Klassifizieren von Daten
Ein Onlinehandelsunternehmen verwendet verschiedene Arten von Daten. Jede Art von Daten profitiert von einer anderen Speicherlösung.
Anwendungsdaten können auf drei Arten klassifiziert werden: strukturiert, teilweise strukturiert und unstrukturiert. Im Folgenden erfahren Sie, wie Sie Ihre Daten klassifizieren, um die passende Speicherlösung für die jeweiligen Daten auszuwählen.
Ansätze zum Speichern von Daten in der Cloud
Im folgenden Video werden Ihre Optionen zum Speichern von Daten in der Cloud vorgestellt:
Strukturierte Daten
In strukturierten Daten, manchmal als relationale Daten bezeichnet, weisen alle Daten dieselben Felder oder Eigenschaften auf. Alle Daten weisen dieselbe Organisation und Form auf (Schema). Das gemeinsame Schema bietet die Möglichkeit, derartige Daten mit Abfragesprachen wie SQL (Structured Query Language) zu durchsuchen. Dadurch sind derartige Daten ideal für Anwendungen wie CRM-Systeme, Reservierungen und Bestandsverwaltung.
Strukturierte Daten werden häufig in Datenbanktabellen mit Zeilen und Spalten gespeichert. In der Tabelle gibt eine Schlüsselspalte an, wie eine Zeile in einer Tabelle mit Daten in einer anderen Zeile einer anderen Tabelle verknüpft ist. In der folgenden Abbildung ruft eine Tabelle mit Daten zu Ergebnissen mithilfe von Schlüsselspalten Daten aus einer Tabelle mit Kursteilnehmernamen und einer Tabelle mit Kursdaten ab.
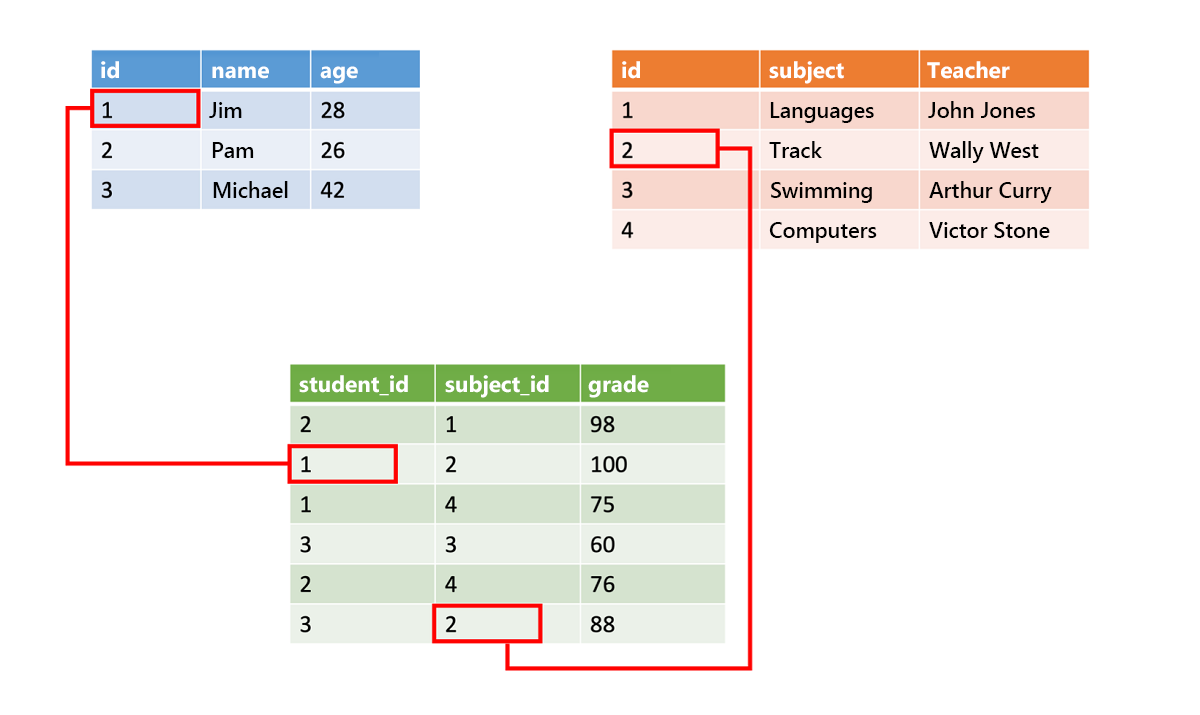
Strukturierte Daten sind einfach aufgebaut und können problemlos eingegeben, abgefragt und analysiert werden. Alle Daten weisen dasselbe Format auf. Durch das Vorschreiben einer einheitlichen Struktur wird allerdings eine Weiterentwicklung der Daten erschwert. Wenn Sie Datenfelder hinzufügen oder entfernen, müssen Sie alle Datensätze der neuen Struktur entsprechend aktualisieren.
