Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server unter Linux
SQL Server unter Linux
In diesem Lernprogramm wird gezeigt, wie Sie eine Verfügbarkeitsgruppe (AG) für SQL Server unter Linux erstellen und konfigurieren. Im Gegensatz zu SQL Server 2016 (13.x) und früheren Versionen unter Windows können Sie eine Verfügbarkeitsgruppe (AG) mit oder ohne Erstellung des zugrunde liegenden Pacemaker-Clusters aktivieren. Die Integration mit dem Cluster erfolgt bei Bedarf später.
Im Tutorial werden die folgenden Aufgaben behandelt:
- Aktivieren von Verfügbarkeitsgruppen
- Erstellen von Verfügbarkeitsgruppenendpunkten und -zertifikaten
- Verwenden von SQL Server Management Studio (SSMS) oder Transact-SQL zum Erstellen einer Verfügbarkeitsgruppe
- Erstellen des SQL Server-Anmeldenamens und der Berechtigungen für Pacemaker
- Erstellen von Verfügbarkeitsgruppenressourcen in einem Pacemaker-Cluster (nur externer Typ)
Voraussetzungen
Stellen Sie den Pacemaker-Cluster mit Hochverfügbarkeit wie in Deploy a Pacemaker cluster for SQL Server on Linux (Bereitstellen eines Pacemaker-Clusters für SQL Server für Linux) beschrieben bereit.
Aktivieren der Verfügbarkeitsgruppenfunktion
Anders als unter Windows können Sie PowerShell oder SQL Server Configuration Manager nicht verwenden, um die Verfügbarkeitsgruppenfunktion (AG) zu aktivieren. Unter Linux können Sie das Feature für Verfügbarkeitsgruppen auf zwei Arten aktivieren: verwenden Sie das Hilfsprogramm "mssql-conf ", oder bearbeiten Sie die mssql.conf Datei manuell.
Wichtig
Sie müssen das AG-Feature für nur Konfigurationsreplikate aktivieren, auch in SQL Server Express.
Verwenden des mssql-conf-Hilfsprogramms
Führen Sie in einer Eingabeaufforderung den folgenden Befehl aus:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Bearbeiten der mssql.conf-Datei
Sie können die mssql.conf Datei auch ändern, die sich unter dem /var/opt/mssql Ordner befindet. Fügen Sie die folgenden Zeilen hinzu:
[hadr]
hadr.hadrenabled = 1
SQL Server neu starten
Nach dem Aktivieren von Verfügbarkeitsgruppen müssen Sie SQL Server neu starten. Verwenden Sie den folgenden Befehl:
sudo systemctl restart mssql-server
Erstellen der Verfügbarkeitsgruppenendpunkte und -zertifikate
Eine Verfügbarkeitsgruppe verwendet TCP-Endpunkte für die Kommunikation. Unter Linux unterstützt SQL Server Endpunkte für eine AG nur, wenn Sie Zertifikate für die Authentifizierung verwenden. Sie müssen das Zertifikat aus einer Instanz auf allen anderen Instanzen wiederherstellen, die als Replikate an derselben AG teilnehmen. Sie benötigen den Zertifikatsprozess auch für ein reines Konfigurationsreplikat.
Sie können nur Endpunkte erstellen und Zertifikate mithilfe von Transact-SQL wiederherstellen. Sie können auch Nicht-SQL Server-generierte Zertifikate verwenden. Außerdem benötigen Sie einen Prozess zum Verwalten und Ersetzen von Zertifikaten, die ablaufen.
Wichtig
Wenn Sie den Assistenten von SQL Server Management Studio verwenden möchten, um die Verfügbarkeitsgruppe zu erstellen, müssen Sie die Zertifikate mit Transact-SQL unter Linux erstellen und wiederherstellen.
Vollständige Syntax zu den optionen, die für die verschiedenen Befehle (einschließlich Sicherheit) verfügbar sind, finden Sie unter:
Hinweis
Obwohl Sie eine Verfügbarkeitsgruppe erstellen, wird der Endpunkttyp FOR DATABASE_MIRRORING verwendet, da einige zugrunde liegende Aspekte einst mit diesem mittlerweile veralteten Feature geteilt wurden.
In diesem Beispiel werden Zertifikate für eine Konfiguration mit drei Knoten erstellt. Die Instanznamen sind LinAGN1, LinAGN2 und LinAGN3.
