Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server
Der Leistungsaspekt der Always On-Verfügbarkeitsgruppen ist entscheidend, um die Vereinbarung zum Servicelevel (SLA) für Ihre unternehmenskritischen Datenbanken zu erfüllen. Wenn Sie den Vorgang bei Verfügbarkeitsgruppen zum Senden von Protokollen an sekundäre Replikate verstehen, können Sie die Recovery Time Objective (RTO) und Recovery Point Objective (RPO) Ihrer Verfügbarkeitsimplementierung besser einschätzen und Engpässe bei leistungsschwachen Verfügbarkeitsgruppen oder Replikaten ausfindig machen. In diesem Artikel werden der Synchronisierungsprozess und die Berechnung einiger der wichtigsten Metriken beschrieben. Zudem enthält der Artikel Links zu einigen allgemeinen leistungsbezogenen Problembehandlungsszenarien.
Datensynchronisierungsprozess
Um die Zeit bis zur vollständigen Synchronisierung einzuschätzen und den Engpass zu identifizieren, müssen Sie den Synchronisierungsprozess verstehen. Leistungsengpässe können an einer beliebigen Stelle im Prozess auftreten. Durch die Ermittlung des Engpasses können Sie den zugrunde liegenden Problemen besser auf den Grund gehen. Der folgende Abbildung und Tabelle veranschaulichen den Datensynchronisierungsprozess:

| Sequenz | Beschreibung des Schritts | Kommentare | Nützliche Metriken |
|---|---|---|---|
| 1 | Protokollgenerierung | Protokolldaten werden auf den Datenträger geleert. Dieses Protokoll muss in die sekundären Replikate repliziert werden. Die Protokolldatensätze werden in die Sendewarteschlange eingereiht. | SQL Server:Datenbankprotokoll > Bytes gespült/Sekunde |
| 2 | Erfassung | Protokolle für jede Datenbank werden erfasst und an die entsprechende Partnerwarteschlange (eine pro Datenbank-Replikapaar) gesendet. Dieser Erfassungsprozess wird kontinuierlich ausgeführt, solange das Verfügbarkeitsreplikat verbunden ist, die Datenverschiebung aus keinem Grund angehalten wird und das Datenbankreplikatpaar entweder synchronisiert oder im Zustand der Synchronisierung angezeigt wird. Wenn der Erfassungsprozess nicht in der Lage ist, die Nachrichten schnell genug zu scannen und in die Warteschlange zu stellen, staut sich die Protokoll-Sendewarteschlange. |
SQL Server:Verfügbarkeitsreplikat > Bytes, die pro Sekunde an das Replikat gesendet werden - eine Aggregation der Gesamtsumme aller Datenbanknachrichten, die für dieses Verfügbarkeitsreplikat in die Warteschlange gestellt sind. log_send_queue_size (KB) und log_bytes_send_rate (KB/s) für das primäre Replikat |
| 3 | Send | Die Nachrichten in jeder Warteschlange für Datenbankreplikate werden aus der Warteschlange verarbeitet und über das Netzwerk an das jeweilige sekundäre Replikat gesendet. | SQL Server:Availability Replica > Bytes gesendet an Transport/Sek. |
| 4 | Empfang und Zwischenspeicherung | Jedes sekundäre Replikat empfängt und speichert die Nachricht zwischen. | Leistungsindikator SQL Server: Verfügbarkeitsreplikat > Empfangene Protokollbytes/Sekunde |
| 5 | Festschreibung | Ein Protokoll wird zur Festschreibung für das sekundäre Replikat geleert. Nachdem das Protokoll geleert wurde, wird eine Bestätigung an das primäre Replikat zurückgesendet. Ist das Protokoll festgeschrieben, wurde ein Datenverlust abgewendet. |
Leistungsindikator SQL Server: Datenbank > Geleerte Protokollbytes/Sekunde Wartetyp HADR_LOGCAPTURE_SYNC |
| 6 | Wiederholen | Wiederholen Sie die geleerten Seiten auf dem sekundären Replikat. Seiten werden in der Wiederholungswarteschlange beibehalten, während sie darauf warten, wiederholt zu werden. |
SQL Server: Datenbankreplikat > Wiederholte Bytes/Sekunde redo_queue_size (KB) und redo_rate. Wartetyp REDO_SYNC |
Flusssteuerungsgates
Verfügbarkeitsgruppen werden mit Flusssteuerungsdaten für das primäre Replikat entworfen, um eine übermäßige Ressourcenauslastung wie etwa bei Netzwerk- und Speicherressourcen für alle Verfügbarkeitsreplikate zu vermeiden. Diese Flusskontrollschranken wirken sich nicht auf den Synchronisierungszustand und Gesundheitszustand der Verfügbarkeitsreplikate aus, können sich jedoch auf die allgemeine Leistung Ihrer Verfügbarkeitsdatenbanken einschließlich des RPO auswirken.
