Bereitstellen des HDFS-Namenknotens und gemeinsamer Spark-Dienste in einer Hochverfügbarkeitskonfiguration
Gilt für:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
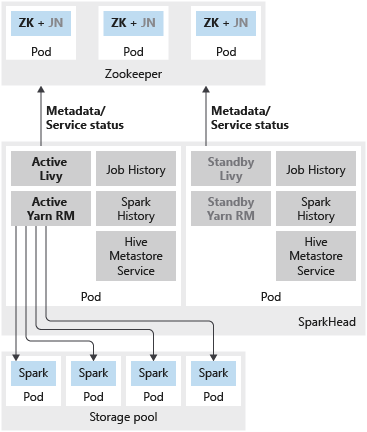
Zusätzlich zur Bereitstellung der SQL Server-Masterinstanz in einer Hochverfügbarkeitskonfiguration mithilfe von Verfügbarkeitsgruppen können Sie auch andere erfolgskritische Dienste im Big Data-Cluster bereitstellen, um eine höhere Zuverlässigkeit sicherzustellen. Sie können HDFS name node und die gemeinsamen Spark-Dienste konfigurieren, die unter sparkhead mit einem zusätzlichen Replikat gruppiert sind. In diesem Fall wird Zookeeper ebenfalls im Big Data-Cluster bereitgestellt, um als Clusterkoordinator und als Metadatenspeicher für folgende Dienste zu dienen:
- HDFS-Namenknoten
- Livy und Yarn Resource Manager.
Beim Spark-Verlauf, dem Auftragsverlauf und dem Hive-Metadatendienst handelt es sich um zustandslose Dienste. Zookeeper ist nicht daran beteiligt, die Dienstintegrität für diese Komponenten sicherzustellen.
Das Bereitstellen mehrerer Replikate für diese Dienste führt zu einer verbesserten Skalierbarkeit und Zuverlässigkeit sowie einem besseren Lastenausgleich der Workloads zwischen den verfügbaren Replikaten.
Hinweis
Die folgenden Dienste werden im sparkhead-Pod als Container bereitgestellt:
- Livy
- Yarn Resource Manager
- Spark-Verlauf
- Auftragsverlauf
- Hive-Metadatendienst
In der folgenden Abbildung wird eine Spark-Hochverfügbarkeitsbereitstellung in einem Big Data-Cluster von SQL Server dargestellt:
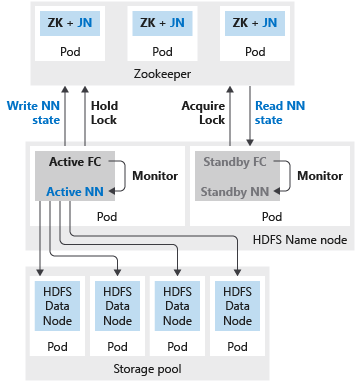
In der folgenden Abbildung wird eine HDFS-Hochverfügbarkeitsbereitstellung in einem Big Data-Cluster von SQL Server dargestellt:
Bereitstellen
Wenn entweder der Namenknoten oder der sparkhead-Pod mit zwei Replikaten konfiguriert wurde, müssen Sie auch die Zookeeper-Ressource mit drei Replikaten konfigurieren. In einer Hochverfügbarkeitskonfiguration für den HDFS-Namenknoten werden die zwei Replikate von zwei Pods gehostet. Die Pods sind nmnode-0 und nmnode-1. Es handelt sich um eine Aktiv-/Passiv-Konfiguration. Es ist immer nur ein Namenknoten aktiv. Der andere befindet sich im Standby-Modus und wird infolge eines Failoverereignisses aktiv.
Sie können entweder die integrierten aks-dev-test-ha- oder kubeadm-prod-Konfigurationsprofile verwenden, um die Big Data-Clusterbereitstellung anzupassen. Diese Profile enthalten die Einstellungen, die für Ressourcen erforderlich sind, für die Sie zusätzliche Hochverfügbarkeit konfigurieren können. Im Folgenden finden Sie beispielsweise einen Abschnitt in der Konfigurationsdatei bdc.json, der für die Bereitstellung des HDFS-Namensknotens, der Zookeeper- und der gemeinsamen Spark-Ressourcen (sparkhead) mit Hochverfügbarkeit relevant ist.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
Als bewährte Methode müssen Sie in einer Produktionsbereitstellung auch die HDFS-Blockreplikation auf 3 festlegen. Diese Einstellung ist bereits in den Profilen aks-dev-test-ha und kubeadm-prod angegeben. Siehe folgenden Abschnitt der Konfigurationsdatei bdc.json:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Bekannte Einschränkungen
Folgende Probleme und Einschränkungen bei der Konfiguration von Hochverfügbarkeit für die Hadoop-Dienste in Big Data-Cluster für SQL Server sind bekannt:
- Alle Konfigurationen müssen zum Zeitpunkt der Bereitstellung von Big Data-Cluster angegeben sein. Mit dem CU1-Release von SQL Server 2019 können Sie die Hochverfügbarkeitskonfiguration nach der Bereitstellung nicht mehr aktivieren.
Nächste Schritte
- Weitere Informationen zum Verwenden von Konfigurationsdateien in Big Data-Clusterbereitstellungen finden Sie unter Bereitstellen von Big Data-Cluster für SQL Server in Kubernetes.
- Weitere Informationen zu Hochverfügbarkeitsoptionen in Big Data-Clustern der SQL Server-Masterinstanz finden Sie im Artikel Bereitstellen der SQL Server-Masterinstanz mit Hochverfügbarkeit.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für