Teilweise strukturierte Daten
Teilweise strukturierte Daten sind weniger organisiert als strukturierte Daten. Teilweise strukturierte Daten werden nicht in einem relationalen Format gespeichert, da die Felder nicht ohne Weiteres in Tabellen, Zeilen und Spalten passen. Teilweise strukturierte Daten enthalten Tags, die die Organisation und Hierarchie der Daten angeben. Ein Beispiel sind Schlüssel/Wert-Paare. Teilweise strukturierte Daten werden auch als nicht relationale oder NoSQL (Not only SQL)-Daten bezeichnet.
Eine Datenserialisierungssprache, die semistrukturierte Daten definiert. In der Datenklassifizierung handelt es sich bei der Serialisierung um die Konvertierung von Daten in ein Format, das übertragen oder gespeichert werden kann.
Softwareentwickler verwenden Datenserialisierungssprachen, um im Arbeitsspeicher gespeicherte Daten in eine Datei zu schreiben, die dann an ein anderes System gesendet, analysiert und gelesen werden kann. Sender und Empfänger benötigen keine Details über das jeweils andere System. Beide Systeme können die Daten verstehen, wenn sie dieselbe Serialisierungssprache verwenden.
Gebräuchliche Serialisierungssprachen
Drei gebräuchliche Serialisierungssprachen sind XML, JSON und YAML.
XML
Extensible Markup Language (XML) war eine der ersten Datensprachen, die weit verbreitet eingesetzt wurde. XML ist textbasiert, sodass XML für Mensch und Maschine leicht lesbar ist. XML-Parser sind für fast alle gängigen Entwicklungsplattformen verfügbar.
Sie können XML verwenden, um Beziehungen auszudrücken. XML umfasst Standards für Schema, Transformation und sogar Darstellung im Web.
Das folgende Beispiel drückt Name, Alter und Hobbys einer Person in XML aus:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML drückt die Form der Daten mithilfe von Tags aus, die in spitzen Klammern definiert werden. Die Tags gibt es in zwei Formen: Elemente, z. B. <FirstName>, und Attribute, die in Text wie Age="23" formuliert werden können. Elemente können untergeordnete Elemente haben, um Beziehungen auszudrücken. Das Tag <Hobbies> drückt beispielsweise eine Auflistung von Hobby-Elementen aus.
XML ist flexibel, und mit XML lassen sich komplexe Daten problemlos formulieren. Allerdings tendiert das XML-Format dazu, sehr umfangreich zu werden, sodass das Speichern, Verarbeiten und Übertragen über ein Netzwerk erschwert wird. Dies hat dazu geführt, dass andere Formate populärer wurden.
JSON
JSON (JavaScript Object Notation) weist eine einfache Spezifikation auf und verwendet zum Angeben der Datenstruktur geschweifte Klammern. Im Vergleich zu XML ist JSON weniger umfangreich und für Menschen leichter lesbar. JSON wird häufig von Webdiensten verwendet, um Daten zurückzugeben.
Nachstehend sind Name, Alter und Hobbys derselben Person in JSON ausgedrückt:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
Das JSON-Format ist nicht so formal wie XML. Es entspricht mehr einem Modell von Schlüssel/Wert-Paaren als einem formalen Datenausdruck. Wie der Namen vermuten lässt, weist die Programmiersprache JavaScript integrierte Unterstützung für dieses Format auf, sodass es sehr beliebt für die Webentwicklung geworden ist. Ähnlich wie bei XML gibt es für andere Sprachen Parser, die Sie verwenden können, um mit diesem Datenformat zu arbeiten. Der Nachteil von JSON ist, dass es eher programmiererorientiert ist, wodurch das Lesen und Ändern für technisch unerfahrene Personen erschwert wird.
YAML
YAML (YAML Ain't Markup Language) ist eine vor Kurzem entwickelte Datenserialisierungssprache. Ein Vorteil der Verwendung von YAML besteht darin, dass die Sprache im Vergleich zu anderen Sprachen für Menschen einfacher zu lesen ist. Die Datenstruktur wird durch Zeilenumbruch und -einzug definiert. Das YAML-Format verringert die Abhängigkeit von Strukturzeichen wie runden Klammern, Kommas und anderen Klammern.
Nachstehend sind dieselbe Daten in YAML ausgedrückt:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Dieses Format ist besser lesbar als JSON. Eine häufige Verwendung dafür sind Konfigurationsdateien, die von Personen geschrieben, aber von Programmen analysiert werden. YAML ist das neueste dieser Datenformate.
Es wird häufig für Konfigurationsdateien verwendet, die von Personen geschrieben wurden, aber von Programmen analysiert werden.
Was sind teilweise strukturierte oder NoSQL-Daten?
