Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: ![]() SQL Server
SQL Server
Bei SQL Server 2012 und 2014 ist die einzige Möglichkeit, ein sekundäres Replikat in einer SQL Server Always On-Verfügbarkeitsgruppe zu initialisieren, die Verwendung von Sicherung, Kopieren und Wiederherstellung. SQL Server 2016 führt eine neue Funktion zum Initialisieren eines sekundären Replikats ein – das automatische Seeding. Das automatische Seeding verwendet die Übermittlung durch Protokollstream, um die Sicherung mit VDI für jede Datenbank der Verfügbarkeitsgruppe mit konfigurierten Endpunkten an das sekundäre Replikat zu streamen. Diese neue Funktion kann verwendet werden, wenn eine Verfügbarkeitsgruppe erstellt wird oder wenn ihr eine Datenbank hinzugefügt wird. Das automatische Seeding ist in allen Versionen von SQL Server verfügbar, die Always On-Verfügbarkeitsgruppen unterstützen, und kann sowohl mit herkömmlichen als auch mit verteilten Verfügbarkeitsgruppen verwendet werden.
Sicherheit
Die Sicherheitsberechtigungen variieren je nach Art des Replikats, das initialisiert wird:
- Bei einer herkömmlichen Verfügbarkeitsgruppe müssen der Verfügbarkeitsgruppe auf dem sekundären Replikat Berechtigungen gewährt werden, wenn dieses mit der Verfügbarkeitsgruppe verknüpft wird. Verwenden Sie in Transact-SQL den Befehl
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE. - Bei einer verteilten Verfügbarkeitsgruppe, bei der sich die erstellten Datenbanken des Replikats auf dem primären Replikat der sekundären Verfügbarkeitsgruppe befinden, sind keine zusätzlichen Berechtigungen erforderlich, da es sich bereits um ein primäres Replikat handelt. Wenn jedoch nur ein Replikat in der zweiten Verfügbarkeitsgruppe vorhanden ist, erteilen Sie der Sekundärverfügbarkeitsgruppe die Berechtigung
CREATE ANY DATABASE, weil das automatische Seeding sonst fehlschlagen kann. - Bei einem sekundären Replikat auf der sekundären Verfügbarkeitsgruppe einer verteilten Verfügbarkeitsgruppe müssen Sie den Befehl
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASEverwenden. Für dieses sekundäre Replikat wird ein Seeding vom primären Replikat der sekundären Verfügbarkeitsgruppe durchgeführt.
Auswirkungen von Leistung und Transaktionsprotokoll auf das primäre Replikat
Ob das automatische Seeding beim Initialisieren eines sekundären Replikats hilfreich ist, hängt von der Größe der Datenbank, der Netzwerkgeschwindigkeit und der Entfernung zwischen dem primären und dem sekundären Replikat ab. Angenommen, dies liegt vor:
- Die Datenbankgröße beträgt 5 TB
- Die Netzwerkgeschwindigkeit beträgt 1GB/s
- Die Entfernung zwischen den beiden Standorten beträgt über 1.600 Kilometer
Wenn die volle Bandbreite verfügbar ist, kann ein Netzwerk mit 1GB/s einen anhaltenden Durchsatz von 125MB/s bereitstellen. In diesem Beispiel würde das automatische Seeding knapp über 11 Stunden dauern. In der Praxis ist das automatische Seeding langsamer, da Netzwerksignale auf langen Entfernungen schwächer werden und der Link mit anderen Ressourcen im Netzwerk geteilt wird. Während des Seedings wird das Transaktionsprotokoll für die Datenbank im primären Replikat noch länger und kann erst abgeschnitten werden, wenn das automatische Seeding für diese Datenbank abgeschlossen ist. Das Transaktionsprotokoll kann dann mit einer Sicherung des Transaktionsprotokolls abgeschnitten werden.
Das automatische Seeding ist ein Singlethreadprozess, der bis zu fünf Datenbanken verarbeiten kann. Der Singlethreadprozess kann die Leistung beeinträchtigen, vor allem wenn die Verfügbarkeitsgruppe über mehrere Datenbanken verfügt.
