Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2017 (14.x) und höhere Versionen
SQL Server 2017 (14.x) und höhere Versionen
In diesem Artikel wird die Python-Erweiterung für die Ausführung externer Python-Skripts mit SQL Server Machine Learning Services beschrieben. Die Erweiterung fügt Folgendes hinzu:
- Eine Python-Ausführungsumgebung
- Die Anaconda-Distribution mit dem Python 3.5-Runtime und -Interpreter.
- Standardbibliotheken und -tools
- Microsoft Python-Pakete:
- revoscalepy für vielseitige Analysen
- microsoftml für Machine-Learning-Algorithmen
Die Installation von Python-Runtime und -Interpreter Version 3.5 gewährleistet eine nahezu vollständige Kompatibilität mit Python-Standardlösungen. Python wird in einem separaten Prozess von SQL Server ausgeführt, um sicherzustellen, dass die Datenbankvorgänge nicht beeinträchtigt werden.
Python-Komponenten
SQL Server enthält sowohl Open Source- als auch proprietäre Pakete. Die von Setup installierte Python-Runtime ist Anaconda 4.2 mit Python 3.5. Python-Runtime wird unabhängig von SQL-Tools installiert und außerhalb der Kernprozesse der Engine im Erweiterbarkeitsframework ausgeführt. Im Rahmen der Installation von Machine Learning Services mit Python müssen Sie den Bedingungen der öffentlichen GNU-Lizenz zustimmen.
SQL Server ändert die ausführbaren Python-Dateien nicht. Sie müssen jedoch die Version von Python verwenden, die von Setup installiert wird, da auf dieser Version die proprietären Pakete erstellt und getestet werden. Eine Liste der von der Anaconda-Distribution unterstützten Pakete finden Sie auf der Website von Continuum Analytics: Anaconda-Paketliste.
Die Anaconda-Distribution, die mit einer bestimmten Datenbank-Engine verknüpft ist, finden Sie in dem Ordner, der mit der Instanz verknüpft ist. Wenn Sie beispielsweise die SQL Server 2017-Datenbank-Engine mit Machine Learning Services und Python auf der Standardinstanz installiert haben, suchen Sie unter C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Python-Pakete, die von Microsoft für parallele und verteilte Workloads hinzugefügt wurden, umfassen die folgenden Bibliotheken.
| Bibliothek | BESCHREIBUNG |
|---|---|
| revoscalepy | Unterstützt Datenquellenobjekte sowie die Exploration, Manipulation, Transformation und Visualisierung von Daten. Es unterstützt die Erstellung von Remote-Computekontexten sowie verschiedenen skalierbaren Modellen für maschinelles Lernen, wie rxLinMod. Weitere Informationen finden Sie unter revoscalepy (Python-Modul in SQL Server). |
| microsoftml | Enthält Algorithmen für das maschinelle Lernen, die hinsichtlich Geschwindigkeit und Genauigkeit optimiert wurden, sowie Inline-Transformationen für die Arbeit mit Text und Bildern. Weitere Informationen finden Sie unter microsoftml-Modul mit SQL Server. |
microsoftml und revoscalepy sind eng miteinander verbunden; in microsoftsoftml verwendete Datenquellen sind als revoscalepy-Objekte definiert. Berechnen Sie Kontextbeschränkungen bei der revoscalepy-Übertragung nach microsoftml. Die gesamte Funktionalität für lokale Vorgänge ist verfügbar, aber der Wechsel zu einem Remote-Computekontext erfordert RxInSqlServer.
Verwenden von Python in SQL Server
Sie importieren das Modul revoscalepy in Ihren Python-Code und rufen dann Funktionen aus dem Modul auf, wie bei allen anderen Python-Funktionen.
Unterstützte Datenquellen sind ODBC-Datenbanken, SQL Server und das XDF-Dateiformat, um Daten mit anderen Quellen oder mit R-Lösungen auszutauschen. Die Eingabedaten für Python müssen tabellarisch sein. Alle Python-Ergebnisse müssen in Form eines Pandas-Datenrahmens zurückgegeben werden.
Unterstützte Computekontexte umfassen lokale oder entfernte SQL Server-Computekontexte. Ein Remotecomputekontext bezieht sich auf die Codeausführung, die auf einem Computer (beispielsweise einer Arbeitsstation) beginnt, aber dann die Skriptausführung auf einen Remotecomputer schaltet. Zum Wechseln des Computekontexts müssen beide Systeme dieselbe Bibliothek 'revoscalepy' verwenden.
Ein lokaler Computekontext umfasst naturgemäß die Ausführung von Python-Code auf demselben Server wie die Instanz der Datenbank-Engine, wobei sich der Code in T-SQL befindet oder in eine gespeicherte Prozedur eingebettet ist. Sie können den Code auch aus einer lokalen Python-IDE ausführen und das Skript auf dem SQL Server-Computer ausführen lassen, indem Sie einen Remotecomputekontext definieren.
