Grundlegendes zur Batch- und Streamverarbeitung
Datenverarbeitung bedeutet, dass Rohdaten durch einen Prozess in sinnvolle Informationen konvertiert werden. Es gibt zwei allgemeine Ansätze zum Verarbeiten von Daten:
- Die Batchverarbeitung, bei der mehrere Datensätze erfasst und gespeichert werden, bevor sie in einem einzigen Vorgang gemeinsam verarbeitet werden
- Die Streamverarbeitung, bei der eine Datenquelle fortlaufend überwacht und in Echtzeit verarbeitet wird, sobald neue Datenereignisse auftreten.
Grundlegendes zur Batchverarbeitung
Bei der Batchverarbeitung werden neu eintreffende Datenelemente gesammelt und gespeichert, und die gesamte Gruppe wird zusammen im Batch verarbeitet. Der Verarbeitungszeitpunkt jeder Gruppe kann auf verschiedene Weise festgelegt werden. Sie können Daten beispielsweise in geplanten Zeitintervallen (z. B. stündlich) verarbeiten, oder die Verarbeitung kann ausgelöst werden, wenn eine bestimmte Datenmenge eingetroffen oder ein anderes Ereignis eingetreten ist.
Nehmen Sie an, dass Sie den Straßenverkehr analysieren möchten, indem Sie die Anzahl der Autos auf einem Straßenabschnitt zählen. Wenn Sie die Batchverarbeitung als Ansatz wählen, müssen Sie die Autos auf einem Parkplatz sammeln und sie dann im geparkten Zustand in einem einzigen Vorgang zählen.
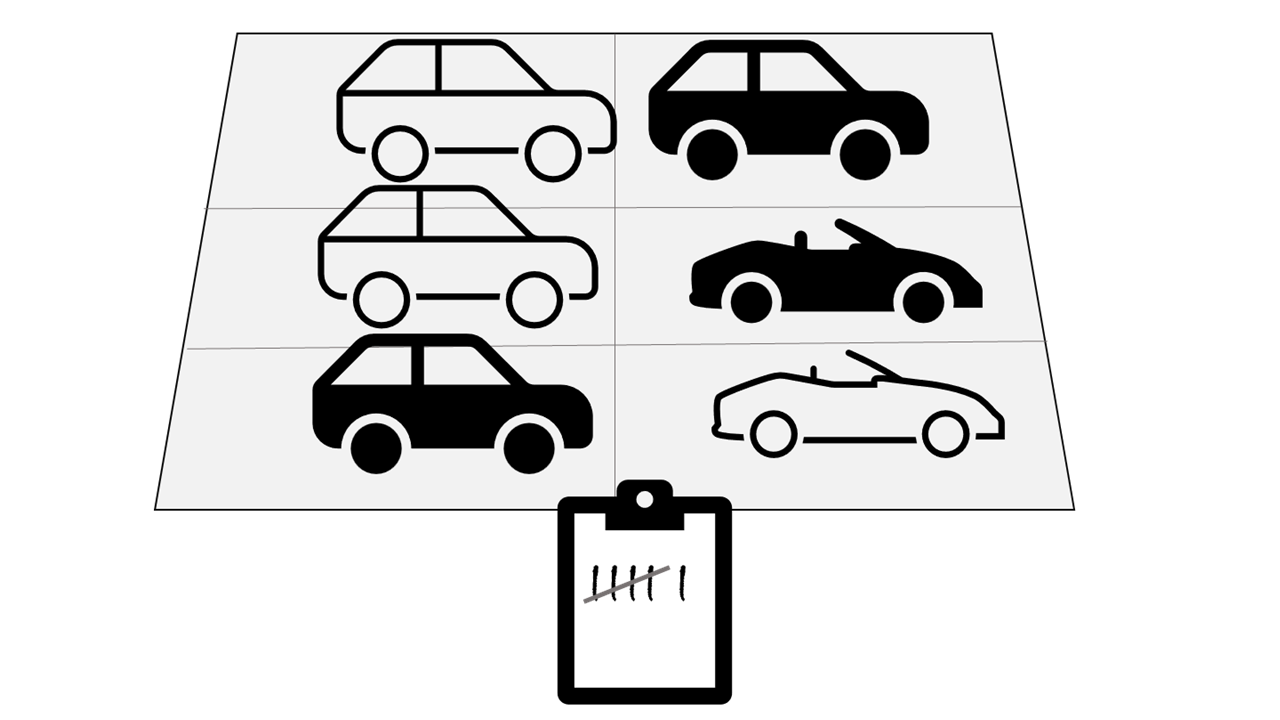
Wenn die Straße stark befahren ist und viele Autos in kurzen Abständen vorbeifahren, ist dieser Ansatz möglicherweise nicht umsetzbar. Beachten Sie außerdem, dass Sie erst dann Ergebnisse erhalten, nachdem Sie eine Gruppe (einen Batch) von Autos geparkt und gezählt haben.
