Beschreiben der Normalisierung
Datenbanknormalisierung ist ein Entwurfsprozess, der verwendet wird, um Daten in Tabellen und Spalten innerhalb einer Datenbank zu organisieren. Jede Tabelle sollte Daten zu einer bestimmten Entität enthalten und nur Informationen umfassen, die diese Entität unterstützen. Das Hauptziel der Normalisierung besteht darin, Duplikate in der Datenbank zu minimieren, um Leistungsbeeinträchtigungen beim Einfügen und Aktualisieren zu vermeiden. Wenn beispielsweise die Adresse einer Person aktualisiert werden muss, ist es einfacher, die Änderung vorzunehmen, wenn die Adresse an einem einzigen Ort gespeichert ist, beispielsweise in der Tabelle Customers.
Die gängigsten Formen der Normalisierung sind die erste, zweite und dritte Normalform.
Erste Normalform
Die erste Normalform hat die folgenden Spezifikationen:
- Erstellen einer separaten Tabelle für jeden Satz von verwandten Daten
- Beseitigen von Wiederholungsgruppen in einzelnen Tabellen
- Identifizieren jedes Satzes von verwandten Daten mit einem Primärschlüssel
In diesem Modell sollten Sie darauf verzichten, mehrere Spalten in einer einzigen Tabelle zu verwenden, um ähnliche Daten zu speichern. Wenn ein Produkt beispielsweise in mehreren Farben erhältlich ist, sollten Sie nicht mehrere Spalten in einer einzigen Zeile haben, die die verschiedenen Farbwerte enthalten. Die erste folgende Tabelle (ProductColors) entspricht nicht der ersten Normalform, da sie sich wiederholende Werte für die Farbe enthält. Bei Produkten, die nur eine Farbe haben, wird Platz verschwendet. Wenn ein Produkt in mehr als drei Farben erhältlich ist, ist es außerdem nicht praktikabel, eine maximale Anzahl von Spalten festzulegen. Stattdessen können Sie die Tabelle wie in der zweiten Tabelle (ProductColor) dargestellt neu erstellen.
Die erste Normalform verlangt außerdem, dass es einen eindeutigen Schlüssel für die Tabelle gibt, also eine Spalte (oder Spalten), deren Wert jede Zeile eindeutig identifiziert. In der zweiten Tabelle ist keine der Spalten für sich allein eindeutig, aber zusammen bilden die Kombination aus „ProductID“ und „Color“ einen eindeutigen Schlüssel. Wenn mehrere Spalten erforderlich sind, um einen eindeutigen Schlüssel zu erstellen, spricht man von einem zusammengesetzten Schlüssel.
Tabelle
ProductColors:ProductID Color1 Color2 Color3 1 Rot Grün Gelb 2 Gelb 3 Blau Rot 4 Blau 5 Rot Tabelle
ProductColor:ProductID Color 1 Rot 1 Grün 1 Gelb 2 Gelb 3 Blau 3 Rot 4 Blau 5 Rot
Die dritte Tabelle (ProductInfo) befindet sich in der ersten Normalform, da sich jede Zeile auf ein bestimmtes Produkt bezieht und es keine Wiederholungsgruppen gibt. Außerdem kann die Spalte „ProduktID“ als Primärschlüssel verwendet werden.
| ProductID | ProductName | Preis | ProductionCountry | ShortLocation |
|---|---|---|---|---|
| 1 | Widget | 15,95 | USA | USA |
| 2 | Foop | 41,95 | Vereinigtes Königreich | Vereinigtes Königreich |
| 3 | Glombit | 49,95 | Vereinigtes Königreich | Vereinigtes Königreich |
| 4 | Sorfin | 99,99 | Philippinen | RepPhil |
| 5 | Stem Bolt | 29,95 | USA | USA |
Zweite Normalform
Die zweite Normalform hat die folgende Spezifikation, zusätzlich zu denen, die für die erste Normalform erforderlich sind:
- Wenn die Tabelle einen zusammengesetzten Schlüssel hat, müssen alle Attribute vom vollständigen Schlüssel abhängig sein, nicht nur von einem Teil davon.
