Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server unter Linux
SQL Server unter Linux
In diesem Tutorial wird erläutert, wie Sie SQL Server-Verfügbarkeitsgruppen mit HPE Serviceguard für Linux konfigurieren, die auf lokalen oder Azure-basierten virtuellen Computern ausgeführt werden.
Eine Übersicht über die HPE Serviceguard Cluster finden Sie unter HPE Serviceguard Clusters.
Hinweis
Microsoft unterstützt die Datenverschiebung, die Verfügbarkeitsgruppe und die SQL Server-Komponente. Wenden Sie sich an HPE, um Unterstützung im Zusammenhang mit der Dokumentation der HPE Serviceguard-Clusterverwaltung und -Quorumverwaltung zu erhalten
Dieses Tutorial umfasst die folgenden Aufgaben:
- Installieren Sie SQL Server auf allen drei virtuellen Computern, die Sie in die Verfügbarkeitsgruppe aufnehmen möchten.
- Installieren Sie HPE Serviceguard auf den VMs.
- Erstellen Sie den HPE Serviceguard Cluster.
- Erstellen Sie das Lastenausgleichsmodul im Azure-Portal.
- Erstellen Sie die Verfügbarkeitsgruppe, und fügen Sie der Verfügbarkeitsgruppe eine Beispieldatenbank hinzu.
- Stellen Sie die SQL Server-Workload für die Verfügbarkeitsgruppe über serviceguard cluster manager bereit.
- Führen Sie ein automatisches Failover aus, und verbinden Sie den Knoten wieder mit dem Cluster.
Voraussetzungen
Erstellen Sie in Azure drei Linux-basierte VMs. Informationen zum Erstellen von Linux-basierten VMs in Azure finden Sie im Schnellstart: Erstellen eines virtuellen Linux-Computers im Azure-Portal. Stellen Sie beim Bereitstellen der VMs sicher, dass von HPE Serviceguard unterstützte Linux-Distributionen verwendet werden. Sie können die virtuellen Computer bei Bedarf auch lokal in einer lokalen Umgebung bereitstellen.
Ein Beispiel für eine unterstützte Distribution finden Sie unter HPE Serviceguard für Linux. Wenden Sie sich an HPE, wenn Sie weitere Informationen zur Unterstützung öffentlicher Cloudumgebungen benötigen.
Die Anweisungen in diesem Tutorial werden auf der Seite „HPE Serviceguard für Linux“ überprüft. Eine Testversion kann über HPE heruntergeladen werden.
SQL Server-Datenbankdateien zum Einbinden des Logical Volume (LVM) für alle VMs. Siehe Schnellstarthandbuch für Serviceguard Linux (HPE).
Stellen Sie sicher, dass die OpenJDK-Java-Laufzeit auf den VMs installiert ist. Das IBM Java SDK wird nicht unterstützt.
Installieren von SQL Server
Führen Sie auf allen drei virtuellen Computern einen der Schritte im folgenden Abschnitt basierend auf der Linux-Verteilung aus, die Sie für dieses Lernprogramm auswählen. Die Schritte installieren SQL Server und Tools.
Red Hat Enterprise Linux (RHEL)
SUSE Linux Enterprise Server (SLES)
Hinweis
Ab SQL Server 2025 (17.x) wird SUSE Linux Enterprise Server (SLES) nicht unterstützt.
Wenn Sie diesen Schritt abgeschlossen haben, haben Sie den SQL Server-Dienst und die Tools auf allen drei virtuellen Computern installiert, die an der Verfügbarkeitsgruppe teilnehmen werden.
Installieren von HPE Serviceguard auf den VMs
In diesem Schritt installieren Sie HPE Serviceguard für Linux auf allen drei VMs. In der folgenden Tabelle werden die Rollen beschrieben, die jeder Server im Cluster hat.
| Number of VMs (Anzahl von VMs) | HPE Serviceguard-Rolle | Replikatrolle der Microsoft SQL Server-Verfügbarkeitsgruppe |
|---|---|---|
| 1 | HPE Serviceguard-Clusterknoten | Primäres Replikat |
| 1 oder mehr | HPE Serviceguard-Clusterknoten | Sekundäres Replikat |
| 1 | HPE Serviceguard-Quorumserver | Konfigurationsreplikat |
Hinweis
In diesem Video von HPE erfahren Sie, wie Sie einen HPE Serviceguard Cluster über die Benutzeroberfläche installieren und konfigurieren.
