Übermitteln von Spark-Aufträgen an Big-Data-Cluster von SQL Server in Visual Studio Code
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
Hier erfahren Sie, wie Sie Spark & Hive Tools für VS Code verwenden, um PySpark-Skripts für Apache Spark zu erstellen und diese zu übermitteln. Zunächst wird beschrieben, wie Sie Spark & Hive Tools für VS Code installieren, anschließend wird die Vorgehensweise zum Übermitteln von Aufträgen an Spark erläutert.
Die Spark & Hive Tools-Erweiterung kann auf allen von Visual Studio Code unterstützten Plattformen installiert werden. Dazu gehören Windows, Linux und macOS. Im Folgenden werden die Voraussetzungen für verschiedene Plattformen aufgeführt.
Voraussetzungen
Die folgenden Elemente sind zum Ausführen der Schritte in diesem Artikel erforderlich:
- Ein Big-Data-Cluster für SQL Server. Siehe Big Data-Cluster für SQL Server.
- Visual Studio Code
- Python und die Python-Erweiterung in Visual Studio Code.
- Mono. Mono ist nur für Linux und macOS erforderlich.
- Einrichten einer interaktiven PySpark-Umgebung für Visual Studio Code
- Ein lokales Verzeichnis namens SQLBDCexample. In diesem Artikel wird C:\SQLBDC\SQLBDCexample verwendet.
Installieren von Spark & Hive Tools
Sobald die Voraussetzungen erfüllt sind, können Sie Spark & Hive Tools für Visual Studio Code installieren. Führen Sie die folgenden Schritte durch, um Spark & Hive Tools zu installieren:
Öffnen Sie Visual Studio Code.
Navigieren Sie über die Menüleiste zu Ansicht>Erweiterungen.
Geben Sie Spark & Hive in das Suchfeld ein.
Wählen Sie in den Suchergebnissen Spark & Hive Tools (veröffentlicht von Microsoft) aus, und wählen Sie dann Installieren aus.
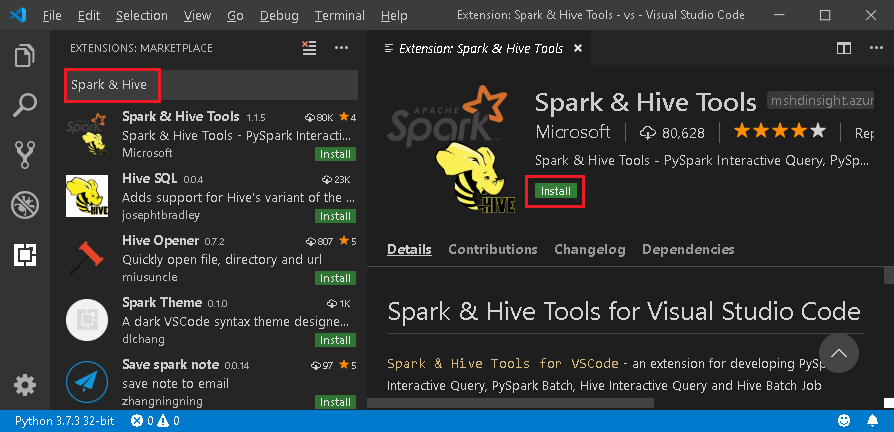
Starten Sie Visual Studio Code bei Bedarf neu.
Öffnen des Arbeitsordners
Führen Sie die folgenden Schritte aus, um einen Arbeitsordner zu öffnen und eine Datei in Visual Studio Code zu erstellen:
Navigieren Sie in der Menüleiste zu Datei>Ordner öffnen...>C:\SQLBDC\SQLBDCexample, und klicken Sie dann auf die Schaltfläche Ordner auswählen. Daraufhin wird der Ordner links in der Ansicht Explorer angezeigt.
Wählen Sie in der Ansicht Explorer den Ordner SQLBDCexample aus, und klicken Sie dann auf das Symbol Neue Datei neben dem Arbeitsordner.
