Vor der Cloud
Nachdem wir nun definiert haben, was Cloud Computing ist, sehen wir uns Beispiele für die Nutzung von Computing in verschiedenen Bereichen wie Business Computing, wissenschaftliches Computing und Personal Computing vor dem Aufkommen von Cloud Computing an.
Beispiele für Domänen und Anwendungen
Business Computing: Beispiele für herkömmliche Managementinformationssysteme sind Logistik und Betrieb, Enterprise Resource Planning (ERP), Customer Relation Management (CRM), Büroproduktivität und Business Intelligence (BI). Diese Tools ermöglichten optimierte Prozesse, die zu einer gesteigerten Produktivität und Kostensenkung in einer Vielzahl von Unternehmen führten.
So ermöglicht die CRM-Software z. B. Unternehmen das Erfassen, Speichern, Verwalten und Interpretieren einer Vielzahl von Daten über ehemalige, aktuelle und potenzielle zukünftige Kunden. CRM-Software bietet eine integrierte Ansicht (in Echtzeit oder nahezu in Echtzeit) aller Organisationsinteraktionen mit Kunden. Beispielsweise könnte CRM-Software für ein Fertigungsunternehmen von einem Vertriebsteam verwendet werden, um Besprechungen, Aufgaben und Nachverfolgungen mit Kunden zu planen. Ein Marketingteam könnte Kunden gezielt mit Kampagnen ansprechen, die auf bestimmten Mustern basieren. Abrechnungsteams können Angebote und Rechnungen nachverfolgen. Als solches handelt es sich um ein zentrales Repository zur Speicherung dieser Informationen. Um diese Funktionalität zu ermöglichen, werden eine Vielzahl von Hardware- und Softwaretechnologien von der Organisation und den Vertriebsteams verwendet, um die Daten zu sammeln, die mithilfe verschiedener Datenbank- und Analysesysteme gespeichert und analysiert werden müssen.
Wissenschaftliches Computing: Wissenschaftliches Computing verwendet mathematische Modelle und Analysetechniken, die auf Computern implementiert werden, um wissenschaftliche Probleme zu lösen. Ein beliebtes Beispiel ist die Computersimulation physikalischer Phänomene. Dieses Feld hat die traditionellen theoretischen und laborexperimentellen Methoden gestört, indem Wissenschaftler und Ingenieure bekannte Ereignisse rekonstruieren oder zukünftige Situationen durch die Entwicklung von Programmen zur Simulation und Untersuchung verschiedener Systeme unter unterschiedlichen Umständen vorhersagen können. Solche Simulationen erfordern in der Regel eine sehr große Anzahl von Berechnungen, die häufig auf teuren Supercomputern oder verteilten Computerplattformen ausgeführt werden.
Persönliches Computing: Beim persönlichen Computing verwendet ein Benutzer verschiedene Anwendungen auf einem Universalcomputer. Solche Anwendungen können für die Office-Produktivität gelten, z. B. Textverarbeitung und Tabellenkalkulationen; Kommunikation, z. B. E-Mail-Clients; oder Unterhaltung, z. B. Videospiele oder Multimediadateien. Ein Personal Computing-Benutzer besitzt, installiert und verwaltet in der Regel die Software und Hardware, die für die Durchführung solcher Aufgaben verwendet wird.
Behandlung der Skalierung
Zunehmender Maßstab im Computing war ein fortlaufender Prozess, sei es, die Anzahl der Kunden und Ereignisse zu erhöhen, um sie in CRM zu erfassen, zu überwachen und zu analysieren, oder die Genauigkeit der numerischen Simulationen im Bereich der Computerwissenschaften oder den Realismus in Videospielanwendungen zu steigern. Darüber hinaus wurde der Bedarf an größerem Umfang durch die Zunahme der Technologieakzeptanz durch verschiedene Bereiche oder die Expansion von Unternehmen und Märkten sowie durch die anhaltende Zunahme der Anzahl der Nutzer und ihrer Bedürfnisse angetrieben. Organisationen müssen bei der Planung und dem Budget für die Bereitstellung ihrer Lösungen den Anstieg der Skalierung berücksichtigen.