Ein praktisches Beispiel für die Batchverarbeitung ist die Methode, mit der Kreditkartenunternehmen die Abrechnung durchführen. Der Kunde erhält keine Rechnung für jeden Kreditkartenkauf, sondern eine monatliche Rechnung für alle Käufe, die im Lauf des Monats getätigt wurden.
Die Batchverarbeitung bietet folgende Vorteile:
- Große Datenmengen können zu einem geeigneten Zeitpunkt verarbeitet werden.
- Die Ausführung kann außerhalb der Spitzenzeiten oder für einen Zeitpunkt geplant werden, an dem sich die Computer oder Systeme ansonsten im Leerlauf befinden (z. B. über Nacht).
Die Batchverarbeitung bringt folgende Nachteile mit sich:
- Die Zeitverzögerung zwischen dem Erfassen der Daten und dem Erhalt der Ergebnisse
- Alle Eingabedaten eines Batchauftrags müssen bereit sein, bevor ein Batch verarbeitet werden kann. Das bedeutet, dass die Daten sorgfältig überprüft werden müssen. Wenn während Batchaufträgen Probleme mit den Daten, Fehler oder Programmabstürze auftreten, muss der gesamte Prozess angehalten werden. Die Eingabedaten müssen sorgfältig überprüft werden, bevor der Auftrag wiederholt ausgeführt werden kann. Selbst kleinere Datenfehler können die Ausführung eines Batchauftrags verhindern.
Grundlegendes zur Datenstromverarbeitung
Bei der Streamverarbeitung wird jedes neue Datenelement beim Eintreffen verarbeitet. Im Gegensatz zur Batchverarbeitung wird nicht auf das nächste Batchverarbeitungsintervall gewartet, und die Daten werden einzeln in Echtzeit verarbeitet, nicht als Batch. Die Streamingdatenverarbeitung ist in Szenarios nützlich, in denen kontinuierlich neue, dynamische Daten generiert werden.
Ein besserer Ansatz für unser hypothetisches Problem der Autozählung wäre zum Beispiel die Anwendung eines Streamingansatzes, bei dem die Autos in Echtzeit gezählt werden, während sie vorbeifahren:
Bei diesem Ansatz müssen Sie nicht warten, bis alle Autos geparkt haben, um mit der Verarbeitung zu beginnen. Sie können die Daten über Zeitintervalle aggregieren, indem Sie beispielsweise die Anzahl der Autos zählen, die jede Minute vorbeifahren.
Es folgen einige praktische Beispiele für das Streaming von Daten:
- Ein Finanzinstitut verfolgt die Änderungen am Aktienmarkt in Echtzeit nach und berechnet dabei den Value at Risk, und die Portfolios werden automatisch auf der Grundlage der Aktienkursentwicklung ausgeglichen.