Führen Sie auf
LinAGN1das folgende Skript aus, um den Hauptschlüssel, das Zertifikat und den Endpunkt zu erstellen, und sichern Sie das Zertifikat. In diesem Beispiel wird der typische TCP-Port 5022 für den Endpunkt verwendet.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL ); GOMachen Sie das Gleiche auf
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL ); GOFühren Sie schließlich die gleiche Sequenz auf
LinAGN3aus:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL ); GOVerwenden Sie
scpoder ein anderes Dienstprogramm, um die Sicherungen des Zertifikats auf jeden Knoten zu kopieren, den Sie in die Verfügbarkeitsgruppe (AG) einbeziehen möchten.In diesem Beispiel:
- Kopieren Sie
LinAGN1_Cert.cerinLinAGN2undLinAGN3. - Kopieren Sie
LinAGN2_Cert.cerinLinAGN1undLinAGN3. - Kopieren Sie
LinAGN3_Cert.cerinLinAGN1undLinAGN2.
- Kopieren Sie
Ändern Sie den Besitzer und die Gruppe, die mit den kopierten Zertifikatsdateien verbunden sind, auf
mssql.sudo chown mssql:mssql <CertFileName>Erstellen Sie auf
LinAGN2die Anmeldenamen und Benutzer auf Instanzebene, dieLinAGN3undLinAGN1zugeordnet sind.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOAchtung
Ihr Kennwort sollte der standardmäßigen Kennwortrichtlinie von SQL Server folgen. Ein Standardkennwort enthält mindestens acht Zeichen, die aus drei der folgenden vier Kategorien stammen müssen: Großbuchstaben, Kleinbuchstaben, Grundzahlen (0–9) und Symbole. Kennwörter können bis zu 128 Zeichen lang sein. Verwenden Sie möglichst lange und komplexe Kennwörter.
Stellen Sie
LinAGN2_CertundLinAGN3_CertaufLinAGN1wieder her. Die Zertifikate der anderen Replikate sind ein wichtiger Aspekt der Kommunikation und Sicherheit der Verfügbarkeitsgruppe.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOErteilen Sie den Anmeldungen, die
LinAGN2undLinAGN3zugeordnet sind, die Berechtigung, sich mit dem Endpunkt aufLinAGN1zu verbinden.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login;Erstellen Sie auf
LinAGN1die Anmeldenamen und Benutzer auf Instanzebene, dieLinAGN3undLinAGN2zugeordnet sind.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GOStellen Sie
LinAGN1_CertundLinAGN3_CertaufLinAGN2wieder her.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOErteilen Sie den Anmeldungen, die
LinAGN1undLinAGN3zugeordnet sind, die Berechtigung, sich mit dem Endpunkt aufLinAGN2zu verbinden.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOErstellen Sie auf
LinAGN1die Anmeldenamen und Benutzer auf Instanzebene, dieLinAGN2undLinAGN3zugeordnet sind.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<password>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GOStellen Sie
LinAGN1_CertundLinAGN2_CertaufLinAGN3wieder her.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOErteilen Sie den Anmeldungen, die
LinAG1undLinAGN2zugeordnet sind, die Berechtigung, sich mit dem Endpunkt aufLinAGN3zu verbinden.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Erstellen der Verfügbarkeitsgruppe
In diesem Abschnitt wird gezeigt, wie Sie SQL Server Management Studio (SSMS) oder Transact-SQL verwenden, um die Verfügbarkeitsgruppe für SQL Server zu erstellen.
Verwenden Sie SQL Server Management Studio
In diesem Abschnitt wird gezeigt, wie mithilfe von SSMS mit dem neuen Verfügbarkeitsgruppenassistenten eine Verfügbarkeitsgruppe mit dem Clustertyp „Extern“ erstellt wird.
Erweitern Sie in SSMS Hochverfügbarkeit mit Always On, klicken Sie mit der rechten Maustaste auf Verfügbarkeitsgruppen, und wählen Sie dann Assistent für neue Verfügbarkeitsgruppen aus.
Wählen Sie im Dialogfeld „Einführung“ die Option Weiter aus.