Organisationen planen in der Regel ihre IT-Infrastruktur in einem Prozess, der als Kapazitätsplanung bezeichnet wird. Im Rahmen der Kapazitätsplanung wird die Zunahme bei der Nutzung verschiedener IT-Dienste gemessen und als Maßstab für die zukünftige Expansion herangezogen. Organisationen müssen im Voraus planen, neuere und bessere Server, Speicher und Netzwerkgeräte zu beschaffen, einzurichten und aufrechtzuerhalten. Manchmal sind Organisationen durch Software begrenzt, da sie möglicherweise nur eine begrenzte Anzahl von Lizenzen erworben haben und möglicherweise mehr erforderlich sind, um die Infrastruktur zu erweitern, um eine größere Anzahl von Benutzern zu decken.
Die grundlegendste Form der Skalierung wird als vertikale Skalierung bezeichnet, wobei alte Systeme durch neuere, leistungsstärkere Systeme ersetzt werden, die die erforderlichen Upgrades auf Serviceebene bereitstellen können. In vielen Fällen besteht die vertikale Skalierung aus dem Upgrade oder Ersetzen von Servern und Speichersystemen durch neuere, schnellere Server oder Speicherarrays mit erhöhter Kapazität. Dieser Vorgang kann Monate dauern, um diesen zu planen und auszuführen, zusammen mit einem Zeitraum, in dem der Dienst möglicherweise ausfallen könnte.
In bestimmten Arten von Systemen wird die Skalierung auch horizontal durchgeführt, indem die Menge der Ressourcen erhöht wird, die dem System zugeordnet sind. Ein Beispiel hierfür ist das High-Performance Computing, bei dem zusätzliche Server und Speicher hinzugefügt werden können, um die Leistung des Systems zu verbessern, was zu einer höheren Anzahl von Berechnungen führt, die pro Sekunde oder eine Erhöhung der Speicherkapazität des Systems durchgeführt werden können. Wie die vertikale Skalierung kann auch dieser Prozess Monate für die Planung und Ausführung in Anspruch nehmen, wobei auch Ausfallzeiten möglich sind.
Da Unternehmen ihre IT-Ausrüstung besaßen und instand hielten, während die Kosten für die Adressierung der Skalierung weiter stiegen, ermittelten die Unternehmen andere Methoden zur Kostensenkung. Große Unternehmen konsolidierten die Rechenanforderungen verschiedener Abteilungen in einem einzigen großen Rechenzentrum, in dem sie Immobilien, Energie, Kühlung und Vernetzung konsolidierten, um Kosten zu senken. Andererseits könnten kleine und mittelständische Unternehmen Immobilien, Netzwerk, Energie, Kühlung und physische Sicherheit leasen, indem sie ihre IT-Geräte in ein gemeinsames Rechenzentrum setzen. Dies wird in der Regel als Co-Location-Service bezeichnet, der von kleinen bis mittleren Unternehmen übernommen wurde, die keine eigenen Rechenzentren im Haus aufbauen wollten. Zusammenlegungsdienste werden weiterhin in verschiedenen Bereichen als kosteneffizienter Ansatz zur Senkung der Betriebskosten eingesetzt.
Die Skalierung hat alle Aspekte des Geschäfts computing beeinflusst. Beispielsweise hat die Skalierung CRM-Systeme durch die Erhöhung der Kunden oder durch die Menge der Informationen beeinflusst, die über Clients gespeichert und analysiert werden. Geschäftsinformatik hat Skalierung durch vertikale und horizontale Skalierung sowie die Konsolidierung von IT-Ressourcen in Rechenzentren und gemeinschaftlichen Standorten behandelt. Beim Scientific Computing wurden parallele und verteilte Systeme eingesetzt, um die Größe der Probleme und die Genauigkeit ihrer numerischen Simulationen hochzuskalieren. Eine Definition der parallelen Verarbeitung ist die Verwendung mehrerer homogener Computer, die den Zustand und die Funktion als einzelner großer Computer gemeinsam nutzen, um Groß- oder Hochpräzisionsberechnungen auszuführen. Verteiltes Computing ist die Verwendung mehrerer autonomer Computersysteme, die mit einem Netzwerk verbunden sind, um ein großes Problem in Teilvorgänge zu unterteilen, die gleichzeitig ausgeführt werden und über Nachrichten über das Netzwerk kommunizieren. Die wissenschaftliche Gemeinschaft hat in diesen Bereichen weiterhin Innovationen vorangetrieben, die sich mit der Skalierung befassen. Die Skalierung bei persönlichen Computern wurde durch gestiegene Benutzeranforderungen beeinflusst, die auf umfangreichere Inhalte und vielfältige Anwendungen zurückzuführen sind. Benutzer skalieren daher ihre eigenen persönlichen Computergeräte, um diese Anforderungen zu erfüllen.
