Design-Sternschema für semantische Modelle
Sie haben ausgewählt, wie Daten in Ihr semantisches Modell fließen. Entwerfen Sie nun das Sternschema, das für übersichtliche und leistungsfähige Abfragen sorgt. Ein Sternschema verbindet Faktentabellen durch Beziehungen mit Dimensionstabellen, wodurch die Filterpfade erstellt werden, von denen Berichte und KI-Verbrauch abhängen. Wenn Sie mit dem Erstellen des Sternschemas in Power BI Desktop vertraut sind, konzentriert sich diese Einheit auf die Entscheidungen des Beziehungsentwurfs, die wichtig sind, wenn Modelle in Komplexität und Skalierung wachsen.
Sternschema in einem semantischen Modell
In einem Sternschema speichern Faktentabellen messbare Geschäftsereignisse (z. B. Verkaufstransaktionen, Auftragspositionen und Webbesuche), und Dimensionstabellen stellen den beschreibenden Kontext bereit (z. B. Produktdetails, Kundeninformationen und Datumsattribute). Dimensionstabellen filtern Faktentabellen durch Beziehungen, wodurch Benutzer Metriken nach einem beliebigen beschreibenden Attribut segmentieren können.
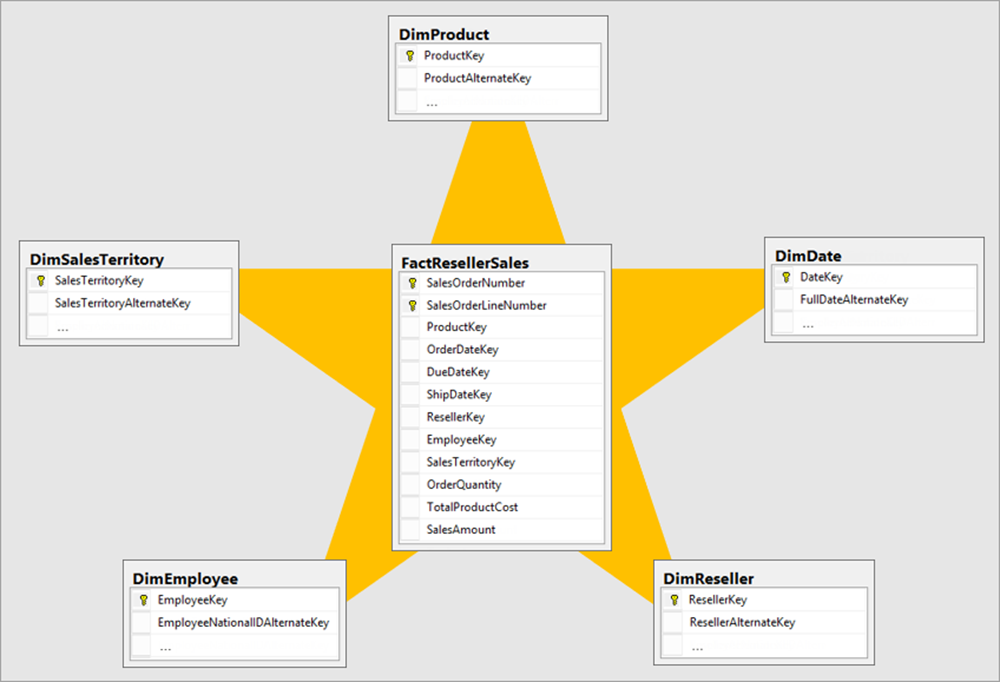
In einem semantischen Fabric-Modell bietet dieses Muster eine saubere Filterweiterleitung sowohl für Berichte als auch für die KI-Nutzung. Wenn Copilot oder ein Daten-Agent eine Natürliche Sprachabfrage generiert, gibt ein gut organisiertes Sternschema den KI klare Pfade zu den richtigen Daten. Mehrdeutige oder zirkuläre Beziehungen verwirren sowohl Berichtsnutzer als auch KI-Tools.
Auswirkungen des Speichermodus auf Beziehungen
Beziehungen in einem semantischen Modell verhalten sich je nach Speichermodus unterschiedlich. Das Verständnis dieser Unterschiede ist für das Entwerfen des Sternschemas unerlässlich, das in verschiedenen Szenarien gut funktioniert.
Direct Lake-Beziehungen
Im Direct Lake-Modus liest das Modul Beziehungen direkt aus den Delta-Tabellenmetadaten vor. Beziehungen funktionieren am besten, wenn:
- Die Schlüsselspalten der Dimensionen haben eine geringe Kardinalität im Vergleich zu den Zeilen der Faktentabelle.