Nachdem die Protokolle für das primäre Replikat erfasst wurden, unterliegen sie zwei Ebenen der Flusssteuerungen. Sobald der Nachrichtenschwellenwert von einem der beiden Gates erreicht wird, werden keine Protokollnachrichten mehr an ein bestimmtes Replikat oder für eine bestimmte Datenbank gesendet. Nachrichten können gesendet werden, sobald Bestätigungsnachrichten für die gesendeten Nachrichten empfangen wurden, um die Anzahl der gesendeten Nachrichten auf einen Wert unterhalb des Schwellenwerts zu senken.
Zusätzlich zu den Flusssteuerungsgaten gibt es einen weiteren Faktor, der verhindern kann, dass die Protokollnachrichten gesendet werden. Durch die Synchronisierung von Replikaten wird sichergestellt, dass die Nachrichten gesendet und in der Reihenfolge der Protokollfolgenummern (Log Sequence Numbers, LSN) angewendet werden. Bevor eine Protokollnachricht gesendet wird, wird ihre LSN auch anhand der niedrigsten bestätigten LSN-Nummer überprüft, um sicherzustellen, dass sie unter einem der Schwellenwerte liegt (abhängig vom Nachrichtentyp). Wenn die Lücke zwischen den beiden LSN-Zahlen größer als der Schwellenwert ist, werden die Nachrichten nicht gesendet. Wenn die Diskrepanz wieder unter dem Schwellenwert liegt, werden die Nachrichten gesendet.
SQL Server 2022 (16.x) erhöht die Anzahl der Nachrichten, die jedes Gate zulässt. Verwenden Sie ab den folgenden Versionen die Ablaufverfolgungskennzeichnung 12310 beim Start, um den Grenzwert zu erhöhen: SQL Server 2019 (15.x) CU9, SQL Server 2017 (14.x) CU18 und SQL Server 2016 (13.x) SP1 CU16. Dieses Ablaufverfolgungsflag kann nicht mit DBCC TRACEON verwendet werden.
In der folgenden Tabelle werden die Nachrichtengrenzwerte verglichen:
Für SQL Server-Versionen, die das Ablaufverfolgungsflag 12310 aktivieren, nämlich SQL Server 2022 (16.x), SQL Server 2019 (15.x) CU9, SQL Server 2017 (14.x) CU18 und SQL Server 2016 (13.x) SP1 CU16 sowie spätere Versionen, gelten die folgenden Grenzwerte:
| Ebene | Anzahl der Gates | Anzahl der Nachrichten | Nützliche Metriken |
|---|---|---|---|
| Transport | 1 pro Verfügbarkeitsreplikat | 16384 | Erweitertes Ereignis database_transport_flow_control_action |
| Datenbank | 1 pro Verfügbarkeitsdatenbank | 7168 |
DBMIRROR_SEND Erweitertes Ereignis hadron_database_flow_control_action |
Die zwei nützlichen Leistungsindikatoren SQL Server: Verfügbarkeitsreplikat > Flusssteuerung/Sekunde und SQL Server: Verfügbarkeitsreplikat > Flusssteuerungszeit (ms/Sekunde) zeigen, wie oft die Flusssteuerung innerhalb der letzten Sekunde aktiviert und wie viel Zeit für das Warten auf die Flusssteuerung benötigt wurde. Längere Wartezeiten bei der Flusssteuerung bedeuten eine höhere RPO. Weitere Informationen zu den Arten von Problemen, die zu einer hohen Wartezeit für die Flusssteuerung führen können, finden Sie unter „Problembehandlung: Potenzieller Datenverlust mit Replikaten für asynchrone Verfügbarkeitsgruppen“.
Schätzen der Failoverzeit (RTO)
Die RTO in Ihrer SLA hängt von der Failoverzeit Ihrer Always On-Implementierung an einem bestimmten Zeitpunkt ab, die mit der folgenden Formel ausgedrückt werden kann:
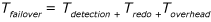
Wichtig
Wenn eine Verfügbarkeitsgruppe mehr als eine Verfügbarkeitsdatenbank enthält, wird die Verfügbarkeitsdatenbank mit dem höchsten Tfailover-Wert zum Grenzwert für die RTO-Konformität.