Anstieg der Internetdienste
Die späten 90er Jahre verzeichneten einen stetigen Anstieg der Akzeptanz dieser Computing-Anwendungen und -Plattformen in allen Bereichen. Bald wurde erwartet, dass Software nicht nur funktionsfähig ist, sondern auch in der Lage ist, Wert und Einblicke für geschäftliche und persönliche Anforderungen zu erzeugen. Diese Anwendungen wurden für die Zusammenarbeit verwendet. Sie wurden kombiniert und aufeinander abgestimmt, um untereinander Informationen zu übertragen. Die IT war nicht mehr nur eine Kostenstelle für ein Unternehmen, sondern eine Quelle für Innovation und Effizienz.
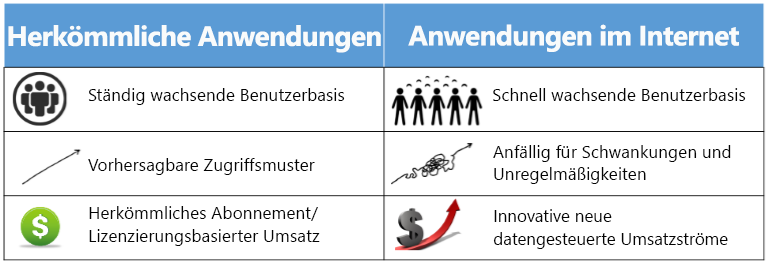
Abbildung 2: Vergleich herkömmlicher und internetskalierter Computer
Das 21. Jahrhundert ist durch eine Explosion des Volumens und der Kapazität der drahtlosen Kommunikation, des World Wide Web und des Internets gekennzeichnet. Diese Veränderungen haben zu einer netzwerkgesteuerten und datengesteuerten Gesellschaft geführt, in der das Produzieren, Verbreiten und Zugreifen auf digitalisierte Informationen vereinfacht wird. Es wird geschätzt, dass das Internet von 25 Millionen Nutzern im Jahr 1994 zu einem globalen Marktplatz von Milliarden von Nutzern gewachsen ist. 1 Dieser Anstieg der Daten und Verbindungen ist für Unternehmen wertvoll. Daten schaffen Werte auf verschiedene Arten, z. B. durch Aktivieren von Experimenten, Segmentieren von Populationen und Unterstützen der Entscheidungsfindung mit Automatisierung. 2 Durch die Einführung digitaler Technologien werden die weltweit führenden 10 Volkswirtschaften ihre Produktion bis 2020 um mehr als eine Billion Dollar erhöhen.
Die zunehmende Anzahl der durch das Internet ermöglichten Verbindungen hat auch seinen Wert gesteigert. Forscher haben hypothesiert, dass der Wert eines Netzwerks superlinear als Funktion der Anzahl der Benutzer variiert. So ist das Gewinnen und Aufbewahren von Kunden im Internet eine Priorität. Dazu werden zuverlässige und reaktionsfähige Dienste erstellt und Änderungen basierend auf beobachteten Datenmustern vorgenommen.
