Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Die verteilte Wiedergabe von SQL Server ist mit SQL Server 2022 (16.x) und höheren Versionen nicht verfügbar.
Das Distributed Replay-Feature von Microsoft SQL Server unterstützt Sie beim Bewerten der Auswirkungen zukünftiger Upgrades von SQL Server. Mit dem Hilfsprogramm können Sie auch die Auswirkungen von Hardware- und Betriebssystemupgrades sowie SQL Server -Optimierungen bewerten.
Einstellung von Distributed Replay in SQL Server 2022
Verteilte Wiedergabe ist ab SQL Server 2022 (16.x) veraltet, wie in veralteten Datenbankmodulfeatures in SQL Server 2022 (16.x) erwähnt. Distributed Replay ist von SQL Server Native Client (SNAC) abhängig, der aus SQL Server 2022 (16.x) herausgenommen wurde. Diese Änderung ist in den Supportrichtlinien für SQL Server Native Client dokumentiert. Darüber hinaus stützt sich Distributed Replay auf .trc-Dateien, die mit SQL Trace und SQL Server Profiler erfasst werden, die beide ebenfalls veraltet sind.
Der Distributed Replay Controller wurde aus dem SQL Server 2022 (16.x) Setup herausgenommen, und der Distributed Replay Client ist ab Version 18 nicht mehr in SQL Server Management Studio (SSMS) verfügbar. Um den Distributed Replay Controller zu erhalten, müssen Sie SQL Server 2019 (15.x) oder eine frühere Version installieren. Um den Distributed Replay Client zu erhalten, müssen Sie SSMS 17.9.1 installieren.
Kunden mit SQL Server 2022 (16.x) können stattdessen die Hilfsprogramme der Replay Markup Language (RML) verwenden, die ostress zum Wiedergeben einer Workload enthalten.
Vorteile von Distributed Replay
Ähnlich wie mit dem SQL Server Profiler können Sie mithilfe von Distributed Replay eine aufgezeichnete Ablaufverfolgung in einer aktualisierten Testumgebung wiedergeben. Im Gegensatz zum SQL Server Profiler ist das Distributed Replay nicht auf die Wiedergabe der Workload eines einzelnen Computers beschränkt.
Das Distributed Replay bietet eine stärker skalierbare Lösung als der SQL Server Profiler. Mit Distributed Replay können Sie eine Arbeitsauslastung von mehreren Computern wiedergeben und eine unternehmenskritische Arbeitsauslastung besser simulieren.
Das Distributed Replay-Feature kann Ablaufverfolgungsdaten mithilfe mehrerer Computer verwenden und eine unternehmenskritische Arbeitsauslastung simulieren. Verwenden des Distributed Replay für Anwendungskompatibilitätstests, Leistungstests oder die Kapazitätsplanung.
Verwendungsbereiche von Distributed Replay
Der SQL Server Profiler und das Distributed Replay überschneiden sich in manchen Punkten.
Mit SQL Server Profiler können Sie eine aufgezeichnete Ablaufverfolgung in einer aktualisierten Testumgebung wiedergeben. Sie können auch die Wiedergabeergebnisse analysieren, um nach möglichen Funktions- und Leistungsinkompatibilitäten zu suchen. Mit dem SQL Server Profiler kann jedoch nur die Workload eines einzelnen Computers wiedergegeben werden. Wenn Sie eine ressourcenintensive OLTP-Anwendung mit zahlreichen gleichzeitig aktiven Verbindungen oder einem hohen Durchsatz wiedergeben, kann der SQL Server Profiler zu einem Ressourcenengpass werden.
Das Distributed Replay bietet eine stärker skalierbare Lösung als der SQL Server Profiler. Mit Distributed Replay können Sie eine Arbeitsauslastung von mehreren Computern wiedergeben und eine unternehmenskritische Arbeitsauslastung besser simulieren.
In der folgenden Tabelle ist beschrieben, wann jedes Tool verwendet werden sollte.
| Werkzeug | Verwenden, wenn ... |
|---|---|
| SQL Server Profiler | Sie möchten den herkömmlichen Wiedergabemechanismus auf einem einzelnen Computer verwenden. Insbesondere benötigen Sie zeilenweise Debugfunktionen, z. B. die Befehle Schritt, Ausführen bis Cursorposition und Haltepunkt ein/aus. Sie möchten eine Analysis Services-Ablaufverfolgung wiedergeben. |
| Verteilte Wiedergabe | Sie möchten die Anwendungskompatibilität auswerten. Sie möchten z. B. Upgradeszenarien für SQL Server und das Betriebssystem, Hardwareupgrades oder die Indexoptimierung testen. Die Parallelität in der aufgezeichneten Ablaufverfolgung ist so stark, dass mit einem einzelnen Wiedergabeclient keine ausreichende Simulation erzielt werden kann. |
Konzepte von Distributed Replay
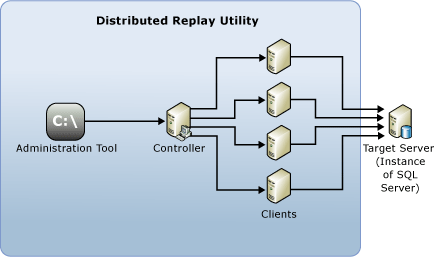
Die folgenden Komponenten bilden die Distributed Replay-Umgebung:
Distributed Replay–Verwaltungstool: Eine Konsolenanwendung (DReplay.exe), die zur Kommunikation mit Distributed Replay Controller verwendet werden kann. Verwenden Sie das Verwaltungstool zum Steuern der verteilten Wiedergabe.