Geben Sie der neuen Datei mit der Erweiterung
.py(Spark-Skript) einen Namen. In diesem Beispiel lautet der Name der Datei HelloWorld.py.Kopieren Sie den folgenden Code, und fügen Sie ihn in die Skriptdatei ein:
import sys from operator import add from pyspark.sql import SparkSession, Row spark = SparkSession\ .builder\ .appName("PythonWordCount")\ .getOrCreate() data = [Row(col1='pyspark and spark', col2=1), Row(col1='pyspark', col2=2), Row(col1='spark vs hadoop', col2=2), Row(col1='spark', col2=2), Row(col1='hadoop', col2=2)] df = spark.createDataFrame(data) lines = df.rdd.map(lambda r: r[0]) counters = lines.flatMap(lambda x: x.split(' ')) \ .map(lambda x: (x, 1)) \ .reduceByKey(add) output = counters.collect() sortedCollection = sorted(output, key = lambda r: r[1], reverse = True) for (word, count) in sortedCollection: print("%s: %i" % (word, count))
Verknüpfen eines Big-Data-Clusters für SQL Server
Bevor Sie Skripts an Ihre Cluster über Visual Studio Code übermitteln können, müssen Sie einen Big Data-Cluster für SQL Server verknüpfen.
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Spark/Hive: Cluster verknüpfen ein.

Wählen Sie SQL Server Big Data (Big-Data-Cluster für SQL Server) als Typ für den verknüpften Cluster aus.
Geben Sie einen Big-Data-Endpunkt für SQL Server ein.
Geben Sie einen Benutzernamen für den Big Data-Cluster für SQL Server ein.
Geben Sie ein Kennwort für den Benutzeradministrator ein.
Legen Sie den Anzeigenamen des Big Data-Clusters fest (optional).
Listen Sie die Cluster auf, überprüfen Sie zur Verifizierung die Ausgabe.
Auflisten der Cluster
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette... , und geben Sie Spark/Hive: Cluster auflisten ein.
Überprüfen Sie die Ansicht Ausgabe. In der Ansicht werden Ihre verknüpften Cluster angezeigt.

Festlegen eines Standardclusters
Falls Sie den zuvor erstellten Ordner SQLBDCexample geschlossen haben, öffnen Sie ihn erneut.
Wählen Sie die Datei HelloWorld.py aus, die Sie zuvor erstellt haben, um sie im Skript-Editor zu öffnen.
Verknüpfen Sie einen Cluster, wenn Sie dies noch nicht getan haben.
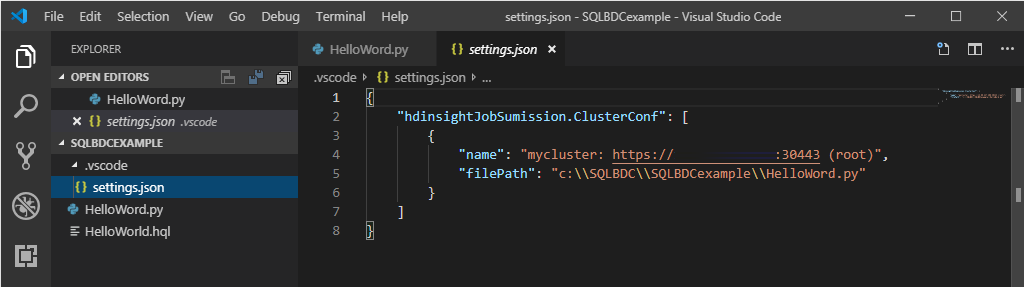
Klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie Spark/Hive: Standardcluster festlegen aus.
Legen Sie einen Cluster als Standardcluster für die aktuelle Skriptdatei fest. Die Tools führen automatisch Updates für die Konfigurationsdatei .VSCode\settings.json durch.
Übermitteln interaktiver PySpark-Abfragen
Sie können interaktive PySpark-Abfragen mithilfe der folgenden Schritte übermitteln:
Falls Sie den zuvor erstellten Ordner SQLBDCexample geschlossen haben, öffnen Sie ihn erneut.
Wählen Sie die Datei HelloWorld.py aus, die Sie zuvor erstellt haben, um sie im Skript-Editor zu öffnen.
Verknüpfen Sie einen Cluster, wenn Sie dies noch nicht getan haben.
Wählen Sie den gesamten Code aus, klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie Spark: PySpark Interactive aus, um die Abfrage zu übermitteln, oder verwenden Sie die Tastenkombination STRG+ALT+I.