Verwenden Sie die cminstaller-Methode, um Serviceguard zu installieren. Spezifische Anweisungen finden Sie unter den folgenden Links:
- Installieren von HPE Serviceguard für Linux auf zwei Knoten. Weitere Informationen finden Sie im Abschnitt Install_serviceguard_using_cminstaller.
- Installieren des HPE Serviceguard-Quorumservers auf dem dritten Knoten. Weitere Informationen finden Sie im Abschnitt Install_QS_from_the_ISO.
Nachdem Sie die Installation des HPE Serviceguard Clusters abgeschlossen haben, können Sie das Clusterverwaltungsportal auf TCP Port 5522 auf dem primären Replikatknoten aktivieren. Mit den folgenden Schritten wird der Firewall eine Regel hinzugefügt, um 5522 zuzulassen. Der folgende Befehl gilt für Red Hat Enterprise Linux (RHEL). Für andere Distributionen müssen Sie ähnliche Befehle ausführen:
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
Erstellen eines HPE Serviceguard-Clusters
Folgen Sie diesen Anweisungen, um den HPE Serviceguard-Cluster zu konfigurieren und zu erstellen. In diesem Schritt konfigurieren Sie auch den Quorumserver.
- Konfigurieren des Serviceguard-Quorum-Server auf dem dritten Knoten. Weitere Informationen finden Sie im Abschnitt Configure_QS.
- Konfigurieren und Erstellen des Serviceguard-Clusters auf den beiden anderen Knoten. Weitere Informationen finden Sie im Abschnitt Configure_and_create_Cluster.
Hinweis
Sie können die manuelle Installation Ihres HPE Serviceguard Clusters und Quorum umgehen, indem Sie die HPE Serviceguard for Linux (SGLX)-Erweiterung aus dem Azure VM Marketplace hinzufügen, wenn Sie Ihre VM erstellen.
Erstellen der Verfügbarkeitsgruppe und Hinzufügen einer Beispieldatenbank
In diesem Schritt erstellen Sie eine Verfügbarkeitsgruppe mit zwei oder mehr synchronen Replikaten und einem Nur-Konfigurationsreplikat, das Datenschutz bietet und möglicherweise auch hohe Verfügbarkeit bietet. Das folgende Diagramm veranschaulicht diese Architektur:
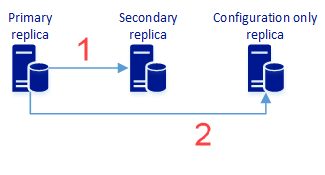
Eine synchrone Replikation von Benutzerdaten wird auf einem sekundären Replikat ausgeführt. Dieser Vorgang schließt auch Metadaten zur Konfiguration der Verfügbarkeitsgruppe ein.
Eine synchrone Replikation von Metadaten zur Konfiguration der Verfügbarkeitsgruppe wird ausgeführt. Benutzerdaten sind nicht enthalten.
Weitere Informationen finden Sie unter High availability and data protection for Availability Group configurations (Hochverfügbarkeit und Datenschutz für Verfügbarkeitsgruppenkonfigurationen).
Führen Sie die folgenden Schritte aus, um die Verfügbarkeitsgruppe zu erstellen:
- Aktivieren der Verfügbarkeitsgruppen und Neustart des mssql-Servers auf allen VMs, einschließlich dem Replikat nur für die Konfiguration.