- Referenzielle Integrität wird in den Quelldaten beibehalten. Wenn referenzielle Integrität gegeben ist, verwendet die Engine INNER Joins anstelle von LEFT OUTER Joins, wodurch die Abfrageleistung verbessert wird.
- Spalten, die in Beziehungen verwendet werden, werden in den zugrunde liegenden Delta-Tabellen indiziert.
Hinweis
Wenn eine Abfrage eine Beziehung umfasst, die dazu führt, dass das Modell Speicherlimits überschreitet oder nicht unterstützte Vorgänge verwendet, greift Direct Lake auf DirectQuery zurück, und das Beziehungsverhalten ändert sich an die DirectQuery-Semantik.
Quellübergreifende Beziehungen
Fabric semantischen Modelle können Tabellen aus verschiedenen Datenspeichern verbinden. Eine Faktentabelle aus einem Seehaus kann eine Beziehung zu einer Dimensionstabelle aus einem Lagerhaus oder zu einer Tabelle haben, auf die über einen SQL-Analyseendpunkt zugegriffen wird. Diese quellübergreifenden Verbindungen verwenden zusammengesetzte Modellfunktionen.
Wenn Tabellen aus verschiedenen Quellen stammen, bestimmt der Speichermodus für jede Tabelle, wie die Beziehung zur Abfragezeit funktioniert. Das Modul löst jede Seite unabhängig voneinander auf und verknüpft die Ergebnisse.
Beziehungstypen
Eins-zu-viele-Beziehungen
Die häufigste Beziehungsart in einem Sternschema ist n:m. Ein eindeutiger Wert in einer Dimensionstabelle bezieht sich auf viele Zeilen in einer Faktentabelle. Eine Produktzeile in der Dimension "Produkt" entspricht beispielsweise Tausenden von Bestellzeilen in der Tabelle "Sales fact".
Konfigurieren Sie One-to-Many-Beziehungen, wobei die Filterrichtung von der Dimension (der „einen“ Seite) zur Faktentabelle (der „vielen“ Seite) fließt. Dies ist das standardmäßige Sternschemafiltermuster.
Viele-zu-viele-Beziehungen
Viele-zu-viele-Beziehungen sind erforderlich, wenn keine der Tabellen eindeutige Werte für die Beziehungsspalte aufweist. Verwenden Sie eine Brückentabelle, um diese Beziehungen aufzulösen. Eine Brückentabelle befindet sich zwischen zwei Tabellen und enthält eindeutige Kombinationen der Schlüssel beider Seiten.
Wenn ein Kunde beispielsweise mehrere Konten haben kann und ein Konto mehreren Kunden angehören kann, löst eine Customer-Account Bridge-Tabelle die Beziehung auf. Die Brückentabelle verfügt über One-to-Many-Beziehungen zu den Tabellen Customer und Account.
Filterrichtung
Verwenden Sie in den meisten Star-Schema-Implementierungen die unidirektionale Filterung von Dimensionen zu Fakten. Dies bietet vorhersehbare Filterverteilung und vermeidet Mehrdeutigkeit in Abfrageergebnissen.
Bidirektionaler Filterungsmechanismus ist manchmal für viele-zu-viele-Beziehungen notwendig oder wenn Dimensionstabellen nach Werten in der Faktentabelle gefiltert werden müssen. Verwenden Sie bidirektionale Filter sparsam, da sie die Abfrageleistung beeinträchtigen und unerwartetes Filterverhalten in Berichten erstellen können.
Referentielle Integrität
Die Einstellung " Referenzielle Integrität annehmen " weist das Modul an, BEIM Abfragen über eine Beziehung INNER-Verknüpfungen anstelle von LEFT OUTER-Verknüpfungen zu verwenden. In direct Lake- und DirectQuery-Modi kann diese Einstellung die Leistung erheblich verbessern, da dadurch die Anzahl der Zeilen reduziert wird, die das Modul verarbeitet.
Aktivieren Sie diese Einstellung, wenn Sie sicher sind, dass jeder Fremdschlüsselwert in der Faktentabelle einen übereinstimmenden Wert in der Dimensionstabelle aufweist. Wenn die referenzielle Integrität verletzt wird, verschwinden Zeilen mit nicht übereinstimmenden Schlüsseln stillschweigend aus den Abfrageergebnissen.
Inaktive Beziehungen und USERELATIONSHIP
Es kann jeweils nur eine aktive Beziehung zwischen zwei Tabellen vorhanden sein. Wenn Sie mehrere Beziehungspfade benötigen (z. B. ein Bestelldatum und ein Lieferdatum, die beide mit derselben Datumsdimension zusammenhängen), machen Sie eine Beziehung aktiv und die anderen inaktiv.