- Ein Unternehmen für Onlinegaming erfasst Echtzeitdaten zu Spielerinteraktionen und speist diese in seine Gamingplattform ein. Die Daten werden dann in Echtzeit analysiert, um Spieler durch neue Anreize und ein dynamisches Spielerlebnis zu binden.
- Eine Immobilienwebsite verfolgt eine Teilmenge der Daten von Mobilgeräten und gibt basierend auf deren Standort in Echtzeit Empfehlungen für Immobilien aus, die besichtigt werden können.
Die Streamverarbeitung ist ideal für zeitkritische Vorgänge, für die eine sofortige Antwort in Echtzeit erforderlich ist. Ein Beispiel hierfür ist ein System, das ein Gebäude auf Rauch- und Hitzeentwicklung überwacht und daraufhin einen Alarm auslöst und Türen entsperrt, damit die Bewohner das Gebäude im Brandfall sofort verlassen können.
Grundlegendes zu den Unterschieden zwischen Batch- und Streamingdaten
Neben der Vorgehensweise bei der Datenverarbeitung gibt es weitere Unterschiede zwischen der Batch- und der Streamingverarbeitung:
Datenbereich: Bei der Batchverarbeitung können alle Daten im Dataset verarbeitet werden. Die Streamverarbeitung hat in der Regel nur Zugriff auf die zuletzt oder innerhalb eines rollierenden Zeitfensters (z. B. die letzten 30 Sekunden) empfangenen Daten.
Datengröße: Die Batchverarbeitung eignet sich für die effiziente Bearbeitung großer Datasets. Die Streamverarbeitung ist für einzelne Datensätze oder Mikrobatches (wenige Datensätze) vorgesehen.
Leistung: Die Wartezeit ist die Zeit, die benötigt wird, um die Daten zu empfangen und zu verarbeiten. Die Wartezeit für die Batchverarbeitung beträgt in der Regel einige Stunden. Die Streamverarbeitung erfolgt in der Regel sofort, wobei die Wartezeit nur Sekunden oder Millisekunden beträgt.
Analyse: In der Regel verwenden Sie die Batchverarbeitung, um komplexe Analysen durchzuführen. Die Streamverarbeitung wird für einfache Antwortfunktionen, Aggregate oder Berechnungen (z. B. gleitende Durchschnittswerte) verwendet.
Kombinieren von Batch- und Streamverarbeitung
Viele groß angelegte Analyselösungen bieten eine Kombination aus Batch- und Streamverarbeitung, sodass sowohl historische Daten als auch Echtzeitdaten analysiert werden können. Bei Lösungen für die Streamverarbeitung ist es üblich, Echtzeitdaten zu erfassen, sie durch Filterung oder Aggregation zu verarbeiten und sie in Form von Echtzeitdashboards und -visualisierungen darzustellen (z. B. die aktuelle Gesamtzahl der Autos, die in der letzten Stunde eine Straße passiert haben) und gleichzeitig auch die verarbeiteten Ergebnisse in einem Datenspeicher für die historische Analyse zusammen mit im Batch verarbeiteten Daten zu speichern (z. B. zur Analyse des Verkehrsaufkommens im vergangenen Jahr).
Selbst wenn keine Echtzeitanalyse oder -visualisierung von Daten benötigt wird, werden Streamingtechnologien häufig eingesetzt, um Echtzeitdaten zu erfassen und für eine anschließende Batchverarbeitung in einem Datenspeicher zu speichern (dies entspricht der Vorgehensweise, alle Autos, die eine Straße entlang fahren, vor ihrer Zählung auf einen Parkplatz umzuleiten).
Das folgende Diagramm zeigt einige Möglichkeiten, wie Batch- und Streamverarbeitung in einer groß angelegten Architektur für die Datenanalyse kombiniert werden können.
