Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird beschrieben, wie Sie einen Cluster mit Storage Spaces Direct (S2D) in der System Center - Virtual Manager (VMM) Fabric einrichten. Sie können ein paar Arten von Clustern einrichten:
- Eine hyperkonvergente Bereitstellung, die Compute- und Speicherressourcen im selben Cluster ausführt.
- Eine disaggregatierte Bereitstellung, in der Compute und Speicher in separaten Umgebungen ausgeführt werden. Die Speicherkomponente basiert auf S2D und Dateiserver mit horizontaler Skalierung (SOFS), um ein unabhängig skalierbares Speicherrepository für VMs und Anwendungen bereitzustellen.
Bevor Sie beginnen
- Stellen Sie sicher, dass Sie den VMM 2016 oder eine neuere Version verwenden.
- Auf den Hyper-V-Hosts in einem Cluster sollte Windows Server 2016 oder höher mit der Hyper-V-Rolle installiert und für das Hosten von VMs konfiguriert sein.
- Sie sollten Netzwerke auf Hosts einrichten, die Knoten im Cluster sind, bevor Sie S2D aktivieren.
- Für hyperkonvergente Bereitstellungen können Sie S2D aktivieren, wenn Sie einen bestehenden Hyper-V-Cluster zur VMM-Fabric hinzufügen oder wenn Sie einen Cluster aus eigenständigen Hyper-V-Hosts in der VMM-Fabric erstellen. Sie können S2D derzeit nicht auf einem Hyper-V-Cluster aktivieren, der von Bare-Metal-Computern mit dem Nano-Betriebssystem bereitgestellt wird.
Bereitstellen eines hyperkonvergenten Clusters
Sie können einen hyperkonvergenten Cluster in der VMM-Fabric mit denselben Methoden bereitstellen, die Sie auch bei anderen Hyper-V-Clustern anwenden würden:
- Aktivieren Sie S2D auf einem Hyper-V-Cluster, der derzeit in der VMM-Fabric verwaltet wird.
- Fügen Sie einen bestehenden Hyper-V-Cluster zur VMM-Fabric hinzu, mit oder ohne aktiviertem S2D.
- Stellen Sie einen Hyper-V-Cluster bereit und aktivieren Sie S2D auf den vorhandenen Hyper-V-Hosts.
- Bereitstellung eines Hyper-V-Clusters mit aktiviertem S2D von Bare-Metal-Servern.
- Sie können S2D derzeit nicht in einer hyperkonvergenten Bereitstellung auf einem Hyper-V-Cluster aktivieren, das von Bare-Metal-Computern mit dem Nano-Betriebssystem bereitgestellt wird.
Bereitstellungsschritte
- Erstellen Sie einen Hyper-V-Cluster in der VMM-Fabric und aktivieren Sie S2D für diesen. Wenn Sie bereits einen S2D-Cluster haben, den Sie außerhalb des VMM konfiguriert haben, können Sie ihn auch zur VMM-Fabric hinzufügen.
- Richten Sie das Netzwerk des Clusters ein. Weitere Informationen
- Ändern Sie den Speicherpool und erstellen Sie freigegebene Cluster-Volumes (CSVs).
- Stellen Sie VMs auf dem Cluster bereit.