Verwenden Sie die USERELATIONSHIP Funktion in DAX, um eine inaktive Beziehung innerhalb einer Berechnung zu aktivieren:
Shipped Amount =
CALCULATE(
SUM(Sales[Amount]),
USERELATIONSHIP(Sales[ShipDate], 'Date'[Date])
)
Dieses Muster sorgt dafür, dass das Modell sauber bleibt und gleichzeitig mehrere analytische Perspektiven für dieselben Daten unterstützt werden.
Umgang mit dem Schneeflakeschema in semantischen Modellen
Quelldaten kommen häufig in einem normalisierten Schneeflockenschema ein, bei dem Dimensionstabellen in mehrere verknüpfte Tabellen aufgeteilt werden. Beispielsweise kann eine Produktdimension in Die Tabellen "Produkt", "Unterkategorie" und "Kategorie" unterteilt werden, die jeweils über Fremdschlüssel verknüpft sind.
In einem semantischen Modell haben Sie zwei Optionen: das Schneeflockenmodell in ein Sternschema umwandeln oder die normalisierte Struktur beibehalten.
Verflachung in Sternschema
Das Flachlegen bedeutet, dass die normalisierten Dimensionstabellen in einer einzigen denormalisierten Dimensionstabelle kombiniert werden. Die Tabelle "Produkt" enthält Spalten "Unterkategorie" und "Kategorie" direkt, wodurch die zusätzlichen Tabellen und Beziehungen wegfallen.
Abflachen bei:
- Die kombinierte Bemaßungstabelle ist relativ zur Faktentabelle immer noch klein (was fast immer bei Dimensionen der Fall ist).
- Sie möchten einfachere Filterpfade von Dimension zu Fakten. Jeder Filter durchläuft eine Beziehung anstelle einer Kette.
- Der KI-Verbrauch ist eine Priorität. Weniger Tabellen und einfachere Beziehungen geben Copilot und Daten-Agents klarere Pfade zu den richtigen Daten.
Verflachen Sie Dimensionstabellen während der Datenvorbereitung in Lakehouses oder Datenflows, bevor die Daten das semantische Modell erreichen. Verwenden Sie Power Query Zusammenführungen, SQL-Verknüpfungen oder Notizbuchtransformationen, um die normalisierten Tabellen in einer einzigen Dimension zu kombinieren.
Bewahren Sie die Schneeflakestruktur auf
In einigen Fällen ist es sinnvoll, die normalisierte Struktur beizubehalten:
- Die Dimensionshierarchie hat mehrere Ebenen, und die Abflachung würde Dutzende redundanter Spalten erstellen.
- Mehrere Faktentabellen teilen sich Subdimensionstabellen (wie z. B. eine gemeinsame Kategorietabelle, die sowohl von Verkaufs- als auch von Bestandsfakten verwendet wird), sodass eine Denormalisierung inkonsistente Kopien erstellen würde.
- Die Sicherheit auf Zeilenebene muss auf einer bestimmten Ebene in der Hierarchie angewendet werden.
Wenn Sie eine Schneeflockenstruktur beibehalten, konfigurieren Sie die Beziehungen sorgfältig. Jede Beziehung in der Beziehungskette muss eindirektionale Filterung von der äußersten Tabelle zur Faktentabelle verwenden, damit Filter ordnungsgemäß verteilt werden. Ein Filter nach "Kategorie" muss über "Unterkategorie" und dann über "Produkt" und in die Faktentabelle fließen.
Hinweis
In den meisten Semantikmodellszenarien ist das Abflachen von Dimensionen zu einem Sternschema die bessere Wahl. Weniger Tabellen bedeuten weniger Beziehungen, einfachere DAX-Daten, schnellere Abfragen und eine bessere KI-Auslastung. Bewahren Sie die Schneeflakestruktur nur dann bei, wenn es einen starken Grund gibt, sie beizubehalten.
Wann zusammengesetzte Modelle für quellübergreifende Szenarien verwendet werden sollten
Verwenden Sie zusammengesetzte Modelle, wenn ihr Sternschema mehrere Fabric Datenspeicher umfasst oder externe Quellen enthält. Zu den gängigen Szenarien gehören:
- Faktentabellen in einem Lakehouse mit Dimensionstabellen, die in einem Warehouse verwaltet werden.
- Echtzeitstreaming von Daten aus einem Eventhouse in Kombination mit historischen Daten in einem Seehaus.
- Importieren Sie Referenzdaten aus einer externen Quelle und kombinieren Sie sie mit Fabric-nativen Faktentabellen (Direct Lake).
Konfigurieren Sie in jedem dieser Szenarien den Speichermodus für jede Tabelle unabhängig und überprüfen Sie, ob quellübergreifende Beziehungen bei Ihren erwarteten Datenmengen akzeptabel arbeiten.