Distributed Replay-Controller: Ein Computer, auf dem der Windows-Dienst „SQL Server Distributed Replay-Controller“ ausgeführt wird. Der Distributed Replay Controller koordiniert die Aktionen der Distributed Replay Clients. Es kann in jeder Distributed Replay-Umgebung jeweils nur eine Controllerinstanz geben.
Distributed Replay-Clients: Mindestens ein Computer (physisch oder virtuell), auf dem der Windows-Dienst „SQL Server Distributed Replay-Client“ ausgeführt wird. Die Distributed Replay Clients simulieren gemeinsam Arbeitsauslastungen auf einer Instanz von SQL Server. In jeder Distributed Replay-Umgebung kann sich mindestens ein Client befinden.
Zielserver: Eine Instanz von SQL Server, mit der Distributed Replay-Clients Ablaufverfolgungsdaten wiedergeben können. Es wird empfohlen, den Zielserver in einer Testumgebung zu platzieren.
Distributed Replay-Verwaltungstool, Controller und Client können auf verschiedenen Computern oder demselben Computer installiert werden. Auf demselben Computer kann nur eine Instanz des Distributed Replay Controller oder Client-Diensts ausgeführt werden.
In der folgenden Abbildung ist die physische Architektur von SQL Server Distributed Replay dargestellt:
Tasks von Distributed Replay
| Taskbeschreibung | Artikel |
|---|---|
| Beschreibt, wie Distributed Replay konfiguriert wird. | Konfigurieren von Distributed Replay |
| Beschreibt, wie die Eingabedaten der Ablaufverfolgung vorbereitet werden. | Vorbereiten von Eingabedaten für die Ablaufverfolgung |
| Beschreibt, wie die Ablaufverfolgungsdaten wiedergegeben werden. | Trace-Daten wiedergeben |
| Beschreibt, wie die Ergebnisse der Ablaufverfolgungsdaten von Distributed Replay überprüft werden. | Überprüfen der Wiedergabeergebnisse |
| Beschreibt, wie das Verwaltungstool zum Initiieren, Überwachen und Abbrechen von Vorgängen auf dem Controller verwendet wird. | Befehlszeilenoptionen für das Verwaltungstool (Distributed Replay Utility) |
Anforderungen
Bevor Sie das Distributed Replay-Feature verwenden, sollten Sie die in diesem Artikel beschriebenen Produktanforderungen berücksichtigen.
Anforderungen an die Eingabedatei für die Ablaufverfolgung
Für die erfolgreiche Wiedergabe von Ablaufverfolgungsdaten müssen die Anforderungen an Version und Format erfüllt und die erforderlichen Ereignisse und Spalten enthalten sein.
Versionen der Eingabedatei für die Ablaufverfolgung
Distributed Replay unterstützt Eingabe-Ablaufverfolgungsdaten, die in den folgenden SQL Server-Versionen gesammelt wurden:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (Kumulatives Update 1 und höher – siehe SQL Server 2017-Buildversionen)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formate für die Eingabe der Ablaufverfolgung
Die Eingabedaten der Ablaufverfolgung können in einem der folgenden Formate vorliegen:
Einzelne Ablaufverfolgungsdatei mit der Erweiterung
.trc.Ein Satz von Rollover-Protokolldateien, die der Dateirollover-Benennungskonvention folgen, z. B.:
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Ereignisse und Spalten in der Eingabe für die Ablaufverfolgung
Die Eingabedaten der Ablaufverfolgung müssen bestimmte Ereignisse und Spalten enthalten, die von Distributed Replay wiedergegeben werden sollen. Die Vorlage TSQL_Replay in SQL Server Profiler enthält neben zusätzlichen Informationen alle erforderlichen Ereignisse und Spalten. Weitere Informationen zu dieser Vorlage finden Sie unter Replay Requirements.
Warnung
Wenn Sie Eingabedaten der Ablaufverfolgung nicht mithilfe der Vorlage TSQL_Replay erfassen oder wenn die Anforderungen an die Eingabedaten nicht erfüllt sind, können unerwartete Wiedergabeergebnisse zurückgegeben werden.
