Joins (SQL Server)
Gilt für: ![]() SQL Server
SQL Server ![]() Azure SQL-Datenbank
Azure SQL-Datenbank ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
SQL Server verwendet bei Sortier-, Schnittmengen-, Vereinigungs- und Vorgängen zum Feststellen von Unterschieden arbeitsspeicherinterne Sortierverfahren und Hashjointechniken. Wenn dieser Abfrageplan verwendet wird, unterstützt SQL Server die vertikale Tabellenpartitionierung.
SQL Server implementiert logische Joinvorgänge, die durch die Transact-SQL-Syntax festgelegt werden:
- Innerer Join
- Left Outer Join
- Rechte äußere Verknüpfung
- Vollständiger äußerer Join
- Kreuzprodukt
Hinweis
Weitere Informationen zur Joinsyntax finden Sie unter FROM-Klausel mit JOIN, APPLY, PIVOT (Transact-SQL).
SQL Server verwendet vier verschiedene physische Joinvorgänge, um logische Joinvorgänge auszuführen:
- Joins geschachtelter Schleifen
- Zusammenführungsjoins
- Hashjoins
- Adaptive Verknüpfungen (beginnend mit SQL Server 2017 (14.x))
Join-Grundlagen
Mithilfe von Joins können Sie Daten aus zwei oder mehr Tabellen basierend auf logischen Beziehungen zwischen den Tabellen abrufen. Joins zeigen an, wie SQL Server Daten aus einer Tabelle zum Auswählen der Zeilen in einer anderen Tabelle verwenden soll.
Eine Joinbedingung definiert die Beziehung zweier Tabellen in einer Abfrage auf folgende Art:
- Sie gibt die Spalte aus jeder Tabelle an, die für den Join verwendet werden soll. Eine typische Joinbedingung gibt einen Fremdschlüssel aus einer Tabelle und den zugehörigen Schlüssel in der anderen Tabelle an.
- Sie gibt auch einen logischen Operator (z. B. = oder <>) an, der zum Vergleichen der Werte aus den Spalten verwendet werden soll.
Joins werden mithilfe der folgenden Transact-SQL-Syntax logisch ausgedrückt:
- INNERER JOIN
- LEFT [ OUTER ] JOIN
- RIGHT [ OUTER ] JOIN
- FULL [ OUTER ] JOIN
- CROSS JOIN
Innere Joins können in FROM- oder WHERE-Klauseln angegeben werden. Äußere Joins und Kreuzprodukte können nur in der FROM-Klausel angegeben werden. Die Joinbedingungen in Verbindung mit WHERE- und HAVING-Suchbedingungen steuern, welche Zeilen aus den Basistabellen ausgewählt werden, auf die in der FROM-Klausel verwiesen wird.
Das Angeben der Joinbedingungen in der FROM-Klausel trägt dazu bei, dass diese von anderen, möglicherweise in einer WHERE-Klausel angegebenen Suchbedingungen getrennt werden. Dies ist die empfohlene Methode zur Angabe von Joins. Eine vereinfachte ISO-Joinsyntax für eine FROM-Klausel lautet:
FROM first_table < join_type > second_table [ ON ( join_condition ) ]
- join_type gibt an, welche Art von Join ausgeführt wird: innerer Join, äußerer Join oder Cross Join. Erläuterungen zu den verschiedenen Jointypen finden Sie unter FROM-Klausel.
- Die join_condition definiert das Prädikat, das für jedes verknüpfte Zeilenpaar ausgewertet werden soll.
Der folgende Code ist ein Beispiel für die Joinspezifizierung einer FROM-Klausel:
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON ( ProductVendor.BusinessEntityID = Vendor.BusinessEntityID )
Der folgende Code ist ein Beispiel für eine einfache SELECT-Anweisung mithilfe dieses Joins:
SELECT ProductID, Purchasing.Vendor.BusinessEntityID, Name
FROM Purchasing.ProductVendor INNER JOIN Purchasing.Vendor
ON (Purchasing.ProductVendor.BusinessEntityID = Purchasing.Vendor.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
GO
Die SELECT-Anweisung gibt die Produkt- und Lieferanteninformationen für alle Kombinationen der Teile zurück, die von einer Firma geliefert werden, deren Firmenname mit dem Buchstaben F beginnt, und bei denen der Produktpreis über 10 USD liegt.
