Verwalten von SQL Server-Big Data-Clustern mit Azure Data Studio-Notebooks
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
SQL Server 2019 (15.x) stellt eine Erweiterung für Azure Data Studio bereit, die Notebooks umfasst. Ein Notebook stellt Dokumentation und Code bereit, die Sie in Azure Data Studio verwenden können, um Big Data-Cluster für SQL Server 2019 zu verwalten.
Notebooks, die ursprünglich als Open-Source-Projekt implementiert wurden, wurden in Azure Data Studio integriert. Sie können Markdown für Text in den Textzellen und einen der verfügbaren Kernel verwenden, um Code in den Codezellen zu schreiben.
Sie können Notebooks verwenden, um Big Data-Cluster für SQL Server 2019 (15.x) bereitzustellen.
Zusätzlich zu Notebooks können Sie eine Sammlung von Notebooks anzeigen, die als Jupyter-Book bezeichnet wird. Ein Jupyter-Book stellt ein Inhaltsverzeichnis bereit, das Ihnen bei der Navigation durch eine Sammlung von Notebooks hilft, sodass Sie das gewünschte Notebook leicht finden können, egal ob zur Problembehandlung in SQL Server oder zum Anzeigen des Clusterstatus.
Voraussetzungen
Zum Öffnen eines Notebooks benötigen Sie Folgendes:
- Die neueste Version von Azure Data Studio
- die SQL Server 2019 (15.x)-Erweiterung, die in Azure Data Studio installiert ist
Zusätzlich zu diesen Voraussetzungen benötigen Sie für die Bereitstellung von SQL Server 2019-Big Data-Clustern:
Zugriff auf Notebooks zur Problembehandlung
Es gibt drei Möglichkeiten, um auf Notebooks zur Problembehandlung zuzugreifen.
Befehlspalette
Wählen Sie Ansicht>Befehlspalette aus.
Geben Sie Jupyter Books: SQL Server 2019 Guide (Jupyter-Books: SQL Server 2019-Leitfaden) ein.
Das Viewlet „Jupyter Books“ mit dem Jupyter-Book, das die Fehlerbehebung für Notebooks für SQL Server-Big Data Cluster enthält, wird geöffnet.
SQL-Masterdashboard
Nachdem Sie Azure Data Studio-Insider-Build installiert haben, stellen Sie eine Verbindung mit einer SQL Server-Big Data-Clusterinstanz her.
Nachdem Sie mit der Instanz verbunden sind, klicken Sie mit der rechten Maustaste auf Ihren Servernamen unter Verbindungen, und wählen Sie Verwalten aus.
Wählen Sie im Dashboard SQL Server-Big Data-Cluster aus. Klicken Sie auf SQL Server 2019 Guide (SQL Server 2019-Leitfaden), um das Jupyter-Book mit den Notebooks zu öffnen, die Sie benötigen.
