Grundlegendes zu den verfügbaren Datenverschiebungstools
Der REST-Endpunkt ist eine nützliche Ressource zum Importieren von Daten in Azure SQL-Datenbank. Andere Tools für die Datenverschiebung umfassen jedoch Azure Data Factory (ADF),Massenkopieprogramm (BCP), SQL Server-Import- und Export-Assistent sowie Skripts in Azure CLI und PowerShell. Diese Tools bieten verschiedene Optionen für die Datenverschiebung, die jeweils für unterschiedliche Szenarien geeignet sind.
In dieser Lerneinheit sehen wir uns Schritt-für-Schritt-Beispiele für einige dieser Tools an, andere hingegen werden im Detail erläutert.
Verwenden der SQL-Datensynchronisierung zum Synchronisieren von Daten
DIE SQL-Datensynchronisierung ist ein Feature in der Azure SQL-Datenbank, mit dem Sie Daten über mehrere Datenbanken hinweg synchronisieren können, sowohl in der Cloud als auch lokal. Diese Funktion ist unerlässlich, um die Datenkonsistenz aufrechtzuerhalten und Hybrid Cloud-Szenarien zu ermöglichen. Die SQL-Datensynchronisierung ist ein Dienst, der auf Azure SQL-Datenbank basiert und mit dem Sie ausgewählte Daten bidirektional über mehrere Datenbanken hinweg synchronisieren können. Er nutzt eine Hub-Spoke-Topologie, in der eine Datenbank als Hub fungiert und andere als Mitglieder fungieren. Die Hubdatenbank muss eine Azure SQL-Datenbank-Instanz sein, während Mitgliedsdatenbanken entweder Azure SQL-Datenbanken oder SQL Server-Datenbanken sein können.
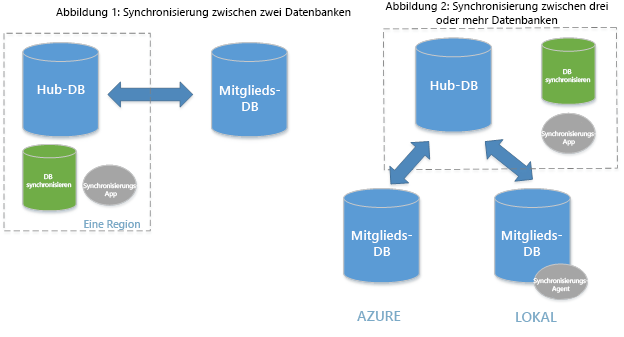
Einrichten der SQL-Datensynchronisierung
Erstellen einer Synchronisierungsgruppe: Um die Datensynchronisierung einzurichten, melden Sie sich beim Azure-Portal an, und navigieren Sie zu Ihrer Azure SQL-Datenbank. Wählen Sie im Abschnitt "Datenverwaltung " die Option "Mit anderen Datenbanken synchronisieren" aus. Wählen Sie dann "Neue Synchronisierungsgruppe " aus, und konfigurieren Sie die Synchronisierungsgruppeneinstellungen, einschließlich des Namen der Synchronisierungsgruppe und der Synchronisierungsmetadatendatenbank.