Die zweite Normalform ist nur für Tabellen mit zusammengesetzten Schlüsseln relevant, wie in der Tabelle ProductColor (die zweite Tabelle). Betrachten Sie den Fall, dass die Tabelle ProductColor auch den Preis des Produkts enthält. Diese Tabelle hat einen zusammengesetzten Schlüssel aus ProductID und Color, da nur mithilfe beider Spaltenwerte eine Zeile eindeutig identifiziert werden kann. Wenn sich der Preis eines Produkts nicht mit der Farbe ändert, könnten die Daten wie in dieser Tabelle angezeigt werden:
| ProductID | Color | Preis |
|---|---|---|
| 1 | Rot | 15,95 |
| 1 | Grün | 15,95 |
| 1 | Gelb | 15,95 |
| 2 | Gelb | 41,95 |
| 3 | Blau | 49,95 |
| 3 | Rot | 49,95 |
| 4 | Blau | 99,95 |
| 5 | Rot | 29,95 |
Diese Tabelle befindet sich nicht in zweiter Normalform. Der Wert „Preis“ hängt von der ProductID ab, aber nicht von der Color. Es gibt drei Zeilen für ProductID 1, so dass der Preis für dieses Produkt dreimal wiederholt wird. Das Problem bei der Verletzung der zweiten Normalform besteht darin, dass wir bei einer Preisaktualisierung sicherstellen müssen, dass dieser überall aktualisiert wird. Wenn wir den Preis in der ersten Zeile aktualisieren, aber nicht in der zweiten oder dritten, ergibt sich eine so genannte Aktualisierungsanomalie. Nach dem Update könnten wir den tatsächlichen Preis für ProductID 1 nicht mehr ermitteln. Die Lösung ist, die Spalte Price in eine Tabelle zu verschieben, die ProductID als einzigen Spaltenschlüssel hat, da dies die einzige Spalte ist, von der Price abhängt. Wir könnten zum Beispiel Tabelle 3 verwenden, um den Preis (Price) zu speichern.
Wenn der Preis für ein Produkt sich je nach Farbe unterscheiden würde, befände sich die vierte Tabelle in der zweiten Normalform, da der Preis von beiden Teilen des Schlüssels abhinge: ProductID und Color.
Dritte Normalform
Die dritte Normalform ist normalerweise das Ziel für die meisten OLTP-Datenbanken. Die dritte Normalform hat die folgende Spezifikation, zusätzlich zu denen, die für die zweite Normalform erforderlich sind:
- Alle Nicht-Schlüsselspalten sind nicht transitiv vom Primärschlüssel abhängig.
Die transitive Beziehung impliziert, dass eine Spalte in einer Tabelle über eine zweite Spalte mit anderen Spalten in Beziehung steht. Abhängigkeit bedeutet, dass eine Spalte ihren Wert von einer anderen ableiten kann, was zu einer Beziehung führt. Zum Beispiel kann Ihr Alter anhand Ihres Geburtsdatums ermittelt werden, wodurch Ihr Alter von Ihrem Geburtsdatum abhängig ist. Gehen Sie zurück zur dritten Tabelle (ProductInfo). Diese Tabelle ist in der zweiten Normalform, aber nicht in der dritten. Die Spalte ShortLocation ist von der Spalte ProductionCountry abhängig, die nicht der Schlüssel ist. Wie bei der zweiten Normalform kann auch die Verletzung der dritten Normalform zu Aktualisierungsanomalien führen. Wenn wir ShortLocation in einer Zeile aktualisieren würden, ohne sie in allen Zeilen zu aktualisieren, in denen dieser Ort vorkommt, würden dies zu inkonsistenten Daten führen. Um dies zu verhindern, könnten wir eine separate Tabelle erstellen, um die Länder-/Regionsnamen und deren Kurzformen zu speichern.
