Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server
Sie müssen zwei Verfügbarkeitsgruppen mit eigenen Listenern erstellen, um eine verteilte Verfügbarkeitsgruppe zu erstellen. Anschließend kombinieren Sie diese Verfügbarkeitsgruppen zu einer verteilten Verfügbarkeitsgruppe. Die folgenden Schritte stellen ein einfaches Beispiel in Transact-SQL dar. Dieses Beispiel deckt nicht alle Details zum Erstellen von Verfügbarkeitsgruppen und Listenern ab, stattdessen legt es den Schwerpunkt auf die Herausarbeitung der wichtigsten Anforderungen.
Eine technische Übersicht über verteilte Verfügbarkeitsgruppen finden Sie unter Verteilte Verfügbarkeitsgruppen.
Voraussetzungen
Um eine verteilte Verfügbarkeitsgruppe zu konfigurieren, müssen Sie folgende Voraussetzungen erfüllen:
- Eine unterstützte Version von SQL Server.
Hinweis
Wenn Sie den Listener für Ihre Verfügbarkeitsgruppe auf Ihrem SQL Server auf Azure VM mithilfe eines verteilten Netzwerknamens (Distributed Network Name, DNN) konfiguriert haben, wird die Konfiguration einer verteilten Verfügbarkeitsgruppe über Ihrer Verfügbarkeitsgruppe nicht unterstützt. Weitere Informationen finden Sie unter Featureinteroperabilität von SQL Server auf Azure VM mit AG und DNN-Listener.
Erlaubnisse
Erfordert die Berechtigung CREATE AVAILABILITY GROUP auf dem Server, um eine Verfügbarkeitsgruppe zu erstellen und sysadmin ein Failover einer verteilten Verfügbarkeitsgruppe durchzuführen.
Festlegen der Endpunkte für die Datenbankspiegelung, um auf alle IP-Adressen zu lauschen
Stellen Sie sicher, dass die Endpunkte für die Datenbankspiegelung zwischen den verschiedenen Verfügbarkeitsgruppen in der Verteilten Verfügbarkeitsgruppe kommunizieren können. Wenn eine Verfügbarkeitsgruppe auf ein bestimmtes Netzwerk auf dem Datenbankspiegelungsendpunkt festgelegt ist, funktioniert die verteilte Verfügbarkeitsgruppe nicht ordnungsgemäß. Legen Sie auf jedem Server, auf dem ein Replikat in der Gruppe "Verteilte Verfügbarkeit" gehostet wird, den Endpunkt für die Datenbankspiegelung so fest, dass er auf alle IP-Adressen (LISTENER_IP = ALL) lauscht.
Erstellen eines Datenbankspiegelungsendpunkts zum Überwachen aller IP-Adressen
Das folgende Skript erstellt beispielsweise einen neuen Datenbankspiegelungsendpunkt am TCP-Port 5022, der auf alle IP-Adressen lauscht.
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
Ändern eines vorhandenen Datenbankspiegelungsendpunkts zum Überwachen aller IP-Adressen
Das folgende Skript ändert z. B. einen vorhandenen Datenbankspiegelungsendpunkt so, dass er auf alle IP-Adressen lauscht.
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
Erstellen der ersten Verfügbarkeitsgruppe
Erstellen der ersten Verfügbarkeitsgruppe auf dem ersten Cluster
Erstellen Sie eine Verfügbarkeitsgruppe für den ersten Windows Server-Failovercluster (WSFC). In diesem Beispiel heißt die Verfügbarkeitsgruppe ag1 für die Datenbank db1. Das primäre Replikat der primären Verfügbarkeitsgruppe wird in einer verteilten Verfügbarkeitsgruppe als globales primäres Replikat bezeichnet. Server1 ist in diesem Beispiel das primäre Replikat.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Hinweis
Im vorherigen Beispiel wird automatisches Seeding verwendet, wobei SEEDING_MODE sowohl für die Replikate als auch für die verteilte Verfügbarkeitsgruppe auf AUTOMATIC festgelegt ist. Diese Konfiguration legt fest, dass die sekundären Replikate und sekundären Verfügbarkeitsgruppen automatisch aufgefüllt werden, ohne eine manuelle Sicherung und Wiederherstellung der primären Datenbank erforderlich zu machen.