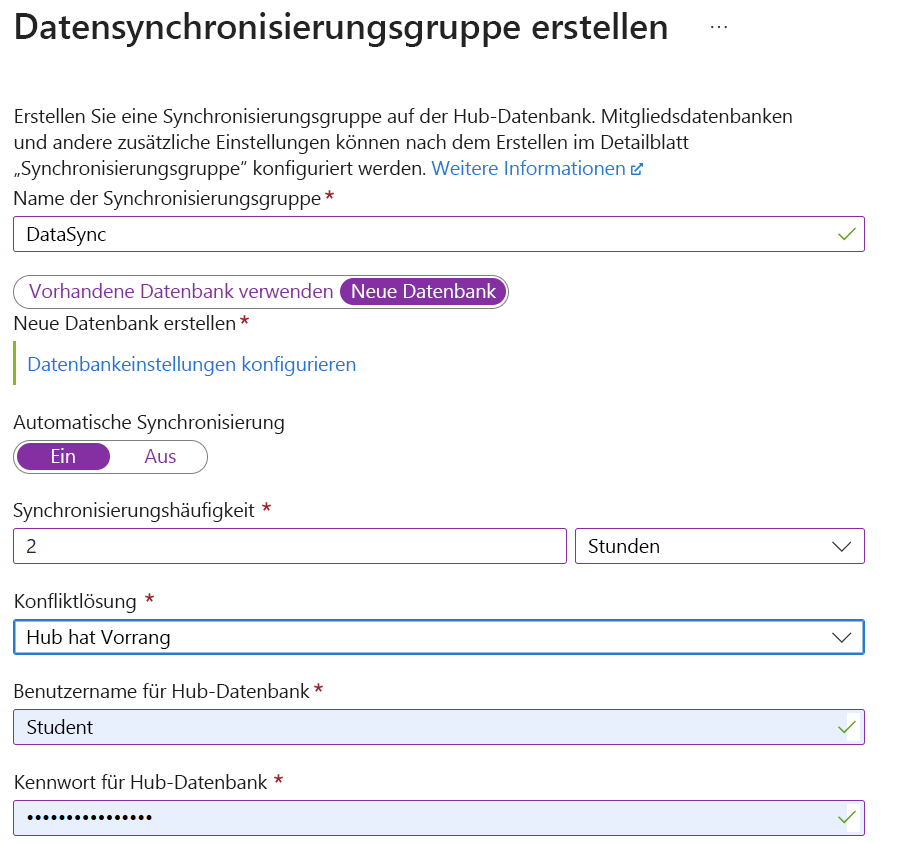
Hinzufügen von Synchronisierungsmitgliedern: Um die Datenbanken hinzuzufügen, die Sie synchronisieren möchten, können Sie andere Azure SQL-Datenbanken oder lokale SQL Server-Datenbanken einschließen. Für lokale Datenbanken müssen Sie einen lokalen Synchronisierungs-Agent installieren und konfigurieren.
Synchronisierungseinstellungen konfigurieren: Um das Synchronisierungsschema zu definieren, geben Sie die zu synchronisierenden Tabellen und Spalten an. Legen Sie die Synchronisierungsrichtung (bidirektional, Hub zu Mitglied, Mitglied zu Hub) und die Synchronisierungshäufigkeit fest. Wählen Sie schließlich eine Konfliktlösungsrichtlinie („Hub gewinnt“ oder „Mitglied gewinnt“) aus, um Datenkonflikte zu behandeln.
Überwachen und Verwalten der Synchronisierung: Verwenden Sie das Azure-Portal, um den Synchronisierungsstatus und die Protokolle zu überwachen. Überprüfen Sie, ob Synchronisierungsfehler auftreten, und beheben Sie sie bei Bedarf.
Bearbeiten von Daten in Azure SQL-Datenbank mithilfe von Azure Data Factory
Azure Data Factory (ADF) ist ein vollständig verwalteter, cloudbasierter Datenintegrationsdienst, mit dem Sie datengesteuerte Workflows zum Orchestrieren und Automatisieren von Datenbewegungen und Datentransformationen erstellen können. Er unterstützt eine Vielzahl von Datenquellen und -zielen und komplexe Hybridprozesse für ETL (Extrahieren, Transformieren und Laden) und ELT (Extrahieren, Laden und Transformieren) und ist damit ein vielseitiges Tool für Datenintegrationsaufgaben.
Mit ADF können Sie Ihre eigenen Prozess zur Datenorchestrierung und -integration entwerfen.
Erstellen einer Data Factory-Ressource: Dies ist die Ressource, die alle Datenintegrations- und Transformationsaktivitäten kapselt.
- Navigieren Sie im Azure-Portal zu "Ressource erstellen " und suchen Sie nach "Datenfabriken".
- Geben Sie die erforderlichen Details wie Abonnement, Ressourcengruppe und Region ein, und wählen Sie dann "Erstellen" aus.
Erstellen verknüpfter Dienste: Verknüpfte Dienste werden verwendet, um die Verbindungsinformationen für Datenquellen und Ziele zu definieren.
- Wählen Sie in Azure Data Factory "Verwalten" und dann "Verknüpfte Dienste" aus.
- Erstellen Sie einen neuen verknüpften Dienst für Ihre Azure SQL-Datenbank-Instanz, indem Sie die erforderlichen Verbindungsdetails angeben.
Erstellen von Datasets: Datasets stellen die Datenstrukturen innerhalb der Datenspeicher dar, die die Aktivitäten in einer Pipeline verwenden.
- Wechseln Sie in Azure Data Factory zur Registerkarte " Autor ".
- Wählen Sie + (Plus) aus, und wählen Sie Datensatz aus.
