Mechanismen und Richtlinien der Timeouts für Leases, Cluster und Integritätsprüfung für Always On-Verfügbarkeitsgruppen
Unterschiedliche Hardware-, Software- und Clusterkonfigurationen sowie unterschiedliche Anwendungsanforderungen in Bezug auf Leistung und Betriebszeit erfordern eine spezifische Konfiguration der Timeoutwerte für Lease, Cluster und Integritätsprüfung. Für bestimmte Anwendungen und Arbeitsauslastungen ist eine striktere Überwachung erforderlich, um Ausfallzeiten infolge schwerer Fehler zu begrenzen. Andere erfordern eine größere Toleranz gegenüber vorübergehenden Netzwerkproblemen und Wartezeiten aufgrund hoher Ressourcennutzung und sind für langsameres Failover geeignet.
Es werden mehrere Dienste auf den einzelnen Knoten zum Erkennen von Fehlern eingesetzt. Der Clusterdienst kann einen Quorumsverlust erkennen, die Ressourcen-DLL kann ein Problem erkennen, das durch die Always On-Integritätserkennung zum Vorschein kommt, oder es kann ein manuelles Failover direkt auf der primären Instanz initiiert werden. Der Clusterdienst, der Ressourcenhost und die SQL Server-Instanz werden über RPC, Shared Memory und T-SQL miteinander synchronisiert. In den meisten Szenarien findet eine erfolgreiche Kommunikation dieser Dienste statt, doch ist diese Kommunikation selbst zwischen Diensten auf demselben Computer nicht hundertprozentig zuverlässig. Darüber hinaus muss die Verfügbarkeitsgruppe (availability group, AG) systemweiten Ereignissen wie Netzwerk- und Datenträgerfehlern standhalten können, durch die eine Kommunikation verhindert oder Funktionen unterbrochen werden. Bei Auftreten vieler Fehler und ohne hundertprozentig zuverlässige Kommunikation zwischen den Diensten ist die Verfügbarkeitsgruppe von verschiedenen Erkennungsmechanismen für das Failover abhängig, damit Fehler unabhängig voneinander erkannt werden und darauf reagiert wird, sodass der Clusterstatus immer für alle Knoten konsistent ist.
Erkennung von Clusterknoten und -ressourcen
Auf jedem Knoten im Cluster wird ein einzelner Clusterdienst ausgeführt, der mit dem Failovercluster zusammenarbeitet und alle Clusterressourcen überwacht. Der Ressourcenhost funktioniert als separater Prozess und stellt die Schnittstelle zwischen dem Clusterdienst und den Clusterressourcen dar. Der Ressourcenhost führt Vorgänge für Clusterressourcen aus, wenn er vom Clusterdienst dazu aufgerufen wird. Clusterfähige Anwendungen wie SQL Server bieten benutzerdefinierte Schnittstellen zum Ressourcenmonitor über Ressourcen-DLLs. Die Ressourcen-DLL implementiert Online- und Offlinevorgänge sowie eine Integritätsüberwachung für benutzerdefinierte Ressourcen. Beim Ressourcenhost handelt es sich um einen untergeordneten Prozess des Clusterdiensts, der beendet wird, sobald der Clusterdienst beendet wird.
Bei SQL Server bestimmt die Ressourcen-DLL der Verfügbarkeitsgruppe den Zustand der Gruppe auf Grundlage des jeweiligen Leasemechanismus und der Always On-Integritätserkennung. Die Ressourcen-DLL der Verfügbarkeitsgruppe stellt die Ressourcenintegrität über den IsAlive-Vorgang bereit. Der Ressourcenmonitor fragt IsAlive im Taktintervall des Clusters ab, das durch die clusterübergreifenden Werte CrossSubnetDelay und SameSubnetDelay festgelegt ist. Auf einem primären Knoten initiiert der Clusterdienst immer dann ein Failover, wenn der IsAlive-Aufruf an die Ressourcen-DLL zurückgibt, dass die Verfügbarkeitsgruppe nicht fehlerfrei ist.
