Bereitstellen eines multimodalen Modells
Um Eingabeaufforderungen zu verarbeiten, die Bilder enthalten, müssen Sie ein multimodales generatives KI-Modell bereitstellen– d. h. ein Modell, das nicht nur textbasierte Eingaben unterstützt, sondern auch bildbasierte (und in einigen Fällen auch audiobasierte) Eingaben unterstützt. Zu den in Microsoft Foundry verfügbaren multimodalen Modellen gehören unter anderem:
- Microsoft Phi-4-multimodal-instruct
- OpenAI gpt-4o
- OpenAI gpt-4o-mini
Tipp
Weitere Informationen zu verfügbaren Modellen in Microsoft Foundry finden Sie im Artikel zum Modellkatalog und zu Sammlungen im Microsoft Foundry-Portal in der Microsoft Foundry-Dokumentation.
Testen von multimodalen Modellen mit bildbasierten Eingabeaufforderungen
Nach der Bereitstellung eines multimodalen Modells können Sie es im Chat-Playground im Microsoft Foundry-Portal testen.
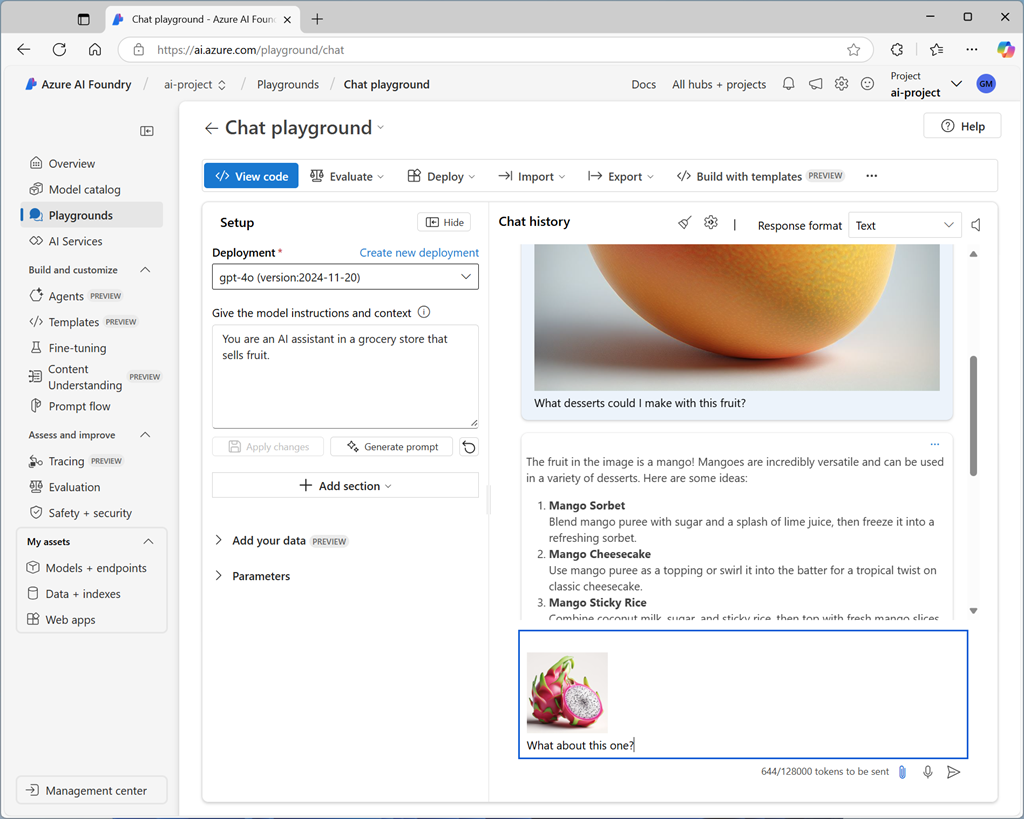
Im Chat-Playground können Sie ein Bild aus einer lokalen Datei hochladen und der Nachricht Text hinzufügen, um eine Antwort von einem multimodalen Modell zu erregen.