Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Important
Die Big Data Cluster von Microsoft SQL Server 2019 werden eingestellt. Der Support für SQL Server 2019 Big Data Cluster endete am 28. Februar 2025. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und den Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Im folgenden Beispiel wird veranschaulicht, wie Sie ein Modell mit Spark ML erstellen, es nach MLeap exportieren und in SQL Server mit der Java-Spracherweiterung bewerten. Dies erfolgt im Kontext eines Big Data-Clusters für SQL Server.
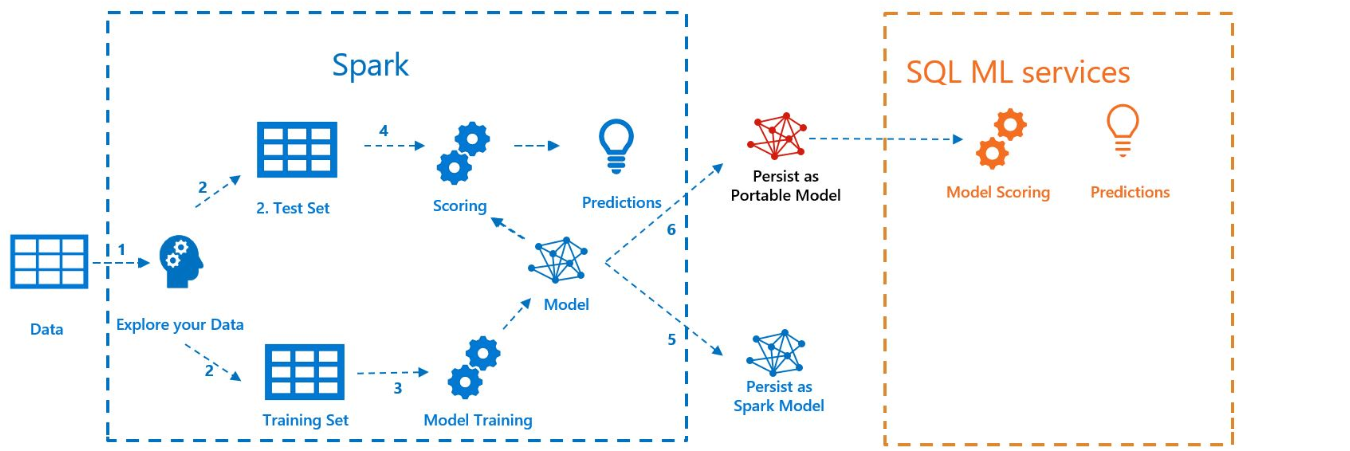
Im folgenden Diagramm werden die in diesem Beispiel durchgeführten Arbeitsschritte veranschaulicht:
Prerequisites
Alle Dateien für dieses Beispiel befinden sich unter https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Zum Ausführen des Beispiels müssen die folgenden Voraussetzungen ebenfalls erfüllt sein:
-
- kubectl
- curl
- Azure Data Studio
Modelltraining mit Spark ML
In diesem Beispiel werden Erhebungsdaten (AdultCensusIncome.csv) zum Erstellen eines Pipelinemodells in Spark ML verwendet.
Verwenden Sie die Datei mleap_sql_test/setup.sh, um das Dataset aus dem Internet herunterzuladen und es auf dem HDFS im Big Data-Cluster Ihrer SQL Server-Instanz abzulegen. Dadurch kann von Spark darauf zugegriffen werden.
Laden Sie anschließend das Beispielnotebook train_score_export_ml_models_with_spark.ipynb herunter. Führen Sie an einer PowerShell- oder Bash-Befehlszeile den folgenden Befehl aus, um das Beispielnotebook herunterzuladen:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Dieses Notebook enthält Zellen mit den erforderlichen Befehlen für diesen Beispielabschnitt.
Öffnen Sie das Notebook in Azure Data Studio, und führen Sie jeden Codeblock aus. Weitere Informationen zum Arbeiten mit Notebooks finden Sie unter Verwenden von Notebooks mit SQL Server.
Die Daten werden zuerst in Spark eingelesen und in Trainings-und Testdatasets aufgeteilt. Anschließend trainiert der Code ein Pipelinemodell mit den Trainingsdaten. Abschließend wird das Modell in ein MLeap-Bundle exportiert.
Tip
Sie können den Python-Code, der diesen Schritten zugeordnet ist, auch außerhalb des Notebooks in der Datei mleap_sql_test/mleap_pyspark.py überprüfen oder ausführen.
Modellbewertung mit SQL Server
Da sich das Spark ML-Pipelinemodell nun in einem allgemeinen MLeap-Bundle-Serialisierungsformat befindet, können Sie das Modell in Java ohne die Verwendung von Spark bewerten.
In diesem Beispiel wird die Java-Spracherweiterung in SQL Server verwendet. Um das Modell in SQL Server bewerten zu können, müssen Sie zunächst eine Java-Anwendung erstellen, die das Modell in Java laden und bewerten kann. Den Beispielcode für diese Java-Anwendung finden Sie im Ordner „mssql-mleap-app“.
Nach dem Erstellen des Beispiels können Sie Transact-SQL verwenden, um die Java-Anwendung aufzurufen und das Modell mit einer Datenbanktabelle zu bewerten. Dies ist in der Quelldatei mleap_sql_test/mleap_sql_tests.py zu sehen.
Next steps
Weitere Informationen zu Big Data-Cluster finden Sie unter Vorgehensweise: Bereitstellen von Big Data-Cluster für SQL Server auf Kubernetes.