Denormalisierung
Während die dritte Normalform theoretisch wünschenswert ist, ist sie nicht immer für alle Daten möglich. Darüber hinaus bietet eine normalisierte Datenbank nicht immer die beste Leistung. Normalisierte Daten erfordern häufig mehrere Verknüpfungsoperationen (join), um alle erforderlichen Daten in einer einzigen Abfrage zurückzubekommen. Es gibt einen Kompromiss zwischen der Normalisierung von Daten, wenn die Anzahl der Verknüpfungen, die für die Rückgabe von Abfrageergebnissen erforderlich sind, eine hohe CPU-Auslastung zur Folge hat, und denormalisierten Daten mit weniger Verknüpfungen und geringerer CPU-Auslastung, aber der Möglichkeit von Aktualisierungsanomalien.
Denormalisierte Daten lassen sich eventuell effizienter abfragen, insbesondere bei leselastigen Workloads wie einem Data Warehouse. In diesen Fällen kann das Vorhandensein zusätzlicher Spalten bessere Abfragemuster und/oder einfachere Abfragen ermöglichen.
Sternschema
Während die meisten Normalisierungen auf OLTP-Workloads abzielen, haben Data Warehouses ihre eigene Modellierungsstruktur, die typischerweise ein denormalisiertes Modell ist. Dieses Design verwendet Faktentabellen, um Messungen oder Metriken für bestimmte Ereignisse, wie beispielsweise Verkäufe, aufzuzeichnen und diese mit Dimensionstabellen zu verknüpfen. Dimensionstabellen sind hinsichtlich der Zeilenanzahl kleiner, können jedoch eine große Anzahl von Spalten enthalten, um die Fakten zu beschreiben. Beispiele für Dimensionen sind beispielsweise Inventar, Zeit und Geografie. Dieses Entwurfsmuster wird verwendet, um die Abfrage der Datenbank zu vereinfachen und Leistungsgewinne bei Leseworkloads zu erzielen.