Verknüpfen der sekundären Replikate mit der primären Verfügbarkeitsgruppe
Alle sekundären Replikate müssen mithilfe von ALTER AVAILABILITY GROUP mit der Option JOIN mit der Verfügbarkeitsgruppe verknüpft werden. Da in diesem Beispiel automatisches Seeding verwendet wird, müssen Sie außerdem ALTER AVAILABILITY GROUP mit der Option GRANT CREATE ANY DATABASE aufrufen. Diese Einstellung ermöglicht der Verfügbarkeitsgruppe, die Datenbank zu erstellen und mit dem automatischen Seeding aus dem ersten Replikat zu beginnen.
In diesem Beispiel werden die folgenden Befehle auf dem sekundären Replikat server2ausgeführt, um die Verknüpfung mit der Verfügbarkeitsgruppe ag1 herzustellen. Der Verfügbarkeitsgruppe ist es damit gestattet, Datenbanken auf dem sekundären Replikat zu erstellen.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Hinweis
Wenn die Verfügbarkeitsgruppe eine Datenbank auf einem sekundären Replikat erstellt, legt sie als Datenbankbesitzer das Konto fest, das die Anweisung ALTER AVAILABILITY GROUP ausgeführt hat, um die Berechtigung zum Erstellen von Datenbanken zu erteilen. Ausführliche Informationen finden Sie unter Grant create database permission on secondary replica to availability group (Erteilen der Berechtigung zum Erstellen von Datenbanken auf dem sekundären Replikat von Verfügbarkeitsgruppen).
Erstellen eines Listeners für die primäre Verfügbarkeitsgruppe
Fügen Sie im nächsten Schritt einen Listener für die primäre Verfügbarkeitsgruppe auf dem ersten WSFC hinzu. In diesem Beispiel hat der Listener den Namen ag1-listener. Weitere Informationen zum Erstellen eines Listeners finden Sie unter Erstellen oder Konfigurieren eines Verfügbarkeitsgruppenlisteners (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Erstellen der zweiten Verfügbarkeitsgruppe
Erstellen Sie anschließend auf dem zweiten WSFC eine zweite Verfügbarkeitsgruppe, ag2. In diesem Fall wird die Datenbank nicht angegeben, da sie automatisch aus der primären Verfügbarkeitsgruppe seediert wird. Das primäre Replikat der sekundären Verfügbarkeitsgruppe wird in einer verteilten Verfügbarkeitsgruppe als Weiterleitung bezeichnet. In diesem Beispiel ist Server3 die Weiterleitung.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Hinweis
- Die sekundäre Verfügbarkeitsgruppe muss denselben Endpunkt für die Datenbankspiegelung verwenden (in diesem Beispiel Port 5022). Andernfalls wird die Replikation nach einem lokalen Failover beendet.
- Die zugrunde liegenden Verfügbarkeitsgruppen sollten sich im gleichen Verfügbarkeitsmodus befinden – entweder sollten sich beide Verfügbarkeitsgruppen im synchronen Commitmodus befinden, oder beide sollten sich im asynchronen Commitmodus befinden. Wenn Sie nicht sicher sind, welche Option Sie verwenden sollen, stellen Sie beide auf den asynchronen Commit-Modus, bis Sie bereit sind, ein Failover durchzuführen.
