_Customers.CustomerKey, Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
Exportieren von Daten
Die folgende Abfrage exportiert Daten von APS nach Hadoop. Sie kann verwendet werden, um relationale Daten in Hadoop zu archivieren, während sie weiterhin abgefragt werden können.
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009]
WITH (
LOCATION='/archive/customer/2009',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat
)
AS
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
Anzeigen von PolyBase-Objekten in SSDT
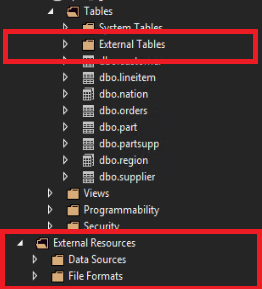
In SQL Server-Datentools werden externe Tabellen in einem separaten Ordner "Externe Tabellen" angezeigt. Externe Datenquellen und externe Dateiformate befinden sich in Unterordnern unter Externe Ressourcen.
Zugehöriger Inhalt
- Informationen zu Hadoop-Sicherheitseinstellungen finden Sie unter Konfigurieren der Hadoop-Sicherheit.
- Weitere Informationen zu PolyBase finden Sie unter Was ist PolyBase?.