Schnellstart: Erstellen und Bewerten eines Vorhersagemodells in R mit SQL Machine Learning
Gilt für: ![]() SQL Server 2016 (13.x) und höher
SQL Server 2016 (13.x) und höher ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Schnellstart erstellen und trainieren Sie ein Vorhersagemodell mit R, speichern das Modell in einer Tabelle in Ihrer SQL Server-Instanz und verwenden es dann zur Vorhersage von Werten aus neuen Daten mit SQL Server Machine Learning Services oder in Big Data-Clustern.
In diesem Schnellstart erstellen und trainieren Sie ein Vorhersagemodell mit R, speichern das Modell in einer Tabelle in Ihrer SQL Server-Instanz und verwenden es dann zur Vorhersage von Werten aus neuen Daten mit SQL Server Machine Learning Services.
In diesem Schnellstart erstellen und trainieren Sie ein Vorhersagemodell mit R, speichern das Modell in einer Tabelle in Ihrer SQL Server-Instanz und verwenden es dann zur Vorhersage von Werten aus neuen Daten mit SQL Server R Services.
In diesem Schnellstart erstellen und trainieren Sie ein Vorhersagemodell mit R, speichern das Modell in einer Tabelle in Ihrer SQL Server-Instanz und verwenden es dann zur Vorhersage von Werten aus neuen Daten mit Machine Learning Services in Azure SQL Managed Instance .
Hierzu erstellen Sie zwei gespeicherte Prozeduren, die in SQL ausgeführt werden. Die erste Prozedur nutzt das in R enthaltene Dataset mtcars und generiert ein einfaches, verallgemeinertes lineares Modell, das die Wahrscheinlichkeit vorhersagt, mit der ein Fahrzeug mit einem Handschaltgetriebe ausgestattet wurde. Die zweite Prozedur ist für die Bewertung vorgesehen: Sie ruft das in der ersten Prozedur generierte Modell auf, um mehrere Vorhersagen basierend auf neuen Daten auszugeben. Durch das Platzieren von Python-Code in einer gespeicherten SQL-Prozedur werden Vorgänge in SQL eingefügt, die wiederverwendbar sind und von anderen gespeicherten Prozeduren und Clientanwendungen aufgerufen werden können.
Tipp
Mit dem folgenden Tutorial, in dem der Prozess zum Anpassen eines Modells mithilfe von rxLinMod beschrieben wird, können Sie Ihr Wissen über lineare Modelle auffrischen: Fitting Linear Models (Anpassen von linearen Modellen).
In diesem Schnellstart lernen Sie Folgendes:
- Einbetten von R-Code in eine gespeicherte Prozedur
- Übergeben von Eingaben an Ihren Code mithilfe von Eingaben in der gespeicherten Prozedur
- Verwenden von gespeicherten Prozeduren zum Operationalisieren von Modellen
Voraussetzungen
Zum Durchführen dieser Schnellstartanleitung benötigen Sie folgende Voraussetzungen.
- SQL Server Machine Learning Services. Informationen zur Installation von Machine Learning Services finden Sie im Windows- oder im Linux-Installationsleitfaden. Sie können auch Machine Learning Services in Big Data-Clustern unter SQL Server aktivieren.
- SQL Server Machine Learning Services. Informationen zur Installation von Machine Learning Services finden Sie im Windows-Installationsleitfaden.
- SQL Server 2016 R Services. Informationen zur Installation von R Services finden Sie im Windows-Installationsleitfaden.
- Machine Learning Services in Azure SQL Managed Instance. In der Übersicht Machine Learning Services in Azure SQL Managed Instance finden Sie weitere Informationen.
- Ein Tool zum Ausführen von SQL-Abfragen, die R-Skripts enthalten. In dieser Schnellstartanleitung wird Azure Data Studio verwendet.
Erstellen des Modells
Zum Erstellen des Modells erstellen Sie Quelldaten für das Training, erstellen das Modell und trainieren es mit diesen Daten, und speichern das Modell anschließend in einer Datenbank, in der es zum Erstellen von Vorhersagen mit neuen Daten verwendet werden kann.