Der Clusterdienst sendet Takte an andere Knoten im Cluster und bestätigt Takte, die er von diesen empfängt. Wenn ein Knoten aufgrund einer Reihe unbestätigter Takte einen Kommunikationsfehler erkennt, sendet er eine Nachricht, damit alle erreichbare Knoten ihre Sichten der Clusterknotenintegrität abstimmen. Dieses Ereignis wird Neugruppierungsereignis genannt und bewahrt die Konsistenz des Clusterstatus auf allen Knoten. Wenn nach einem Neugruppierungsereignis das Quorum verloren gegangen ist, werden alle Clusterressourcen, einschließlich der Verfügbarkeitsgruppen in dieser Partition, offline geschaltet. Alle Knoten in dieser Partition gehen in einen Auflösungsstatus über. Wenn eine Partition vorhanden ist, die ein Quorum enthält, wird die Verfügbarkeitsgruppe einem Knoten in der Partition zugewiesen und wird zum primären Replikat, während es sich bei allen anderen Knoten um sekundäre Replikate handelt.
Always On-Integritätserkennung
Die Always On-Ressourcen-DLL überwacht den Status interner SQL Server-Komponenten. sp_server_diagnostics meldet die Integrität dieser SQL Server-Komponenten in einem durch HealthCheckTimeout gesteuerten Intervall. sp_server_diagnostics meldet den Integritätsstatus von fünf Komponenten auf Instanzebene: System, Ressource, Abfrageverarbeitung, E/A-Subsystem und Ereignisse. Außerdem wird die Integrität jeder Verfügbarkeitsgruppe gemeldet. Bei jeder Aktualisierung aktualisiert die Ressourcen-DLL den Integritätsstatus der Verfügbarkeitsgruppenressource basierend auf der Fehlerebene der Verfügbarkeitsgruppe. Bei der Rückgabe von Daten von sp_server_diagnostics ist für jede Komponente ein Status vom Typ Fehlerfrei, Warnung, Fehler oder Unbekannt mit einigen XML-Daten angegeben, die den Status der Komponente beschreiben. Im Falle der Integritätserkennung ergreift die Ressourcen-DLL nur dann Maßnahmen, wenn eine Komponente einen Fehlerstatus aufweist.
Wenn die Integritätserkennung der Ressourcen-DLL über mehrere Intervalle keine Aktualisierung meldet, wird die Verfügbarkeitsgruppe als fehlerhaft erkannt, und es werden Fehler in IsAlive-Aufrufen gemeldet.
Leasemechanismus
Im Gegensatz zu anderen Failovermechanismen spielt die SQL Server-Instanz beim Leasemechanismus eine aktive Rolle. Der Leasemechanismus wird als Looks-Alive-Validierung zwischen dem Clusterressourcenhost und dem SQL Server-Prozess verwendet. Der Mechanismus dient der Sicherstellung, dass die beiden Seiten (Cluster- und SQL Server-Dienst) in häufigem Kontakt stehen, den Zustand des jeweils anderen überprüfen und schließlich ein Split-Brain-Szenario verhindern. Wenn die Verfügbarkeitsgruppe als primäres Replikat online geschaltet wird, erzeugt die SQL Server-Instanz einen dedizierten Leaseworkerthread für die Verfügbarkeitsgruppe. Der Leaseworker teilt sich einen kleinen Bereich des Speichers mit dem Ressourcenhost, der die Ereignisse für Leaseverlängerung und Leasebeendigung enthält. Der Leaseworker und der Ressourcenhost arbeiten kreisförmig, indem sie das jeweilige Leaseverlängerungsereignis signalisieren und dann im Ruhezustand darauf warten, dass die andere Seite das eigene Leaseverlängerungsereignis oder das Beendigungsereignis signalisiert. Sowohl der Ressourcenhost als auch der SQL Server-Leasethread besitzen einen Wert für die Gültigkeitsdauer, der jedes Mal dann aktualisiert wird, wenn der Thread nach der Signalisierung durch den anderen Thread aktiviert wird. Wenn beim Warten auf das Signal die Gültigkeitsdauer erreicht wird, läuft die Lease ab und das Replikat geht dann in den Auflösungsstatus für die jeweilige Verfügbarkeitsgruppe über. Wenn das Leasebeendigungsereignis signalisiert wird, geht das Replikat in eine Auflösungsrolle über.