Erstellen eines Clusters
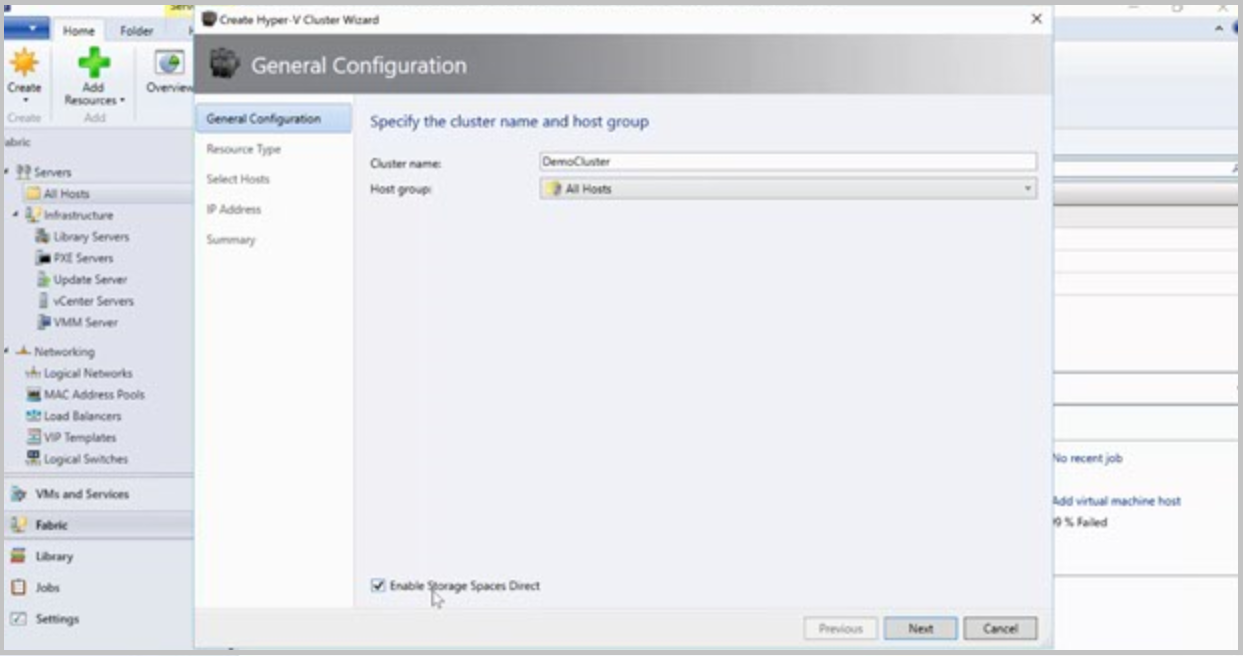
- Wählen Sie Fabric-Ressourcen>Erstellen>Hyper-V-Cluster.
- Geben Sie in Allgemeine Konfiguration einen Clusternamen ein. Wählen Sie eine Hostgruppe und dann Direkte Speicherplätze aktivieren aus.
- Der Rest der Schritte ist identisch mit den Anweisungen zum Erstellen eines Hyper-V-Hostclusters mit einem vorhandenen Server. Beachten Sie, dass Sie den Cluster validieren müssen, wenn S2D aktiviert ist.
Wenn Sie den Cluster erstellen, führt VMM folgende Schritte aus:
- Auf jedem Host:
- Installiert die Dateiserverrolle.
- Installiert die Failoverclustering-Funktion.
- Aktiviert Speicherreplikat und Datendeduplizierung.
- Validiert die Clusterkonfiguration.
- Erstellt den Cluster.
- Aktiviert S2D und erstellt einen Speicherpool mit demselben Namen wie der im Assistenten angegebene.
Einen vorhandenen Cluster hinzufügen
- Wählen Sie VMs und Dienste, klicken Sie mit der rechten Maustaste auf Alle Hosts und wählen Sie Hyper-V-Hosts und -Cluster hinzufügen.
- Wenn sich der Cluster nicht in der VMM-Domäne befindet, wählen Sie Der Windows-Server-Computer befindet sich in einer nicht vertrauenswürdigen Active Directory-Domäne aus.
- Geben Sie das Cluster an und stellen Sie ein ausführendes Konto bereit. Dadurch wird der Hostcluster zu VMM hinzugefügt.
- Wenn der Cluster nicht S2D-aktiviert ist, müssen Sie es in den Clustereigenschaften aktivieren.
Pool verwalten und CSVs erstellen
Nachdem Sie das Netzwerk auf dem Cluster eingerichtet haben, erstellen Sie CSVs.
- Wählen Sie Sie Fabric>Speicher>Arrays und klicken Sie mit der rechten Maustaste auf den Direkte Speicherplätze Cluster >Pool verwalten. Ändern Sie bei Bedarf den Namen des Pools, der standardmäßig erstellt wurde.
- Klicken Sie mit der rechten Maustaste auf den Cluster, und klicken Sie dann auf >Eigenschaften>Freigegebene Volumes, um ein Volume zu erstellen.
- Im Assistenten zum Erstellen von Volumes >Kapazität können Sie die Volume-Größe, das Dateisystem, die Resilienz und die Optionen für die Speicherebenen festlegen. Beim Erstellen des Volumes wird automatisch ein virtueller Datenträger erstellt.
Wenn Sie PowerShell verwenden, wird der Pool und die Speicherebene automatisch mit der Option Enable-ClusterS2D autoconfig=true erstellt.