-
Aktiverien einer
AlwaysOn_healthEreignis-Sitzung (optional) - Erstellen eines Zertifikats auf der primären VM
- Erstellen des Zertifikats auf sekundären Servern
- Erstellen der Datenbankspiegelungsendpunkte auf allen Replikaten
- Erstellen einer Verfügbarkeitsgruppe
- Verknüpfen der sekundären Replikate
- Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe
Aktivieren von Verfügbarkeitsgruppen und Neustarten von mssql-server
Aktivieren Sie Verfügbarkeitsgruppen auf allen Knoten, die eine SQL Server-Instanz hosten. Starten Sie dann „mssql-server“ neu. Führen Sie das folgende Skript auf allen drei Knoten aus:
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
Aktivieren einer AlwaysOn_health-Ereignissitzung (optional)
Aktivieren Sie optional erweiterte Ereignisse für AlwaysOn-Verfügbarkeitsgruppen, um bei der Diagnose von Ursachen zu helfen, wenn Sie eine Verfügbarkeitsgruppe behandeln. Führen Sie auf jeder SQL Server-Instanz den folgenden Befehl aus:
ALTER EVENT SESSION AlwaysOn_health ON SERVER
WITH (STARTUP_STATE = ON);
GO
Erstellen eines Zertifikats auf der primären VM
Das folgende Transact-SQL-Skript erstellt einen Hauptschlüssel und ein Zertifikat. Anschließend werden das Zertifikat und die Datei mit einem privaten Schlüssel gesichert. Aktualisieren Sie das Skript durch sichere Kennwörter. Stellen Sie eine Verbindung mit der primären SQL Server-Instanz her, und führen Sie das folgende Transact-SQL-Skript aus:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<private-key-password>'
);
Zu diesem Zeitpunkt weist das primäre SQL Server-Replikat ein Zertifikat unter /var/opt/mssql/data/dbm_certificate.cer und einen privaten Schlüssel unter var/opt/mssql/data/dbm_certificate.pvk auf. Kopieren Sie diese beiden Dateien auf allen Servern, die Verfügbarkeitsreplikate hosten, an denselben Ort. Um auf diese Dateien zuzugreifen, verwenden Sie den mssql Benutzer, oder erteilen Sie dem mssql Benutzer die Berechtigung.
Der folgende Befehl kopiert z.B. auf dem Quellserver die Dateien auf den Zielcomputer. Ersetzen Sie die node2-Werte durch den Namen des Hosts, auf dem die sekundäre SQL Server-Instanz ausgeführt wird. Kopieren Sie das Zertifikat auch auf das nur-Konfigurations-Replikat und führen Sie die folgenden Befehle auf diesem Knoten aus.
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
Führen Sie nun auf den sekundären VMs, auf denen die sekundäre Instanz und das Nur-Konfigurationsreplikat von SQL Server ausgeführt werden, die folgenden Befehle aus, damit der mssql Benutzer das kopierte Zertifikat besitzen kann:
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Erstellen des Zertifikats auf sekundären Servern
Das folgende Transact-SQL-Skript erstellt einen Hauptschlüssel und ein Zertifikat aus der Sicherung, die Sie auf dem primären SQL Server-Replikat erstellt haben. Aktualisieren Sie das Skript durch sichere Kennwörter. Das Entschlüsselungskennwort ist dasselbe Kennwort, das Sie zum Erstellen der .pvk Datei in einem früheren Schritt verwendet haben. Führen Sie das folgende Skript auf allen sekundären Servern mit Ausnahme des Konfigurationsreplikats aus, um das Zertifikat zu erstellen:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<private-key-password>'
);
Im vorherigen Beispiel ersetzen Sie <private-key-password> durch dasselbe Passwort, das Sie bei der Erstellung des Zertifikats auf dem primären Replikat verwendet haben.
Erstellen der Datenbankspiegelungsendpunkte auf allen Replikaten
Führen Sie in den primären und sekundären Replikaten die folgenden Befehle aus, um die Endpunkte für die Datenbankspiegelung zu erstellen:
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Hinweis
5022 ist der Standardport, der für den Datenbankspiegelungsendpunkt verwendet wird. Sie können ihn in jeden verfügbaren Port ändern.
Erstellen Sie im nur konfigurationsgeschützten Replikat den Endpunkt für die Datenbankspiegelung mithilfe des folgenden Befehls. Legen Sie den Wert für Role auf WITNESS fest, was die erforderliche Rolle für das nur für die Konfiguration bestimmte Replikat ist.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Erstellen der Verfügbarkeitsgruppe
Führen Sie die folgenden Befehle in der primären Replikatinstanz aus. Diese Befehle erstellen eine Verfügbarkeitsgruppe mit dem Namen ag1, für die cluster_type auf EXTERNAL festgelegt ist und die der Verfügbarkeitsgruppe die Berechtigung zum Erstellen von Datenbanken gewährt.
Bevor Sie die folgenden Skripts ausführen, ersetzen Sie die Platzhalter <node1>, <node2> und <node3> (nur Konfigurations-Replikate) durch die Namen der VMs, die Sie in den vorherigen Schritten erstellt haben.
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
Verbinden der sekundären Replikate
Führen Sie die folgenden Befehle auf allen sekundären Replikaten aus. Diese Befehle verknüpfen die sekundären Replikate mit der Verfügbarkeitsgruppe ag1 mit dem primären Replikat und stellen der Verfügbarkeitsgruppe ag1 Zugriff zum Erstellen von Datenbanken bereit.