Die Ausfallerkennungszeit, Tdetection, ist der Zeitaufwand, den das System zur Erkennung des Fehlers benötigt. Diese Zeit hängt von den Einstellungen auf Clusterebene ab, nicht von den einzelnen Verfügbarkeitsreplikaten. Abhängig von der konfigurierten Bedingung für ein automatisches Failover kann ein Failover als sofortige Antwort auf einen kritischen internen SQL Server-Fehler wie verwaiste Spinlocks ausgelöst werden. In diesem Fall kann die Erkennung so schnell sein, wie der sp_server_diagnostics Fehlerbericht an den Windows Server-Failovercluster (WSFC) gesendet wird. Das Standardintervall ist 1/3 des Timeouts für die Integritätsprüfung. Ein Failover kann auch aufgrund eines Timeouts ausgelöst werden, z. B. das Timeout für die Clusterintegrität ist abgelaufen (standardmäßig 30 Sekunden) oder die Lease zwischen der Ressourcen-DLL und der SQL Server-Instanz ist abgelaufen (standardmäßig 20 Sekunden). In diesem Fall ist die Erkennungszeit so lange wie das Timeoutintervall. Weitere Informationen finden Sie unter Flexible Failoverrichtlinie für automatisches Failover einer Verfügbarkeitsgruppe (SQL Server).
Um für ein Failover bereit zu sein, muss das sekundäre Replikat lediglich eine Wiederholung ausführen, um das Ende des Protokolls zu erreichen. Die Wiederholungszeit, Tredo, wird mit der folgenden Formel berechnet:

Hierbei steht redo_queue für den Wert in redo_queue_size und redo_rate für den Wert in redo_rate.
Der zeitliche Mehraufwand für das Failover, Toverhead, schließt den Zeitaufwand ein, der für ein Failover des WSFC-Clusters und die Aktivierung der Datenbanken erforderlich ist. Diese Zeit ist normalerweise kurz und konstant.
Schätzen potenzieller Datenverluste (RPO)
Die RPO in Ihrer SLA hängt von dem möglichen Datenverlust Ihrer Always On-Implementierung zu einem beliebigen Zeitpunkt ab. Dieser mögliche Datenverlust kann mit der folgenden Formel ausgedrückt werden:
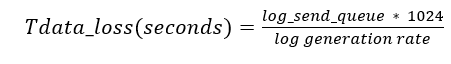
Hierbei steht log_send_queue für den Wert von log_send_queue_size und log generation rate für den Wert von SQL Server: Datenbank > Geleerte Protokollbytes/Sekunde.
Warnung
Wenn eine Verfügbarkeitsgruppe mehr als eine Verfügbarkeitsdatenbank enthält, wird die Verfügbarkeitsdatenbank mit der höchsten Tdata_loss-Wert zum Grenzwert für die RPO-Konformität.
Die Protokollsendewarteschlange stellt alle Daten dar, die aufgrund eines schwerwiegenden Fehlers verloren gehen können. Auf den ersten Blick ist es merkwürdig, dass die Protokollgenerierungsrate anstelle der Protokoll-Senderate verwendet wird (siehe log_send_rate). Denken Sie jedoch daran, dass die Verwendung der Protokoll-Senderate Ihnen nur die Zeit für die Synchronisierung gibt, während RPO Datenverlust basierend darauf misst, wie schnell sie generiert wird und nicht, wie schnell sie synchronisiert wird.
Eine einfachere Möglichkeit zur Einschätzung von Tdata_loss bietet die Verwendung von last_commit_time. Die DMV für das primäre Replikat meldet diesen Wert für alle Replikate. Sie können die Diskrepanz zwischen dem Wert für das primäre Replikat und dem für das sekundäre Replikat berechnen, um einzuschätzen, wie schnell das Protokoll für das sekundäre Replikat im Vergleich zum primären Replikat verarbeitet wird. Wie bereits erwähnt, gibt diese Berechnung nicht an, welches potenzielle Datenverlust basierend auf der Geschwindigkeit der Protokollgenerierung auftreten könnte, aber es sollte eine ziemlich genaue Annäherung sein.
Schätzen von RTO und RPO mit dem SSMS-Dashboard
In Always On Availability Groups werden RTO und RPO für die Datenbanken berechnet und angezeigt, die auf den sekundären Replikaten gehostet werden. Im SQL Server Management Stuiod (SSMS)-Dashboard im primären Replikat werden RTO und RPO nach dem sekundären Replikat gruppiert.