Erstellen der Quelldaten
Öffnen Sie Azure Data Studio, stellen Sie eine Verbindung mit Ihrer Instanz her, und öffnen Sie ein neues Abfragefenster.
Erstellen Sie eine Tabelle zum Speichern der Trainingsdaten.
CREATE TABLE dbo.MTCars( mpg decimal(10, 1) NOT NULL, cyl int NOT NULL, disp decimal(10, 1) NOT NULL, hp int NOT NULL, drat decimal(10, 2) NOT NULL, wt decimal(10, 3) NOT NULL, qsec decimal(10, 2) NOT NULL, vs int NOT NULL, am int NOT NULL, gear int NOT NULL, carb int NOT NULL );Fügen Sie die Daten aus dem integrierten Dataset
mtcarsein.INSERT INTO dbo.MTCars EXEC sp_execute_external_script @language = N'R' , @script = N'MTCars <- mtcars;' , @input_data_1 = N'' , @output_data_1_name = N'MTCars';Tipp
In der R-Runtime sind viele kleine und große Datasets enthalten. Geben Sie
library(help="datasets")in eine R-Eingabeaufforderung ein, um eine Liste von installierten Datasets mit R abzurufen.
Erstellen und Trainieren des Modells
Die Daten der Autogeschwindigkeit enthalten zwei numerische Spalten: Pferdestärke (hp) und Gewicht (wt). Aus diesen Daten erstellen Sie ein verallgemeinertes lineares Modell, das die Wahrscheinlichkeit schätzt, mit der ein Fahrzeug mit einem Handschaltgetriebe ausgestattet wurde.
Sie definieren die Formel in Ihrem R-Code und übergeben die Daten als Eingabeparameter, um das Modell zu erstellen.
DROP PROCEDURE IF EXISTS generate_GLM;
GO
CREATE PROCEDURE generate_GLM
AS
BEGIN
EXEC sp_execute_external_script
@language = N'R'
, @script = N'carsModel <- glm(formula = am ~ hp + wt, data = MTCarsData, family = binomial);
trained_model <- data.frame(payload = as.raw(serialize(carsModel, connection=NULL)));'
, @input_data_1 = N'SELECT hp, wt, am FROM MTCars'
, @input_data_1_name = N'MTCarsData'
, @output_data_1_name = N'trained_model'
WITH RESULT SETS ((model VARBINARY(max)));
END;
GO
- Das erste Argument für
glmist der Parameter formula, deramals abhängig vonhp + wtdefiniert. - Die Eingabedaten werden in der Variablen
MTCarsDatagespeichert, die mit der SQL-Abfrage aufgefüllt wird. Wenn Sie Ihren Eingabedaten nicht einen spezifischen Namen zuweisen, lautet der Standardvariablenname InputDataSet.
Speichern des Modells in der Datenbank
Als Nächstes speichern Sie das Modell in einer Datenbank, damit Sie es für Vorhersagen verwenden oder erneut trainieren können.
Erstellen Sie eine Tabelle zum Speichern des Modells.
Die Ausgabe eines R-Pakets, das ein Modell erstellt, ist normalerweise ein binäres Objekt. Daher muss die Tabelle, in der Sie das Modell speichern, eine Spalte vom Typ varbinary(max) bereitstellen.
CREATE TABLE GLM_models ( model_name varchar(30) not null default('default model') primary key, model varbinary(max) not null );Führen Sie die folgende Transact-SQL-Anweisung aus, um die gespeicherte Prozedur aufzurufen, das Modell zu generieren und dieses in der erstellten Tabelle zu speichern.
INSERT INTO GLM_models(model) EXEC generate_GLM;Tipp
Wenn Sie diesen Code ein zweites Mal ausführen, erhalten Sie den folgenden Fehler: „Violation of PRIMARY KEY constraint...Cannot insert duplicate key in object dbo.stopping_distance_models.“ (Verstoß gegen die PRIMARY KEY-Einschränkung... Ein doppelter Schlüssel kann nicht in das Objekt „dbo.stopping_distance_models“ eingefügt werden.) Eine Option zur Vermeidung dieses Fehlers ist das Aktualisieren des Namens für jedes neue Modell. Sie können den Namen beispielsweise in eine aussagekräftigere Zeichenfolge ändern und den Modelltyp, den Tag der Erstellung usw. einfügen.