Ausführungsarchitektur
Die folgenden Diagramme zeigen die Interaktion von SQL Server-Komponenten mit Python-Runtime in jedem der unterstützten Szenarios: datenbankinternes Ausführen von Skripts und Remoteausführung von einer Python-Befehlszeile aus, indem ein SQL Server-Computekontext verwendet wird.
Datenbankinternes Ausführen von Python-Skripts
Wenn Sie Python „innerhalb“ von SQL Server ausführen, müssen Sie das Python-Skript in einer speziellen gespeicherten Prozedur kapseln, sp_execute_external_script.
Nachdem das Skript in die gespeicherte Prozedur eingebettet wurde, kann jede Anwendung, die einen Aufruf der gespeicherten Prozedur ausführen kann, die Ausführung von Python-Code einleiten. Anschließend verwaltet SQL Server die Ausführung des Codes. Dies wird im folgenden Diagramm gezeigt.
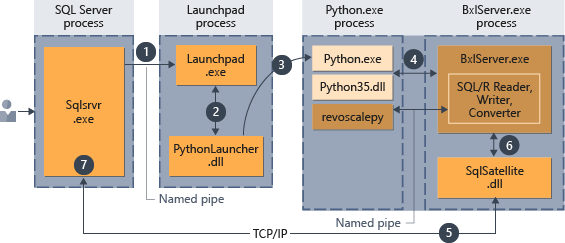
- Eine Anforderung für Python-Runtime wird vom Parameter
@language='Python'angegeben, der an die gespeicherte Prozedur weitergegeben wird. SQL Server sendet diese Anforderung an den Launchpad-Dienst. Unter Linux verwendet SQL einen launchpadd-Dienst, um mit einem separaten Launchpad-Prozess für jeden Benutzer zu kommunizieren. Ausführliche Informationen finden Sie im Diagramm zur Erweiterbarkeitsarchitektur. - Der Launchpad-Dienst startet das entsprechende Startprogramm; in diesem Fall „PythonLauncher“.
- PythonLauncher startet den externen Python35-Prozess.
- BxlServer koordiniert mit Python-Runtime, um die Austauschvorgänge von Daten und der Speicherung von Arbeitsergebnissen zu verwalten.
- SQL Satellite verwaltet die Kommunikation über zugehörige Aufgaben und Prozesse mit SQL Server.
- BxlServer verwendet SQL Satellite, um Status und Ergebnisse an SQL Server zu übermitteln.
- SQL Server ruft die Ergebnisse ab und schließt zugehörige Aufgaben und Prozesse.
Von einem Remoteclient ausgeführte Python-Skripts
Sie können Python-Skripts von einem Remotecomputer, z. B. einem Laptop, ausführen und im Kontext des SQL Server-Computers ausführen lassen, wenn diese Bedingungen erfüllt sind:
- Sie entwerfen die Skripts entsprechend.
- Der Remotecomputer hat die Erweiterbarkeitsbibliotheken installiert, die von Machine Learning Services verwendet werden. Das revoscalepy-Paket ist zur Verwendung von Remotecomputekontexten erforderlich.
Das folgende Diagramm stellt den gesamten Workflow dar, wenn Skripts von einem Remotecomputer gesendet werden.
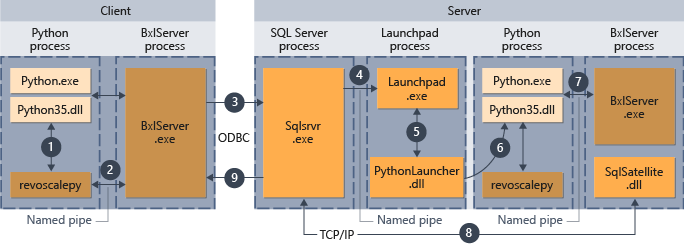
- Python-Runtime ruft für in revoscalepy unterstützte Funktionen eine Verknüpfungsfunktion auf, die wiederum Bxlserver aufruft.
- BxlServer ist in Machine Learning Services (datenbankintern) enthalten und läuft in einem separaten Prozess von Python-Runtime.
- BxlServer bestimmt das Verbindungsziel und initiiert eine Verbindung mithilfe von ODBC, wobei Anmeldeinformationen, die als Teil der Verbindungszeichenfolge im Python-Skript bereitgestellt werden, übergeben werden.
- BxlServer öffnet eine Verbindung mit der SQL Server-Instanz.
- Beim Aufruf einer externen Skriptruntime wird der Launchpad-Dienst aufgerufen, der wiederum das entsprechenden Startprogramm startet: in diesem Fall PythonLauncher.dll. Danach wird die Verarbeitung von Python-Code in einem Workflow ähnlich behandelt wie beim Aufruf von Python-Code aus einer gespeicherten Prozedur in T-SQL.
- PythonLauncher ruft die Python-Instanz ab, die auf dem SQL Server-Computer installiert ist.
- Ergebnisse werden an BxlServer zurückgegeben.
- SQL Satellite verwaltet die Kommunikation mit SQL Server sowie die Bereinigung zugehöriger Auftragsobjekte.
- SQL Server gibt die Ergebnisse an den Client zurück.