Geben Sie im Dialogfeld 'Verfügbarkeitsgruppenoptionen angeben' einen Namen für die AG ein, und wählen Sie einen Clustertyp
EXTERNALoderNONEin der Dropdownliste aus. Verwenden SieEXTERNAL, wenn Sie Pacemaker bereitstellen. Verwenden SieNONEfür spezielle Szenarien, wie z. B. Lese-Skalierung. Die Option für die Zustandserkennung auf Datenbankebene ist optional. Weitere Informationen zu dieser Option finden Sie unter Failover-Option für die Integritätserkennung auf Datenbankebene der Verfügbarkeitsgruppe. Wählen Sie Weiter aus.
Wählen Sie im Dialogfeld "Datenbanken auswählen" die Datenbanken aus, die an der AG teilnehmen sollen. Jede Datenbank muss über eine vollständige Sicherung verfügen, bevor Sie sie einer AG hinzufügen können. Wählen Sie Weiter aus.
Wählen Sie im Dialogfeld „Replikate angeben“ die Option Replikat hinzufügen aus.
Geben Sie im Dialogfeld „Verbindung mit Server herstellen“ den Namen der Linux-Instanz von SQL Server, die das sekundäre Replikat sein wird, und die Anmeldeinformationen zum Herstellen einer Verbindung ein. Wählen Sie Verbinden.
Wiederholen Sie die vorherigen beiden Schritte für die Instanz, die ein Replikat im Modus „Nur Konfiguration“ oder ein anderes sekundäres Replikat enthalten soll.
Alle drei Instanzen werden im Dialogfeld "Replikate angeben" angezeigt. Wenn Sie einen Clustertyp "Extern" verwenden, stellen Sie sicher, dass der Verfügbarkeitsmodus des sekundären Replikats, das ein echtes sekundäres Replikat ist, mit dem des primären Replikats übereinstimmt und der Failover-Modus auf "Extern" gesetzt ist. Wählen Sie für das nur zur Konfiguration verwendete Replikat den Verfügbarkeitsmodus "Nur Konfiguration" aus.
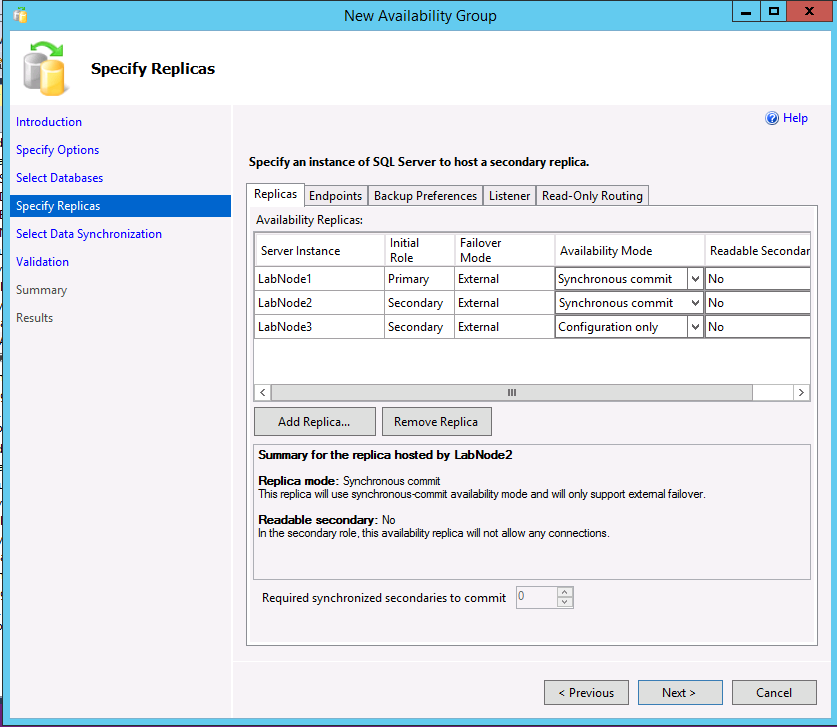
Das folgende Beispiel zeigt eine AG (Verfügbarkeitsgruppe) mit zwei Replikaten, den Cluster-Typ „Extern“ und ein Replikat im Modus „Nur Konfiguration“.