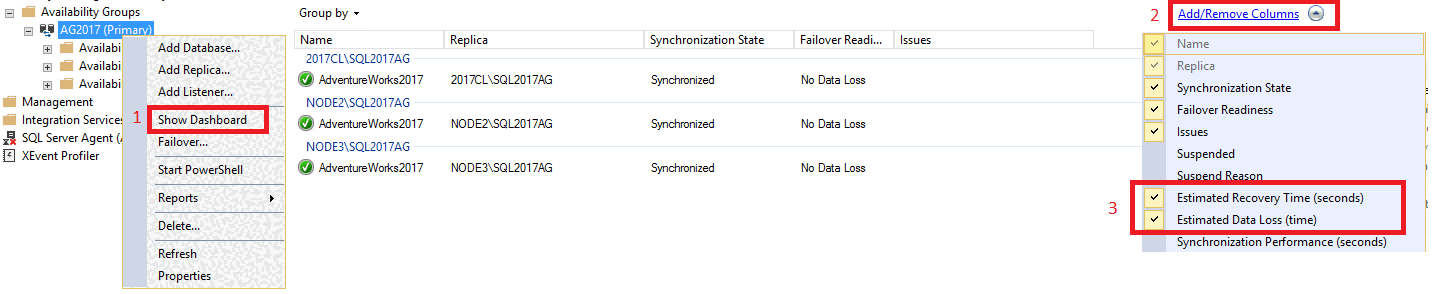
Führen Sie die folgenden Schritte aus, um das RTO und das RPO im Dashboard anzuzeigen:
Erweitern Sie in SQL Server Management Studio den Knoten Hochverfügbarkeit mit Always On. Klicken Sie mit der rechten Maustaste auf den Namen Ihrer Verfügbarkeitsgruppen, und klicken Sie dann auf Dashboard anzeigen.
Wählen Sie Spalten hinzufügen/entfernen unter der Registerkarte Gruppieren nach aus. Aktivieren Sie Geschätzte Wiederherstellungszeit (Sekunden) [RTO] und Geschätzter Datenverlust (Zeit) [RPO].

Berechnung des RTO der sekundären Datenbank
Durch die Berechnung der Wiederherstellungszeit wird ermittelt, wie viel Zeit benötigt wird, um die sekundäre Datenbank nach einem Failover wiederherzustellen. Die Failoverzeit ist normalerweise kurz und konstant. Die Erkennungszeit hängt von den Einstellungen auf Clusterebene und nicht von den einzelnen Verfügbarkeitsreplikaten ab.
Für eine sekundäre Datenbank (DB_sec) basiert die Berechnung und Anzeige des RTO auf dessen redo_queue_size und redo_rate.

Mit Ausnahme von Sonderfällen ist die Formel zur Berechnung des RTO einer Sekundärdatenbank wie folgt:

Berechnung des RPO der sekundären Datenbank
Die Berechnung und Anzeige des RPO einer sekundären Datenbank (DB_sec) basiert auf den Werten is_failover_ready, last_commit_time und den korrelierten Werten der primären Datenbank (DB_pri) sowie last_commit_time. Wenn der Wert von DB_sec.is_failover_ready1 ist, werden Daten zwischen der primären und den Sekundärsystemen synchronisiert, und beim Übernahme tritt kein Datenverlust auf. Wenn dieser Wert jedoch lautet 0, gibt es eine Lücke zwischen der last_commit_time primären Datenbank und der last_commit_time sekundären Datenbank.
Für die primäre Datenbank ist der Zeitpunkt des last_commit_time, zu dem die letzte Transaktion abgeschlossen wurde. Für die sekundäre Datenbank ist die last_commit_time letzte Commitzeit für die Transaktion aus der primären Datenbank, die ebenfalls erfolgreich auf der sekundären Datenbank gehärtet wurde. Diese Zahl ist für die primäre und sekundäre Datenbank identisch. Eine Lücke zwischen diesen beiden Werten ist jedoch die Dauer, in der ausstehende Transaktionen nicht in der sekundären Datenbank gehärtet wurden und im Falle eines Failovers verloren gehen können.