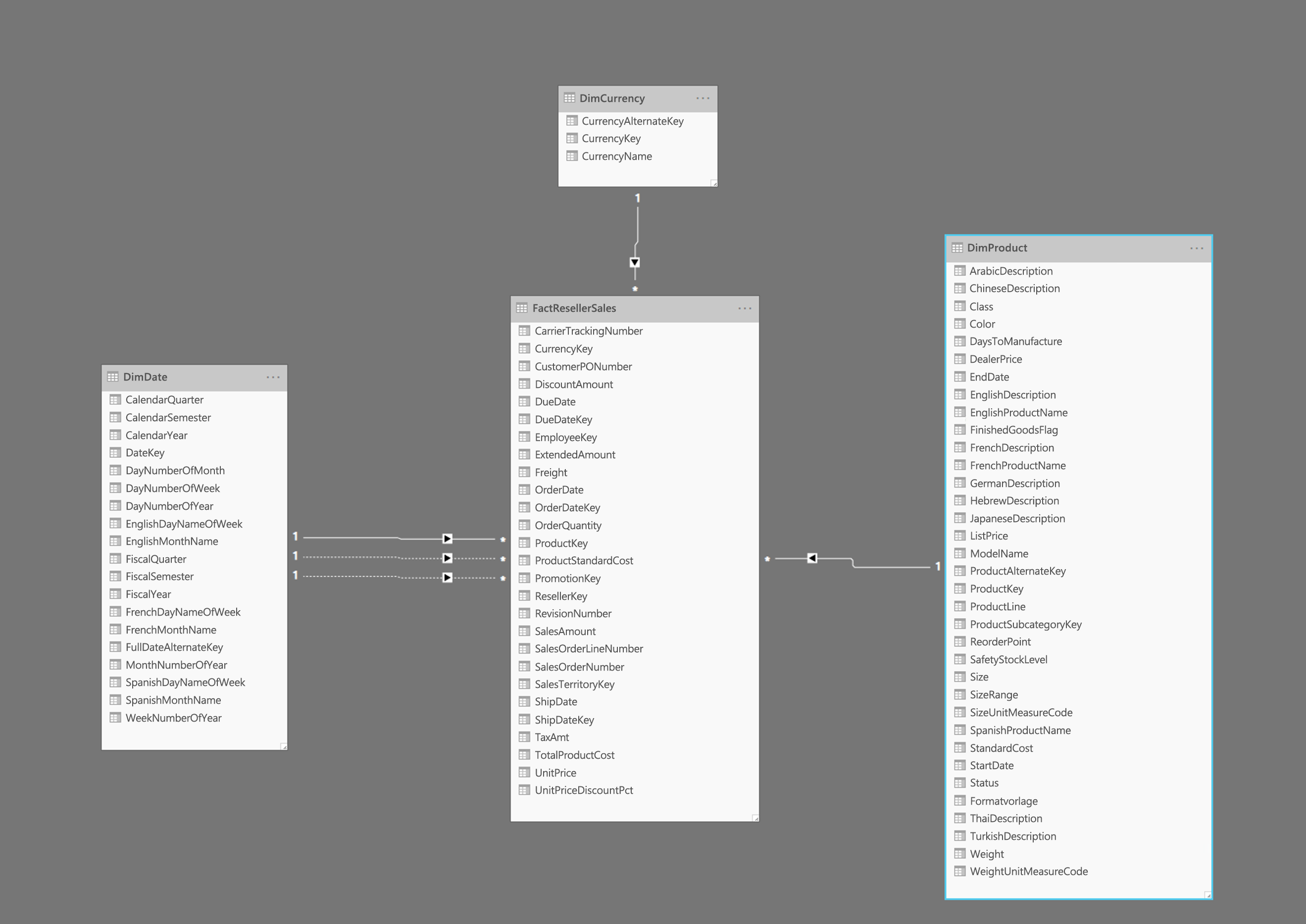
Die Abbildung zeigt ein Beispiel für ein Sternschema mit einer Faktentabelle FactResellerSales und Dimensionen für Datum, Währung und Produkte. Die Faktentabelle enthält Daten, die sich auf Verkaufstransaktionen beziehen, und die Dimensionen enthalten nur Daten, die sich auf bestimmte Elemente der Verkaufsdaten beziehen. Die Tabelle FactResellerSales enthält beispielsweise nur einen ProductKey, um anzugeben, welches Produkt verkauft wurde. Alle Details zu jedem Produkt werden in der Tabelle DimProduct gespeichert und über die Spalte ProductKey mit der Faktentabelle verknüpft.
Mit dem Entwurf eines Sternschemas verwandt ist das Schneeflockenschema, das eine Reihe von normalisierten Tabellen für eine einzelne Geschäftseinheit verwendet. Die folgende Abbildung zeigt ein Beispiel für eine einzelne Dimension in einem Schneeflockenschema. Die Dimension „Products“ wird normalisiert und in drei Tabellen gespeichert: DimProductCategory, DimProductSubcategory und DimProduct.
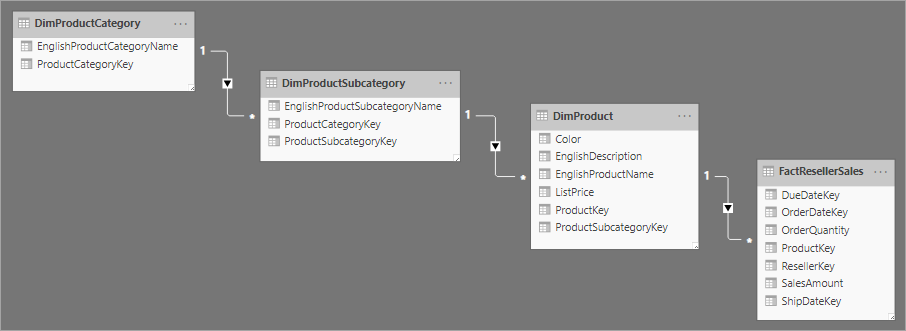
Der Hauptunterschied zwischen Stern- und Schneeflockenschemas besteht darin, dass die Dimensionen in einem Schneeflockenschema normalisiert werden, um Redundanz zu reduzieren, was Speicherplatz spart. Der Nachteil ist, dass Ihre Abfragen mehr Verknüpfungen erfordern, was die Komplexität erhöhen und die Leistung verringern kann.