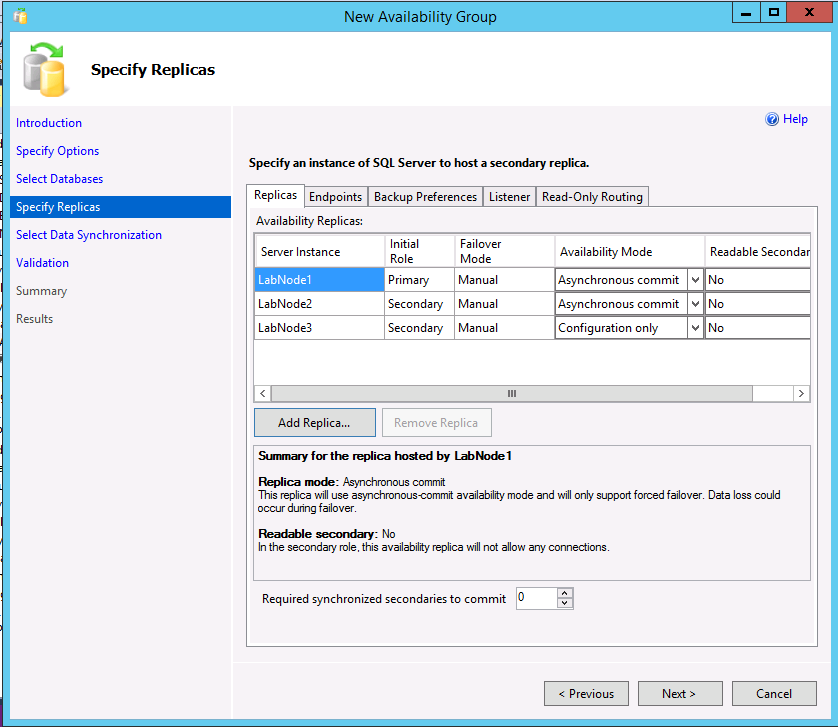
Das folgende Beispiel zeigt eine Verfügbarkeitsgruppe (AG) mit zwei Replikaten, einem Clustertyp von "Keine" und einem Replikat im Modus „Nur Konfiguration“.
Wenn Sie die Sicherungseinstellungen ändern möchten, wählen Sie die Registerkarte "Sicherungseinstellungen" aus. Weitere Informationen zu Sicherungseinstellungen mit AGs finden Sie unter Konfigurieren von Sicherungen auf sekundären Replikaten einer AlwaysOn-Verfügbarkeitsgruppe.
Wenn Sie lesbare Secondärdateien verwenden oder eine AG mit einem Clustertyp "Keine" zum Lesen erstellen, können Sie einen Listener erstellen, indem Sie die Registerkarte "Listener " auswählen. Sie können später auch einen Listener hinzufügen. Um einen Listener zu erstellen, wählen Sie die Option " Listener für Verfügbarkeitsgruppen erstellen " aus, und geben Sie einen Namen, einen TCP-/IP-Port ein, und ob eine statische oder automatisch zugewiesene DHCP-IP-Adresse verwendet werden soll. Bei einer AG mit einem Clustertyp "None" sollte die IP statisch sein und auf die IP-Adresse der primären Adresse festgelegt werden.

Wenn Sie einen Listener für lesbare Szenarien erstellen, erlaubt SSMS die Erstellung des schreibgeschützten Routings über den Assistenten. Sie können sie auch später über SSMS oder Transact-SQL hinzufügen. So fügen Sie das schreibgeschützte Routing jetzt hinzu:
Klicken Sie auf die Registerkarte „Read-Only Routing“.
Geben Sie die URLs für die schreibgeschützten Replikate ein. Diese URLs ähneln den Endpunkten, mit dem Unterschied, dass sie anstelle des Endpunkts den Port der Instanz verwenden.
- Wählen Sie die einzelnen URLs und weiter unten die lesbaren Replikate aus. Um mehrere auszuwählen, halten Sie die UMSCHALTTASTE gedrückt, oder ziehen Sie die Maus.
Wählen Sie Weiter aus.
Wählen Sie aus, wie die sekundären Replikate initialisiert werden sollen. Im Standardfall wird das automatische Seeding verwendet, das den gleichen Pfad auf allen an der Verfügbarkeitsgruppe beteiligten Servern benötigt. Sie können den Assistenten nutzen, um eine Sicherung, Kopie und Wiederherstellung auszuführen (zweite Option); oder ihn beauftragen, sich zu verbinden, wenn Sie die Datenbank manuell gesichert, kopiert und auf den Replikaten wiederhergestellt haben (dritte Option); oder die Datenbank später hinzufügen (letzte Option). Wie bei Zertifikaten, wenn Sie Sicherungen manuell erstellen und kopieren, legen Sie Berechtigungen für die Sicherungsdateien für die anderen Replikate fest. Wählen Sie Weiter aus.