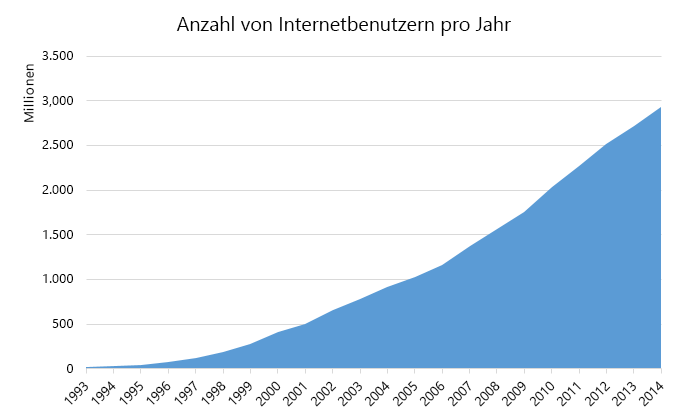
Abbildung 3: Erhöhung der Anzahl der Internetbenutzer pro Jahr
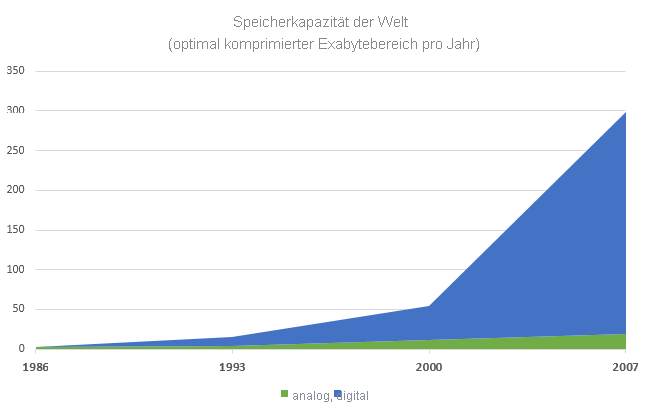
Abbildung 4: Zunehmende Menge an Daten, die pro Jahr gespeichert werden5
Einige Beispiele für Internet-Skalierungssysteme sind:
- Suchmaschinen , die große Datensätze (bis zu Petabyte) durchforsten, speichern, indexieren und durchsuchen. Google startete z. B. als riesiger Webindex, der alle paar Tage den Webdatenverkehr durchsuchte und analysierte und diese Indizes mit Schlüsselwörtern abglich. Jetzt aktualisiert es seine Indizes nahezu in Echtzeit und ist eine der beliebtesten Möglichkeiten, auf Informationen im Internet zuzugreifen. Ihr Index hat Billionen von Seiten mit einer Größe von Tausenden von Terabyte. 4
- Soziale Netzwerke wie Facebook und LinkedIn, die es Benutzern ermöglichen, persönliche und berufliche Beziehungen zu schaffen und Communitys basierend auf ähnlichen Interessen aufzubauen. Facebook unterstützt beispielsweise mehr als eine Milliarde aktive Nutzer pro Monat.
- Online-Einzelhandelsdienste wie Amazon, die einen globalen Bestand an Millionen von Produkten unterhalten, die an über 200 Millionen Kunden verkauft werden, mit Nettoumsatzvolumen von fast 90 Milliarden US-Dollar jährlich.
- Rich-Streaming-Multimediaanwendungen, mit denen Benutzer Videos und andere Formen von umfangreichen Inhalten ansehen und teilen können. Ein solches Beispiel: YouTube verarbeitet Uploads von 300 Minuten Video pro Sekunde.
- Echtzeitkommunikationssysteme für Audio-, Video- und Textchats wie Skype, die mehr als 50 Milliarden Minuten Anrufe pro Monat erhalten.
- Produktivitäts- und Zusammenarbeitssuiten , die Millionen von Dokumenten für viele gleichzeitige Benutzer bereitstellen und so Echtzeit-, persistente Updates ermöglichen. Beispielsweise behauptet Microsoft 365, 50 Millionen monatliche aktive Mitarbeiter zu unterstützen.
- CRM-Anwendungen von Anbietern wie Salesforce, die in über hunderttausend Organisationen bereitgestellt werden. Große CRMs bieten jetzt intuitive Dashboards zum Nachverfolgen von Status, Analysen, um die Kunden zu finden, die die meisten Unternehmen generieren, und Umsatzprognosen, um zukünftiges Wachstum vorherzusagen.
- Data Mining- und Business Intelligence-Anwendungen , die die Nutzung anderer Dienste (wie oben) analysieren, um Ineffizienzen und Möglichkeiten für die Monetarisierung zu finden.
