Problembehandlung für ein pyspark Notebook
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
In diesem Artikel wird gezeigt, wie ein Troubleshooting für pyspark-Notebooks durchgeführt wird, wenn Fehler auftreten.
Architektur eines Pyspark-Auftrags in Azure Data Studio
Azure Data Studio kommuniziert mit dem livy-Endpunkt in SQL Server-Big Data-Cluster.
Der livy-Endpunkt gibt spark-submit-Befehle im Big Data-Cluster aus. Jeder spark-submit-Befehl verfügt über einen Parameter, der YARN als Clusterressourcen-Manager angibt.
Für ein effizientes Troubleshooting Ihrer PySpark-Sitzung sammeln und überprüfen Sie Protokolle auf jeder der drei folgenden Ebenen: Livy, YARN und Spark.
Für diese Troubleshootingschritte ist Folgendes erforderlich:
- Eine Azure Data CLI (
azdata)-Installation, deren Konfiguration ordnungsgemäß auf Ihren Cluster festgelegt ist - Vertrautheit mit der Ausführung von Linux-Befehlen und Erfahrung mit Protokolltroubleshooting
Schritte zur Problembehandlung
Überprüfen Sie den Stapel und die Fehlermeldungen in
pyspark.Rufen Sie die Anwendungs-ID aus der ersten Zelle im Notebook ab. Verwenden Sie diese Anwendungs-ID, um die
livy-, YARN- und Spark-Protokolle zu untersuchen.SparkContextverwendet diese YARN-Anwendungs-ID.
Rufen Sie die Protokolle ab.
Verwenden Sie zur Untersuchung
azdata bdc debug copy-logs.Im folgenden Beispiel wird eine Verbindung zu einem Big Data-Cluster-Endpunkt hergestellt, um die Protokolle zu kopieren. Aktualisieren Sie vor der Ausführung die folgenden Werte im Beispiel.
-
<ip_address>: Big Data-Cluster-Endpunkt -
<username>: Benutzername Ihres Big Data-Clusters -
<namespace>: Kubernetes-Namespace für Ihren Cluster -
<folder_to_copy_logs>: Der lokale Ordnerpfad zum Speicherort, an den Ihre Protokolle kopiert werden sollen
azdata login --auth basic --username <username> --endpoint https://<ip_address>:30080 azdata bdc debug copy-logs -n <namespace> -d <folder_to_copy_logs>Beispielausgabe
<user>@<server>:~$ azdata bdc debug copy-logs -n <namespace> -d copy_logs Collecting the logs for cluster '<namespace>'. Collecting logs for containers... Creating an archive from logs-tmp/<namespace>. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-<namespace>-YYYYMMDD-HHMMSS-dumps.tar.gz. Collecting the logs for cluster 'kube-system'. Collecting logs for containers... Creating an archive from logs-tmp/kube-system. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS.tar.gz. Creating an archive from logs-tmp/dumps. Log files are archived in /home/<user>/copy_logs/debuglogs-kube-system-YYYYMMDD-HHMMSS-dumps.tar.gz.-
Überprüfen Sie die Livy-Protokolle. Die Livy-Protokolle befinden sich unter
<namespace>\sparkhead-0\hadoop-livy-sparkhistory\supervisor\log.- Suchen Sie in der ersten Zelle des PySpark-Notebooks nach der YARN-Anwendungs-ID.
- Suchen Sie nach dem
ERR-Status.
Unten sehen Sie ein Beispiel für ein Livy-Protokoll mit dem
YARN ACCEPTED-Status. Livy hat die YARN-Anwendung übermittelt.HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO impl.YarnClientImpl: Submitted application application_<application_id> YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: Application report for application_<application_id> (state: ACCEPTED) YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: YYY-MM-DD HH:MM:SS INFO yarn.Client: YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: client token: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: diagnostics: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster host: N/A YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: ApplicationMaster RPC port: -1 YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: queue: default YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: start time: ############ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: final status: UNDEFINED YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: tracking URL: https://sparkhead-1.fnbm.corp:8090/proxy/application_<application_id>/ YY/MM/DD HH:MM:SS INFO utils.LineBufferedStream: user: <account>Überprüfen Sie die YARN-Benutzeroberfläche.
Rufen Sie im Dashboard für die Big Data-Cluster-Verwaltung in Azure Data Studio die YARN-Endpunkt-URL ab, oder führen Sie
azdata bdc endpoint list –o tableaus.Beispiel:
azdata bdc endpoint list -o tableRückgabe
Description Endpoint Name Protocol ------------------------------------------------------ ---------------------------------------------------------------- -------------------------- ---------- Gateway to access HDFS files, Spark https://knox.<namespace-value>.local:30443 gateway https Spark Jobs Management and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/sparkhistory spark-history https Spark Diagnostics and Monitoring Dashboard https://knox.<namespace-value>.local:30443/gateway/default/yarn yarn-ui https Application Proxy https://proxy.<namespace-value>.local:30778 app-proxy https Management Proxy https://bdcmon.<namespace-value>.local:30777 mgmtproxy https Log Search Dashboard https://bdcmon.<namespace-value>.local:30777/kibana logsui https Metrics Dashboard https://bdcmon.<namespace-value>.local:30777/grafana metricsui https Cluster Management Service https://bdcctl.<namespace-value>.local:30080 controller https SQL Server Master Instance Front-End sqlmaster.<namespace-value>.local,31433 sql-server-master tds SQL Server Master Readable Secondary Replicas sqlsecondary.<namespace-value>.local,31436 sql-server-master-readonly tds HDFS File System Proxy https://knox.<namespace-value>.local:30443/gateway/default/webhdfs/v1 webhdfs https Proxy for running Spark statements, jobs, applications https://knox.<namespace-value>.local:30443/gateway/default/livy/v1 livy httpsÜberprüfen Sie die Anwendungs-ID und die einzelnen application_master- und Containerprotokolle.

Überprüfen Sie die YARN-Anwendungsprotokolle.
Rufen Sie das Anwendungsprotokoll für die App ab. Verwenden Sie
kubectl, um eine Verbindung zumsparkhead-0-Pod herzustellen. Beispiel:kubectl exec -it sparkhead-0 -- /bin/bashFühren Sie dann innerhalb dieser Shell mit der korrekten
application_idden folgenden Befehl aus:yarn logs -applicationId application_<application_id>Suchen Sie nach Fehlern oder Stapeln.
Unten sehen Sie ein Beispiel für einen Berechtigungsfehler, der gegen HDFS verstößt. Suchen Sie im Java-Stapel nach
Caused by:.YYYY-MM-DD HH:MM:SS,MMM ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:399) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:255) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:193) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1852) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1836) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1795) at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:324) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2504) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileChecked(FSNamesystem.java:2448) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=<account>, access=WRITE, inode="/system/spark-events":sph:<bdc-admin>:drwxr-xr-xÜberprüfen Sie die Spark-Benutzeroberfläche.
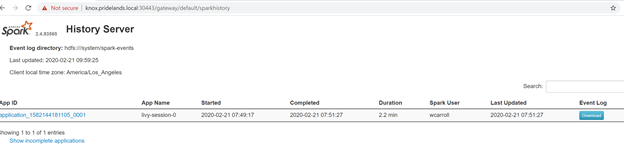
Führen Sie ein Drilldown in die Tasks der Stufen durch, und suchen Sie nach Fehlern.
Nächste Schritte
Behandeln von Problemen mit der Integration von Active Directory in SQL Server-Big Data-Cluster