Wenn der Assistent im Validierungsdialog für alle Prüfungen keinen Erfolg zurückgibt, untersuchen Sie weiter. Einige Warnungen sind akzeptabel und nicht fatal, wie beispielsweise wenn Sie keinen Listener erstellen. Wählen Sie Weiter aus.
Wählen Sie im Dialogfeld „Zusammenfassung“ die Option Fertig stellen aus. Der Prozess zur Erstellung der AG beginnt.
Nachdem die Verfügbarkeitsgruppe erstellt wurde, wählen Sie auf der Registerkarte „Ergebnisse“ die Option Schließen aus. Jetzt können Sie die Verfügbarkeitsgruppe auf den Replikaten in den dynamischen Verwaltungssichten und unter dem Ordner „Hochverfügbarkeit mit Always On“ in SSMS sehen.




Verwenden von Transact-SQL
Dieser Abschnitt enthält Beispiele für das Erstellen einer Verfügbarkeitsgruppe mithilfe von Transact-SQL. Sie können den Listener und das schreibgeschützte Routing nach dem Erstellen der AG konfigurieren. Sie können die AG selbst mit ALTER AVAILABILITY GROUP ändern, aber Sie können den Clustertyp in SQL Server 2017 (14.x) nicht ändern. Wenn Sie keine Verfügbarkeitsgruppe mit dem Clustertyp „Extern“ erstellen wollten, müssen Sie sie löschen, und neu mit dem Clustertyp „Keine“ erstellen. Weitere Informationen und andere Optionen finden Sie unter den folgenden Links:
- VERFÜGBARKEITSGRUPPE ERSTELLEN (Transact-SQL)
- VERÄNDERN VERFÜGBARKEITSGRUPPE (Transact-SQL)
- Schreibgeschütztes Routing für eine Always On-Verfügbarkeitsgruppe konfigurieren
- Konfigurieren eines Listeners für Always On-Verfügbarkeitsgruppen
Beispiel A: Zwei Replikate mit einem Replikat im Modus „Nur Konfiguration“ (externer Clustertyp)
Dieses Beispiel zeigt, wie Sie eine Verfügbarkeitsgruppe („AG“) mit zwei Replikaten erstellen, die ein Replikat im Modus „Nur Konfiguration“ verwendet.
Führen Sie die folgende Anweisung auf dem Knoten aus, der als primäres Replikat fungiert und eine vollständige Kopie der Datenbanken mit Lese- und Schreibzugriff enthält. In diesem Beispiel wird das automatische Seeding verwendet.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY ); GOFühren Sie in einem Abfragefenster, das mit dem anderen Replikat verbunden ist, die folgende Anweisung aus, um das Replikat mit der AG zu verbinden und den Seedingprozess vom primären zum sekundären Replikat zu initiieren.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOFühren Sie in einem Abfragefenster, das nur mit dem Konfigurationsreplikat verbunden ist, die folgende Anweisung aus, um es mit der AG zu verbinden.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Beispiel B: Drei Replikate mit schreibgeschütztem Routing (externer Clustertyp)
Dieses Beispiel zeigt drei vollständige Replikate und wie Sie das schreibgeschützte Routing als Teil der ersten AG-Erstellung konfigurieren können.
Führen Sie die folgende Anweisung auf dem Knoten aus, der als primäres Replikat fungiert und eine vollständige Kopie der Datenbanken mit Lese- und Schreibzugriff enthält. In diesem Beispiel wird das automatische Seeding verwendet.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOBei dieser Konfiguration sind einige Punkte zu beachten:
-
AGNameist der Name der AG (Aktiengesellschaft). -
DBNameist der Name der Datenbank, die Sie mit der AG verwenden. Dies kann auch eine Liste mit durch Kommas getrennte Namen sein. -
ListenerNameist ein Name, der sich von einem der zugrunde liegenden Server oder Knoten unterscheidet. Es ist zusammen mitIPAddressDNS registriert. -
IPAddressist eine IP-Adresse, die zugeordnetListenerNameist. Es ist auch einzigartig und nicht identisch mit einem der Server oder Knoten. Anwendungen und Endbenutzer verwenden entwederListenerNameoderIPAddress, um eine Anbindung an die AG herzustellen.-
SubnetMaskist die Subnetzmaske vonIPAddress. In SQL Server 2019 (15.x) und früheren Versionen ist dieser Wert255.255.255.255. In SQL Server 2022 (16.x) und höheren Versionen lautet0.0.0.0dieser Wert .