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Hinzufügen einer Datenbank zu einer Verfügbarkeitsgruppe
Stellen Sie eine Verbindung mit dem primären Replikat her, und führen Sie die folgenden T-SQL-Befehle aus, um folgende Schritte auszuführen:
Erstellen Sie eine Beispieldatenbank mit dem Namen
db1, die Sie der Verfügbarkeitsgruppe hinzufügen.CREATE DATABASE [db1]; GOLegen Sie das Wiederherstellungsmodell der Datenbank auf „Vollständig“ fest. Für alle Datenbanken in einer Verfügbarkeitsgruppe ist das vollständige Wiederherstellungsmodell erforderlich.
ALTER DATABASE [db1] SET RECOVERY FULL;Sichern Sie die Datenbank. Eine Datenbank erfordert mindestens eine vollständige Sicherung, bevor Sie diese zu einer Verfügbarkeitsgruppe hinzufügen können.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Setzen Sie die Datenbank auf das Modell der vollständigen Wiederherstellung.
ALTER DATABASE [db1] SET RECOVERY FULL;Sichern Sie die Datenbank auf dem Datenträger.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Fügen Sie die Datenbank
db1zur Verfügbarkeitsgruppe hinzu.ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
Nachdem Sie die vorherigen Schritte abgeschlossen haben, wird eine ag1 Verfügbarkeitsgruppe angezeigt. Die drei VMs werden als Replikate mit einem primären Replikat, einem sekundären Replikat und einem nur Konfigurationsreplikat hinzugefügt.
ag1 enthält eine Datenbank.
Bereitstellen der Arbeitsauslastung für die SQL Server-Verfügbarkeitsgruppe (HPE Cluster-Manager)
Stellen Sie in HPE Serviceguard die SQL Server-Arbeitsauslastung in der Verfügbarkeitsgruppe über die Benutzeroberfläche des Serviceguard-Cluster-Managers bereit.
Stellen Sie die Arbeitsauslastung der Verfügbarkeitsgruppe bereit, und aktivieren Sie die Hochverfügbarkeit und die Notfallwiederherstellung (DR) über den Serviceguard-Cluster mithilfe der Serviceguard manager graphical user interface (grafischen Benutzeroberfläche des Serviceguard-Managers). Weitere Informationen finden Sie im Abschnitt Schützen von Microsoft SQL Server für Linux für Always On-Verfügbarkeitsgruppen.
Erstellen des Lastenausgleichs im Azure-Portal
Für Bereitstellungen in Azure Cloud erfordert HPE Serviceguard für Linux einen Lastenausgleich, um Clientverbindungen mit dem primären Replikat zu ermöglichen, um herkömmliche IP-Adressen zu ersetzen.
Öffnen Sie im Azure-Portal die Ressourcengruppe mit den Serviceguard-Clusterknoten oder virtuellen Computern.
Wählen Sie in der Ressourcengruppe Hinzufügen aus.
Suchen Sie nach „Lastenausgleich“, und wählen Sie dann in den Suchergebnissen den von Microsoft veröffentlichten Lastenausgleich aus.
Wählen Sie auf dem Blatt Lastenausgleich die Option Erstellen aus.
Konfigurieren Sie den Lastenausgleich wie folgt:
Einstellung value Name Name des Lastenausgleichs. Beispiel: SQLAvailabilityGroupLB.Typ Intern SKU „Basic“ oder „Standard“ Virtual Network Virtuelles Netzwerk, das für die VM Replikate verwendet wird Subnetz Subnetz, in dem SQL Server-Instanzen gehostet werden Zuweisung von IP-Adressen Statisch Private IP-Adresse Erstellen einer privaten IP-Adresse im Subnetz Abonnement Auswählen des betreffenden Abonnements Ressourcengruppe Auswählen der betroffenen Ressourcengruppe Ort Auswählen desselben Speicherorts wie für SQL-Knoten
Konfigurieren des Back-End-Pools
Der Back-End-Pool stellt die Adressen der beiden Instanzen dar, in denen der Serviceguard-Cluster konfiguriert ist.
- Wählen Sie in Ihrer Ressourcengruppe den zuvor erstellten Load Balancer aus.
- Wechseln Sie zu "Einstellungen>"-Back-End-Pools, und wählen Sie "Hinzufügen" aus, um einen Back-End-Adresspool zu erstellen.
- Geben Sie im Bereich Back-End-Pool hinzufügen unter Name einen Namen für den Back-End-Pool ein.