Die Komprimierung kann für das automatische Seeding verwendet werden, ist aber in der Standardeinstellung deaktiviert. Das Aktivieren der Komprimierung reduziert die Netzwerkbandbreite und beschleunigt möglicherweise den Prozess, führt jedoch zu zusätzlichem Prozessoroverhead. Aktivieren Sie das Ablaufverfolgungsflag 9567, um die Komprimierung während des automatischen Seedings zu verwenden. Siehe dazu Optimieren der Komprimierung für die Verfügbarkeitsgruppe.
Datenträgerlayout
Bis SQL Server 2016 muss der Ordner, in dem die Datenbank durch das automatische Seeding erstellt wird, bereits vorhanden und mit dem Pfad auf dem primären Replikat identisch sein.
In SQL Server 2017 empfiehlt Microsoft, denselben Pfad für Daten und Protokolldateien für alle Replikate zu verwenden, die in einer Verfügbarkeitsgruppe enthalten sind. Sie können jedoch bei Bedarf unterschiedliche Pfade verwenden. In einer plattformübergreifenden Verfügbarkeitsgruppe kann sich beispielsweise eine Instanz von SQL Server unter Windows und eine weitere Instanz von SQL Server unter Linux befinden. Die unterschiedlichen Plattformen verfügen über unterschiedliche Standardpfade. SQL Server 2017 unterstützt Verfügbarkeitsgruppenreplikate auf Instanzen von SQL Server mit unterschiedlichen Standardpfaden.
Die folgende Tabelle enthält Beispiele für die unterstützten Datenträgerlayouts, die automatisches Seeding unterstützen können:
| Primäre Instanz Standarddatenpfad |
Sekundäre Instanz Standarddatenpfad |
Primäre Instanz Speicherort der Quelldatei |
Sekundäre Instanz Speicherort der Quelldatei |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Szenarios, bei denen der Speicherort der Datenbank der primären und sekundären Replikate nicht dem Standardpfad der Instanz entspricht, sind von dieser Änderung nicht betroffen. Die Anforderung, dass die Dateipfade von sekundären Replikaten mit denen der primären Replikate übereinstimmen müssen, besteht weiterhin.
| Primäre Instanz Standarddatenpfad |
Sekundäre Instanz Standarddatenpfad |
Primäre Instanz Speicherort der Datei |
Sekundäre Instanz Speicherort der Datei |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
Beim Kombinieren von Standard- und Nicht-Standardpfaden auf den primären und sekundären Replikaten verhält sich SQL Server 2017 anders als die vorherigen Versionen. In der folgenden Tabelle wird das Verhaltensmuster von SQL Server 2017 veranschaulicht.
| Primäre Instanz Standarddatenpfad |
Sekundäre Instanz Standarddatenpfad |
Primäre Instanz Speicherort der Datei |
SQL Server 2016 Sekundäre Instanz Speicherort der Datei |
SQL Server 2017 Sekundäre Instanz Speicherort der Datei |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
Aktivieren Sie das Ablaufverfolgungsflag 9571, um das Verhalten von SQL Server 2016 (und früher) wiederherzustellen. Weitere Informationen zum Aktivieren von Ablaufverfolgungsflags finden Sie unter DBCC TRACEON (Transact-SQL).
Erstellen einer Verfügbarkeitsgruppe mit automatischem Seeding
Sie erstellen eine Verfügbarkeitsgruppe mit automatischem Seeding mit Transact-SQL oder SQL Server Management Studio (SSMS, Version 17 oder höher). Befolgen Sie diese Anweisungen, um den Assistenten für Verfügbarkeitsgruppen in SSMS zu verwenden. Bei Schritt 9 wird das automatische Seeding als erste und Standardoption angezeigt.