-
-
Führen Sie in einem Abfragefenster, das mit dem anderen Replikat verbunden ist, die folgende Anweisung aus, um das Replikat mit der AG zu verbinden und den Seedingprozess vom primären zum sekundären Replikat zu initiieren.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOWiederholen Sie Schritt 2 für das dritte Replikat.
Beispiel C: Zwei Replikas mit schreibgeschütztem Routing (Cluster-Typ: Keiner)
In diesem Beispiel wird gezeigt, wie eine Konfiguration mit zwei Replikaten mit dem Clustertyp „Keine“ erstellt wird. Verwenden Sie diese Konfiguration für das Lese-Skalierungs-Szenario, bei dem kein Failover erwartet wird. In diesem Schritt wird der Listener erstellt, der tatsächlich das primäre Replikat und das schreibgeschützte Routing mithilfe der Roundrobin-Funktionalität ist.
Führen Sie die folgende Anweisung auf dem Knoten aus, der als primäres Replikat fungiert und eine vollständige Kopie der Datenbanken mit Lese- und Schreibzugriff enthält. In diesem Beispiel wird das automatische Seeding verwendet.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = NONE) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>', FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE( ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name')) ), SECONDARY_ROLE( ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>' ) ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>', FAILOVER_MODE = MANUAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ('LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name') )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>') ), LISTENER '<ListenerName>' (WITH IP = ( '<PrimaryReplicaIPAddress>', '<SubnetMask>'), Port = <PortOfListener> ); GOIn diesem Beispiel:
-
AGNameist der Name der AG (Aktiengesellschaft). -
DBNameist der Name der Datenbank, die Sie mit der AG verwenden. Dies kann auch eine Liste mit durch Kommas getrennte Namen sein. -
PortOfEndpointist die portnummer, die vom von Ihnen erstellten Endpunkt verwendet wird.-
PortOfInstanceist die Portnummer, die von der Instanz von SQL Server verwendet wird.
-
-
ListenerNameist ein Name, der sich von einem der zugrunde liegenden Replikate unterscheidet, aber nicht tatsächlich verwendet wird. -
PrimaryReplicaIPAddressist die IP-Adresse des primären Replikats.-
SubnetMaskist die Subnetzmaske vonIPAddress. In SQL Server 2019 (15.x) und früheren Versionen ist dieser Wert255.255.255.255. In SQL Server 2022 (16.x) und höheren Versionen lautet0.0.0.0dieser Wert .
-
-
Binden Sie das sekundäre Replikat in die Verfügbarkeitsgruppe ein und initiieren Sie das automatische Seeding.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Erstellen des SQL Server-Anmeldenamens und der Berechtigungen für Pacemaker
Ein Pacemaker-Hochverfügbarkeitscluster, der SQL Server auf Linux verwendet, benötigt Zugriff auf die SQL Server-Instanz sowie Berechtigungen für die Verfügbarkeitsgruppe selbst. Diese Schritte erstellen die Anmeldung und die zugehörigen Berechtigungen sowie eine Datei, die Pacemaker angibt, wie sie sich bei SQL Server authentifizieren können.
Führen Sie in einem Abfragefenster, das mit dem ersten Replikat verbunden ist, das folgende Skript aus:
CREATE LOGIN PMLogin WITH PASSWORD = '<password>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOGeben Sie auf Knoten 1 den Befehl ein:
sudo emacs /var/opt/mssql/secrets/passwdMit diesem Befehl wird der Emacs-Editor geöffnet.
Geben Sie die beiden folgenden Zeilen in den Editor ein:
PMLogin <password>Halten Sie die
Ctrl-Taste gedrückt, drücken SieXund anschließendC, um die Datei zu beenden und zu speichern.Führen Sie folgende Befehle aus:
sudo chmod 400 /var/opt/mssql/secrets/passwdum die Datei zu sperren.
Wiederholen Sie die Schritte 1 bis 5 auf den anderen Servern, die als Replikate dienen.