- Wählen Sie unter Verknüpft mit die Option Virtueller Computer aus.
- Wählen Sie die virtuellen Computer in der Umgebung aus, und ordnen Sie ihnen jeweils die entsprechende IP-Adresse zu.
- Wählen Sie Hinzufügen aus.
Erstellen eines Tests
Der Test definiert, wie Azure überprüft, welcher Serviceguard-Clusterknoten das primäre Replikat ist. Azure testet den Dienst auf der Grundlage der IP-Adresse an einem Port, den Sie beim Erstellen des Tests definieren.
Wählen Sie im Bereich Einstellungen für Lastenausgleich die Option Integritätstests aus.
Wählen Sie im Bereich Integritätstests die Option Hinzufügen aus.
Verwenden Sie dabei die folgenden Werte:
Einstellung value Name Name für den Test. Beispiel: SQLAGPrimaryReplicaProbe.Protocol TCP Hafen Sie können jeden verfügbaren Port verwenden. Beispiel: 59999. Interval 5 Fehlerhafter Schwellenwert 2 Wählen Sie OK aus.
Melden Sie sich bei allen Ihren virtuellen Computern an, und öffnen Sie den Testport mithilfe der folgenden Befehle:
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
Azure erstellt den Test und verwendet ihn dann, um den Serviceguard-Knoten zu testen, auf dem die primäre Replikatinstanz der Verfügbarkeitsgruppe ausgeführt wird. Denken Sie an den port, den Sie konfiguriert haben (59999), der für die Bereitstellung der AG im Serviceguard-Cluster erforderlich ist.
Festlegen der Lastenausgleichsregeln
Die Lastenausgleichsregeln konfigurieren, wie der Lastenausgleich Datenverkehr an den Serviceguard-Knoten weiterleitet, der das primäre Replikat im Cluster ist. Aktivieren Sie für diesen Lastenausgleich Direct Server Return, da jeweils nur ein Serviceguard-Clusterknoten ein primäres Replikat sein kann.
Wählen Sie auf den Einstellungen des Lastenausgleichs die Option " Lastenausgleichsregeln" aus.
Wählen Sie unter Lastenausgleichsregeln"Hinzufügen" aus.
Konfigurieren Sie die Lastenausgleichsregel mit den folgenden Einstellungen:
Einstellung value Name Name für die Lastenausgleichsregeln. Beispiel: SQLAGPrimaryReplicaListener.Protocol TCP Hafen 1433 Back-End-Port 1433. Dieser Wert wird ignoriert, da diese Regel eine Floating IP verwendet. Probe Verwenden Sie den Namen des Tests, den Sie für diesen Load Balancer erstellt haben. Sitzungspersistenz Keine Leerlaufzeitüberschreitung (Minuten) 4 Floating-IP Aktiviert Wählen Sie OK aus.
Azure konfiguriert die Lastenausgleichsregel. Jetzt ist der Lastenausgleich so konfiguriert, dass Datenverkehr an den Serviceguard-Knoten weitergeleitet wird, der die primäre Replikatinstanz im Cluster ist.
Notieren Sie sich die Frontend-IP-Adresse des LbReadWriteIP Load Balancers, die Sie für das Bereitstellen der AG im Serviceguard-Cluster benötigen.
Die Ressourcengruppe verfügt nun über einen mit allen Serviceguard-Computern verbundenen Lastenausgleich. Der Lastenausgleich enthält auch eine IP-Adresse für die Clients, um eine Verbindung mit der primären Replikatinstanz im Cluster herzustellen, sodass jeder Computer, der ein primäres Replikat ist, auf Anforderungen für die Verfügbarkeitsgruppe reagieren kann.
Ein automatisches Failover ausführen und den Knoten mit dem Cluster verknüpfen
Führen Sie für den automatischen Failover-Test das primäre Replikat offline, indem Sie es ausschalten. Diese Aktion repliziert die plötzliche Nichtverfügbarkeit des primären Knotens. Das erwartete Verhalten sieht wie folgt aus:
Der Cluster-Manager stuft eines der sekundären Replikate in der Verfügbarkeitsgruppe auf „Primär“ hoch.
Das ausgefallene primäre Replikat tritt dem Cluster automatisch bei, nachdem es neu gestartet wurde. Der Clustermanager macht es zu einem sekundären Replikat.
Informationen zu HPE Serviceguard finden Sie unter Testen des Setups für die Failoverbereitschaft.