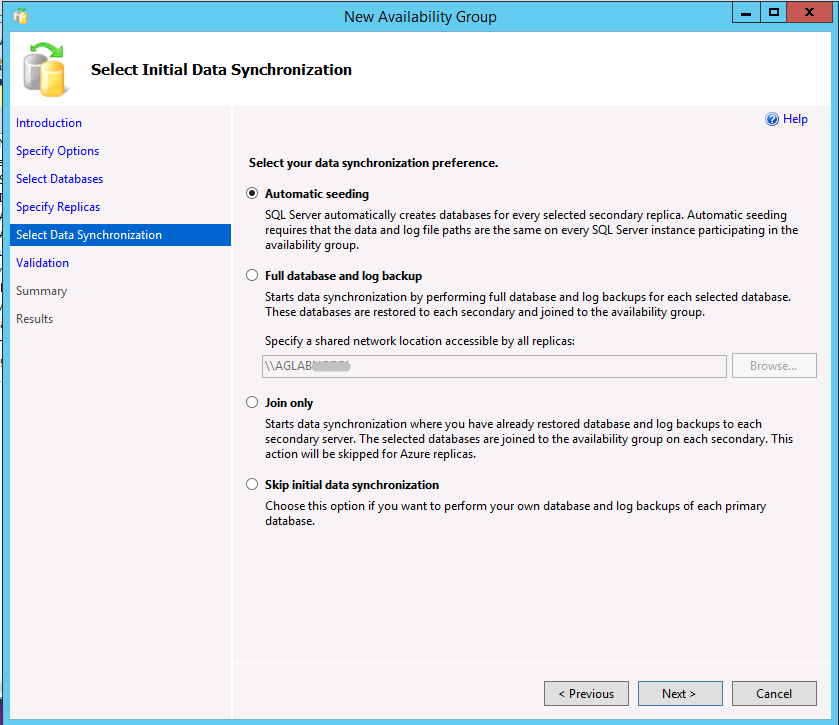
Im folgenden Beispiel wird eine Verfügbarkeitsgruppe mit automatischem Seeding mithilfe von Transact-SQL erstellt. Siehe auch Erstellen einer Verfügbarkeitsgruppe (Transact-SQL). Das Seeding für ein sekundäres Replikat wird aktiviert, indem Sie die Option SEEDING_MODE auf AUTOMATIC festlegen. Das Standardverhalten ist MANUAL und somit das Verhalten von Vorgängerversionen von SQL Server 2016 und erfordert eine Sicherung der Datenbank auf dem primären Replikat, eine Kopie der Sicherungsdatei auf das sekundäre Replikat und eine Wiederherstellung der Sicherung WITH NORECOVERY.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
Das Festlegen von SEEDING_MODE auf einem primären Replikat während einer CREATE AVAILABILITY GROUP-Anweisung hat keine Auswirkung, da das primäre Replikat bereits die Hauptlese-/Schreibkopie der Datenbank enthält. SEEDING_MODE würde nur angewendet werden, wenn ein anderes Replikat zum primären würde und eine Datenbank hinzugefügt würde. Der Seedingmodus kann später geändert werden. Siehe dazu Ändern des Seedingmodus eines Replikats.
Sobald auf einer Instanz, die zum sekundären Replikat wird, die Verknüpfung erfolgt, wird folgende Meldung zum SQL Server-Protokoll hinzugefügt:
Dem lokalen Verfügbarkeitsreplikat der Verfügbarkeitsgruppe „AGName“ wurde nicht die Berechtigung zum Erstellen von Datenbanken erteilt, aber
SEEDING_MODEist aufAUTOMATICfestgelegt. Verwenden Sie den BefehlALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASE, um das Erstellen von Datenbanken zuzulassen, für die vom primären Verfügbarkeitsreplikat ein Seeding ausgeführt wird.
Erteilen der Berechtigung zum Erstellen von Datenbanken auf dem sekundären Replikat von Verfügbarkeitsgruppen
Erteilen Sie der Verfügbarkeitsgruppe nach dem Hinzufügen die Berechtigung zum Erstellen von Datenbanken auf der sekundären Replikatinstanz von SQL Server. Die Verfügbarkeitsgruppe benötigt die Berechtigung zum Erstellen von Datenbanken, damit das automatische Seeding funktioniert.
Tipp
Wenn die Verfügbarkeitsgruppe eine Datenbank für ein sekundäres Replikat erstellt, legt sie „sa“ (genauer gesagt, das Konto mit der SID 0x01) als Besitzer der Datenbank fest.
Verwenden Sie ALTER AUTHORIZATION, um den Datenbankbesitzer zu ändern, nachdem ein sekundäres Replikat automatisch eine Datenbank erstellt hat. Siehe ALTER AUTHORIZATION (Transact-SQL).