Bereitstellen von virtuellen Computern
VMs können direkt im hyperkonvergenten Cluster bereitgestellt werden. Ihre virtuellen Festplatten werden auf den Volumes platziert, die Sie erstellen. Sie erstellen und stellen diese virtuellen Computer genauso wie jede andere VM bereit.
Bereitstellen einer disaggregatierten Bereitstellung
In einer disaggregatierten Bereitstellung werden Compute und Speicher in separaten Umgebungen ausgeführt. Die Speicherkomponente basiert auf S2D und Dateiserver mit horizontaler Skalierung (SOFS), um ein unabhängig skalierbares Speicherrepository für VMs und Anwendungen bereitzustellen.
Einrichten eines SOFS-Clusters und Aktivieren von S2D
Auswählen von Fabric-Ressourcen>Erstellen>Dateiserver-Cluster
Geben Sie in Allgemeine Konfiguration einen Clusternamen ein. Wählen Sie eine Hostgruppe und dann Speicher, der direkt an jeden Clusterknoten angefügt ist (direkte Speicherplätze) aus.
Geben Sie im Ressourcentyp das RunAs-Konto mit lokalen Administratorberechtigungen auf den Servern an, die Sie dem Cluster hinzufügen möchten, und legen Sie fest, ob vorhandene Windows-Server oder Bare-Metal-Computer hinzugefügt werden sollen.
Definieren Sie in Cluster-Knoten eine Liste von Computern, die dem Cluster hinzugefügt werden sollen.
Bestätigen Sie auf der Seite „Zusammenfassung“ die Einstellungen und wählen Sie „Fertigstellen“ aus.
Wenn Sie dem SOFS-Cluster weitere Knoten hinzufügen möchten, erkennt VMM automatisch alle Datenträger, die dem Knoten zugeordnet sind. Wenn Sie einen Speicherpool ändern und die neuen hinzuzufügenden Datenträger auswählen, macht VMM diese Datenträger für die Hosts und VMs verfügbar, die den von diesem Pool unterstützten Share verwenden. Erfahren Sie mehr über das Hinzufügen von Knoten zu einem SOFS.
Hinzufügen eines vorhandenen SOFS-Clusters mit aktiviertem S2D
- Wählen Sie Fabric>Ressourcen hinzufügen, Speichergeräte aus.
- Wählen Sie im Assistenten „Hinzufügen von Ressourcen“ die Option Windows-basierten Dateiserver aus.
- Geben Sie im Ermittlungsbereich die Cluster-IP-Adresse oder den FQDN an, stellen Sie ein ausführendes Konto mit Clusterzugriff bereit und überprüfen Sie bei Bedarf, ob sich der Cluster in einer anderen Domäne befindet.
- Wählen Sie im Speichergerät das SOFS aus, um es dem VMM-Fabric hinzuzufügen. Sie sollten dem Pool erst eine Klassifizierung zuweisen, nachdem Sie den Anbieter hinzugefügt haben.
- In Zusammenfassung die Einstellungen überprüfen und den Assistenten abschließen.
Pool verwalten und CSVs erstellen
- Nachdem das SOFS-Cluster im VMM-Fabric ist, klicken Sie mit der rechten Maustaste auf Speicher>Dateiserver>Pools verwalten. Wählen Sie Neu aus, um einen neuen Pool zu erstellen.
- Geben Sie im Assistenten zum Erstellen neuer Speicherpools unter >Allgemein einen Namen und eine Klassifizierung für den Pool ein.
- Wählen Sie in Physische Datenträger die virtuellen Datenträger aus, um den Pool zu erstellen. Neu einlesen und Scheck, dass der Pool in Speicher>Arrays erscheint.
- Jetzt können Sie Dateifreigaben aus dem Pool erstellen. Aktivieren Dateifreigabe erstellen.
- Im Assistenten zum Erstellen einer Dateifreigabe >Allgemein geben Sie einen Namen für die Freigabe an und wählen Sie den Pool aus, aus dem der Speicher entnommen werden soll.
- Geben Sie in „Kapazität“ die Freigabegröße und die Einstellungen an.
- Überprüfen Sie unter Zusammenfassung die Einstellungen. Nachdem der Share erstellt wurde, wird ein neues CSV unter dem Speicherpool hinzugefügt.
Nächste Schritte
- Sie geben den Dateifreigabepfad in den Eigenschaften eines Hyper-V-Hosts oder -Clusters an. Weitere Informationen zur Bereitstellung von Speicher.