Erstellen der Verfügbarkeitsgruppenressourcen im Pacemaker-Cluster (nur „Extern“)
Nachdem Sie eine AG in SQL Server erstellt haben, müssen Sie die entsprechenden Ressourcen in Pacemaker erstellen, wenn Sie einen Clustertyp "External" angeben. Eine AG benötigt zwei Ressourcen: die Verfügbarkeitsgruppenressource und eine IP-Adressressource. Das Konfigurieren der IP-Adressressource ist optional, wenn Sie keinen Listener verwenden. Es ist jedoch ratsam, wenn Sie Zuhörerfunktionen benötigen.
Die von Ihnen erstellte AG-Ressource ist ein Ressourcentyp, der als Klon bezeichnet wird. Die AG-Ressource enthält Kopien auf jedem Knoten und eine steuernde Ressource, die als Master bezeichnet wird. Der Master ist dem Server zugeordnet, auf dem das primäre Replikat gehostet wird. Die anderen Ressourcen hosten sekundäre Replikate (regulär oder nur-konfiguration) und können in einem Failover zum master heraufgestuft werden.
Hinweis
In SQL Server 2025 (17.x) mit kumulativem Update (CU) 3 und höher ist Pacemaker HA Agent v2 (Preview) für Red Hat Enterprise Linux (RHEL) und Ubuntu über das mssql-server-ha Paket verfügbar. Nicht-Produktionsumgebungen können den Pacemaker HA Agent v2 auswerten. Der vorhandene Pacemaker HA-Agent (v1) wird für Produktionsbereitstellungen vollständig unterstützt. Weitere Informationen finden Sie unter Pacemaker HA Agent v2 (Vorschau).
Pacemaker HA Agent v1
Erstellen Sie die AG-Ressource in Pacemaker mithilfe des Pacemaker HA-Agents (v1): (
ocf:mssql:ag)sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s promotable notify=trueIn diesem Beispiel ist
NameForAGResourceder eindeutige Name, den Sie dieser Clusterressource für die AG zuweisen, undAGNameist der Name der AG, die Sie erstellt haben.Erstellen Sie die IP-Adressressource für das Application Gateway (AG), die Sie der Listener-Funktionalität zuordnen.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>In diesem Beispiel steht
NameForIPResourcefür den eindeutigen Namen der IP-Ressource, undIPAddressist die statische IP-Adresse, die Sie der Ressource zuweisen.Um sicherzustellen, dass die IP-Adresse und die AG-Ressource auf demselben Knoten ausgeführt werden, konfigurieren Sie eine Colocation-Einschränkung.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYIn diesem Beispiel
NameForIPResourceist der Name der IP-Ressource undNameForAGResourceder Name für die AG-Ressource.Erstellen Sie eine Abhängigkeitsbedingung, um sicherzustellen, dass die AG-Ressource verfügbar ist, bevor die IP-Adresse in Betrieb genommen wird. Während die Colocation-Einschränkung eine Sortiereinschränkung impliziert, erzwingt dieser Schritt sie.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>In diesem Beispiel
NameForIPResourceist der Name der IP-Ressource undNameForAGResourceder Name für die AG-Ressource.
Pacemaker HA Agent v2 (Vorschau)
Pacemaker HA Agent v2 verwendet eine dienstbasierte Architektur. Der Agent wird als dedizierter Systemdienst mit dem Namen mssql-pcsag ausgeführt, der für die Verarbeitung von hochverfügbaren SQL Server-spezifischen Vorgängen und die Kommunikation mit Pacemaker verantwortlich ist.
Der mssql-pcsag Dienst wird mithilfe standardmäßiger Systemdienststeuerelemente verwaltet. Sie können den Status dieses Diensts nach Bedarf mithilfe der folgenden Befehle starten, beenden, neu starten und überprüfen:
sudo systemctl start mssql-pcsag # Start the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl stop mssql-pcsag # Stop the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl restart mssql-pcsag # Restart the Pacemaker HA agent v2 (mssql-pcsag) service
sudo systemctl status mssql-pcsag # Check the status of the Pacemaker HA agent v2 (mssql-pcsag) service
Pacemaker interagiert über den mssql-pcsag Dienst mit SQL Server-Verfügbarkeitsgruppen. Damit verfügbarkeitsgruppenüberwachung und Failover ordnungsgemäß funktionieren:
- Der Pacemaker-Cluster muss ausgeführt werden.