Im folgenden Beispiel wird diese Berechtigung an eine Verfügbarkeitsgruppe namens „AGName“ erteilt.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
Legen Sie bei Bedarf den Datenbankbesitzer des sekundären Replikats fest.
Überprüfen des automatischen Seedings
Bei erfolgreicher Ausführung wird die Datenbank/werden die Datenbanken auf dem sekundären Replikat automatisch erstellt und weist/weisen einen der folgenden beiden Status auf:
- SYNCHRONIZED (SYNCHRONISIERT), wenn das sekundäre Replikat so konfiguriert ist, dass es synchron ist, und die Daten synchronisiert werden.
- SYNCHRONIZING (WIRD SYNCHRONISIERT), wenn das sekundäre Replikat mit asynchroner Datenverschiebung konfiguriert wird oder wenn es mit synchroner Datenverschiebung synchronisiert wird, aber noch nicht mit dem primären Replikat synchronisiert wurde.
Zusätzlich zur unten beschriebenen dynamischen Verwaltungssicht werden Beginn und Abschluss des automatischen Seedings im SQL Server-Protokoll angezeigt:

Kombinieren von Sicherung und Wiederherstellung mit automatischem Seeding
Es ist möglich, das herkömmliche Sichern, Kopieren und Wiederherstellen mit automatischem Seeding zu kombinieren. Stellen Sie in diesem Fall zuerst die Datenbank auf einem sekundären Replikat wieder her, einschließlich aller verfügbaren Transaktionsprotokolle. Aktivieren Sie beim Erstellen der Verfügbarkeitsgruppe als Nächstes das automatische Seeding, um die Datenbank des sekundären Replikats „einzuholen“, als ob eine Sicherung des Protokollfragments wiederhergestellt würde (siehe Protokollfragmentsicherungen (SQL Server)).
Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe mit automatischem Seeding
Sie können mit automatischem Seeding mit Transact-SQL oder SQL Server Management Studio (SSMS, Version 17 oder höher) eine Datenbank zu einer Verfügbarkeitsgruppe hinzufügen.
Wenn das sekundäre Replikat das automatische Seeding verwendet hat, als es zur Verfügbarkeitsgruppe hinzugefügt wurde, muss weiter nichts unternommen werden. Wenn das sekundäre Replikat „Sichern“, „Kopieren“ und „Wiederherstellen“ verwendet hat, ändern Sie zuerst den Seedingmodus (siehe nächster Abschnitt). Verwenden Sie beim Hinzufügen der Datenbank dann die GRANT-Anweisung. Siehe dazu Verfügbarkeitsgruppe – Hinzufügen einer Datenbank.
Ändern des Seedingmodus eines Replikats
Der Seedingmodus eines Replikats kann geändert werden, nachdem die Verfügbarkeitsgruppe erstellt wurde, und das automatische Seeding kann so aktiviert oder deaktiviert werden. Das Aktivieren des automatischen Seedings nach dem Erstellen ermöglicht, dass eine Datenbank zur Verfügbarkeitsgruppe hinzugefügt werden kann, die automatisches Seeding verwendet, wenn Sie mit Sichern, Kopieren und Wiederherstellen erstellt wurde. Beispiel:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
Verwenden Sie zum Deaktivieren des automatischen Seedings den Wert „MANUAL“ (MANUELL).