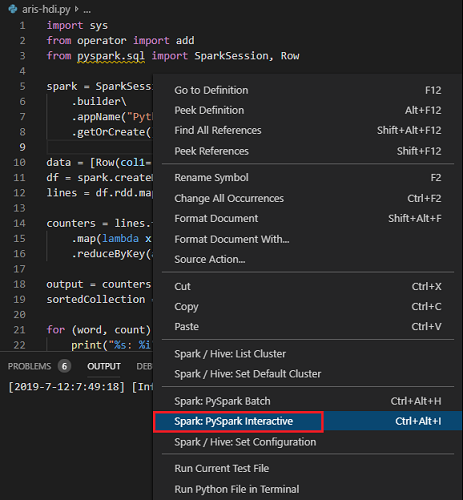
Wählen Sie den Cluster aus, wenn Sie keinen Standardcluster festgelegt haben. Nach einigen Augenblicken werden die Python Interactive-Ergebnisse auf einer neuen Registerkarte angezeigt. Mit den Tools können Sie auch einen Codeblock anstelle der gesamten Skriptdatei über das Kontextmenü übermitteln.
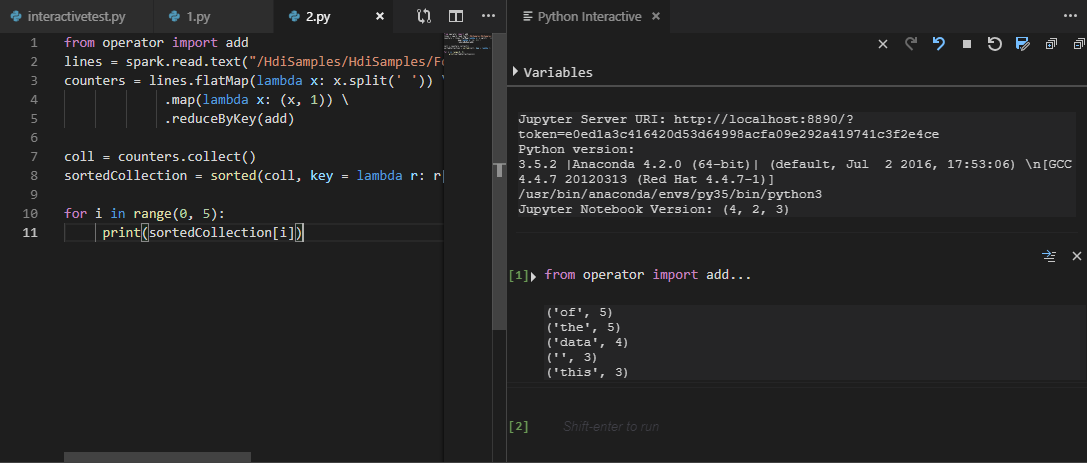
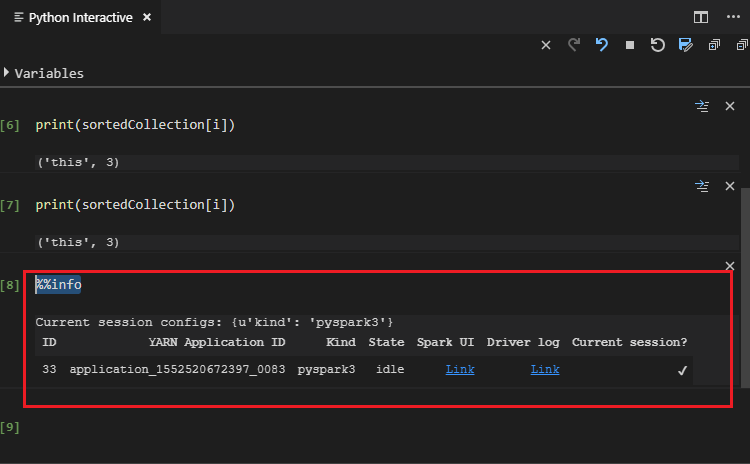
Geben Sie „%%info“ ein, und drücken Sie dann UMSCHALT + EINGABETASTE, um die Auftragsinformationen anzuzeigen. (Optional)
Hinweis
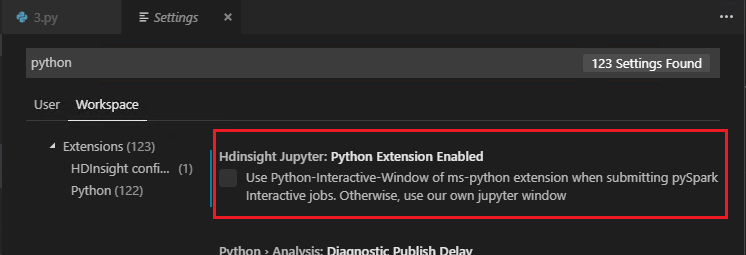
Wenn Python Extension Enabled (Python-Erweiterung aktiviert) nicht in den Einstellungen aktiviert ist (die Standardeinstellung ist aktiviert), werden die Ergebnisse der übermittelten PySpark-Interaktion im alten Fenster angezeigt.
