Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Die E/A-Aktivitäten einer Instanz von SQL Server Datenbank-Engine schließen logische und physische Lesevorgänge ein. Jedes Mal, wenn das Datenbankmodul eine Seite aus dem Puffercache anfordert, tritt ein logischer Lesevorgang auf, der auch als Pufferpool bezeichnet wird. Wenn sich die Seite derzeit nicht im Puffercache befindet, kopiert ein physischer Lesevorgang zuerst die Seite vom Datenträger in den Cache.
Die von einer Instanz des Datenbankmoduls generierten Leseanforderungen werden vom relationalen Modul gesteuert und vom Speichermodul optimiert. Das relationale Modul bestimmt die effektivste Zugriffsmethode (z. B. eine Tabellenüberprüfung, eine Indexüberprüfung oder ein gelesener Schlüssel). Die Zugriffsmethoden und Puffer-Manager-Komponenten des Speichermoduls bestimmen das allgemeine Muster der auszuführenden Lesevorgänge und optimieren die zum Implementieren der Zugriffsmethode erforderlichen Lesevorgänge. Der Thread, der den Batch ausführt, plant die Ausführung der Lesevorgänge.
Vorauslesen (Read-Ahead)
Das Datenbank-Engine unterstützt einen Leistungsoptimierungsmechanismus, der als Read-Ahead oder Vorauslesen bekannt ist. Read-Ahead vorausahnt die Daten- und Indexseiten, die zur Erfüllung eines Ausführungsplans benötigt werden, und lädt die Seiten in den Puffer-Cache, bevor sie von der Abfrage genutzt werden. Dieser Prozess ermöglicht es, dass Berechnung und E/A gleichzeitig ablaufen, wobei sowohl die CPU als auch der Datenträger vollständig genutzt werden.
Mit dem Read-Ahead-Mechanismus kann das Datenbankmodul bis zu 64 zusammenhängende Seiten (512 KB) aus einer Datei lesen. Das Lesen wird als einzelner Scatter-Gather-Lesevorgang für die entsprechende Anzahl von (wahrscheinlich nicht zusammenhängenden) Puffern im Zwischenspeicher ausgeführt. Wenn eine der Seiten im Bereich bereits im Puffercache vorhanden ist, wird die entsprechende Seite aus dem Lesevorgang verworfen, wenn der Lesevorgang abgeschlossen ist. Der Seitenbereich kann auch von beiden Enden "gekürzt" werden, wenn die entsprechenden Seiten bereits im Cache vorhanden sind.
Es gibt zwei Arten des Read-Ahead: eine für Datenseiten und eine für Indexseiten.
Lesen von Datenseiten
Tabellenscans, die vom Datenbankmodul für das Lesen von Datenseiten verwendet werden, sind effizient. Die IAM-Seiten (Index Allocation Map) in einer SQL Server-Datenbank listen die von einer Tabelle oder einem Index verwendeten Datenblöcke auf. Die Speicher-Engine kann die IAM lesen, um eine geordnete Liste der Datenträgeradressen zu erstellen, die gelesen werden müssen. Hierdurch wird der Speicher-Engine ermöglicht, E/A-Operationen in Form von langen, sequenziellen Lesevorgängen zu optimieren, die abhängig von ihrem Speicherort auf dem Datenträger nacheinander ausgeführt werden. Weitere Informationen zu IAM-Seiten finden Sie unter Verwalten des von Objekten verwendeten Platzes.
Lesen von Indexseiten
In der Speicher-Engine werden Indexseiten nacheinander in der Reihenfolge der Schlüssel gelesen. Diese Abbildung zeigt z. B. eine vereinfachte Darstellung eines Satzes von Blattseiten, die einen Satz von Schlüsseln enthalten, und den Zwischenindexknoten, der eine Zuordnung der Blattseiten vornimmt. Weitere Informationen zur Struktur von Seiten in einem Index finden Sie unter "Gruppierte und nicht gruppierte Indizes".
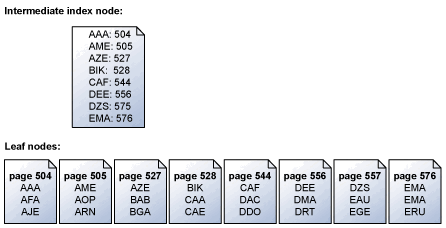
Die Speicher-Engine verwendet die Informationen der Zwischenindexseite oberhalb der Blattebene, um serielle Read-Ahead-Operationen für die Seiten zu planen, die die Schlüssel enthalten. Wenn eine Anforderung für alle Schlüssel von ABC bis zu DEF gemacht wird, liest das Speicher-Engine zuerst die Indexseite über der Blattseite. Es liest jedoch nicht nur jede Datenseite in Sequenz von Seite 504 bis Seite 556 (die letzte Seite mit Schlüsseln im angegebenen Bereich). Stattdessen scannt die Speicher-Engine die Zwischenindexseite und erstellt eine Liste der Blattseiten, die gelesen werden müssen. Anschließend plant die Speicher-Engine alle Lesevorgänge, geordnet nach Schlüsseln. Die Speicher-Engine erkennt ebenfalls, dass es sich bei den Seiten 504/505 und 527/528 um zusammenhängende Seiten handelt, und führt einen einzelnen Scatter-Lesevorgang aus, um angrenzende Seiten in einem einzigen Vorgang abzurufen. Wenn viele Seiten in einem seriellen Vorgang abgerufen werden sollen, plant die Speicher-Engine einen Block von Lesevorgängen zur selben Zeit. Wenn eine Teilmenge dieser Lesevorgänge abgeschlossen ist, plant das Speichermodul eine gleiche Anzahl neuer Lesevorgänge, bis alle erforderlichen Lesevorgänge geplant sind.