In RTO/RPO-Formeln verwendete Leistungsmetriken
redo_queue_size(KB): Die Größe der Redo-Warteschlange, die in RTO verwendet wird, entspricht der Größe der Transaktionsprotokolle zwischen den Punktenlast_received_lsnundlast_redone_lsn. Derlast_received_lsnWert ist die Protokollblock-ID, die den Punkt angibt, an dem alle Protokollblöcke vom sekundären Replikat empfangen wurden, das diese sekundäre Datenbank hostt. Der Wert vonlast_redone_lsnist die Protokollsequenznummer des letzten Protokolldatensatzes, der in der sekundären Datenbank wiederhergestellt wurde. Basierend auf diesen beiden Werten finden wir IDs des Startprotokollblocks (last_received_lsn) und des Endprotokollblocks (last_redone_lsn). Der Abstand zwischen diesen beiden Protokollblöcken kann dann darstellen, wie viele Transaktionsprotokollblöcke noch nicht erneut bearbeitet werden. Die Messung erfolgt in Kilobyte (KB).redo_rate(KB/s): Wird bei der RTO-Berechnung verwendet, ist dies ein kumulierter Wert, der angibt, wie viel des Transaktionsprotokolls (KB) pro Sekunde erneut angezeigt oder in der sekundären Datenbank wiedergegeben wurde.last_commit_time(datetime): In RPO verwendet, hat dieser Wert eine andere Bedeutung zwischen der primären und sekundären Datenbank. Für die primäre Datenbank istlast_commit_timeder Zeitpunkt, zu dem die letzte Transaktion zugesichert wurde. Für die sekundäre Datenbank ist derlast_commit_timeder neueste Commit der Transaktion in der primären Datenbank, der ebenfalls erfolgreich in der sekundären Datenbank gesichert wurde. Da dieser Wert in der sekundären Datenbank mit dem gleichen Wert für die primäre synchronisiert werden sollte, ist jede Lücke zwischen diesen beiden Werten die Schätzung des Datenverlusts (RPO).
Schätzen von RTO und RPO mithilfe dynamischer Verwaltungssichten (DMVs)
Es ist möglich, die DMVs sys.dm_hadr_database_replica_states und sys.dm_hadr_database_replica_cluster_states abzufragen, um die RPO und RTO einer Datenbank zu schätzen. Die folgenden Abfragen erstellen gespeicherte Prozeduren, die beide Aufgaben bewältigen.
Hinweis
Stellen Sie sicher, dass Sie die gespeicherte Prozedur erstellen und ausführen, um das RTO zuerst zu schätzen, da die von ihr erzeugten Werte notwendig sind, um die gespeicherte Prozedur zur Schätzung des RPO auszuführen.
Erstellen einer gespeicherten Prozedur zum Schätzen des RTO
Erstellen Sie im sekundären Zielreplikat eine gespeicherte Prozedur
proc_calculate_RTO. Wenn diese gespeicherte Prozedur bereits vorhanden ist, löschen Sie sie zuerst, und erstellen Sie sie dann neu.IF object_id(N'proc_calculate_RTO', 'p') IS NOT NULL DROP PROCEDURE proc_calculate_RTO; GO RAISERROR ('creating procedure proc_calculate_RTO', 0, 1) WITH NOWAIT; GO -- name: proc_calculate_RTO -- -- description: Calculate RTO of a secondary database. -- -- parameters: @secondary_database_name nvarchar(max): name of the secondary database. -- -- security: this is a public interface object. -- CREATE PROCEDURE proc_calculate_RTO @secondary_database_name NVARCHAR (MAX) AS BEGIN DECLARE @db AS sysname; DECLARE @is_primary_replica AS BIT; DECLARE @is_failover_ready AS BIT; DECLARE @redo_queue_size AS BIGINT; DECLARE @redo_rate AS BIGINT; DECLARE @replica_id AS UNIQUEIDENTIFIER; DECLARE @group_database_id AS UNIQUEIDENTIFIER; DECLARE @group_id AS UNIQUEIDENTIFIER; DECLARE @RTO AS FLOAT; SELECT @is_primary_replica = dbr.is_primary_replica, @is_failover_ready = dbcs.is_failover_ready, @redo_queue_size = dbr.redo_queue_size, @redo_rate = dbr.redo_rate, @replica_id = dbr.replica_id, @group_database_id = dbr.group_database_id, @group_id = dbr.group_id FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbcs.database_name = @secondary_database_name; IF @is_primary_replica IS NULL OR @is_failover_ready IS NULL OR @redo_queue_size IS NULL OR @replica_id IS NULL OR @group_database_id IS NULL OR @group_id IS NULL BEGIN PRINT 'RTO of Database ' + @secondary_database_name + ' is not available'; RETURN; END ELSE IF @is_primary_replica = 1 BEGIN PRINT 'You are visiting wrong replica'; RETURN; END IF @redo_queue_size = 0 SET @RTO = 0; ELSE IF @redo_rate IS NULL OR @redo_rate = 0 BEGIN PRINT 'RTO of Database ' + @secondary_database_name + ' is not available'; RETURN; END ELSE SET @RTO = CAST (@redo_queue_size AS FLOAT) / @redo_rate; PRINT 'RTO of Database ' + @secondary_database_name + ' is ' + CONVERT (VARCHAR, ceiling(@RTO)); PRINT 'group_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @group_id); PRINT 'replica_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @replica_id); PRINT 'group_database_id of Database ' + @secondary_database_name + ' is ' + CONVERT (NVARCHAR (50), @group_database_id); ENDWird mit dem Namen der sekundären Zieldatenbank ausgeführt
proc_calculate_RTO:EXECUTE proc_calculate_RTO @secondary_database_name = N'DB_sec';Die Ausgabe zeigt den RTO-Wert der Zieldatenbank des sekundären Replikats. Speichern Sie group_id, replica_id und group_database_id, um diese Angaben mit der gespeicherten Prozedur zur Schätzung des RPO zu verwenden.