Übermitteln von PySpark-Batchaufträgen
Falls Sie den zuvor erstellten Ordner SQLBDCexample geschlossen haben, öffnen Sie ihn erneut.
Wählen Sie die Datei HelloWorld.py aus, die Sie zuvor erstellt haben, um sie im Skript-Editor zu öffnen.
Verknüpfen Sie einen Cluster, wenn Sie dies noch nicht getan haben.
Klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie Spark: PySpark Batch aus, oder verwenden Sie die Tastenkombination STRG+ALT+H.
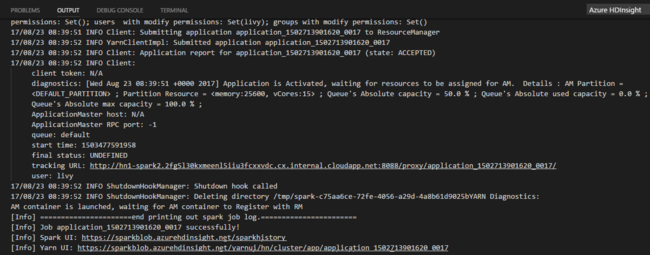
Wählen Sie den Cluster aus, wenn Sie keinen Standardcluster festgelegt haben. Nachdem Sie einen Python-Auftrag übermittelt haben, werden Übermittlungsprotokolle im Ausgabefenster in Visual Studio Code angezeigt. Die Spark UI URL (Spark-Benutzeroberflächen-URL) und die Yarn UI URL (Yarn-Benutzeroberflächen-URL) werden ebenfalls angezeigt. Sie können die URL in einem Webbrowser öffnen, um den Status des Auftrags zu verfolgen.
Apache Livy-Konfiguration
Die Apache Livy-Konfiguration wird unterstützt, diese kann im Arbeitsbereichsordner in der Datei .VSCode\settings.json festgelegt werden. Derzeit wird in der Livy-Konfiguration nur das Python-Skript unterstützt. Weitere Informationen finden Sie im README für Livy.
Auslösen der Livy-Konfiguration
Methode 1
- Navigieren Sie in der Menüleiste zu Datei>Einstellungen>Einstellungen.
- Geben Sie im Textfeld Einstellungen suchen die Option HDInsight Job Sumission: Livy Conf ein.
- Klicken Sie beim relevanten Suchergebnis auf In „settings.json“ bearbeiten.
Methode 2
Übermitteln Sie eine Datei. Beachten Sie, dass der .vscode-Ordner automatisch zum Arbeitsordner hinzugefügt wird. Die Livy-Konfiguration finden Sie, indem Sie unter .vscode die Option settings.json auswählen.
Die Projekteinstellungen:
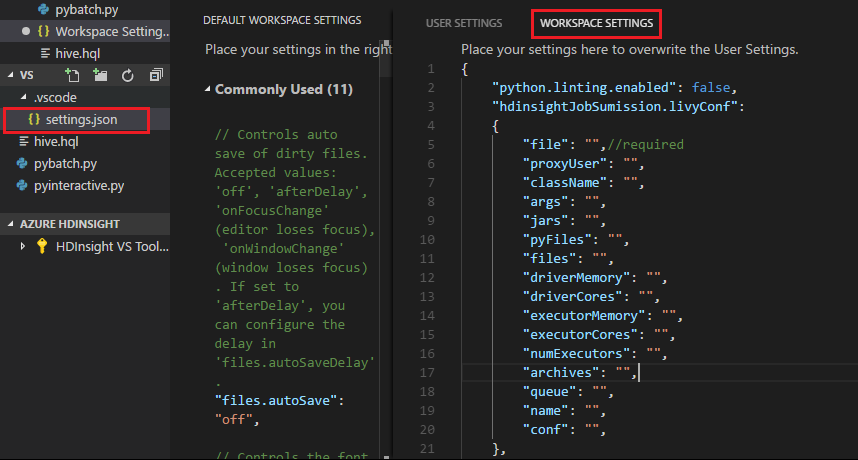
Hinweis
Legen Sie für die Einstellungen driverMemory und executorMemory Werte mit einer Einheit fest, z. B. 1gb oder 1024mb.