Verknüpfen der sekundären Replikate mit der sekundären Verfügbarkeitsgruppe
In diesem Beispiel werden die folgenden Befehle auf dem sekundären Replikat server4ausgeführt, um die Verknüpfung mit der Verfügbarkeitsgruppe ag2 herzustellen. Der Verfügbarkeitsgruppe wird dann erlaubt, Datenbanken auf dem sekundären Replikat zu erstellen, um das automatische Seeding zu unterstützen.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Erstellen eines Listeners für die sekundäre Verfügbarkeitsgruppe
Fügen Sie im nächsten Schritt einen Listener für die sekundäre Verfügbarkeitsgruppe auf dem zweiten WSFC hinzu. In diesem Beispiel hat der Listener den Namen ag2-listener. Weitere Informationen zum Erstellen eines Listeners finden Sie unter Erstellen oder Konfigurieren eines Verfügbarkeitsgruppenlisteners (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Erstellen einer verteilten Verfügbarkeitsgruppe auf dem ersten Cluster
Erstellen Sie auf dem ersten WSFC eine verteilte Verfügbarkeitsgruppe (die in diesem Beispiel den Namen distributedAG trägt). Verwenden Sie den CREATE AVAILABILITY GROUP -Befehl mit der DISTRIBUTED -Option. Der AVAILABILITY GROUP ON-Parameter gibt die Memberverfügbarkeitsgruppen ag1 und ag2 an.
Verwenden Sie den folgenden Transact-SQL-Code, um Ihre verteilte Verfügbarkeitsgruppe mithilfe des automatischen Seedings zu erstellen:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Hinweis
Die LISTENER_URL gibt den Listener für jede Verfügbarkeitsgruppe zusammen mit dem Datenbankspiegelungs-Endpunkt der Verfügbarkeitsgruppe an. In diesem Beispiel ist das Port 5022 (nicht Port 60173 , der zum Erstellen des Listeners verwendet wurde). Wenn Sie einen Lastenausgleich verwenden, z. B. in Azure, fügen Sie eine Lastenausgleichsregel für den Port einer verteilten Verfügbarkeitsgruppehinzu. Fügen Sie zusätzlich zum SQL Server-Instanzport die Regel für den Listenerport hinzu.
Abbrechen des automatischen Seedings für die Weiterleitung
Falls es aus unterschiedlichsten Gründen erforderlich ist, die Initialisierung der Weiterleitung abzubrechen, bevor die zwei Verfügbarkeitsgruppen synchronisiert werden, ändern Sie die verteilte Verfügbarkeitsgruppe mit ALTER, indem Sie den SEEDING_MODE-Parameter der Weiterleitung auf MANUAL festlegen und das Seeding sofort abbrechen. Führen Sie den Befehl für die globale primäre Datenbank aus:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Verknüpfen der verteilten Verfügbarkeitsgruppe auf dem zweiten Cluster
Verknüpfen Sie anschließend die verteilte Veerfügbarkeitsgruppe auf dem zweiten WSFC.
Verwenden Sie den folgenden Transact-SQL-Code, um Ihre verteilte Verfügbarkeitsgruppe mithilfe des automatischen Seedings zu verknüpfen:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Verknüpfen der Datenbank auf dem sekundären Replikat der zweiten Verfügbarkeitsgruppe
Wenn die zweite Verfügbarkeitsgruppe für die Verwendung des automatischen Seedings eingerichtet wurde, fahren Sie mit Schritt 2 fort.
Wenn die zweite Verfügbarkeitsgruppe manuelles Seeding verwendet, stellen Sie die Sicherung, die Sie auf dem globalen primären Replikat erstellt haben, auf dem sekundären Replikat der zweiten Verfügbarkeitsgruppe wieder her:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;Nachdem die Datenbank auf dem sekundären Replikat der zweiten Verfügbarkeitsgruppe in einen Wiederherstellungsstatus versetzt wurde, müssen Sie sie manuell mit der Verfügbarkeitsgruppe verknüpfen.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Ein Failover für eine verteilte Verfügbarkeitsgruppe
Da SQL Server 2022 (16.x) die Unterstützung für verteilte Verfügbarkeitsgruppen für die REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT-Einstellung eingeführt hat, unterscheiden sich Anweisungen zum Ausführen eines Failover für eine verteilte Verfügbarkeit für SQL Server 2022 und höhere Versionen als für SQL Server 2019 und frühere Versionen.
