Untersuchen der analytischen Datenverarbeitung
Bei der analytischen Datenverarbeitung werden in der Regel schreibgeschützte (oder hauptsächlich schreibgeschützte) Systeme verwendet, die große Mengen an Verlaufsdaten oder Geschäftsmetriken speichern. Analysen können auf einer Momentaufnahme der Daten zu einem bestimmten Zeitpunkt oder auf einer Reihe von Momentaufnahmen basieren.
Die spezifischen Details für ein analytisches Verarbeitungssystem können je nach Lösung variieren, aber eine allgemeine Architektur für Analysen auf Unternehmensniveau sieht wie folgt aus:
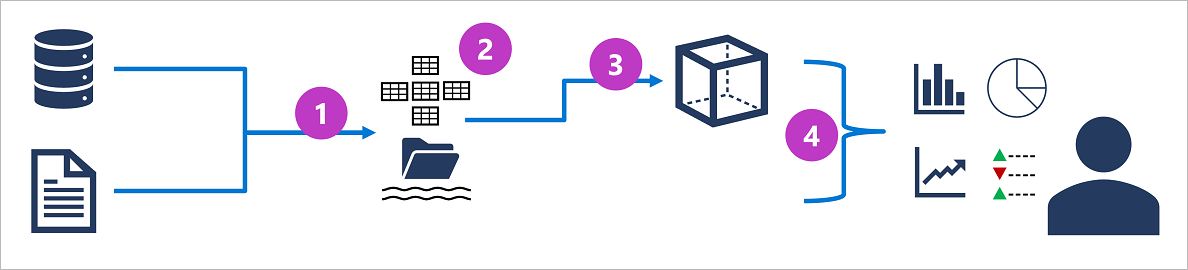
- Operative Daten werden extrahiert, transformiert und in einen Data Lake zur Analyse geladen (ETL).
- Daten werden in ein Schema von Tabellen geladen. In der Regel in einem Spark-basierten Data Lakehouse mit tabellarischen Abstraktionen über Dateien im Data Lake oder in einem Data Warehouse mit einem vollständig relationalen SQL-Modul.
- Daten im Data Warehouse können aggregiert und in ein OLAP-Modell (Online Analytical Processing, analytische Onlineverarbeitung) oder einen OLAP-Cube geladen werden. Aggregierte numerische Werte (Measures) aus Faktentabellen werden für Schnittmengen von Dimensionen aus Dimensionstabellen berechnet. Beispielsweise kann sich der Umsatz nach Datum, Kunde und Produkt zusammenrechnen.
- Die Daten im Data Lake, Data Warehouse und Analysemodell können abgefragt werden, um Berichte, Visualisierungen und Dashboards zu erstellen.
Data Lakes werden häufig in groß angelegten Datenanalyse-Szenarien eingesetzt, in denen eine große Menge an dateibasierten Daten gesammelt und analysiert werden muss.
Data Warehouses sind eine bewährte Methode zum Speichern von Daten in einem relationalen Schema, das für Lesevorgänge optimiert ist, also in erster Linie Abfragen zur Unterstützung der Berichterstellung und Datenvisualisierung. Data Lakehouses sind eine neuere Innovation, welche die flexible und skalierbare Speicherung eines Data Lake mit der relationalen Abfragesemantik eines Data Warehouses kombiniert. Das Data Warehouse-Schema erfordert möglicherweise eine gewisse Denormalisierung von Daten in einer OLTP-Datenquelle (dies führt zu Duplikaten, damit Abfragen schneller ausgeführt werden).
Ein OLAP-Modell ist ein aggregierter Datenspeicherungstyp, der für analytische Workloads optimiert ist. Datenaggregationen sind dimensionsübergreifend auf verschiedenen Ebenen, sodass Sie einen Drillup bzw. Drilldown für die Ansicht von Aggregationen auf mehreren hierarchischen Ebenen durchführen können, um zum Beispiel den Gesamtumsatz nach Region, Stadt oder für eine einzelne Adresse zu suchen. Da OLAP-Daten vorab aggregiert werden, können Abfragen zum Zurückgeben der in ihnen enthaltenen Zusammenfassungen schnell ausgeführt werden.
Verschiedene Benutzertypen können Datenanalysen auf verschiedenen Stufen der Gesamtarchitektur ausführen. Beispiel:
- Wissenschaftliche Fachkräfte für Daten arbeiten möglicherweise direkt mit Datendateien in einem Data Lake, um Daten zu untersuchen und zu modellieren.
- Data Analysts fragen Tabellen möglicherweise direkt im Data Warehouse ab, um komplexe Berichte und Visualisierungen zu erstellen.
- Geschäftsbenutzer*innen können vorab aggregierte Daten in einem Analysemodell in Form von Berichten oder Dashboards nutzen.