Von diesen Systemen wird offensichtlich erwartet, dass sie mit einer hohen Anzahl von gleichzeitigen Benutzern zurechtkommen. Dies erfordert eine Infrastruktur mit der Kapazität, große Datenmengen zu verarbeiten, Daten zu generieren und Daten sicher zu speichern, und zwar alle ohne spürbare Verzögerungen. Diese Dienste erzielen ihren Wert, indem sie einen konstanten und zuverlässigen Qualitätsstandard bieten. Sie bieten auch umfangreiche Benutzeroberflächen für mobile Geräte und Webbrowser, die eine einfache Bedienung ermöglichen, aber schwieriger zu erstellen und zu warten sind.
Hier ist eine Zusammenfassung der Anforderungen von Internet-Skalierungssystemen:
- Ubiquity: Von überall aus, von einer Vielzahl von Geräten aus zugänglich. Ein Verkäufer erwartet z. B., dass sein CRM-Dienst zeitnahe Updates auf einem mobilen Gerät bereitstellt, um Kundenbesuche kürzer, schneller und effektiver zu gestalten. Der Dienst sollte unter einer Vielzahl von Netzwerkverbindungen reibungslos funktionieren.
- Hochverfügbarkeit: Der Dienst muss „immer betriebsbereit“ sein. Die Betriebszeiten werden durch die Anzahl der Neunen angegeben. Drei Neunen oder 99,9 % bedeuten, dass ein Dienst neun Stunden im Jahr nicht verfügbar sein wird. Fünf Neunen (ca. 6 Minuten pro Jahr) sind ein typischer Schwellenwert für einen Hochverfügbarkeitsdienst. Schon eine Ausfallzeit von wenigen Minuten in Anwendungen für den Onlineeinzelhandel kann sich beim Umsatz in Millionen von US-Dollar auswirken.
- Geringe Latenz: Schnelle und reaktionsfähige Zugriffszeiten. Selbst geringfügig langsamere Ladezeiten haben gezeigt, dass sie die Nutzung dieser Webseite deutlich verringern. Beispielsweise verringert die Erhöhung der Suchlatenz von 100 ms auf 400 ms die Anzahl der Suchvorgänge pro Benutzer von 0,8% auf 0,6%, und die Änderung bleibt auch dann erhalten, wenn die Latenz auf die ursprünglichen Ebenen reduziert wurde.
- Skalierbarkeit: Die Fähigkeit, eine variable Belastung, in der Regel aufgrund von Saisonalität und Viralität, zu bewältigen, was zu Spitzen und Trögen beim Datenverkehr sowohl in langen als auch in kurzen Zeiträumen führt. An Tagen wie "Black Friday" und "Cyber Monday" müssen Einzelhändler wie Amazon mehrmals den Netzwerkdatenverkehr verarbeiten als im Durchschnitt.
- Kosteneffizienz: Ein Internet-Skalierungsdienst erfordert viel mehr Infrastruktur als eine herkömmliche Anwendung sowie ein besseres Management. Eine Möglichkeit zum Optimieren der Kosten besteht darin, Dienste einfacher zu verwalten und die Anzahl der Administratoren, die einen Dienst verarbeiten, zu verringern. Kleinere Dienste können es sich leisten, ein niedriges Verhältnis von Dienst zu Administrator aufzuweisen (z. B. 2:1, wobei ein einzelner Administrator zwei Dienste verwalten muss). Um die Rentabilität aufrechtzuerhalten, müssen Dienste wie Microsoft Bing über ein hohes Dienst-zu-Administrator-Verhältnis verfügen (z. B. 2500:1, was bedeutet, dass ein einzelner Administrator 2.500 Dienste verwaltet). 6
- Interoperabilität: Viele dieser Dienste werden häufig zusammen verwendet und müssen daher eine einfache Schnittstelle für die Wiederverwendung bereitstellen und standardisierte Mechanismen zum Importieren und Exportieren von Daten unterstützen. Beispielsweise können viele andere Dienste (wie Uber) Google Maps in ihre Produkte integrieren, um benutzern vereinfachte Standort- und Navigationsinformationen bereitzustellen.