Bei einer verteilten Verfügbarkeitsgruppe ist der einzige unterstützte Failover-Typ ein durch einen manuellen Benutzer initiiertes FORCE_FAILOVER_ALLOW_DATA_LOSS. Um Datenverluste zu verhindern, müssen Sie daher zusätzliche Schritte ausführen (im Detail in diesem Abschnitt beschrieben), um sicherzustellen, dass Daten zwischen den beiden Replikaten synchronisiert werden, bevor Sie das Failover initiieren.
Im Falle eines Notfalls, in dem Datenverlust akzeptabel ist, können Sie ein Failover initiieren, ohne sicherzustellen, dass die Datensynchronisierung ausgeführt wird:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
Mit demselben Befehl können Sie sowohl den Failover zur Weiterleitung als auch das Failback zum globalen Primärserver durchführen.
Auf SQL Server 2022 (16.x) und höher können Sie die REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT-Einstellung für eine verteilte Verfügbarkeitsgruppe konfigurieren, die darauf ausgelegt ist, keinen Datenverlust zu gewährleisten, wenn eine verteilte Verfügbarkeitsgruppe fehlschlägt. Wenn diese Einstellung konfiguriert ist, führen Sie die Schritte in diesem Abschnitt aus, um für Ihre verteilte Verfügbarkeitsgruppe einen Failover auszuführen. Wenn Sie die REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT-Einstellung nicht verwenden möchten, führen Sie die Anweisungen aus, um für eine verteilte Verfügbarkeitsgruppe in SQL Server 2019 und früheren Versionen einen Failover auszuführen.
Hinweis
Das Festlegen von REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT auf 1 bedeutet, dass das primäre Replikat wartet, bis Transaktionen auf dem sekundären Replikat bestätigt werden, bevor sie auf dem primären Replikat bestätigt werden, was die Leistung beeinträchtigen kann. Während das Einschränken oder Beenden von Transaktionen auf der globalen Primären nicht erforderlich ist, damit die verteilte Verfügbarkeitsgruppe in SQL Server 2022 (16.x) synchronisiert werden kann, kann dies die Leistung sowohl für Benutzertransaktionen als auch für die Synchronisierung verteilter Verfügbarkeitsgruppen mit REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT auf 1 verbessern.
Schritte, um sicherzustellen, dass kein Datenverlust auftritt
Um sicherzustellen, dass kein Datenverlust auftritt, müssen Sie zuerst die Verteilte Verfügbarkeitsgruppe so konfigurieren, dass keine Datenverluste unterstützt werden, indem Sie die folgenden Schritte ausführen:
- Um sich auf Failover vorzubereiten, überprüfen Sie, ob sich die globale primäre und Weiterleitung im
SYNCHRONOUS_COMMITModus befinden. Wenn nicht, setzen Sie sie aufSYNCHRONOUS_COMMITbis ALTER AVAILABILITY GROUP. - Legen Sie die verteilte Verfügbarkeitsgruppe auf dem globalen primären Replikat und der Weiterleitung auf einen synchronen Commit fest.
- Warten Sie, bis die Verteilte Verfügbarkeitsgruppe synchronisiert wird.
- Legen Sie im globalen primären Replikat die
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT-Einstellung für die verteilte Verfügbarkeitsgruppe auf 1 fest, indem Sie ALTER AVAILABILITY GROUP verwenden. - Stellen Sie sicher, dass alle Replikate in den lokalen VG und der verteilten Verfügbarkeitsgruppe intakt sind und die verteilte Verfügbarkeitsgruppe SYNCHRONIZED ist.