Wenn in einer einzigen Abfrage auf mehrere Tabellen verwiesen wird, müssen alle Spaltenverweise eindeutig sein. Im vorherigen Beispiel verfügt sowohl die ProductVendor- als auch die Vendor-Tabelle über eine Spalte mit der Bezeichnung BusinessEntityID. Alle Spaltennamen, die in zwei oder mehr Tabellen vorkommen, auf die in der Abfrage verwiesen wird, müssen mit dem Tabellennamen gekennzeichnet werden. Alle Verweise auf die Vendor-Spalten im Beispiel sind gekennzeichnet.
Wenn ein Spaltenname nicht in zwei oder mehr in der Abfrage verwendeten Tabellen vorkommt, brauchen Verweise darauf nicht mit dem Tabellennamen gekennzeichnet zu werden. Dies ist im vorherigen Beispiel dargestellt. Eine solche SELECT-Klausel ist manchmal schwer verständlich, weil nicht angezeigt wird, welche Spalte aus welcher Tabelle stammt. Die Lesbarkeit der Abfrage wird verbessert, indem alle Spalten mit dem entsprechenden Tabellennamen gekennzeichnet werden. Die Übersichtlichkeit kann weiterhin durch Verwenden von Tabellenaliasnamen verbessert werden, besonders, wenn die Tabellennamen mit dem Datenbank- und Besitzernamen gekennzeichnet werden müssen. Der folgende Code unterscheidet sich vom vorherigen nur dadurch, dass Tabellenaliasnamen zugewiesen und die Spalten der Übersichtlichkeit halber mit Tabellenaliasnamen gekennzeichnet wurden:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv
INNER JOIN Purchasing.Vendor AS v
ON (pv.BusinessEntityID = v.BusinessEntityID)
WHERE StandardPrice > $10
AND Name LIKE N'F%';
In den vorhergehenden Beispielen wurden die Joinbedingungen in der FROM-Klausel angegeben. Dies ist die bevorzugte Methode. Die folgende Abfrage enthält dieselbe Joinbedingung, die in der WHERE-Klausel angegeben wird:
SELECT pv.ProductID, v.BusinessEntityID, v.Name
FROM Purchasing.ProductVendor AS pv, Purchasing.Vendor AS v
WHERE pv.BusinessEntityID=v.BusinessEntityID
AND StandardPrice > $10
AND Name LIKE N'F%';
Die SELECT-Liste für einen Join kann auf alle Spalten in den verknüpften Tabellen oder auf eine beliebige Teilmenge der Spalten verweisen. Es ist nicht erforderlich, dass die SELECT-Liste Spalten aus allen Tabellen im Join enthält. So kann z. B. in einem Join dreier Tabellen nur eine Tabelle verwendet werden, um die anderen Tabellen zu verbinden, und in der Auswahlliste muss auf keine der Spalten aus der mittleren Tabelle verwiesen werden. Dies wird auch als Antisemijoin bezeichnet.
Obwohl Joinbedingungen normalerweise Übereinstimmungsvergleiche (=) enthalten, können andere Vergleichsoperatoren oder relationale Operatoren ebenso wie andere Prädikate angegeben werden. Weitere Informationen finden Sie unter Vergleichsoperatoren (Transact-SQL) und WHERE (Transact-SQL).
Beim Verarbeiten von Joins durch SQL Server wählt der Abfrageoptimierer (aus verschiedenen Möglichkeiten) die effizienteste Methode aus. Dabei werden der effizienteste physische Join, die Joinreihenfolge der Tabellen und sogar logische Joinvorgänge ausgewählt, die mit der Transact-SQL-Syntax nicht direkt ausgedrückt werden können (z. B. Semijoins und Antisemijoins). Die physische Ausführung von verschiedenen Joins kann viele verschiedene Optimierungen verwenden, weshalb keine zuverlässige Einschätzung möglich ist. Weitere Informationen zu Semijoins und Antisemijoins finden Sie unter Referenz zu logischen und physischen Showplanoperatoren.
Spalten, die in einer Joinbedingung verwendet werden, müssen nicht den gleichen Namen oder Datentyp haben. Die Datentypen müssen jedoch kompatibel sein, falls sie nicht identisch sind, oder es müssen Datentypen sein, die SQL Server implizit konvertieren kann. Wenn die Datentypen nicht implizit konvertiert werden können, muss die Joinbedingung den Datentyp mithilfe der CAST-Funktion explizit konvertieren. Weitere Informationen über die impliziten und expliziten Konvertierungen finden Sie unter Datentypkonvertierung (Datenbank-Engine).