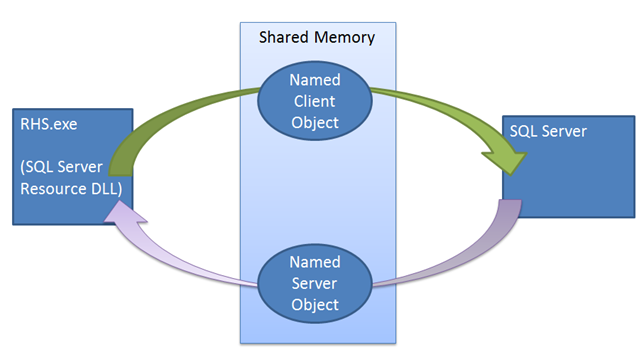
Der Leasemechanismus erzwingt die Synchronisierung zwischen SQL Server und Windows Server-Failovercluster. Bei Ausgabe eines Failoverbefehls sendet der Clusterdienst einen Offline-Aufruf an die Ressourcen-DLL des aktuellen primären Replikats. Die Ressourcen-DLL versucht zunächst, die Verfügbarkeitsgruppe mithilfe einer gespeicherten Prozedur offline zu schalten. Wenn bei dieser gespeicherten Prozedur ein Fehler oder ein Timeout auftritt, wird dies dem Clusterdienst zurückgemeldet, der dann einen Befehl zum Beenden ausgibt. Bei diesem Befehl wird erneut versucht, dieselbe gespeicherte Prozedur auszuführen, doch wartet der Cluster diesmal nicht, dass die Ressourcen-DLL einen Erfolg oder Fehler meldet, bevor die Verfügbarkeitsgruppe auf einem neuen Replikat online geschaltet wird. Wenn dieser zweite Prozeduraufruf fehlschlägt, muss sich der Ressourcenhost darauf verlassen, dass die Instanz vom Leasemechanismus offline geschaltet wird. Wenn die Ressourcen-DLL zum Offlineschalten der Verfügbarkeitsgruppe aufgerufen wird, signalisiert die Ressourcen-DLL das Leasebeendigungsereignis und aktiviert dadurch den SQL Server-Leaseworkerthread, um die Verfügbarkeitsgruppe offline zu schalten. Auch wenn dieses Beendigungsereignis nicht signalisiert wird, läuft die Lease ab und das Replikat geht in den Auflösungsstatus über.
Die Lease ist in erster Linie ein Synchronisierungsmechanismus zwischen der primären Instanz und dem Cluster, sie kann aber auch dort Fehlerbedingungen erzeugen, wo sonst kein Failover erforderlich wäre. Beispielsweise können hohe CPU-Werte, Situation mit fehlendem Arbeitsspeicher (wenig virtueller Arbeitsspeicher, Prozesspaging), SQL-Prozesse, die beim Erzeugen eines Speicherabbilds nicht reagieren, ein nicht reagierendes System, oder ein Cluster (WSFC), der offline geht (z. B. wegen Quorumverlust), die Verlängerung der Lease-Dauer durch die SQL-Instanz verhindern und einen Neustart oder ein Failover verursachen.
Richtlinien für Timeoutwerte des Clusters
Wägen Sie die Vor- und Nachteile sorgfältig ab, und machen Sie sich die Konsequenzen einer weniger strikten Überwachung des SQL Server-Clusters bewusst. Durch höhere Timeoutwerte des Clusters ergibt sich eine größere Toleranz gegenüber vorübergehenden Netzwerkproblemen, doch verlangsamt sich gleichzeitig die Reaktion auf schwerwiegende Fehler. Werden höhere Timeoutwerte für den Fall einer Ressourcenüberlastung oder hoher geografischer Latenz verwendet, verlängert sich auch die Zeit für die Wiederherstellung nach schwerwiegenden oder nicht behebbaren Fehlern. Zwar ist dies bei vielen Anwendungen akzeptabel, jedoch nicht in allen Fällen die optimale Lösung.
Die Standardeinstellungen werden für schnelles Reagieren auf Symptome schwerwiegender Fehler und eine Begrenzung von Ausfallzeiten optimiert, doch können diese Einstellungen für bestimmte Arbeitslasten und Konfigurationen zu strikt sein. Es wird nicht empfohlen, LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold oder HealthCheckTimeout auf Werte unterhalb der Standardwerte zu setzen. Die jeweils richtigen Einstellungen für eine Bereitstellung variieren und ergeben sich wahrscheinlich erst nach einem längeren Optimierungszeitraum. Nehmen Sie Änderungen an diesen Werten nur schrittweise und unter Berücksichtigung der Beziehungen und Abhängigkeiten vor, die zwischen diesen Werten bestehen.