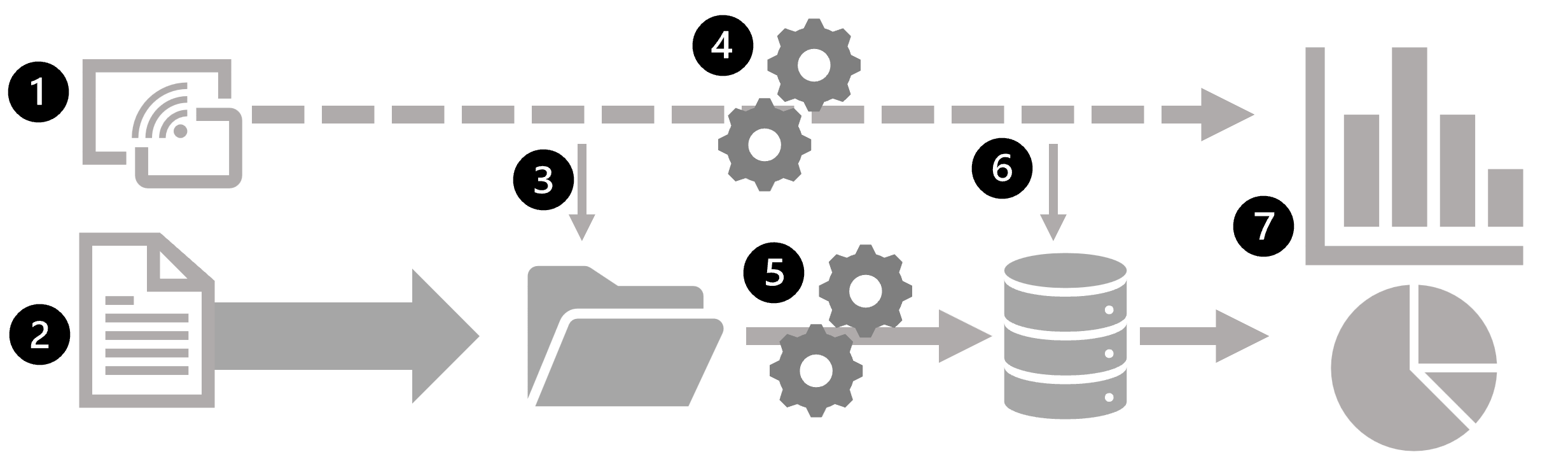
- Datenereignisse aus einer Streamingdatenquelle werden in Echtzeit erfasst.
- Daten aus anderen Quellen werden zur Batchverarbeitung in einen Datenspeicher (häufig ein Data Lake) eingespeist.
- Wenn keine Echtzeitanalyse erforderlich ist, werden die erfassten Streamingdaten für die nachfolgende Batchverarbeitung in den Datenspeicher geschrieben.
- Ist eine Echtzeitanalyse erforderlich, wird eine Technologie zur Streamverarbeitung eingesetzt, um die Streamingdaten für die Echtzeitanalyse oder -visualisierung aufzubereiten. Dabei werden die Daten häufig gefiltert oder über Zeitfenster aggregiert.
- Die Nicht-Streamingdaten werden in regelmäßigen Abständen als Batch verarbeitet, um sie für die Analyse vorzubereiten, und die Ergebnisse werden in einem analytischen Datenspeicher (oft als Data Warehouse bezeichnet) für historische Analysen gespeichert.
- Die Ergebnisse der Streamverarbeitung können auch im analytischen Datenspeicher abgelegt werden, um historische Analysen zu unterstützen.
- Mithilfe von Analyse- und Visualisierungstools werden die Echtzeitdaten und die historischen Daten dargestellt und untersucht.
Hinweis
Zu den häufig verwendeten Lösungsarchitekturen für die kombinierte Batch- und Streamverarbeitung von Daten gehören Lambda- und Delta-Architekturen. Die Details dieser Architekturen würden den Rahmen dieses Kurses sprengen, aber sie beinhalten Technologien für die Verarbeitung großer Datenmengen in Batches und Echtzeitstreams, um eine End-to-End-Analyselösung bereitzustellen.