Die meisten Abfragen, die einen Join verwenden, können in eine Unterabfrage (eine in eine andere Abfrage geschachtelte Abfrage) umgeschrieben werden, und die meisten Unterabfragen können in Joins umgeschrieben werden. Weitere Informationen zu Unterabfragen finden Sie unter Unterabfragen.
Hinweis
Tabellen können nicht direkt über ntext-, text- oder image-Spalten verknüpft werden. Sie können jedoch mithilfe von SUBSTRING indirekt über ntext- , text- oder image-Spalten verknüpft werden.
SELECT * FROM t1 JOIN t2 ON SUBSTRING(t1.textcolumn, 1, 20) = SUBSTRING(t2.textcolumn, 1, 20) führt z. B. einen inneren Join zwischen zwei Tabellen auf den ersten 20 Zeichen jeder Textspalte in den Tabellen t1 und t2 aus.
Außerdem können ntext- oder text-Spalten aus zwei Tabellen verglichen werden, indem die Längen der Spalten mithilfe einer WHERE-Klausel wie im folgenden Beispiel verglichen werden: WHERE DATALENGTH(p1.pr_info) = DATALENGTH(p2.pr_info).
Grundlegendes zu Nested Loops-Joins
Wenn eine Joineingabe klein (weniger als 10 Zeilen) und die andere Joineingabe relativ umfangreich ist und indizierte Joinspalten aufweist, ist ein indizierter Nested Loops-Join der schnellste Joinvorgang, da sie mit dem geringsten E/A-Aufkommen und den wenigsten Vergleichen auskommen.
Der Join geschachtelter Schleifen, auch geschachtelte Iteration genannt, verwendet eine Joineingabe als äußere Eingabetabelle (im grafischen Ausführungsplan als obere Eingabe dargestellt) und eine zweite Joineingabe als innere (untere) Eingabetabelle. Die äußere Schleife verarbeitet die äußere Eingabetabelle zeilenweise. Die innere Schleife wird für jede äußere Zeile ausgeführt und sucht übereinstimmende Zeilen in der inneren Eingabetabelle.
Im einfachsten Fall wird beim Suchvorgang eine Tabelle oder ein Index vollständig gescannt. Dieser Vorgang wird als naiver Join geschachtelter Schleifen bezeichnet. Wird beim Suchvorgang ein Index verwendet, wird dies indizierter Join geschachtelter Schleifen genannt. Wird der Index als Teil des Abfrageplans erstellt (und nach Beendigung der Abfrage gelöscht), wird dies temporärer indizierter Join geschachtelter Schleifen genannt. Alle beschriebenen Varianten werden vom Abfrageoptimierer berücksichtigt.
Ein Nested Loops-Join ist besonders wirksam, wenn die äußere Eingabe klein und die innere Eingabe vorindiziert und umfangreich ist. In vielen kleinen Transaktionen, die beispielsweise nur wenige Zeilen betreffen, sind indizierte Nested Loops-Joins sowohl Zusammenführungsjoins als auch Hashjoins überlegen. In umfangreichen Abfragen dagegen sind Nested Loops-Joins häufig nicht die optimale Wahl.
Wenn das „OPTIMIZED“-Attribut eines Operators für Joins geschachtelter Schleifen auf Truefestgelegt ist, bedeutet dies, dass ein optimierter Join geschachtelter Schleifen (oder eine Sortierung im Batchmodus) verwendet wird, um E/A-Vorgänge zu minimieren, wenn die innere Tabelle groß ist, unabhängig davon, ob sie parallelisiert wird oder nicht. Das Vorhandensein dieser Optimierung in einem bestimmten Plan ist beim Analysieren eines Ausführungsplans möglicherweise nicht offensichtlich, da die Sortierung selbst ein verborgener Vorgang ist. Wenn jedoch in der Plan-XML nach dem Attribut „OPTIMIZED“ gesucht wird, deutet dies darauf hin, dass der Join geschachtelter Schleifen möglicherweise versucht, die Eingabezeilen neu anzuordnen und die E/A-Leistung zu verbessern.
Zusammenführungsjoins
Sind beide Joineingaben nicht klein, aber nach ihrer Joinspalte sortiert (was beispielsweise der Fall ist, wenn sie beim Scannen sortierter Indizes gewonnen wurden), so ist ein Zusammenführungsjoin der schnellste Joinvorgang. Sind beide Joineingaben umfangreich und etwa gleich groß, so bietet ein Zusammenführungsjoin mit vorherigem Sortiervorgang und ein Hashjoin vergleichbares Leistungsverhalten. Hashjoinvorgänge sind jedoch häufig erheblich schneller, wenn sich beide Eingaben im Umfang deutlich unterscheiden.