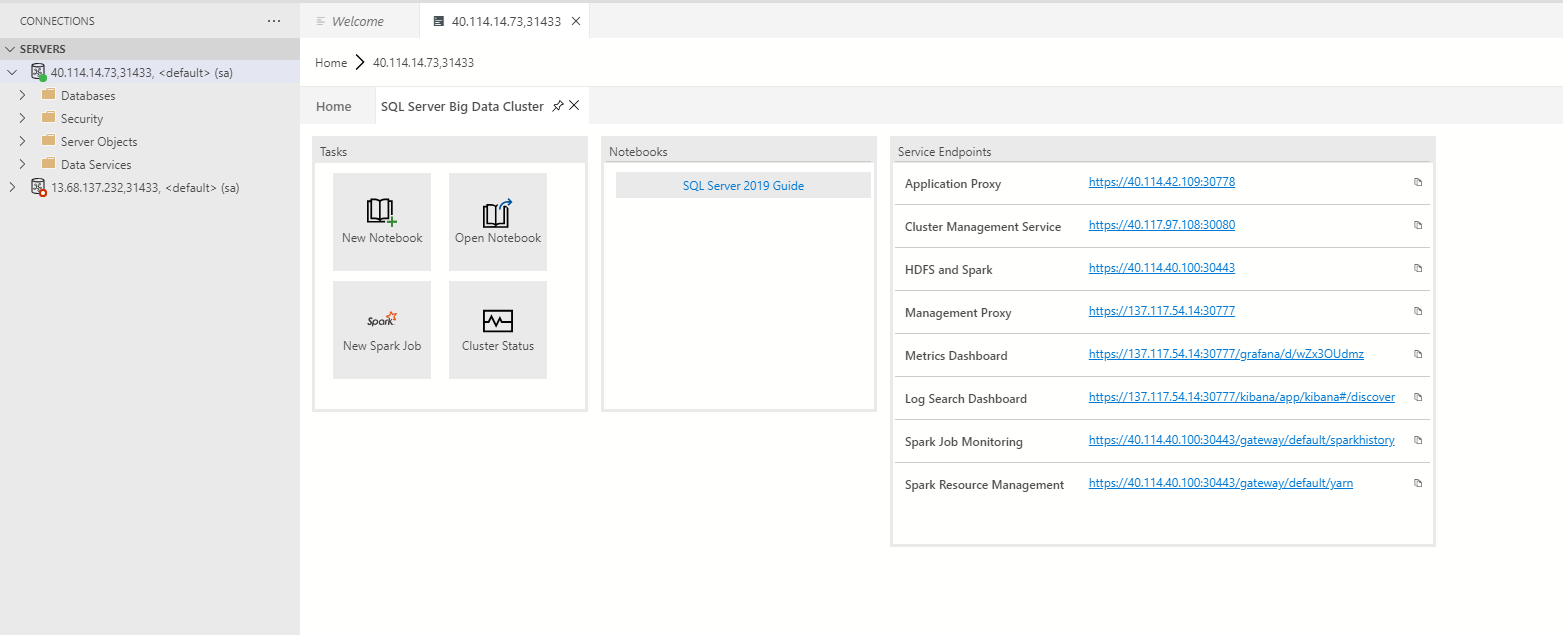
Wählen Sie das Notebook für die Aufgabe aus, die Sie ausführen müssen.
Controllerdashboard
Klappen Sie in der Ansicht VerbindungenSQL Server-Big Data-Cluster auf.
Fügen Sie Details zu Controllerendpunkten hinzu.
Sobald Sie mit dem Controller verbunden sind, klicken Sie mit der rechten Maustaste auf den Endpunkt, und wählen Sie Verwalten aus.
Wählen Sie nach dem Laden des Dashboards Troubleshoot (Problembehandlung) aus, um die Problembehandlungsrichtlinien für das Jupyter-Book zu öffnen.
Verwenden von Notebooks zur Problembehandlung
Suchen Sie im Inhaltsverzeichnis des Jupyter-Book nach der Richtlinie zur Problembehandlung, das Sie benötigen.
Die Notebooks sind optimiert, sodass Sie nur Run Cells (Zellen ausführen) auswählen müssen. Diese Aktion führt jede Zelle im Notebook einzeln aus, bis das Notebook vollständig ist.
Wenn ein Fehler gefunden wird, schlägt das Jupyter-Book ein Notebook vor, das Sie ausführen können, um den Fehler zu beheben. Befolgen Sie die empfohlenen Schritte, und führen Sie das Notebook erneut aus.
Ändern des Big Data-Clusters
So ändern Sie den SQL Server-Big Data-Cluster für ein Notebook:
Klicken Sie in der Symbolleiste des Notebooks auf das Menü Anfügen an.

Klicken Sie im Menü Anfügen an auf einen Server.

Nächste Schritte
Weitere Informationen zu Notebooks in Azure Data Studio finden Sie unter Verwenden von Notebooks mit SQL Server.
Informationen zum Speicherort von Notebooks zur Verwaltung von Big Data-Clustern finden Sie unter Verwaltungsressourcen für Big Data-Cluster.