Beispielausgabe:
RTO of Database DB_sec' is 0 group_id of Database DB4 is F176DD65-C3EE-4240-BA23-EA615F965C9B replica_id of Database DB4 is 405554F6-3FDC-4593-A650-2067F5FABFFD group_database_id of Database DB4 is 39F7942F-7B5E-42C5-977D-02E7FFA6C392
Erstellen einer gespeicherten Prozedur zum Schätzen des RPO
Erstellen Sie im primären Replikat eine gespeicherte Prozedur
proc_calculate_RPO. Wenn sie bereits vorhanden ist, löschen Sie sie zuerst, und erstellen Sie sie dann neu.IF object_id(N'proc_calculate_RPO', 'p') IS NOT NULL DROP PROCEDURE proc_calculate_RPO; GO RAISERROR ('creating procedure proc_calculate_RPO', 0, 1) WITH NOWAIT; GO -- name: proc_calculate_RPO -- -- description: Calculate RPO of a secondary database. -- -- parameters: @group_id uniqueidentifier: group_id of the secondary database. -- @replica_id uniqueidentifier: replica_id of the secondary database. -- @group_database_id uniqueidentifier: group_database_id of the secondary database. -- -- security: this is a public interface object. -- CREATE PROCEDURE proc_calculate_RPO @group_id UNIQUEIDENTIFIER, @replica_id UNIQUEIDENTIFIER, @group_database_id UNIQUEIDENTIFIER AS BEGIN DECLARE @db_name AS sysname; DECLARE @is_primary_replica AS BIT; DECLARE @is_failover_ready AS BIT; DECLARE @is_local AS BIT; DECLARE @last_commit_time_sec AS DATETIME; DECLARE @last_commit_time_pri AS DATETIME; DECLARE @RPO AS NVARCHAR (MAX); SELECT @db_name = dbcs.database_name, @is_failover_ready = dbcs.is_failover_ready, @last_commit_time_sec = dbr.last_commit_time FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbr.group_id = @group_id AND dbr.replica_id = @replica_id AND dbr.group_database_id = @group_database_id; SELECT @last_commit_time_pri = dbr.last_commit_time, @is_local = dbr.is_local FROM sys.dm_hadr_database_replica_states AS dbr INNER JOIN sys.dm_hadr_database_replica_cluster_states AS dbcs ON dbr.replica_id = dbcs.replica_id AND dbr.group_database_id = dbcs.group_database_id WHERE dbr.group_id = @group_id AND dbr.is_primary_replica = 1 AND dbr.group_database_id = @group_database_id; IF @is_local IS NULL OR @is_failover_ready IS NULL BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END IF @is_local = 0 BEGIN PRINT 'You are visiting wrong replica'; RETURN; END IF @is_failover_ready = 1 SET @RPO = '00:00:00'; ELSE IF @last_commit_time_sec IS NULL OR @last_commit_time_pri IS NULL BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END ELSE BEGIN IF DATEDIFF(ss, @last_commit_time_sec, @last_commit_time_pri) < 0 BEGIN PRINT 'RPO of database ' + @db_name + ' is not available'; RETURN; END ELSE SET @RPO = CONVERT (VARCHAR, DATEADD(ms, datediff(ss, @last_commit_time_sec, @last_commit_time_pri) * 1000, 0), 114); END PRINT 'RPO of database ' + @db_name + ' is ' + @RPO; END -- secondary database's last_commit_time -- correlated primary database's last_commit_timeFühren Sie
proc_calculate_RPOmit der group_id, replica_id und group_database_id der sekundären Zieldatenbank aus.EXECUTE proc_calculate_RPO @group_id = 'F176DD65-C3EE-4240-BA23-EA615F965C9B', @replica_id = '405554F6-3FDC-4593-A650-2067F5FABFFD', @group_database_id = '39F7942F-7B5E-42C5-977D-02E7FFA6C392';Die Ausgabe zeigt den RPO-Wert der Zieldatenbank des sekundären Replikats.
Überwachung von RTO und RPO
In diesem Abschnitt wird das Überwachen von Verfügbarkeitsgruppen für die Metriken RTO und RPO veranschaulicht. Diese Demonstration ähnelt dem GUI-Tutorial unter The Always On health model, part 2: Extending the health model (Always On-Integritätsmodell, Teil 2: Erweitern des Integritätsmodells).