Der Zusammenführungsjoin setzt voraus, dass beide Eingaben nach den Zusammenführungsspalten sortiert sind; diese werden von den Gleichheitsoperatoren des Joinprädikats (in der ON-Klausel) definiert. Der Abfrageoptimierer scannt in der Regel einen Index, falls ein Index für die geeigneten Spalten vorhanden ist, oder platziert einen Sort-Operator unter den Zusammenführungsjoin. In seltenen Fällen können mehrere Gleichheitsklauseln auftreten, jedoch werden die Zusammenführungsspalten nur von einigen der verfügbaren Gleichheitsklauseln genommen.
Da die Eingaben sortiert vorliegen, ruft der Merge Join-Operator von jeder Eingabe jeweils eine Zeile ab und vergleicht diese. Beispielsweise werden bei inneren Joins die Zeilen zurückgegeben, wenn sie gleich sind. Sind sie nicht gleich, wird die Zeile mit dem kleineren Wert verworfen, und von der betreffenden Eingabe wird die nächste Zeile abgerufen. Dieser Vorgang wird wiederholt, bis alle Zeilen verarbeitet wurden.
Die Zusammenführungsjoinoperation ist eine reguläre oder eine n:n-Operation. Ein n:n-Zusammenführungsjoin verwendet eine temporäre Tabelle, um Zeilen zu speichern. Treten bei den Eingaben doppelte Werte auf, so muss eine Eingabe bis zum ersten Duplikat zurückgespult werden, damit alle Duplikate der anderen Eingabe verarbeitet werden können.
Ist ein Residualprädikat vorhanden, so werten alle Zeilen, die dem Zusammenführungsprädikat genügen, das Residualprädikat aus. Nur die Zeilen werden zurückgegeben, die auch dem Residualprädikat genügen.
Der Zusammenführungsjoin ist sehr schnell, kann aber eine teure Wahl darstellen, wenn Sortieroperationen erforderlich sind. Wenn jedoch die Datenmenge umfangreich ist und die gewünschten Daten vorsortiert aus vorhandenen B-Baum-Indizes abgerufen werden können, ist der Zusammenführungsjoin häufig der schnellste Joinalgorithmus.
Hashjoins
Hashjoins können umfangreiche, unsortierte, nicht indizierte Eingaben effizient verarbeiten. Sie sind für Zwischenergebnisse in komplexen Abfragen aus folgenden Gründen nützlich:
- Zwischenergebnisse sind nicht indiziert (es sei denn, sie werden explizit auf einem Datenträger gespeichert und dann indiziert) und häufig nicht für den nächste Vorgang im Abfrageplan passend sortiert.
- Abfrageoptimierer schätzen nur die Größe von Zwischenergebnissen ab. Weil Schätzungen in komplexen Abfragen sehr ungenau sein können, müssen Algorithmen zum Verarbeiten von Zwischenergebnissen nicht nur effizient sein, sondern auch kontrolliert beendet werden können, wenn ein Zwischenergebnis viel umfangreicher als erwartet ausfällt.
Der Hashjoin lässt Reduktionen bei der Denormalisierung zu. Die Denormalisierung wird in der Regel verwendet, um bessere Leistung durch Reduzierung der Joinvorgänge zu erreichen, und zwar trotz der Redundanzgefahr wie beispielsweise durch inkonsistente Updates. Hashjoins vermindern den Bedarf, die Denormalisierung durchzuführen. Hashjoins ermöglichen die vertikale Partitionierung (die Darstellung von Spaltengruppen aus einer einzelnen Tabelle in separate Dateien oder Indizes), wodurch sie zu einer beachtenswerten Option für den physischen Datenbankentwurf wird.
Der Hashjoin verfügt über zwei Eingaben: die Erstellungseingabe und die Untersuchungseingabe. Der Abfrageoptimierer weist diese Rollen so zu, dass die kleinere Eingabe als Erstellungseingabe verwendet wird.