- Legen Sie im globalen primären Replikat die Rolle „Verteilte Verfügbarkeitsgruppe“ auf „
SECONDARY„ fest, wodurch die verteilte Verfügbarkeitsgruppe nicht verfügbar ist. - Führen Sie auf der Weiterleitung (das beabsichtigte neue primäre Replikat) ein Failover der verteilten Verfügbarkeitsgruppe durch, indem Sie ALTER AVAILABILITY GROUP mit
FORCE_FAILOVER_ALLOW_DATA_LOSSverwenden. - Legen Sie für das neue sekundäre Replikat (das vorherige globale primäre Replikat) die verteilte Verfügbarkeitsgruppe
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITauf 0 fest. - Optional: Wenn sich die Verfügbarkeitsgruppen über eine geografische Entfernung befinden, die zu Latenz führt, ändern Sie den Verfügbarkeitsmodus in
ASYNCHRONOUS_COMMIT. Dadurch wird die Änderung aus dem ersten Schritt bei Bedarf rückgängig gemacht.
T-SQL-Beispiel
Dieser Abschnitt enthält die Schritte in einem detaillierten Beispiel, um für die verteilte Verfügbarkeitsgruppe mit dem Namen distributedAG mithilfe von Transact-SQL ein Failover durchzuführen. Die Beispielumgebung verfügt über insgesamt vier Knoten für die Verteilte Verfügbarkeitsgruppe. Die globale primäre N1 und N2-Hostverfügbarkeitsgruppe ag1 sowie die N3- und N4-Weiterleitungs-Hostverfügbarkeitsgruppe ag2. Die Verteilte Verfügbarkeitsgruppe distributedAG überträgt Änderungen von ag1 auf ag2.
Abfrage, um
SYNCHRONOUS_COMMITfür die Primärinstanzen der lokalen Verfügbarkeitsgruppen zu überprüfen, die die verteilte Verfügbarkeitsgruppe bilden. Führen Sie den folgenden T-SQL-Code direkt auf dem Weiterleitungsserver und dem globalen Primärserver aus:SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Legen Sie die verteilte Verfügbarkeitsgruppe auf einen synchronen Commit fest, indem Sie folgenden Code auf dem globalen primären Replikat und der Weiterleitung ausführen.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Hinweis
In einer verteilten Verfügbarkeitsgruppe hängt der Synchronisierungsstatus der zwei Verfügbarkeitsgruppen vom Verfügbarkeitsmodus beider Replikate ab. Für den synchronen Commitmodus müssen sowohl die aktuell primäre Verfügbarkeitsgruppe als auch die aktuell sekundäre Verfügbarkeitsgruppe den Verfügbarkeitsmodus
SYNCHRONOUS_COMMITaufweisen. Aus diesem Grund müssen Sie dieses Skript sowohl für das globale primäre Replikat als auch für die Weiterleitung ausführen.Warten Sie, bis sich der Status der verteilten Verfügbarkeitsgruppe in
SYNCHRONIZEDändert. Führen Sie die folgende Abfrage für die globale Primäre aus:-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];Führen Sie den nächsten Schritt aus, sobald synchronization_state_desc für die Verfügbarkeitsgruppe gleich
SYNCHRONIZEDist.Legen Sie für SQL Server 2022 (16.x) und höher auf der globalen primären Instanz
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITauf 1 fest, indem Sie die folgende T-SQL verwenden:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Überprüfen Sie, ob Ihre Verfügbarkeitsgruppen auf allen Replikaten gesund sind, indem Sie das globale primäre Replikat und die Weiterleitung abfragen.