UPDATE GLM_models SET model_name = 'GLM_' + format(getdate(), 'yyyy.MM.HH.mm', 'en-gb') WHERE model_name = 'default model'
Bewerten neuer Daten mithilfe des trainierten Modells
Der Begriff Bewertung bezieht sich bei Data Science auf die Erstellung von Vorhersagen, Wahrscheinlichkeiten oder anderen Werten, die auf neuen Daten basieren, die einem trainierten Modell zugeführt werden. Sie verwenden das Modell, das Sie im vorherigen Abschnitt erstellt haben, um Vorhersagen für neue Daten zu bewerten.
Erstellen einer Tabelle aus neuen Daten
Erstellen Sie zunächst eine Tabelle mit neuen Daten.
CREATE TABLE dbo.NewMTCars(
hp INT NOT NULL
, wt DECIMAL(10,3) NOT NULL
, am INT NULL
)
GO
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (110, 2.634)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (72, 3.435)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (220, 5.220)
INSERT INTO dbo.NewMTCars(hp, wt)
VALUES (120, 2.800)
GO
Vorhersagen von Handschaltgetrieben
Schreiben Sie ein SQL-Skript mit den folgenden Funktionen, um Vorhersagen basierend auf Ihrem Modell zu erhalten:
- Ruft das gewünschte Modell ab
- Ruft die neuen Eingabedaten ab
- Ruft eine R-Vorhersagefunktion auf, die mit dem Modell kompatibel ist
Mit der Zeit sammeln sich womöglich mehrere R-Modelle in der Tabelle an, die alle mit unterschiedlichen Parametern oder Algorithmen erstellt oder mit verschiedenen Datenteilmengen trainiert wurden. In diesem Beispiel wird das Modell namens default model verwendet.
DECLARE @glmmodel varbinary(max) =
(SELECT model FROM dbo.GLM_models WHERE model_name = 'default model');
EXEC sp_execute_external_script
@language = N'R'
, @script = N'
current_model <- unserialize(as.raw(glmmodel));
new <- data.frame(NewMTCars);
predicted.am <- predict(current_model, new, type = "response");
str(predicted.am);
OutputDataSet <- cbind(new, predicted.am);
'
, @input_data_1 = N'SELECT hp, wt FROM dbo.NewMTCars'
, @input_data_1_name = N'NewMTCars'
, @params = N'@glmmodel varbinary(max)'
, @glmmodel = @glmmodel
WITH RESULT SETS ((new_hp INT, new_wt DECIMAL(10,3), predicted_am DECIMAL(10,3)));
Das obige Skript für die folgenden Schritte aus:
Verwenden Sie eine SELECT-Anweisung, um ein einzelnes Modell aus der Tabelle abzurufen, und übergeben Sie es als Eingabeparameter.
Rufen Sie nach dem Abruf des Modells aus der Tabelle die Funktion
unserializefür das Modell auf.Wenden Sie die Funktion
predictmit den passenden Argumenten auf das Modell an, und geben Sie die neuen Eingabedaten an.
Hinweis
Im Beispiel wird die str-Funktion während der Testphase hinzugefügt, um das Schema der von R zurückgegebenen Daten zu überprüfen. Sie können diese Anweisung später entfernen.
Die im R-Skript verwendeten Spaltennamen werden nicht zwangsläufig an die Ausgabe der gespeicherten Prozedur übergeben. Hier wird die Klausel WITH RESULTS verwenden, um einige neue Spaltennamen zu definieren.
Ergebnisse
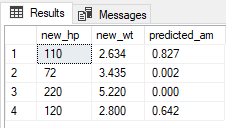
Es ist auch möglich, die PREDICT (Transact-SQL)-Anweisung zum Generieren eines vorhergesagten Werts oder einer Bewertung für ein gespeichertes Modell zu verwenden.
Nächste Schritte
Weitere Informationen zu Tutorials für R mit SQL Machine Learning finden Sie unter:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für