Hashjoins werden für viele ergebnismengenorientierte Operationen verwendet: INNER JOIN (innerer Join); LEFT, RIGHT und FULL OUTER JOIN (linker, rechter und vollständiger äußerer Join); LEFT SEMI-JOIN und RIGHT SEMI-JOIN (linker und rechter Semijoin); INTERSECTION (Schnittmenge); UNION (Vereinigungsmenge) und DIFFERENCE (Restmenge). Darüber hinaus können mit einer Variante des Hashjoins Duplikate entfernt und Gruppierungen vorgenommen werden, z.B. SUM(salary) GROUP BY department. Diese Varianten verwenden dieselbe Eingabe als Erstellungseingabe und Untersuchungseingabe.
In den folgenden Abschnitten werden verschiedene Typen von Hashjoins beschrieben: arbeitsspeicherinterne Hashjoins, schrittweise Hashjoins und rekursive Hashjoins.
Arbeitsspeicherinterne Hashjoins
Der Hashjoin scannt oder berechnet zuerst die gesamte Erstellungseingabe und erstellt dann eine Hashtabelle im Arbeitsspeicher. Jede Zeile wird in ein Hashbucket eingefügt, abhängig von dem für den Hashschlüssel berechneten Hashwert. Wenn die gesamte Erstellungseingabe kleiner als der verfügbare Arbeitsspeicher ist, können alle Zeilen in die Hashtabelle eingefügt werden. Auf diese Erstellungsphase folgt die Untersuchungsphase. Die gesamte Untersuchungseingabe wird zeilenweise gescannt oder berechnet, und für jede Untersuchungszeile wird der Wert des Hashschlüssels berechnet, das entsprechende Hashbucket wird gescannt, und die Übereinstimmungen werden erzeugt.
Grace-Hashjoins
Wenn die Erstellungseingabe nicht vollständig in den Arbeitsspeicher passt, wird der Hashjoin in mehreren Schritten durchgeführt. Dies wird als schrittweiser Hashjoin bezeichnet. Jeder Schritt besteht aus einer Erstellungsphase und einer Untersuchungsphase. Zuerst wird die gesamte Erstellungseingabe und Untersuchungseingabe verarbeitet und (durch Anwenden einer Hashfunktion auf die Hashschlüssel) in mehrere Dateien aufgeteilt. Durch Anwenden der Hashfunktion auf die Hashschlüssel wird sichergestellt, dass die zwei zu verknüpfenden Datensätze sich stets in demselben Dateipaar befinden. So wird die Aufgabe, zwei umfangreiche Eingaben zu verknüpfen, auf mehrere kleinere gleichartige Teilaufgaben reduziert. Der Hashjoin wird dann auf jedes Paar partitionierter Dateien angewendet.
Rekursive Hashjoins
Wenn die Erstellungseingabe so umfangreich ist, dass Eingaben für einen standardmäßigen externen Mergeprozess mehrere Mergeebenen erfordern würden, sind mehrere Partitionierungsschritte und mehrere Partitionierungsebenen erforderlich. Sind nur einige Partitionen umfangreich, so sind zusätzliche Partitionierungsschritte nur für diese Partitionen erforderlich. Um alle Partitionierungsschritte möglichst schnell zu machen, werden umfangreiche, asynchrone E/A-Operationen verwendet, sodass bereits ein Thread mehrere Datenträger auslastet.
Hinweis
Wenn die Erstellungseingabe nur wenig umfangreicher als der verfügbare Arbeitsspeicher ist, werden Elemente des schrittweisen und des arbeitsspeicherinternen Hashjoin in einem Schritt kombiniert, sodass ein hybrider Hashjoin entsteht.
Bei der Optimierung kann nicht in jedem Fall ermittelt werden, welcher Hashjoin verwendet wird. Daher verwendet SQL Server zunächst einen arbeitsspeicherinternen Hashjoin und geht, abhängig von der Größe der Erstellungseingabe, sukzessive zum GRACE- und rekursiven Hashjoin über.
Wenn der Abfrageoptimierer falsch einschätzt, welche Eingabe kleiner ist und daher als Erstellungseingabe verwendet werden müsste, werden die Rollen der Erstellungs- und der Untersuchungseingabe dynamisch vertauscht. Der Hashjoin stellt sicher, dass die kleinere Überlaufdatei als Erstellungseingabe verwendet wird. Diese Technik wird als Rollentausch bezeichnet. Ein Rollentausch tritt innerhalb des Hashjoins nach mindestens einem Überlauf auf den Datenträger auf.