Elemente der Schätzung der Failoverzeit (RTO) und der Schätzung potenzieller Datenverluste (RPO) werden im Facet „Datenbankreplikatstatus“ des Richtlinienmanagements bequem als Leistungsmetriken bereitgestellt. Weitere Informationen finden Sie unter Ansicht der richtlinienbasierten Managementfacetten auf einem SQL Server-Objekt. Sie können diese beiden Metriken nach einem Zeitplan überwachen und werden benachrichtigt, wenn die Metriken Ihre RTO bzw. RPO überschreiten.
Die angezeigten Skripts erstellen zwei Systemrichtlinien mit den folgenden Merkmalen, die basierend auf ihren jeweiligen Zeitplänen ausgeführt werden:
Eine RTO-Richtlinie mit einer Auswertung im 5-Minuten-Takt, bei der ein Fehler auftritt, wenn die geschätzte Failoverzeit 10 Minuten überschreitet
Eine RPO-Richtlinie mit einer Auswertung im 30-Minuten-Takt, bei der ein Fehler auftritt, wenn die geschätzte Failoverzeit 1 Stunde überschreitet
Beide Richtlinien weisen die gleich Konfiguration für alle Verfügbarkeitsreplikate auf.
Auf allen Servern werden Richtlinien ausgewertet, jedoch nur für die Verfügbarkeitsgruppen, bei denen das lokale Verfügbarkeitsreplikat das primäre Replikat darstellt. Wenn das lokale Verfügbarkeitsreplikat nicht das primäre Replikat ist, werden die Richtlinien nicht ausgewertet.
Richtlinienfehler werden praktischerweise auf dem Always On-Dashboard angezeigt, wenn Sie diese für das primäre Replikat anzeigen.
Führen Sie zum Erstellen der Richtlinien die folgenden Anweisungen für alle Serverinstanzen aus, die an der Verfügbarkeitsgruppe teilnehmen:
Starten Sie den SQL Server-Agent-Dienst , wenn er noch nicht gestartet wurde.
Wählen Sie in SQL Server Management Studio im Menü "Extras" die Option "Optionen" aus.
Wählen Sie auf der Registerkarte "AlwaysOn" von SQL Server die Option "Benutzerdefinierte AlwaysOn-Richtlinie aktivieren " aus, und wählen Sie "OK" aus.
Durch diese Einstellung können Sie ordnungsgemäß konfigurierte benutzerdefinierte Richtlinien auf dem Always On-Dashboard anzeigen.
Erstellen Sie eine richtlinienbasierte Verwaltungsbedingung mit den folgenden Spezifikationen:
-
Name:
RTO - Facet:Database Replica State (Zustand des Datenbankreplikats)
-
Feld:
Add(@EstimatedRecoveryTime, 60) - Operator: <=
-
Wert:
600
Diese Bedingung schlägt fehl, wenn die potenzielle Failoverzeit 10 Minuten überschreitet, einschließlich eines Mehraufwands von 60 Sekunden für die Fehlererkennung und das Failover.
-
Name:
Erstellen Sie eine zweite richtlinienbasierte Verwaltungsbedingung mit den folgenden Spezifikationen:
-
Name:
RPO - Facet:Database Replica State (Zustand des Datenbankreplikats)
-
Feld:
@EstimatedDataLoss - Operator: <=
-
Wert:
3600
Bei dieser Bedingung tritt ein Fehler auf, wenn der Datenverlust 1 Stunde überschreitet.
-
Name:
Erstellen Sie eine dritte richtlinienbasierte Verwaltungsbedingung mit den folgenden Spezifikationen:
-
Name:
IsPrimaryReplica - Facet:Verfügbarkeitsgruppe
-
Feld:
@LocalReplicaRole - Operator: =
-
Wert:
Primary
Diese Bedingung überprüft, ob das lokale Verfügbarkeitsreplikat für eine bestimmte Verfügbarkeitsgruppe das primäre Replikat ist.
-
Name:
Erstellen Sie eine richtlinienbasierte Verwaltungsrichtlinie mit den folgenden Spezifikationen:
Seite Allgemein:
Name:
CustomSecondaryDatabaseRTOBedingung überprüfen:
RTOFür Ziele:Alle DatabaseReplicaState in IsPrimaryReplica AvailabilityGroup
Durch diese Einstellung wird sichergestellt, dass die Richtlinie nur für Verfügbarkeitsgruppen ausgewertet wird, bei denen das lokale Verfügbarkeitsreplikat das primäre Replikat darstellt.