Sie können auch eine benutzerdefinierte Ablaufverfolgungsvorlage erstellen und diese zur Wiedergabe von Ereignissen mit Distributed Replay verwenden, solange sie die folgenden Ereignisse enthält:
- Audit-Anmeldung
- Überwachungs-Abmeldung
- BestehendeVerbindung
- RPC-Ausgabeparameter
- RPC:Abgeschlossen
- RPC:Wird gestartet
- SQL: Batch abgeschlossen
- SQL:BatchStarting
Wenn Sie serverseitige Cursor wiedergeben, sind auch die folgenden Ereignisse erforderlich:
- CursorClose
- CursorExecute
- CursorOpen
- CursorPrepare
- CursorUnprepare
Wenn Sie serverseitige vorbereitete SQL-Anweisungen wiedergeben, sind auch die folgenden Ereignisse erforderlich:
- Ausführung vorbereiteter SQL-Anweisung
- SQL vorbereiten
Alle Eingabedaten der Ablaufverfolgung müssen die folgenden Spalten enthalten:
- Ereignisklasse
- Ereignisfolge
- Textdaten
- Anwendungsname
- Anmeldename
- Datenbankname
- Datenbank-ID
- Hostname (Rechnername)
- Binärdaten
- SPID
- Startzeit
- Endzeitpunkt
- IsSystem
Unterstützte Kombinationen aus Eingaben der Ablaufverfolgung und Zielserver
In der folgenden Tabelle sind die unterstützten Versionen der Ablaufverfolgungsdaten sowie jeweils die unterstützten Versionen von SQL Server aufgeführt, für die Daten wiedergegeben werden können.
| Version der Eingabedaten für die Ablaufverfolgung | Unterstützte Versionen von SQL Server für die Zielserverinstanz |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Betriebssystemanforderungen
Zum Ausführen des Verwaltungstools und der Controller- und Clientdienste werden dieselben Betriebssysteme wie für die SQL Server -Instanz unterstützt. Weitere Informationen dazu, welche Betriebssysteme für Ihre SQL Server-Instanz unterstützt werden, finden Sie unter Hardware- und Softwareanforderungen für SQL Server 2016 und SQL Server 2017.
Distributed Replay-Funktionen werden unter x86-basierten und x64-basierten Betriebssystemen unterstützt. Bei x64-basierten Betriebssystemen wird nur der WOW-Modus (Windows on Windows) unterstützt.
Installationseinschränkungen
Jeder einzelne Computer kann nur eine einzelne Instanz jeder installierten Distributed Replay-Funktion enthalten. Die folgende Tabelle legt dar, wie viele Installationen der einzelnen Funktionen in einer einzelnen Distributed Replay-Umgebung zulässig sind.
| Verteilte Replay-Funktion | Maximale Installationen pro Wiedergabeumgebung |
|---|---|
| SQL Server Distributed Replay-Controllerdienst | 1 |
| SQL Server Distributed Replay Client-Dienst | 16 (physische oder virtuelle Computer) |
| Verwaltungstool | Unbegrenzt |
Hinweis
Zwar kann auf einem einzelnen Computer nur eine Instanz des Verwaltungstools installiert werden, doch können Sie mehrere Instanzen des Verwaltungstools starten. Von mehreren Verwaltungstools ausgegebene Befehle werden in der Reihenfolge aufgelöst, in der sie empfangen werden.
Datenzugriffsanbieter
Distributed Replay unterstützt nur den SQL Server Native Client ODBC-Datenzugriffsanbieter.
Anforderungen bei der Vorbereitung des Zielservers
Es wird empfohlen, den Zielserver in einer Testumgebung zu platzieren. Um Ablaufverfolgungsdaten für eine andere Instanz von SQL Server abzuspielen, als sie ursprünglich aufgezeichnet wurde, stellen Sie sicher, dass auf dem Zielserver die folgenden Schritte ausgeführt wurden:
Alle in den Ablaufverfolgungsdaten verzeichneten Anmeldungen und Benutzer müssen auch in der gleichen Datenbank auf dem Zielserver vorhanden sein.
Alle Benutzernamen und Benutzer auf dem Zielserver müssen über dieselben Berechtigungen wie auf dem ursprünglichen Server verfügen.
Die Datenbank-IDs auf dem Ziel sollten idealerweise mit denen auf der Quelle übereinstimmen. Wenn sie allerdings nicht gleich sein sollten, können Sie basierend auf DatabaseName einen Abgleich ausführen, sofern dieser in der Ablaufverfolgung enthalten ist.
Die Standarddatenbank für jede in den Protokolldaten enthaltene Anmeldung muss auf dem Zielserver auf die entsprechende Zieldatenbank der Anmeldung festgelegt werden. Angenommen, die wiederzugebenden Ablaufverfolgungsdaten enthalten Aktivitäten für den Benutzernamen Fred in der Datenbank Fred_Db der ursprünglichen Instanz von SQL Server. Dann muss auf dem Zielserver die Standarddatenbank für den Benutzernamen Fredauf die Datenbank festgelegt werden, die mit Fred_Db übereinstimmt (auch, wenn sich der Datenbankname unterscheidet). Um die Standarddatenbank des Logins festzulegen, verwenden Sie die Systemgespeicherte Prozedur
sp_defaultdb.
Beim Wiedergeben von Ereignissen, die fehlende oder fehlerhafte Benutzernamen aufweisen, können Wiedergabefehler auftreten, die Wiedergabe wird jedoch fortgesetzt.