Beziehung zwischen Timeouts für Cluster und Lease
Die primäre Funktion des Leasemechanismus besteht darin, die SQL Server-Ressource dann offline zu nehmen, wenn der Clusterdienst nicht mit der Instanz kommunizieren kann, während ein Failover zu einem anderen Knoten erfolgt. Wenn der Cluster den Offlinevorgang auf der Clusterressource der Verfügbarkeitsgruppe ausführt, sendet der Clusterdienst einen RPC-Aufruf an „rhs.exe“ zum Offlineschalten der Ressource. Die Ressourcen-DLL verwendet gespeicherte Prozeduren, um SQL Server anzuweisen, die Verfügbarkeitsgruppe offline zu schalten, doch kann bei dieser gespeicherten Prozedur ein Fehler oder Timeout auftreten. Der Ressourcen-Host stoppt während des Offline-Aufrufs auch seinen eigenen Lease Renewal Thread. Im ungünstigsten Fall bewirkt SQL Server ein Ablaufen der Lease nach dem halben * LeaseTimeout und führt zum Übergang der Instanz in einen Auflösungsstatus. Failover können von mehreren verschiedenen Seiten aus initiiert werden, doch ist es äußerst wichtig, dass die Sicht des Clusterstatus im gesamten Cluster und auf allen SQL Server-Instanzen konsistent ist. Stellen Sie sich beispielsweise ein Szenario vor, in dem die primäre Instanz die Verbindung mit dem restlichen Cluster verliert. Aufgrund der Timeoutwerte des Clusters ermittelt jeder Knoten im Cluster zur gleichen Zeit einen Fehler, doch kann nur der primäre Knoten mit der primären SQL Server-Instanz interagieren, um ein Aufgeben der primären Rolle zu erzwingen.
Aus Sichtweise des primären Knotens hat der Clusterdienst das Quorum verloren, und der Dienst beginnt sich selbst zu beenden. Der Clusterdienst gibt einen RPC-Aufruf an den Ressourcenhost zum Beenden des Prozesses aus. Dieser Beendigungsaufruf sorgt dafür, dass die Verfügbarkeitsgruppe auf der SQL Server-Instanz offline geschaltet wird. Dieser Offlineaufruf erfolgt über T-SQL, kann jedoch nicht gewährleisten, dass die Verbindung zwischen SQL und der Ressourcen-DLL erfolgreich hergestellt wird.
Aus Sicht des restlichen Clusters gibt es derzeit kein primäres Replikat, also stimmt der Cluster ab und legt ein einziges neues primäres Replikat für die verbleibenden Knoten im Cluster fest. Wenn bei der von der Ressourcen-DLL aufgerufenen gespeicherten Prozedur ein Fehler oder Timeout auftritt, könnte es beim Cluster zu einem Split-Brain-Szenario kommen.
Durch das Timeout für die Lease werden Split-Brain-Szenarien bei Kommunikationsfehlern verhindert. Selbst wenn die gesamte Kommunikation fehlschlägt, wird der Prozess der Ressourcen-DLL beendet und die Lease kann nicht aktualisiert werden. Nach Ablauf der Lease wird die Verfügbarkeitsgruppe eigenständig offline geschaltet. Die SQL Server-Instanz muss erkennen, dass sie nicht mehr das primäre Replikat hostet, bevor der Cluster ein neues Replikat erstellt. Da der restliche Cluster, der für das Auswählen eines neuen primären Replikats zuständig ist, keine Möglichkeit zur Koordination mit dem aktuellen primären Replikat hat, wird durch die Timeoutwerte sichergestellt, dass ein neues primäres Replikat erst dann erstellt wird, wenn sich das aktuelle primäre Replikat offline geschaltet hat.
Bei einem Failover des Clusters muss die SQL Server-Instanz, auf der das vorherige primäre Replikat gehostet ist, in einen Auflösungsstatus übergehen, bevor das neue primäre Replikat online geschaltet wird. Der SQL Server-Lease-Thread weist jederzeit eine verbleibende Gültigkeitsdauer von ½ * des LeaseTimeout auf, da bei jeder Verlängerung der Lease die neue Gültigkeitsdauer auf LeaseInterval oder ½ * LeaseTimeout aktualisiert wird. Wenn der Clusterdienst oder der Ressourcenhost stoppt oder beendet wird, ohne das Leasebeendigungsereignis zu signalisieren, deklariert der Cluster den primären Knoten nach SameSubnetThreshold\ SameSubnetDelay Millisekunden als inaktiv. Innerhalb dieses Zeitraums muss die Lease ablaufen, damit sichergestellt ist, dass das primäre Replikat offline geschaltet ist. Da die maximale Gültigkeitsdauer für das Timeout der Lease ½ * LeaseTimeout ist, muss ½ LeaseTimeout weniger als SameSubnetThreshold * SameSubnetDelay betragen.