Das folgende Video beschreibt Speicheroptionen für teilweise strukturierte Daten und NoSQL-Daten:
Unstrukturierte Daten
Die Organisation von unstrukturierten Daten ist nicht definiert. Unstrukturierte Daten werden häufig im Dateiformat bereitgestellt, z. B. in Foto- oder Videodateien. Die Videodatei selbst hat möglicherweise eine Gesamtstruktur und teilweise strukturierte Metadaten, aber die Daten, die das Video selbst bilden, sind unstrukturiert. Aus diesem Grund werden Fotos, Videos und andere ähnliche Dateien als unstrukturierte Daten klassifiziert.
Zu unstrukturierten Daten zählen beispielsweise Folgende:
- Mediendateien, z. B. Fotos, Videos und Audiodateien.
- Microsoft 365-Dateien, z. B. Word-Dokumente.
- Textdateien.
- Protokolldateien.
Datenklassifizierung: Bewerten der Datentypen
Es gibt drei Möglichkeiten, um Daten zu klassifizieren: strukturiert, teilweise strukturiert und unstrukturiert. Damit Sie Ihre Daten klassifizieren und die passende Speicherlösung auswählen können, ist ein grundlegendes Verständnis der Unterschiede unabdingbar.
Strukturierte Daten sind organisierte Daten, die ohne Weiteres in Tabellen der Spalten mit Daten passen. Teilweise strukturierte Daten sind zwar ebenfalls organisiert und verfügen über eindeutige Eigenschaften und Werte, weisen jedoch Abweichungen in den Daten auf. Unstrukturierte Daten passen nicht ohne Weiteres in Tabellen oder Spalten und weisen kein einheitliches Schema auf.
Lassen Sie uns die Datasets, die in einem Onlineeinzelhandelsgeschäft verwendet werden, betrachten und klassifizieren.
Produktkatalogdaten
Die Produktkatalogdaten für ein Onlineeinzelhandelsgeschäft sind teilweise strukturiert. Jedes Produkt verfügt über Produkt-SKU, Beschreibung, Menge, Preis, Größenoptionen, Farboptionen, Foto und u. U. Video. Diese Daten erscheinen zunächst als relational, da sie die gleiche Struktur aufweisen. Wenn Sie jedoch neue Produkte bzw. neuartige Produkte einführen, kann es wünschenswert sein, andere Datenfelder hinzufügen. Stellen Sie sich beispielsweise vor, Sie nehmen neue Tennisschuhe in Ihr Sortiment auf, die über eine Bluetoothfunktion verfügen, mit der Sensordaten von den Schuhen an eine Fitness-App auf dem Smartphone des Benutzers übertragen werden. Der Trend zu dieser Funktion scheint immer beliebter zu werden, sodass Sie Kunden die Möglichkeit geben möchten, nach „bluetoothfähigen“ Schuhen zu filtern. Sie möchten nicht alle vorhandenen Schuhdaten mit der Eigenschaft „Bluetoothfähig“ aktualisieren. Sie möchten diese neue Eigenschaft nur zu neuen Schuhen hinzufügen.
Durch Hinzufügen der Eigenschaft „Bluetoothfähig“ sind die Daten Ihrer Schuhe nicht mehr homogen. Sie haben Unterschiede im Schema eingeführt. Wenn diese Änderung die einzige zu erwartende Ausnahme ist, können Sie die vorhandenen Daten normalisieren, sodass alle Produkte über ein „Bluetoothfähig“-Feld verfügen, um eine strukturierte und relationale Organisation aufrechtzuerhalten. Wenn dies jedoch nur eines von mehreren speziellen Feldern ist, die Sie in Zukunft unterstützen möchten, dann ist die Klassifizierung der Daten „teilweise strukturiert“. Die Daten werden durch Tags organisiert, wobei jedes Produkt im Katalog jedoch eindeutige Felder enthalten kann.
Die Klassifizierung für Produktkatalogdaten ist teilweise strukturiert.
Fotos und Videos
Bei den Fotos und Videos, die auf den Produktseiten angezeigt werden, handelt es sich um unstrukturierte Daten. Obwohl Mediendateien Metadaten enthalten können, ist der Inhalt der Mediendatei unstrukturiert.
Die Datenklassifizierung für Fotos und Videos ist unstrukturiert.
Geschäftsdaten
Business Analysten möchten in der Regel Business Intelligence-Funktionen implementieren, um Bestandspipelines auszuwerten und Vertriebsdaten zu überprüfen. Um diese Vorgänge auszuführen, müssen Daten aus mehreren Monaten aggregiert und dann abgefragt werden. Aufgrund des Bedarfs, ähnliche Daten zu aggregieren, müssen diese Daten strukturiert werden, damit die Daten eines Monats mit denen des nächsten Monats verglichen werden können.
Die Klassifizierung für Geschäftsdaten ist strukturiert.