Hinweis
Der Rollentausch tritt unabhängig von Abfragehinweisen oder von der Struktur auf. Der Rollentausch wird nicht im Abfrageplan angezeigt. Wenn ein solcher Vorgang auftritt, erfolgt er transparent für den Benutzer.
Hashabbruch
Der Begriff „Hashabbruch“ wird manchmal zur Beschreibung von GRACE- oder rekursiven Hashjoins verwendet.
Hinweis
Rekursive Hashjoins oder Hashabbrüche verursachen eine reduzierte Leistung auf dem Server. Wenn in einer Ablaufverfolgung viele Hash Warning-Ereignisse angezeigt werden, sollten Sie die Statistiken für die verknüpften Spalten aktualisieren.
Weitere Informationen zu Hashabbrüchen finden Sie unter Hash Warning-Ereignisklasse.
Adaptive Joins
Mit dem Batchmodus für adaptive Joins können Sie wählen, ob eine Methode für Hashjoins oder Joins geschachtelter Schleifen zurückgestellt wird. Die Methode wird dann erst nach der Überprüfung der ersten Eingabe angewendet. Der Operator für adaptive Joins definiert einen Schwellenwert, der bestimmt, wann zu einem Plan geschachtelter Schleifen gewechselt wird. Daher kann ein Abfrageplan während der Ausführung dynamisch zu einer passenderen Joinstrategie wechseln, ohne dass er erneut kompiliert werden muss.
Tipp
Workloads mit häufiger Oszillation zwischen kleinen und großen Joineingabescans profitieren am meisten von dieser Funktion.
Die Laufzeitentscheidung basiert auf den folgenden Schritten:
- Wenn die Anzahl der Zeilen der Buildjoineingabe so klein ist, dass ein Join geschachtelter Schleifen passender wäre als ein Hashjoin, wechselt der Plan zu einem Algorithmus geschachtelter Schleifen.
- Wenn die Buildjoineingabe eine bestimmte Anzahl an Zeilen übersteigt, wird nicht gewechselt, und der Plan wird mit einem Hashjoin fortgesetzt.
Die folgende Abfrage veranschaulicht ein Beispiel für einen adaptiven Join:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 360;
Die Abfrage gibt 336 Zeilen zurück. Bei Aktivierung der Liveabfragestatistik wird der folgende Plan angezeigt:

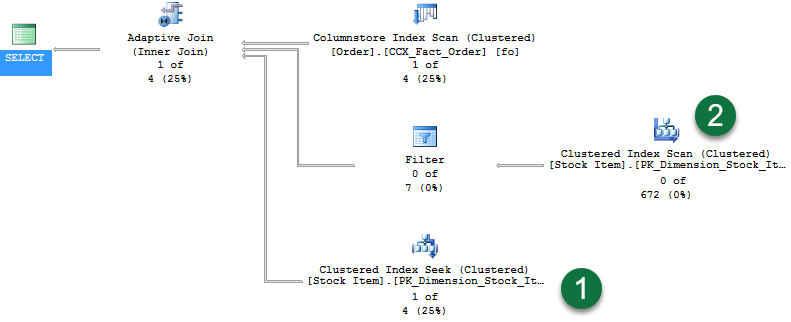
Beachten Sie im Plan Folgendes:
- Ein Columnstore-Indexscan wurde verwendet, um Zeilen für die Buildphase des Hashjoins bereitzustellen.
- Den neuen Operator für adaptive Joins. Dieser Operator definiert einen Schwellenwert, der bestimmt, wann zu einem Plan geschachtelter Schleifen gewechselt wird. In diesem Beispiel entspricht der Schwellenwert 78 Zeilen. Alles mit >= 78 Zeilen verwendet einen Hashjoin. Wenn der Schwellenwert nicht überschritten wird, wird ein Join geschachtelter Schleifen verwendet.
- Da von der Abfrage 336 Zeilen zurückgegeben werden, wird der Schwellenwert überschritten. Deshalb stellt der zweite Branch die Überprüfungsphase eines standardmäßigen Hashjoinvorgangs dar. Die Liveabfragestatistik zeigt Zeilen an, die die Operatoren durchlaufen: in diesem Fall „672 von 672“.
- Beim letzten Branch handelt es sich um eine Suche im gruppierten Index, die vom Join geschachtelter Schleifen verwendet worden wäre, wenn der Schwellenwert nicht überschritten worden wäre. Wir sehen „0 von 336“ Zeilen angezeigt (der Branch wird nicht verwendet).