Auswertungsmodus:Nach Zeitplan
Zeitplan:CollectorSchedule_Every_5min
Aktiviert: Ausgewählt
Seite Beschreibung:
Kategorie:Availability database warnings (Warnungen zu Verfügbarkeitsdatenbanken)
Mit dieser Einstellung können die Ergebnisse der Richtlinienauswertung auf dem Always On-Dashboard angezeigt werden.
Beschreibung: Das aktuelle Replikat ist eine RTO, die 10 Minuten überschreitet. Hierbei wird von einem Mehraufwand von 1 Minute für die Erkennung und das Failover ausgegangen. Sie sollten Leistungsprobleme in der jeweiligen Serverinstanz sofort untersuchen.
Anzuzeigender Text:RTO wurde überschritten.
Erstellen Sie eine zweite richtlinienbasierte Verwaltungsrichtlinie mit den folgenden Spezifikationen:
Seite Allgemein:
-
Name:
CustomAvailabilityDatabaseRPO -
Bedingung überprüfen:
RPO - Für Ziele:Alle DatabaseReplicaState in IsPrimaryReplica AvailabilityGroup
- Auswertungsmodus:Nach Zeitplan
- Zeitplan:CollectorSchedule_Every_30min
- Aktiviert: Ausgewählt
-
Name:
Seite Beschreibung:
Kategorie:Availability database warnings (Warnungen zu Verfügbarkeitsdatenbanken)
Beschreibung: Die Verfügbarkeitsdatenbank hat Ihre RPO von einer Stunde überschritten. Sie sollten Leistungsprobleme in den Verfügbarkeitsreplikaten sofort untersuchen.
Anzuzeigender Text:RPO wurde überschritten.
Wenn Sie fertig sind, werden zwei neue SQL Server-Agent-Aufträge erstellt, eine für jeden Richtlinienauswertungszeitplan. Diese Aufträge sollten Namen haben, die mit syspolicy_check_schedule beginnen.
Sie können zur Überprüfen der Auswertungsergebnisse den Auftragsverlauf einsehen. Fehler bei der Auswertung werden auch im Windows-Anwendungsprotokoll (in der Ereignisanzeige) mit der Ereignis-ID 34052 erfasst. Sie können auch den SQL Server-Agent für das Senden von Warnungen für Richtlinienfehler konfigurieren. Weitere Informationen finden Sie unter Konfigurieren von Benachrichtigungen zum Benachrichtigen von Richtlinienadministratoren von Richtlinienfehlern.
Leistungsbezogene Problembehandlungsszenarien
Die folgende Tabelle enthält die allgemeinen leistungsbezogenen Problembehandlungsszenarien.
| Szenario | BESCHREIBUNG |
|---|---|
| Problembehandlung: Verfügbarkeitsgruppe hat RTO überschritten | Nach einem automatischen Failover oder einem geplanten manuellen Failover ohne Datenverlust überschreitet die Failoverzeit die RTO. Ein anderer Fall: Wenn Sie die Failoverzeit eines sekundären Replikats im synchronen Commitmodus (z.B. eines Partners für das automatische Failover) einschätzen, stellen Sie fest, dass diese Ihre RTO überschreitet. |
| Problembehandlung: Verfügbarkeitsgruppe hat RPO überschritten | Nachdem Sie ein erzwungenes manuelles Failover ausgeführt haben, ist der Datenverlust größer als Ihre RPO. Ein anderer Fall: Wenn Sie den möglichen Datenverlust eines sekundäres Replikats im asynchronen Commitmodus berechnen, stellen Sie fest, dass dieser Ihre RPO überschreitet. |
| Problembehandlung: Änderungen am primären Replikat spiegeln sich nicht im sekundären Replikat wider | Die Clientanwendung schließt eine Aktualisierung des primären Replikats erfolgreich ab, die Abfrage des sekundären Replikats zeigt jedoch an, dass die Änderung nicht angezeigt wird. |
Nützliche erweiterte Ereignisse
Für die Behandlung von Problemen mit Replikaten im Zustand Wird synchronisiert sind folgende erweiterte Ereignisse nützlich.
| Veranstaltungsname | Category | Channel | Verfügbarkeitsreplikat |
|---|---|---|---|
redo_caught_up |
Transaktionen | Debuggen | Secondary |
redo_worker_entry |
Transaktionen | Debuggen | Secondary |
hadr_transport_dump_message |
alwayson |
Debuggen | Primär |
hadr_worker_pool_task |
alwayson |
Debuggen | Primär |
hadr_dump_primary_progress |
alwayson |
Debuggen | Primär |
hadr_dump_log_progress |
alwayson |
Debuggen | Primär |
hadr_undo_of_redo_log_scan |
alwayson |
Analytic | Secondary |