- Wählen Sie den Datenspeichertyp (z. B. Azure SQL-Datenbank, Azure Blob Storage) aus. Geben Sie außerdem die erforderlichen Verbindungsdetails und Dataseteigenschaften an.
Erstellen einer Pipeline: Pipelines sind logische Gruppierungen von Aktivitäten, die eine Arbeitseinheit ausführen.
- Wählen Sie in Azure Data Factory "Autor" aus, und erstellen Sie eine neue Pipeline.
- Fügen Sie der Pipeline eine Kopierdatenaktivität hinzu, um Daten aus dem Quelldatensatz in das Ziel-Dataset zu kopieren.
Führen Sie die Pipeline aus: Wenn Sie die Pipeline ausführen, werden die von Ihnen konfigurierten Aktivitäten ausgeführt.
- Lösen Sie die Pipeline aus, um den Prozess zum Kopieren von Daten zu starten.
- Überwachen Sie die Pipelineausführung, um sicherzustellen, dass die Daten erfolgreich importiert werden.
Importieren und Exportieren von Daten mithilfe einer BACPAC-Datei
Eine BACPAC-Datei ist im Wesentlichen eine ZIP-Datei mit der Erweiterung ".bacpac", die das Datenbankschema und die Daten enthält. Sie wird für die Datenbankmigration, Sicherung und Archivierung verwendet. Sie können eine Datenbank in eine BACPAC-Datei exportieren und in Azure Blob Storage oder lokal speichern und später wieder in Azure SQL-Datenbank, Azure SQL Managed Instance oder SQL Server importieren. Außerdem können Sie BACPAC-Dateien verwenden, um nur eine Teilmenge der Daten zu importieren. Diese Flexibilität ermöglicht es Ihnen, die Datenverschiebung genauer anzupassen.
Sie können Daten mit BACPAC-Dateien über das Azure-Portal und SQL Server Management Studio (SSMS) importieren und exportieren, aber sie können auch das SQLPackage-Hilfsprogramm verwenden.
Führen Sie den folgenden Beispielbefehl aus, um Daten mithilfe von SQLPackage in eine BACPAC-Datei zu importieren. Ersetzen Sie <ServerName>, <DatabaseName>, <UserName>, <Password> und <PathToBacpacFile> in den folgenden Skripts durch den tatsächlichen Servernamen, den Datenbanknamen, die Benutzeranmeldeinformationen und den Pfad für die BACPAC-Datei.
sqlpackage.exe /Action:Import /tsn:<ServerName> /tdn:<DatabaseName> /tu:<UserName> /tp:<Password> /sf:<PathToBacpacFile>
Führen Sie den folgenden Beispielbefehl aus, um Daten mithilfe von SQLPackage in eine BACPAC-Datei zu exportieren.
sqlpackage.exe /Action:Export /ssn:<ServerName> /sdn:<DatabaseName> /su:<UserName> /sp:<Password> /tf:<PathToBacpacFile>
Verwenden des Massenkopierprogramms (Bulk Copy Program, BCP)
Das BCP-Hilfsprogramm ist ein Befehlszeilentool, mit dem Tabellen in Dateien exportiert werden, damit Sie sie importieren können. Verwenden Sie diesen Ansatz für die Migration zwischen einer einzelnen SQL-Datenbank und SQL Managed Instance.
Verwenden des SQL Server-Import/Export-Assistenten
Der SQL Server-Import/Export-Assistent ist ein grafisches Tool in SSMS zum Importieren und Exportieren von Daten zwischen SQL Server und vielen Datenquellen. Ein Vorteil des SQL Server-Import/Export-Assistenten besteht darin, dass er SQL Server Integration Services (SSIS) zum Kopieren von Daten verwendet. SSIS ist ein hochgradig konfigurierbares Tool zum Erstellen von ETL-Prozessen (Extrahieren, Transformieren und Laden), die sowohl in SQL Server- als auch in Azure SQL-Datenbank-Instanzen ausgeführt werden können.
Verwenden der Azure CLI und von PowerShell
Sie können Skripts in der Azure CLI und in PowerShell verwenden, um Import- und Exportprozesse zu automatisieren. Die Verwendung von Skripts für den Import oder Export eignet sich für die Integration in CI/CD-Pipelines. Im Vergleich zu anderen Methoden müssen die einzelnen Skripts jedoch stärker angepasst werden.
Weitere Informationen zu anderen Tools zum Exportieren und Importieren von Daten finden Sie unter Importieren und Exportieren von Daten aus SQL Server und Azure SQL-Datenbank.