Die Speicher-Engine nutzt Vorabrufen, um die Suchvorgänge in Basistabellen aus nicht gruppierten Indizes zu beschleunigen. Die Blattzeilen eines nicht gruppierten Indexes enthalten Zeiger auf die Datenzeilen, die die jeweiligen Schlüsselwerte enthalten. Wenn das Speichermodul die Blattseiten des nicht gruppierten Indexes liest, beginnt es auch mit der Planung asynchroner Lesevorgänge für die Datenzeilen, deren Zeiger bereits abgerufen wurden. Dadurch kann das Speichermodul Datenzeilen aus der zugrunde liegenden Tabelle abrufen, bevor der Scan des nicht gruppierten Indexes abgeschlossen wird. Dieses Verfahren wird unabhängig davon eingesetzt, ob die Tabelle über einen gruppierten Index verfügt. SQL Server Enterprise Edition verwendet mehr Vorladen als andere Editionen von SQL Server, sodass mehr Seiten vorausgelesen werden können. Die Stufe des Vorabrufs kann in keiner der Editionen konfiguriert werden. Weitere Informationen zu nicht gruppierten Indizes finden Sie unter "Gruppierte und nicht gruppierte Indizes".
Erweitertes Scannen
In SQL Server Enterprise Edition ermöglicht die erweiterte Scanfunktion mehreren Aufgaben, vollständige Tabellenscans zu teilen. Wenn für einen Ausführungsplan einer Transact-SQL-Anweisung ein Scan der Datenseiten in einer Tabelle erforderlich ist und das Datenbank-Engine erkennt, dass die Tabelle bereits für einen anderen Ausführungsplan gescannt wurde, verknüpft Datenbank-Engine den zweiten Scan mit dem ersten Scan, und zwar an der aktuellen Position des zweiten Scans. Datenbank-Engine liest jede Seite einmal und übergibt die Zeilen jeder Seite an beide Ausführungspläne. Dieser Vorgang wird fortgesetzt, bis das Ende der Tabelle erreicht ist.
Zu diesem Zeitpunkt verfügt der erste Ausführungsplan über die vollständigen Ergebnisse eines Scans. Der zweite Ausführungsplan muss jedoch weiterhin die gelesenen Datenseiten abrufen, bevor er der laufenden Überprüfung beigetreten ist. Der Scan für den zweiten Ausführungsplan kehrt zur ersten Datenseite der Tabelle zurück und scannt die folgenden Seiten, bis die Seite erreicht ist, an der der Join mit dem ersten Scan erfolgt ist. Auf diese Weise können beliebig viele Scans kombiniert werden. Das Datenbankmodul durchläuft wiederholt die Datenseiten, bis alle Scans abgeschlossen sind. Dieser Mechanismus wird auch als "merry-go-round scanning" bezeichnet und veranschaulicht, warum die Reihenfolge der von einer SELECT Anweisung zurückgegebenen Ergebnisse nicht garantiert werden kann, ohne eine ORDER BY Klausel.
Nehmen Sie z. B. an, Sie verfügen über eine Tabelle mit 500.000 Seiten.
UserA führt eine Transact-SQL-Anweisung aus, die eine Überprüfung der Tabelle erfordert. Wenn dieser Scan 100.000 Seiten verarbeitet hat, führt eine weitere Transact-SQL Anweisung aus, UserB die dieselbe Tabelle überprüft. Das Datenbank-Engine plant einen Satz mit Leseanforderungen für die Seiten nach Seite 100.001 und gibt die Zeilen für jede Seite an beide Scans zurück. Wenn der Scan die 200.000te Seite erreicht, führt eine weitere Transact-SQL Anweisung aus, UserC die dieselbe Tabelle überprüft. Beginnend mit Seite 200.001 gibt Datenbank-Engine die Zeilen jeder gelesenen Seite an alle drei Scans zurück. Nachdem es die 500.000. Zeile liest, ist der Scan für UserA abgeschlossen, und die Scans für UserB und UserC springen zurück und beginnen wieder mit dem Lesen ab Seite 1. Wenn das Datenbankmodul Seite 100.000 erreicht, wird der Scan für UserB abgeschlossen. Der Scan nach UserC geht dann allein weiter, bis Seite 200.000 gelesen wird. An diesem Punkt sind alle Scans abgeschlossen.
Ohne die erweiterten Scanfunktionen müssten sich die einzelnen Benutzer den Pufferspeicher teilen, was Konflikte in der Speicherverteilung verursachen würde. Dieselben Seiten würden dann einmal für jeden Benutzer gelesen werden, anstatt einmal gelesen und dann für mehrere Benutzer freigegeben zu werden. Dies würde die Leistung beeinträchtigen und Ressourcen unnötig beanspruchen.