SameSubnetThreshold \<= CrossSubnetThreshold und SameSubnetDelay \<= CrossSubnetDelay sollte für alle SQL Server-Cluster zutreffen.
Funktionsweise des Timeouts für die Integritätsprüfung
Das Timeout für die Integritätsprüfung ist flexibler, da kein anderer Failovermechanismus direkt davon abhängt. Beim Standardwert von 30 Sekunden ist das sp_server_diagnostics-Intervall auf 10 Sekunden festgelegt, mit einem Mindestwert von 15 Sekunden für das Timeout und einem Intervall von 5 Sekunden. Allgemeiner ausgedrückt: Das sp_server_diagnostics-Aktualisierungsintervall beträgt immer 1/3 * HealthCheckTimeout. Wenn die Ressourcen-DLL in einem Intervall keinen neuen Satz von Integritätsdaten erhält, verwendet sie weiterhin die Integritätsdaten aus dem vorherigen Intervall, um die aktuelle Verfügbarkeitsgruppe und den Zustand der Instanz zu ermitteln. Durch einen höheren Timeoutwert für die Integritätsprüfung, weist das primäre Replikat eine größere Toleranz gegenüber der CPU-Auslastung auf, wodurch sp_server_diagnostics daran gehindert werden kann, in jedem Intervall neue Daten bereitzustellen, jedoch werden für einen längeren Zeitraum Integritätsprüfungen auf Grundlage veralteter Daten durchgeführt. Unabhängig vom Timeoutwert geschieht Folgendes: Sobald Daten empfangen werden, die darauf hinweisen, dass das Replikat nicht fehlerfrei ist, wird im nächsten IsAlive-Aufruf zurückgegeben, dass die Instanz fehlerhaft ist, und der Clusterdienst initiiert ein Failover.
Die Fehlerbedingungsebene der Verfügbarkeitsgruppe ändert die Fehlerbedingungen für die Integritätsprüfung. Für jede Fehlerebene gilt: Wenn das Verfügbarkeitsgruppenelement von sp_server_diagnostics als fehlerhaft gemeldet wird, schlägt die Integritätsprüfung fehl. Jede Ebene übernimmt alle Fehlerbedingungen der darunter liegenden Ebenen.
| Ebene | Bedingung, unter der die Instanz als inaktiv betrachtet wird |
|---|---|
| 1: OnServerDown | Die Integritätsprüfung führt keine Aktion aus, wenn Fehler bei anderen Ressourcen als der Verfügbarkeitsgruppe auftreten. Wenn innerhalb von 5 Intervallen oder 5/3 * HealthCheckTimeout keine Verfügbarkeitsgruppendaten eintreffen |
| 2: OnServerUnresponsive | Wenn keine Daten von sp_server_diagnostics für HealthCheckTimeout empfangen werden. |
| 3: OnCriticalServerError | (Standardeinstellung) Wenn die Systemkomponente einen Fehler meldet. |
| 4: OnModerateServerError | Wenn die Ressourcenkomponente einen Fehler meldet. |
| 5: OnAnyQualifiedFailureConitions | Wenn die Abfrageverarbeitungskomponente einen Fehler meldet. |
Aktualisieren von Timeoutwerten für Cluster und Always On
Clusterwerte
Es gibt vier Werte in der WSFC-Konfiguration, die zur Bestimmung von Timeoutwerten für den Cluster herangezogen werden:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
Die Verzögerungswerte bestimmen die Wartezeit zwischen Takten vom Clusterdienst. Die Schwellenwerte legen die Anzahl der Takte fest, die keine Bestätigung vom Zielknoten oder der Ressource empfangen können, bevor das Objekt vom Cluster als inaktiv deklariert wird. Erfolgt für mehr als SameSubnetDelay \* SameSubnetThreshold Millisekunden kein erfolgreicher Takt zwischen Knoten im gleichen Subnetz, wird der Knoten als inaktiv erkannt. Dasselbe gilt für die Kommunikation im gesamten Subnetz unter Verwendung subnetzübergreifender Werte.
