Überwachen des Big Data-Cluster-Status mithilfe von Azure Data Studio
In diesem Artikel wird erläutert, wie Sie den Status eines Big-Data-Clusters mit Azure Data Studio anzeigen.
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Verwenden von Azure Data Studio
Nachdem Sie den neuesten Insider-Build von Azure Data Studio heruntergeladen haben, können Sie mithilfe des Dashboards des Big-Data-Clusters für SQL Server Dienstendpunkte sowie den Status eines Big-Data-Clusters anzeigen. Einige der unten aufgeführten Features sind erstmals im Insider-Build von Azure Data Studio verfügbar.
Stellen Sie zunächst eine Verbindung mit Ihrem Big-Data-Cluster in Azure Data Studio her. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit einem Big-Data-Cluster für SQL Server mithilfe von Azure Data Studio.
Klicken Sie mit der rechten Maustaste auf den Endpunkt des Big-Data-Clusters, und wählen Sie Verwalten.
Klicken Sie auf die Registerkarte SQL Server Big Data Cluster (Big-Data-Cluster für SQL Server), um auf das Dashboard des Big-Data-Clusters zuzugreifen.
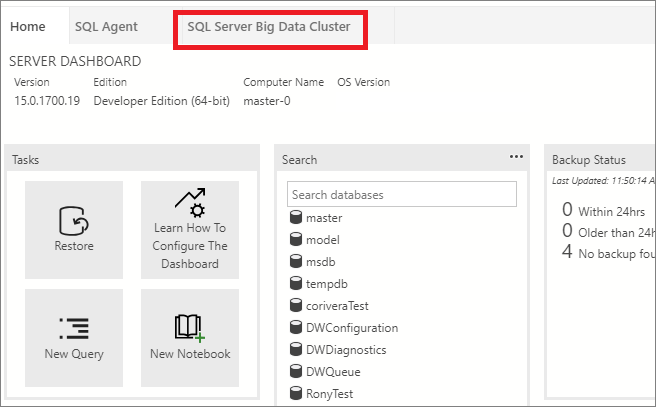
Dienstendpunkte
Es ist wichtig, einfach auf die verschiedenen Dienste innerhalb eines Big-Data-Clusters zugreifen zu können. Das Dashboard des Big-Data-Clusters stellt eine Dienstendpunkttabelle bereit, in der die Dienstendpunkte angezeigt werden und aus der diese kopiert werden können.
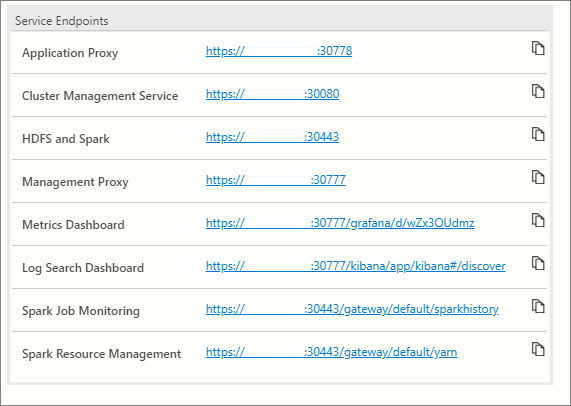
Diese Dienste listen die Endpunkte auf, die Sie kopieren und einfügen können, wenn Sie den Endpunkt für die Verbindung mit diesen Diensten benötigen. Sie können beispielsweise das Kopiersymbol rechts neben dem Endpunkt wählen und diesen dann in ein Textfenster einfügen, in dem er angefordert wird. Der Endpunkt des Clusterverwaltungsdiensts wird zum Ausführen des Notebooks für den Clusterstatus benötigt.
Dashboards
In der Dienstendpunkttabelle werden auch mehrere Dashboards für die Überwachung offengelegt:
- Metriken (Grafana)
- Protokolle (Kibana)
- Spark-Auftragsüberwachung
- Spark-Ressourcenverwaltung
Sie können direkt diese Links auswählen. Sie müssen sich beim Zugriff auf diese Dashboards authentifizieren. Geben Sie für die Dashboards „Metriken“ und „Protokolle“ die Controller-Administratoranmeldeinformationen an, die Sie zum Zeitpunkt der Bereitstellung mithilfe der Umgebungsvariablen AZDATA_USERNAME und AZDATA_PASSWORD festlegen. Spark-Dashboards verwenden Gateway-Anmeldeinformationen (Knox): entweder eine AD-Identität in einem Cluster, der mit AD integriert ist oder AZDATA_USERNAME, und AZDATA_PASSWORD, wenn die Standardauthentifizierung in Ihrem Cluster verwendet wird.
Beginnend mit SQL Server 2019 (15.x) CU 5 verwenden alle Endpunkte einschließlich Gateway AZDATA_USERNAME und AZDATA_PASSWORD, wenn Sie einen neuen Cluster mit Standardauthentifizierung bereitstellen. Endpunkte auf Clustern, die ein Upgrade auf CU 5 erhalten, verwenden weiterhin root als Nutzername für die Verbindung mit dem Gatewayendpunkt. Diese Änderung gilt nicht für Bereitstellungen, die die Active Directory-Authentifizierung verwenden. Weitere Informationen finden Sie unter Anmeldeinformationen für den Zugriff auf Dienste über den Gatewayendpunkt in den Versionshinweisen.
Notebook für den Clusterstatus
Sie können auch den Clusterstatus des Big-Data-Clusters anzeigen, indem Sie das Notebook für den Clusterstatus starten. Wählen Sie die Aufgabe Clusterstatus aus, um das Notebook zu starten.

Bevor Sie beginnen, benötigen Sie folgende Elemente:
- Name des Big-Data-Clusters
- Benutzername des Controllers
- Kennwort des Controllers
- Endpunkte des Controllers
Der Standardname des Big-Data-Clusters ist mssql-cluster, sofern Sie diesen nicht im Laufe der Bereitstellung angepasst haben. Sie finden den Endpunkt des Controllers in der Dienstendpunkttabelle im Dashboard des Big-Data-Clusters. Der Endpunkt wird als Clusterverwaltungsdienst aufgeführt. Wenn Sie die Anmeldeinformationen nicht kennen, fragen Sie den Administrator, der Ihren Cluster bereitgestellt hat.
Wählen Sie in der oberen Symbolleiste Run Cells (Zellen ausführen) aus.
Befolgen Sie die Aufforderung zur Eingabe Ihrer Anmeldeinformationen. Nachdem Sie die Anmeldeinformationen für den Namen des Big-Data-Clusters, den Benutzernamen sowie das Kennwort des Controllers eingegeben haben, drücken Sie die EINGABETASTE.
Hinweis
Wenn Sie keine Konfigurationsdatei für Ihre Big Data eingerichtet haben, werden Sie nach dem Endpunkt des Controllers gefragt. Geben oder fügen Sie ihn ein, und drücken Sie dann die EINGABETASTE, um fortzufahren.
Wenn Sie erfolgreich eine Verbindung hergestellt haben, zeigt der Rest des Notebooks die Ausgabe der einzelnen Komponenten des Big-Data-Clusters an. Wenn Sie eine bestimmte Codezelle erneut ausführen möchten, zeigen Sie mit der Maus auf die Codezelle, und wählen Sie das Symbol zum Ausführen aus.