Wir werden nun einige der frühen Lösungen für die oben genannten Probleme untersuchen. 7 Die erste Herausforderung war die große Round-Trip-Zeit für frühe Webdienste, die sich hauptsächlich in den Vereinigten Staaten befanden. Die ersten Mechanismen zur Bewältigung der Probleme der geringen Latenzzeit (aufgrund von weit entfernten Servern) und des Serverausfalls basierten einfach auf Redundanz. Eine Technik zur Erreichung dieses Ziels war das "Spiegeln" von Inhalten, bei denen Kopien beliebter Webseiten an verschiedenen Orten auf der ganzen Welt gespeichert werden. Dadurch wurde die Last auf dem zentralen Server minimiert, die von Endbenutzern wahrgenommene Latenz verringert und der Datenverkehr bei Fehlern auf einen anderen Server umgestellt. Der Nachteil war eine Zunahme der Komplexität bei der Behandlung von Inkonsistenzen, wenn sogar eine Kopie der Daten geändert werden sollte. Daher ist dieses Verfahren eher für statische Workloads mit umfangreichen Lesevorgängen wie die Bereitstellung von Bildern, Videos oder Musik geeignet. Aufgrund der Effektivität dieser Technik verwenden die meisten Internetdienste Content Delivery Networks (CDNs), um verteilte globale Caches beliebter Inhalte zu speichern. Beispielsweise verwaltet Cable News Network (CNN) jetzt Replikate seiner Videos auf mehreren "Edge"-Servern an verschiedenen Standorten weltweit, mit personalisierter Werbung pro Standort.
Natürlich war es nicht immer sinnvoll, dass einzelne Unternehmen Dutzende von Servern auf der ganzen Welt kaufen. Kosteneffizienzen wurden häufig durch die Nutzung von gemeinsam genutzten Hostingdiensten gewonnen. Hier würden Freigaben eines einzelnen Webservers an mehrere Mandanten vermietet, wodurch sich die Kosten für die Serverwartung amortisieren. Gemeinsame Hostingdienste könnten sehr ressourceneffizient sein, da die Ressourcen aufgrund der Annahme überprovisioniert werden könnten, dass nicht alle Dienste gleichzeitig mit Spitzenkapazität arbeiten würden. (Ein überprovisionierter physischer Server ist eine, bei der die aggregierte Kapazität aller Mandanten größer als die tatsächliche Kapazität des Servers ist.) Der Nachteil war, dass es fast unmöglich war, die Dienste der Mandanten von denen ihrer Nachbarn zu isolieren. So könnte ein einzelner überlasteter oder fehleranfälliger Dienst alle seine Nachbarn negativ beeinflussen. Ein weiteres Problem ergab sich, da die Mandanten oft böswillig seien und versuchen könnten, ihren Vorteil der Zusammenlegung zu nutzen, um Daten zu stehlen oder anderen Benutzern den Dienst zu verweigern.
Um dies zu umgehen, wurden virtuelle private Server als Varianten des gemeinsam genutzten Hostingmodells entwickelt. Einem Mandanten würde eine virtuelle Maschine (VM) auf einem gemeinsam genutzten physischen Server zur Verfügung gestellt. (Wir sprechen später mehr über virtuelle Computer und deren Eigenschaften.) Diese virtuellen Computer wurden häufig statisch zugeordnet und mit einem einzigen physischen Computer verknüpft, daher waren sie schwierig zu skalieren und benötigten häufig manuelle Wiederherstellung von Fehlern. Obwohl sie nicht mehr überdimensioniert werden konnten, wiesen sie eine bessere Isolation der Leistung und Sicherheit zwischen den zusammengelegten Diensten als eine einfache Ressourcenfreigabe auf.