Vergleichen Sie den Plan nun mit derselben Abfrage, dieses Mal aber mit einem Quantity-Wert, der nur eine Zeile in der Tabelle hat:
SELECT [fo].[Order Key], [si].[Lead Time Days], [fo].[Quantity]
FROM [Fact].[Order] AS [fo]
INNER JOIN [Dimension].[Stock Item] AS [si]
ON [fo].[Stock Item Key] = [si].[Stock Item Key]
WHERE [fo].[Quantity] = 361;
Die Abfrage gibt eine Zeile zurück. Bei Aktivierung der „Liveabfragestatistik“ wird der folgende Plan angezeigt:
Beachten Sie im Plan Folgendes:
- Bei einer zurückgegebenen Zeile durchlaufen Zeilen jetzt den Clustered Index Seek.
- Da die Buildphase des Hashjoins nicht fortgesetzt wurde, wird der zweite Branch nicht von Zeilen durchlaufen.
Hinweise zu adaptiven Joins
Adaptive Joins erfordern mehr Speicherplatz als ein äquivalenter Plan eines indizierten Joins geschachtelter Schleifen. Der zusätzliche Speicherplatz wird so angefordert, als wären die geschachtelte Schleifen ein Hashjoin. Auch die Buildphase ist mit Aufwand verbunden: sowohl für einen Stop-and-Go-Vorgang als auch für einen äquivalenten Join eines Streamings geschachtelter Schleifen. Dieser zusätzliche Aufwand geht mit Flexibilität für Szenarios einher, in denen die Zeilenzahl in der Buildeingabe schwankt.
Adaptive Joins im Batchmodus funktionieren bei der ersten Ausführung einer Anweisung. Nach der ersten Kompilierung bleiben aufeinanderfolgende Ausführungen adaptiv, basierend auf dem Schwellenwert des kompilierten adaptiven Joins und den Laufzeitzeilen, die die Buildphase der äußeren Eingabe durchlaufen.
Wenn ein adaptiver Join zu einem Vorgang geschachtelter Schleifen wechselt, verwendet er die Zeilen, die bereits vom Hashjoinbuild gelesen wurden. Der Operator liest nicht erneut die Zeilen des äußeren Verweises.
Nachverfolgen der Aktivität adaptiver Joins
Der Operator für adaptive Joins verfügt über folgende Planoperatorattribute:
| Planattribut | Beschreibung |
|---|---|
| AdaptiveThresholdRows | Gibt den beim Wechsel von einem Hashjoin zu einem Nested Loop-Join zu verwendenden Schwellenwert an |
| EstimatedJoinType | Gibt den erwarteten Jointyp an |
| ActualJoinType | Gibt in einem Plan an, welcher Joinalgorithmus basierend auf dem Schwellenwert verwendet wurde. |
Der geschätzte Plan zeigt die Form des adaptiven Joinplans an sowie den definierten Schwellenwert für adaptive Joins und den geschätzten Jointyp.
Tipp
Der Abfragespeicher erfasst einen adaptiven Joinplan im Batchmodus und kann diesen erzwingen.
Zulässige Anweisungen für adaptive Joins
Ein logischer Join ist dann für adaptive Joins im Batchmodus zulässig, wenn er folgende Bedingungen erfüllt:
- Der Datenbank-Kompatibilitätsgrad ist 140 oder höher.
- Die Abfrage ist eine
SELECT-Anweisung (Anweisungen zur Datenänderung sind aktuell nicht verfügbar). - Der Join kann sowohl vom physischen Algorithmus eines indizierten Joins geschachtelter Schleifen als auch eines Hashjoins ausgeführt werden.
- Der Hashjoin verwendet den Batchmodus, der durch das Vorhandensein eines Columnstore-Index in der Abfrage, durch einen direkten Verweis auf eine Tabelle im Columnstore-Index im Join oder durch die Verwendung des Batchmodus für Rowstore aktiviert wird.
- Die generierten alternativen Lösungen des Joins geschachtelter Schleifen und Hashjoins sollten dasselbe erste untergeordnete Element haben (äußerer Verweis).