Zum Auflisten aller aktuellen Clusterwerte öffnen Sie auf einem beliebigen Knoten im Zielcluster einen PowerShell-Terminal mit erhöhten Rechten. Führen Sie den folgenden Befehl aus:
Get-Cluster | fl *
Um einen dieser Werte zu aktualisieren, führen Sie den folgenden Befehl auf einem PowerShell-Terminal mit erhöhten Rechten aus:
(Get-Cluster).<ValueName> = <NewValue>
Wenn Sie das Produkt aus Verzögerung * Schwellenwert erhöhen, damit das Timeout für den Cluster eine größere Toleranz aufweist, ist es effektiver, zuerst den Verzögerungswert und erst dann den Schwellenwert zu erhöhen. Durch einen höheren Verzögerungswert wird der Zeitraum zwischen den einzelnen Takten verlängert. Ein längerer Zeitraum zwischen den Takten bietet mehr Zeit, damit sich vorübergehende Netzwerkprobleme von selbst lösen können, und verringert eine Netzwerküberlastung im Vergleich zum Senden von mehr Takten im gleichen Zeitraum.
Timeout für Lease
Der Leasemechanismus wird durch einen einzelnen Wert gesteuert, der für jede Verfügbarkeitsgruppe in einem WSFC-Cluster spezifisch ist. Ein Leasetimeout kann zu den folgenden Fehlern führen:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
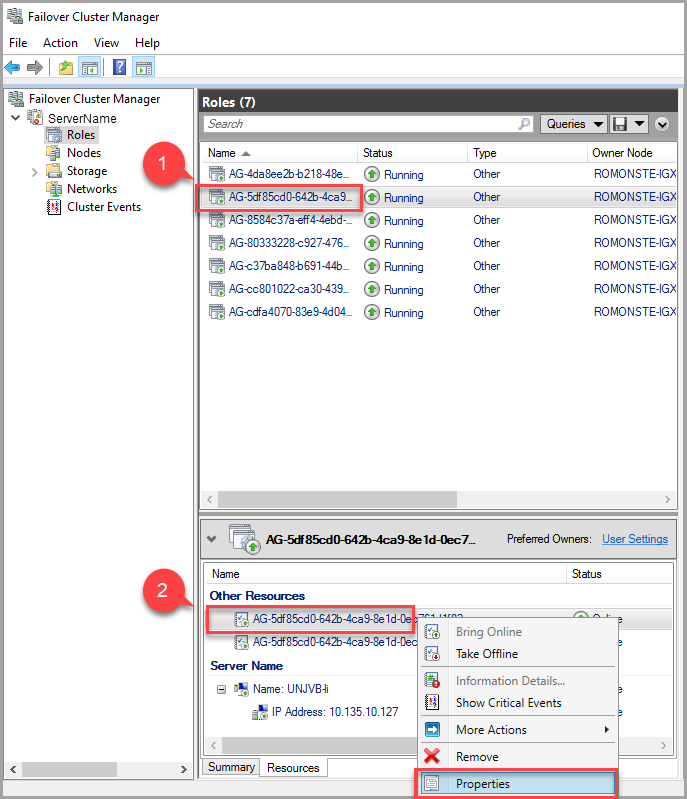
Verwenden Sie zum Ändern des Leasetimeout-Werts den Failovercluster-Manager, und führen Sie die folgenden Schritte aus:
Suchen Sie auf der Registerkarte „Rollen“ nach der Rolle der Zielverfügbarkeitsgruppe. Wählen Sie die Rolle der Ziel-VG-Rolle aus.
Klicken Sie mit der rechten Maustaste auf die Verfügbarkeitsgruppenressource am unteren Rand des Fensters, und wählen Sie Eigenschaften aus.
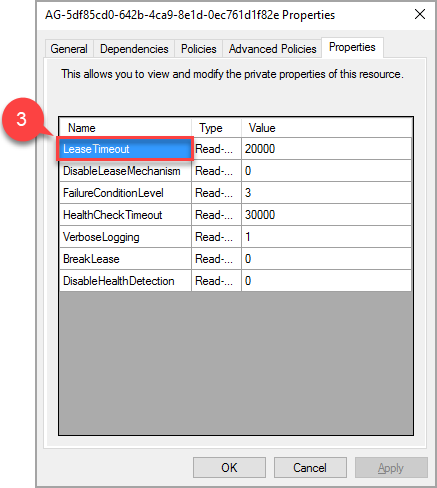
Navigieren Sie im Popupfenster zur Registerkarte Eigenschaften, um eine Liste spezifischer Werte für diese Verfügbarkeitsgruppe zu sehen. Wählen Sie den LeaseTimeout-Wert aus, um ihn zu ändern.