Verhindern des automatischen Seedings, nachdem eine Verfügbarkeitsgruppe erstellt wurde
Wenn Sie das automatische Seeding für ein sekundäres Replikat nicht vollständig deaktivieren, aber vorübergehend vermeiden möchten, dass das sekundäre Replikat automatisch Datenbanken erstellen kann, müssen Sie der Verfügbarkeitsgruppe die „CREATE“-Berechtigung verweigern. Dies ist der Fall, wenn eine neue Datenbank der Verfügbarkeitsgruppe hinzugefügt wird, aber die Verfügbarkeitsgruppe die Datenbank nicht auf einem sekundären Replikat erstellen können soll.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Überwachen des automatischen Seedings
Es gibt vier Arten der Überwachung und Problembehandlung des automatischen Seedings:
- SQL Server-Protokoll wie bereits beschrieben
- Dynamische Verwaltungssichten
- Tabellen mit Sicherungsverläufen
- Erweiterte Ereignisse
Dynamische Verwaltungssichten
Es gibt zwei dynamische Verwaltungsansichten (DMVs) zum Überwachen des Seedings: sys.dm_hadr_automatic_seeding und sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingenthält den allgemeinen Status des automatischen Seedings und speichert den Verlauf bei jeder Ausführung (ob erfolgreich oder nicht). Die Spaltecurrent_stateweist entweder den Wert „COMPLETED“ oder „FAILED“ auf. Verwenden Sie bei dem Wert „FAILED“ den Wert infailure_state_desczur Diagnose des Problems. Möglicherweise müssen Sie dies mit dem Inhalt des SQL Server-Protokolls kombinieren, um den Fehler zu finden. Diese DMV wird auf dem primären Replikat und allen sekundären Replikaten aufgefüllt.sys.dm_hadr_physical_seeding_statszeigt den Status des automatischen Seedings bei der Ausführung an. Wie beisys.dm_hadr_automatic_seedingwird ein Wert für die primären und sekundären Replikate zurückgegeben, der Verlauf wird jedoch nicht gespeichert. Die Werte gelten nur für die aktuelle Ausführung und werden nicht gespeichert. Die relevanten Spalten sindstart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_ms,total_network_wait_time_msund, falls der Seedingvorgang fehlschlägt, „failure_message“.
Tabellen mit Sicherungsverläufen
Das automatische Seeding erstellt auch Einträge in den msdb-Tabellen, die den Verlauf für Sicherungen und Wiederherstellungen speichern. Auf dem sekundären Replikat, das das automatische Seeding empfängt, verfügt die Spalte „physical_device_name“ der backupmediafamily-Tabelle über eine GUID für ihren Wert, und der entsprechende Eintrag in backupset enthält den Namen des primären Replikats für „server_name“ und „machine_name“.
Erweiterte Ereignisse
Das automatische Seeding fügt neue erweiterte Ereignisse zum Nachverfolgen von Statistiken zu Statusänderungen, Fehlern und Leistung während der Initialisierung hinzu. Das folgende Skript erstellt z.B. eine Sitzung für erweiterte Ereignisse, die Ereignisse im Zusammenhang mit automatischem Seeding erfasst.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
Die folgende Tabelle enthält erweiterte Ereignisse, die sich auf automatisches Seeding beziehen.
| Name | BESCHREIBUNG |
|---|---|
| hadr_db_manager_seeding_request_msg | Seedinganforderungsnachricht. |
| hadr_physical_seeding_backup_state_change | Statusänderung auf der Sicherungsseite für das physische Seeding. |
| hadr_physical_seeding_restore_state_change | Statusänderung auf der Wiederherstellungsseite für das physische Seeding. |
| hadr_physical_seeding_forwarder_state_change | Statusänderung auf der Weiterleitungsseite für das physische Seeding. |
| hadr_physical_seeding_forwarder_target_state_change | Statusänderung auf der Zielseite der Weiterleitung für das physische Seeding. |
| hadr_physical_seeding_submit_callback | Senderückrufereignis für das physische Seeding. |
| hadr_physical_seeding_failure | Fehlerereignis für das physische Seeding. |
| hadr_physical_seeding_progress | Statusereignis für das physische Seeding. |
| hadr_physical_seeding_schedule_long_task_failure | Fehlerereignis für langen Task im Zeitplan für das physische Seeding. |
| hadr_automatic_seeding_start | Tritt beim Senden eines automatischen Seedingvorgangs auf. |
| hadr_automatic_seeding_state_transition | Tritt beim Statuswechsel eines automatischen Seedingvorgangs auf. |
| hadr_automatic_seeding_success | Tritt beim Erfolg eines automatischen Seedingvorgangs auf. |
| hadr_automatic_seeding_failure | Tritt bei einem Fehler eines automatischen Seedingvorgangs auf. |
| hadr_automatic_seeding_timeout | Tritt beim Timeout eines automatischen Seedingvorgangs auf. |
Weitere Informationen
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
Handbuch zur Problembehandlung und Überwachung von Always On-Verfügbarkeitsgruppen