Verwenden der Sprach-zu-Text-API
Tipp
Weitere Details finden Sie auf der Registerkarte "Text und Bilder ".
Azure Speech in Foundry Tools unterstützt die Spracherkennung über die Sprach-zu-Text-API. Die spezifischen Details variieren je nach verwendeter SDK (Python, C# usw.). Es gibt ein konsistentes Muster für das Verwenden der Sprache-in-Text-API:
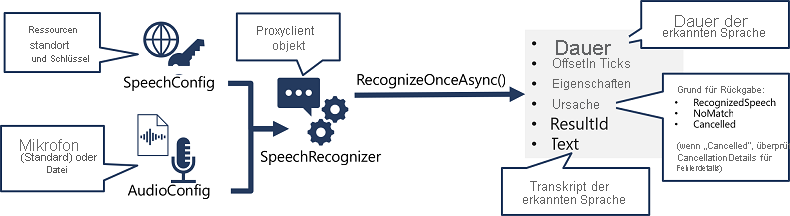
- Verwenden Sie ein SpeechConfig-Objekt , um die informationen zu kapseln, die zum Herstellen einer Verbindung mit Ihrer Foundry-Ressource erforderlich sind. Insbesondere der Endpunkt (oder die Region) und der Schlüssel.
- Verwenden Sie optional ein AudioConfig-Objekt, um die Eingabequelle für die zu transkribierenden Audioinformationen zu definieren. Standardmäßig ist dies das Standardsystemmikrofon, aber Sie können auch eine Audiodatei angeben.
- Verwenden Sie SpeechConfig und AudioConfig , um ein SpeechRecognizer-Objekt zu erstellen. Dieses Objekt ist ein Proxyclient für die Sprach-zu-Text-API .
- Verwenden Sie die Methoden des SpeechRecognizer-Objekts , um die zugrunde liegenden API-Funktionen aufzurufen. Beispielsweise verwendet die RecognizeOnceAsync() -Methode den Azure-Sprachdienst, um asynchron eine einzelne gesprochene Äußerung zu transkribieren.
- Verarbeiten sie die Antwort. Bei der RecognizeOnceAsync() -Methode ist das Ergebnis ein SpeechRecognitionResult-Objekt , das die folgenden Eigenschaften enthält:
- Dauer
- OffsetInTicks
- Eigenschaften
- Ursache
- Ergebnis-ID
- Text
Wenn der Vorgang erfolgreich war, weist die Reason-Eigenschaft den Enumerationswert "RecognizedSpeech" auf, und die Text-Eigenschaft enthält die Transkription. Andere mögliche Werte für Ergebnis sind NoMatch (die Audioinhalte wurden erfolgreich geparst, aber es wurde keine Sprache erkannt) oder Abgebrochen. Letzteres bedeutet, dass ein Fehler aufgetreten ist (in diesem Fall können Sie in der Sammlung Eigenschaften nach der Eigenschaft CancellationReason suchen, um festzustellen, was nicht funktioniert hat).
Beispiel: Transkribieren einer Audiodatei
Im folgenden Python-Beispiel wird Azure Speech in Foundry Tools verwendet, um die Sprache in einer Audiodatei zu transkribieren.
import azure.cognitiveservices.speech as speech_sdk
# Speech config encapsulates the connection to the resource
speech_config = speech_sdk.SpeechConfig(subscription="YOUR_FOUNDRY_KEY",
endpoint="YOUR_FOUNDRY_ENDPOINT")
# Audio config determines the audio stream source (defaults to system mic)
file_path = "audio.wav"
audio_config = speech_sdk.audio.AudioConfig(filename=file_path)
# Use a speech recognizer to transcribe the audio
speech_recognizer = speech_sdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
result = speech_recognizer.recognize_once_async().get()
# Did it succeeed
if result.reason == speech_sdk.ResultReason.RecognizedSpeech:
# Yes!
print(f"Transcription:\n{result.text}")
else:
# No. Try to determine why.
print("Error transcribing message: {}".format(result.reason))