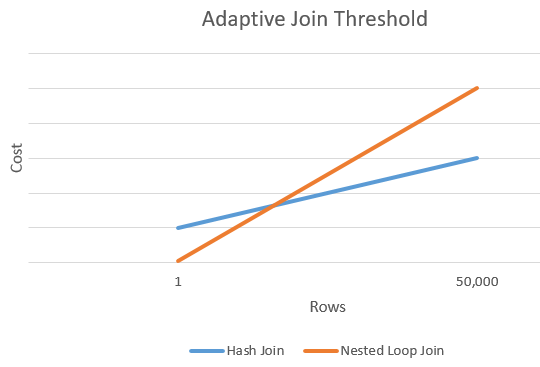
Adaptive Schwellenwertzeilen
Das folgende Diagramm zeigt eine beispielhafte Überschneidung zwischen den Ressourcen eines Hashjoins und den Ressourcen des alternativen Joins geschachtelter Schleifen. Am Überschneidungspunkt wird der Schwellenwert bestimmt, der wiederum den für den Joinvorgang verwendeten Algorithmus bestimmt.
Deaktivieren von adaptiven Joins ohne Änderung des Kompatibilitätsgrads
Adaptive Joins können im Datenbank- oder Anweisungsbereich deaktiviert werden, während der Datenbank-Kompatibilitätsgrad weiterhin bei 140 und höher bleibt.
Führen Sie die folgende Anweisung im Kontext der betreffenden Datenbank aus, um adaptive Joins für alle Abfrageausführungen zu deaktivieren, die aus der Datenbank stammen:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = ON;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = OFF;
Ist diese Einstellung aktiviert, wird sie in sys.database_scoped_configurations als aktiviert aufgeführt.
Um adaptive Joins für alle Abfrageausführungen wieder zu aktivieren, die aus der Datenbank stammen, führen Sie die folgende Anweisung im Kontext der betroffenen Datenbank aus:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_ADAPTIVE_JOINS = OFF;
-- Azure SQL Database, SQL Server 2019 and later versions
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ADAPTIVE_JOINS = ON;
Durch Festlegen von DISABLE_BATCH_MODE_ADAPTIVE_JOINS als USE HINT-Abfragehinweis können adaptive Joins für eine bestimmte Abfrage auch deaktiviert werden. Zum Beispiel:
SELECT s.CustomerID,
s.CustomerName,
sc.CustomerCategoryName
FROM Sales.Customers AS s
LEFT OUTER JOIN Sales.CustomerCategories AS sc
ON s.CustomerCategoryID = sc.CustomerCategoryID
OPTION (USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS'));
Hinweis
Ein USE HINT-Abfragehinweis hat Vorrang vor einer datenbankweit gültigen Konfiguration oder einer Ablaufverfolgungsflageinstellung.
NULL-Werte und Joins
Wenn die Spalten der zu verknüpfenden Tabellen NULL-Werte enthalten, werden diese Werte nicht als übereinstimmend angesehen. Das Vorhandensein von NULL-Werten in einer Spalte aus einer der verknüpften Tabellen kann nur mithilfe eines äußeren Joins zurückgegeben werden (wenn die WHERE-Klausel keine NULL-Werte ausschließt).
Es folgen zwei Tabellen, bei denen NULL in der Spalte enthalten ist, die Bestandteil des Joins ist.
table1 table2
a b c d
------- ------ ------- ------
1 one NULL two
NULL three 4 four
4 join4
Ein Join, der die Werte in der a-Spalte mit denen der c-Spalte vergleicht, erhält keine Übereinstimmung für die Zeilen, die NULL-Werte enthalten:
SELECT *
FROM table1 t1 JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Nur eine Zeile mit dem Wert 4 in der Spalte a und c wird zurückgegeben:
a b c d
----------- ------ ----------- ------
4 join4 4 four
(1 row(s) affected)
Außerdem sind aus einer Basistabelle zurückgegebene NULL-Werte schwer von den von einem äußeren Join zurückgegebenen NULL-Werten zu unterscheiden. Die folgende SELECT-Anweisung führt z. B. einen linken äußeren Join für diese beiden Tabellen aus:
SELECT *
FROM table1 t1 LEFT OUTER JOIN table2 t2
ON t1.a = t2.c
ORDER BY t1.a;
GO
Hier sehen Sie das Ergebnis.
a b c d
----------- ------ ----------- ------
NULL three NULL NULL
1 one NULL NULL
4 join4 4 four
(3 row(s) affected)
In den Ergebnissen ist ein NULL in den Daten nicht ohne Weiteres von einem NULL zu unterscheiden, der einen fehlgeschlagenen Join darstellt. Wenn NULL-Werte in den zu verknüpfenden Daten enthalten sind, empfiehlt es sich, sie durch einen normalen Join aus den Ergebnissen auszuschließen.