Je nach Konfiguration der Verfügbarkeitsgruppe sind möglicherweise zusätzliche Ressourcen für Listener, freigegebene Datenträger, Dateifreigaben usw. vorhanden. Diese Ressourcen erfordern keine zusätzliche Konfiguration.
Hinweis
Der neue Wert der Eigenschaft „LeaseTimeout“ wird wirksam, nachdem die Ressource offline und wieder online geschaltet wurde.
Werte für die Integritätsprüfung
Zwei Werte steuern die Always On-Integritätsprüfung: FailureConditionLevel und HealthCheckTimeout. FailureConditionLevel gibt die Toleranzstufe für bestimmte Fehlerbedingungen an, die von sp_server_diagnostics gemeldet werden. HealthCheckTimeout legt den Zeitraum fest, über den die Ressourcen-DLL keine Aktualisierung von sp_server_diagnostics empfangen muss. Das Aktualisierungsintervall für sp_server_diagnostics ist immer HealthCheckTimeout / 3.
Verwenden Sie zum Konfigurieren der Failoverbedingungsebene die Option FAILURE_CONDITION_LEVEL = <n> der Anweisung CREATE oder ALTER AVAILABILITY GROUP, wobei <n> eine ganze Zahl zwischen 1 und 5 ist. Mit dem folgenden Befehl wird die Fehlerbedingungsebene für die Verfügbarkeitsgruppe „AG1“ auf 1 festgelegt:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Verwenden Sie zum Konfigurieren des Timeouts für die Integritätsprüfung die Option HEALTH_CHECK_TIMEOUT der Anweisung CREATE oder ALTER AVAILABILITY GROUP. Mit dem folgenden Befehl wird das Timeout für die Integritätsprüfung für die Verfügbarkeitsgruppe AG1 auf 60.000 Millisekunden festgelegt:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Zusammenfassung der Richtlinien für Timeouts
Es wird davon abgeraten, Timeouts auf Werte unterhalb der Standardwerte zu setzen.
Das Lease-Intervall (½ * LeaseTimeout) muss kürzer als SameSubnetThreshold * SameSubnetDelay sein
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Timeouteinstellung | Zweck | Zwischen | Verwendung | IsAlive & LooksAlive | Ursachen | Ergebnis |
|---|---|---|---|---|---|---|
| Timeout für Lease Standard: 20000 |
Verhindert Split Brain | Vom primären Replikat auf den Cluster (HADR) |
Windows event objects (Windows-Ereignisobjekte) | Wird in beiden verwendet | Nicht reagierendes Betriebssystems, unzureichender virtueller Arbeitsspeicher, Arbeitssatzpaging, Generieren von Speicherabbildern, voll ausgelastete CPU, WSFC ist offline (Verlust des Quorums) | Verfügbarkeitsgruppenressource von offline zu online geschalten, dann wird ein Failover ausgeführt |
| Sitzungstimeout Standard: 10000 |
Melden von Kommunikationsproblemen zwischen dem primären und sekundären Replikat | Sekundäres Replikat auf primäres Replikat (HADR) |
TCP Sockets (messages sent via DBM endpoint) (TCP-Sockets (über einen DBM-Endpunkt gesendete Meldungen)) | In keinem von beiden verwendet | Netzwerkkommunikation, Probleme auf dem sekundären Replikat (offline), nicht reagierendes Betriebssystem, Ressourcenkonflikte |
Verbindung des sekundären Replikats wird getrennt |
| HealthCheck-Timeout Standard: 30000 |
Angeben von Timeouts, während die Integrität des primären Replikats ermittelt wird | Cluster auf primäres Replikat (FCI & HADR) |
T-SQL sp_server_diagnostics | Wird in beiden verwendet | Erfüllte Fehlerbedingungen, nicht reagierendes Betriebssystem, unzureichender virtueller Speicher, Kürzung des Arbeitssatzes, WSFC ist offline (Verlust des Quorums), Probleme mit dem Scheduler (Deadlock) | VG-Ressource wird von offline zu online geschaltet, oder es wird ein Failover dafür ausgeführt, FCI-Neustart oder -Failover |