Unterstützte Livy-Konfigurationen
POST /batches
Anforderungstext
| name | description | type |
|---|---|---|
| file | Die Datei, die die auszuführende Anwendung enthält | Pfad (erforderlich) |
| proxyUser | Der Benutzer, dessen Identität beim Ausführen des Auftrags angenommen werden soll | string |
| className | Die Java-/Spark-Hauptklasse der Anwendung | string |
| args | Die Befehlszeilenargumente für die Anwendung | Eine Liste von Zeichenfolgen |
| jars | Die JAR-Dateien, die in dieser Sitzung verwendet werden sollen | Eine Liste von Zeichenfolgen |
| pyFiles | Die Python-Dateien, die in dieser Sitzung verwendet werden sollen | Eine Liste von Zeichenfolgen |
| files | Die Dateien, die in dieser Sitzung verwendet werden sollen | Eine Liste von Zeichenfolgen |
| driverMemory | Die Menge an Arbeitsspeicher, die für den Treiberprozess verwendet werden soll | string |
| driverCores | Die Anzahl der Kerne, die für den Treiberprozess verwendet werden soll | INT |
| executorMemory | Die Menge an Arbeitsspeicher, die pro Executorprozess verwendet werden soll | string |
| executorCores | Die Anzahl von Kernen, die für jeden Executor verwendet werden sollen | INT |
| numExecutors | Die Anzahl der Executors, die für diese Sitzung gestartet werden sollen | INT |
| archives | Die Archive, die in dieser Sitzung verwendet werden sollen | Eine Liste von Zeichenfolgen |
| queue | Der Name der YARN-Warteschlange, an die übermittelt werden soll | Zeichenfolge |
| name | Der Name der Sitzung | string |
| conf | Spark-Konfigurationseigenschaften | Zuordnung von Schlüsseln zu Werten |
| :- | :- | :- |
Antworttext
Das erstellte Batchobjekt
| name | description | type |
|---|---|---|
| id | Die Sitzungs-ID | INT |
| appId | Die Anwendungs-ID der Sitzung | String |
| appInfo | Die ausführliche Anwendungsinformationen | Zuordnung von Schlüsseln zu Werten |
| log | Die Protokollzeilen | Eine Liste von Zeichenfolgen |
| state | Der Batchzustand | string |
| :- | :- | :- |
Hinweis
Die zugewiesene Livy-Konfiguration wird im Ausgabebereich angezeigt, wenn das Skript übermittelt wird.
Zusätzliche Features
Spark & Hive für Visual Studio Code unterstützt die folgenden Features:
Die automatische Vervollständigung von IntelliSense: Für Schlüsselwörter, Methoden, Variablen usw. werden Vorschläge angezeigt. Verschiedene Symbole stellen verschiedene Objekttypen dar.
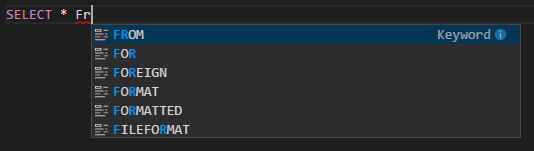
IntelliSense-Fehlermarkierung: Der Sprachdienst unterstreicht Fehler im Hive-Skript.
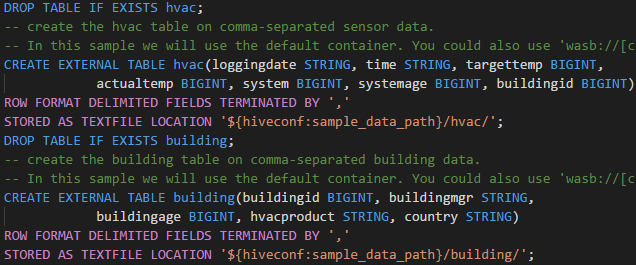
Syntaxhervorhebungen: Der Sprachdienst verwendet verschiedene Farben, um zwischen Variablen, Schlüsselwörtern, Datentypen, Funktionen usw. zu unterscheiden.
Aufheben der Verknüpfung von Clustern
Navigieren Sie auf der Menüleiste zu Ansicht>Befehlspalette, und geben Sie dann Spark/Hive: Clusterverknüpfung aufheben ein.
Wählen Sie einen Cluster auf, dessen Verknüpfung aufgehoben werden soll.
Überprüfen Sie die Ausgabe.
Nächste Schritte
Weitere Informationen zu Big Data-Clustern für SQL Server und zugehörige Szenarios finden Sie unter Big Data-Cluster für SQL Server.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für