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');Legen Sie auf dem globalen primären Replikat die Rolle der verteilten Verfügbarkeitsgruppe auf
SECONDARYfest. Zu diesem Zeitpunkt ist die verteilte Verfügbarkeitsgruppe nicht verfügbar. Nach Abschluss dieses Schritts können Sie kein Failback durchführen, bis die restlichen Schritte ausgeführt wurden.ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);Führen Sie ein Failover vom globalen primären Repliakt durch, indem Sie die folgende Abfrage auf der Weiterleitung ausführen, um die Verfügbarkeitsgruppen zu übertragen und die verteilte Verfügbarkeitsgruppe wieder online zu bringen.
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;Nach diesem Schritt:
- Die globalen primären Übergänge von
N1zuN3. - Die Weiterleitung wechselt von
N3zuN1. - Die Gruppe für verteilte Verfügbarkeit ist verfügbar.
- Die globalen primären Übergänge von
Auf dem neuen Weiterleiterserver (dem vorherigen globalen Primär-
N1) löschen Sie die Eigenschaft "Verteilte Verfügbarkeitsgruppe"REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, indem Sie sie auf 0 setzen:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);OPTIONAL: Wenn zwischen Verfügbarkeitsgruppen eine geografische Entfernung liegt, die Latenz (Wartezeit) verursacht, ziehen Sie in Betracht, den Verfügbarkeitsmodus wieder auf dem globalen primären Replikat
ASYNCHRONOUS_COMMITder Weiterleitung in zu ändern. Dadurch wird die im ersten Schritt vorgenommene Änderung bei Bedarf wiederhergestellt.-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
Entfernen einer verteilten Verfügbarkeitsgruppe
Die folgende Transact-SQL-Anweisung entfernt eine verteilte Verfügbarkeitsgruppe mit dem Namen distributedAG:
DROP AVAILABILITY GROUP distributedAG;
Erstellen einer verteilten Verfügbarkeitsgruppe auf Failoverclusterinstanzen
Sie können eine verteilte Verfügbarkeitsgruppe mit einer Verfügbarkeitsgruppe auf einer Failoverclusterinstanz (FCI) erstellen. In diesem Fall benötigen Sie keinen Verfügbarkeitsgruppenlistener. Verwenden Sie den virtuellen Netzwerknamen (VNN) für das primäre Replikat der FCI-Instanz. Im folgenden Beispiel ist eine verteilte Verfügbarkeitsgruppe namens SQLFCIDAG dargestellt. Eine Verfügbarkeitsgruppe ist SQLFCIAG. SQLFCIAG besitzt zwei FCI-Replikate. Der VNN für das primäre FCI-Replikat ist FCI SQLFCIAG-1, und der VNN für das sekundäre FCI-Replikat ist SQLFCIAG-2. Die verteilte Verfügbarkeitsgruppe enthält außerdem SQLAG-DR zur Wiederherstellung im Notfall.
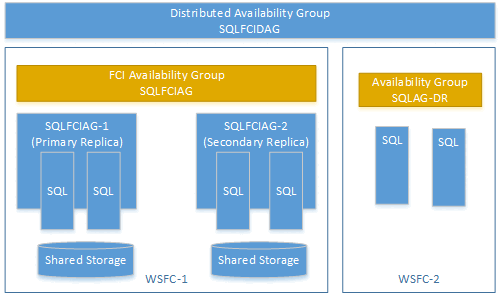
Die folgende DDL erstellt diese verteilte Verfügbarkeitsgruppe:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
Die Listener-URL ist mit dem VNN der primären FCI-Instanz identisch.
Ausführen eines manuellen Failovers für die FCI in der verteilten Verfügbarkeitsgruppe
Um ein manuelles Failover für die FCI-Verfügbarkeitsgruppe auszuführen, aktualisieren Sie die verteilte Verfügbarkeitsgruppe, um die Änderung der Listener-URL zu übernehmen. Führen Sie beispielsweise die folgende DDL sowohl für das globale primäre Replikat der verteilten Verfügbarkeitsgruppe als auch für die Weiterleitung der verteilten Verfügbarkeitsgruppe von SQLFCIDAG aus:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)