- Der
mssql-pcsagDienst muss ausgeführt werden.
Während Pacemaker und mssql-pcsag als separate Komponenten bereitgestellt werden, arbeiten sie zur Laufzeit zusammen. Wenn entweder Pacemaker oder der mssql-pcsag-Dienst beendet wird, funktionieren die Failover-Vorgänge der Verfügbarkeitsgruppe nicht wie erwartet.
Hinweis
Durch den Neustart des mssql-pcsag Diensts wird SQL Server nicht neu gestartet. Ebenso startet der Neustart von SQL Server den Pacemaker HA-Agent nicht automatisch neu. Überprüfen Sie, ob beide Dienste während der Problembehandlung ausgeführt werden.
Pacemaker HA Agent v2 führt Zuverlässigkeits- und Leistungsverbesserungen gegenüber dem vorherigen Agenten ein, darunter:
Verbesserte Failoverleistung, um geplante und ungeplante Failoverzeiten zu reduzieren.
Unterstützung für flexible automatische Failover-Richtlinien, einschließlich Konfiguration der Ausfallbedingungsebene und des Timeouts zur Gesundheitsprüfung.
Beispiel: Die folgende Transact-SQL Anweisung ändert die Fehlerbedingungsebene einer vorhandenen Verfügbarkeitsgruppe mit dem Namen AG1 auf Ebene 2:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 2);Beispiel: Die folgende Transact-SQL-Anweisung ändert den Timeoutschwellenwert für die Integritätsprüfung einer vorhandenen Verfügbarkeitsgruppe mit dem Namen AG1 auf 60.000 Millisekunden (60 Sekunden).
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT = 60000);Beispiel: Nach dem Anwenden der Konfiguration verwenden Sie die folgende Transact-SQL-Anweisung, um die konfigurierte Fehlerzustandsstufe und das Integritätsprüfungs-Timeout für Verfügbarkeitsgruppen zu überprüfen.
SELECT failure_condition_level, health_check_timeout FROM sys.availability_groups;Unterstützung für TLS 1.3 für die Kommunikation zwischen dem Pacemaker-Cluster und SQL Server.
Erstellen Sie die AG-Ressource in Pacemaker mithilfe des Pacemaker HA-Agents v2: (
ocf:mssql:agv2)sudo pcs resource create <NameForAGResource> ocf:mssql:agv2 ag_name=<AGName> meta failure-timeout=30s promotable notify=trueWenn Sie ein Upgrade von Pacemaker HA Agent v1 auf v2 durchführen, entfernen Sie die vorhandene AG-Ressource, bevor Sie die
agv2Ressource erstellen:sudo pcs resource delete <NameForAGResource>Durch diesen Vorgang wird die AG-Synchronisierung vorübergehend beendet, während die Ressource neu erstellt wird. Das Löschen und erneutes Erstellen der Pacemaker-AG-Ressource löscht die AG nicht. Nachdem die Ressource neu erstellt wurde, setzt Pacemaker die Management- und AG-Synchronisierung automatisch fort.
Erstellen Sie die IP-Adressressource für das Application Gateway (AG), die Sie der Listener-Funktionalität zuordnen.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>In diesem Beispiel steht
NameForIPResourcefür den eindeutigen Namen der IP-Ressource, undIPAddressist die statische IP-Adresse, die Sie der Ressource zuweisen.Um sicherzustellen, dass die IP-Adresse und die AG-Ressource auf demselben Knoten ausgeführt werden, konfigurieren Sie eine Colocation-Einschränkung.
sudo pcs constraint colocation add <NameForIPResource> with promoted <NameForAGResource>-clone INFINITYIn diesem Beispiel
NameForIPResourceist der Name der IP-Ressource undNameForAGResourceder Name für die AG-Ressource.Erstellen Sie eine Abhängigkeitsbedingung, um sicherzustellen, dass die AG-Ressource verfügbar ist, bevor die IP-Adresse in Betrieb genommen wird. Während die Colocation-Einschränkung eine Sortiereinschränkung impliziert, erzwingt dieser Schritt sie.
sudo pcs constraint order promote <NameForAGResource>-clone then start <NameForIPResource>In diesem Beispiel
NameForIPResourceist der Name der IP-Ressource undNameForAGResourceder Name für die AG-Ressource.