Ein weiteres Problem der gemeinsamen Nutzung öffentlicher Ressourcen war, dass die Speicherung privater Daten in der Infrastruktur von Drittanbietern erforderlich war. Einige der oben beschriebenen Internetdienste konnten nicht die Kontrolle über die Datenspeicherung verlieren, da jede Offenlegung der privaten Daten ihrer Kunden katastrophale Folgen hätte. Daher mussten diese Unternehmen ihre eigene globale Infrastruktur einrichten. Vor dem Aufkommen der öffentlichen Cloud konnten solche Dienste nur von großen Unternehmen wie Google und Amazon bereitgestellt werden. Jedes dieser Unternehmen würde große, homogene Rechenzentren auf der ganzen Welt mit Waren-Off-the-Shelf-Komponenten aufbauen, wo ein Rechenzentrum als ein einziger, massiver Lagercomputer (WSC) betrachtet werden könnte. Ein WSC bot eine einfache Abstraktion, um Anwendungen und Daten global zu verteilen und gleichzeitig das Besitzrecht zu behalten.
Aufgrund der Skalenvorteile könnte die Nutzung eines Rechenzentrums optimiert werden, um Kosten zu senken. Obwohl dies noch nicht so effizient war wie die öffentliche Freigabe von Ressourcen (die Cloud), hatten diese Lagercomputer viele wünschenswerte Eigenschaften, die als Grundlage für die Erstellung von Internet-Skalierungsdiensten dienten. Die Skalierung der Computinganwendungen entwickelte sich von der Betreuung einer festen Benutzerbasis hin zu einer dynamischen globalen Population. Standardisierte WSCs ermöglichten großen Unternehmen, derart große Zielgruppen zu versorgen. Eine ideale Infrastruktur würde die Leistung und Zuverlässigkeit eines WSC mit dem gemeinsam genutzten Hostingmodell kombinieren. Dies würde es sogar einem kleinen Unternehmen ermöglichen, eine global wettbewerbsfähige Anwendung zu entwickeln und zu starten, ohne den hohen Aufwand für die Erstellung großer Rechenzentren.
Ein weiterer Ansatz zum Teilen von Ressourcen war Grid Computing, das das Teilen autonomer Computersysteme über Institutionen und geografische Standorte hinweg ermöglichte. Mehrere akademische und wissenschaftliche Institutionen würden zusammenarbeiten und ihre Ressourcen auf ein gemeinsames Ziel bündeln. Jede Institution würde dann einer "virtuellen Organisation" beitreten, indem sie einen bestimmten Satz von Ressourcen durch gut definierte Freigaberegeln zur Verfügung stellt. Ressourcen sind oft heterogen und lose gekoppelt, sodass komplexe Programmierkonstrukte zusammengefügt werden müssen. Raster wurden auf die Unterstützung von nicht kommerziellen Forschungs- und akademischen Projekten ausgerichtet, und sie stützten sich auf bestehende Open-Source-Technologien.
Die Cloud war ein logischer Nachfolger, der viele der Features der oben genannten Lösungen kombinierte. Anstelle dass Universitäten den Zugriff auf einen Pool von Ressourcen über ein Grid teilen und nutzen, erlaubt die Cloud ihnen, eine von einem Clouddienstanbieter (Cloud Service Provider, CSP) zentral verwaltete Recheninfrastruktur anzumieten. Da der zentrale Anbieter einen großen Ressourcenpool verwaltet hat, um alle Clients zu erfüllen, erleichterte die Cloud die dynamische Skalierung der Nachfrage nach oben und unten innerhalb kurzer Zeit. Anstatt offene Standards wie das Raster zu verwenden, basiert Cloud Computing jedoch auf proprietären Protokollen und benötigt den Benutzer, eine bestimmte Vertrauensebene in den CSP zu setzen.
Später in diesem Modul behandeln wir, wie sich die Cloud entwickelt hat, um das Computing zu einem öffentlichen Dienstprogramm zu machen, das getaktet und verwendet werden kann.
Verweise
- Echtzeitstatistikprojekt (2015). Internet Live Stats
- IBM (2017). Was ist Big Data?
- Google Inc. (2015). Funktionsweise der Suche
- Hilbert, Martin und Lopez, Priscila (2011). Die technologische Kapazität der Welt zum Speichern, Kommunizieren und Berechnen von Informationen
- Hamilton, James R und andere (2007). Entwerfen und Bereitstellen von Internet-Scale-Diensten
- Brewer, Eric und andere (2001). Lehren aus riesigen Dienstleistungen